Voice Recognition Market Insights for Teams Building at Scale


Learn how the voice recognition market is growing for real-time enterprise use. Covers growth drivers, deployment models, and platform evaluation factors.
Voice workflows break in subtle ways. Calls lag, transcripts drift, agents talk over customers, and teams end up firefighting latency instead of fixing outcomes. If you are tracking the voice recognition market, it is likely because voice has moved from experiment to infrastructure inside your org. Accuracy and speed now sit directly on revenue, compliance, and customer trust.
The voice recognition market is growing fast, but not every platform is built for real-time pressure in healthcare, BFSI, or high-volume support. Leaders are asking harder questions around latency budgets, deployment models, and production reliability. In this guide, we break down where the market is heading, what actually matters in enterprise deployments, and how teams are evaluating modern voice stacks for live use.
Key Takeaways
Voice Recognition Market Is Infrastructure-Driven: Growth is led by real-time, always-on enterprise deployments where latency, uptime, and compliance directly affect revenue and operational outcomes.
Latency Has Become a Buying Constraint: Sub-300 ms response times now determine whether voice systems succeed in live healthcare, BFSI, and high-volume support workflows.
Edge and Hybrid Architectures Are Gaining Ground: While cloud still dominates share, edge and on-prem deployments are growing fastest due to privacy, offline reliability, and deterministic performance needs.
Enterprise Value Is Concentrated in Regulated Verticals: Healthcare documentation, BFSI voice biometrics, and automotive voice OS drive higher revenue density than consumer voice search.
Platforms Win on Architecture, Not Model Size: Specialized, task-focused voice models outperform large general-purpose systems under real production load in the voice recognition market.
Voice Recognition Market Size and Growth Outlook

Enterprise buyers evaluating voice recognition are tracking market growth signals that directly impact infrastructure planning, deployment models, and long-term automation ROI.
Market Scale Expansion: The global voice and speech recognition market was valued at USD 20.25B in 2023 and is projected to reach USD 53.67B by 2030, growing at a 14.6% CAGR.
Acceleration Window: Growth between 2024 and 2030 is driven by enterprise adoption of real-time transcription, voice biometrics, and embedded voice systems rather than consumer assistants.
Revenue Density Shift: Market value is concentrating in healthcare, BFSI, automotive, and enterprise contact centers, where voice replaces high-cost, human-heavy workflows.
Deployment Economics: Cloud-based voice systems account for roughly 61–62% of deployments, but hybrid and on-prem models are expanding fastest due to latency and data-residency constraints.
Technology Mix Evolution: Speech recognition holds 64.6% share, while voice recognition and embedded edge voice AI are growing faster as real-time and privacy requirements increase.
Market growth favors platforms that deliver predictable latency, regulatory alignment, and scalable voice throughput rather than raw model size or generic accuracy benchmarks.
Key Trends Shaping the Voice Recognition Market
Enterprise voice teams are tracking technology shifts that directly affect latency budgets, deployment architecture, and whether voice systems survive real production load.
From Cascades to Unified Models: Enterprises are moving away from ASR→LLM→TTS pipelines toward unified speech models that cut serial latency and preserve emotion during live conversations.
Edge Inference Becomes Default: On-device and embedded voice models are gaining traction to meet offline requirements, sub-300ms response targets, and strict data-residency rules.
Voice Biometrics With Liveness Signals: BFSI adoption now requires passive liveness detection, replay resistance, and behavioral scoring layered on top of raw voiceprint matching.
Multilingual Code-Switching at Runtime: Modern deployments must handle mid-sentence language switching, regional accents, and phonetic drift without reloading models or delaying inference.
Specialized Voice Silicon Adoption: Purpose-built voice AI chips are replacing general GPUs in high-volume environments to reduce cost, power draw, and inference jitter.
The market is shifting toward real-time, infrastructure-grade voice systems built for continuous operation, regulatory exposure, and human conversational speed rather than demo-level accuracy.
Compare real-world latency, deployment models, and production readiness across leading platforms in Top Voice API Providers: Revolutionizing Speech Recognition
What Is Driving Voice Recognition Market Growth
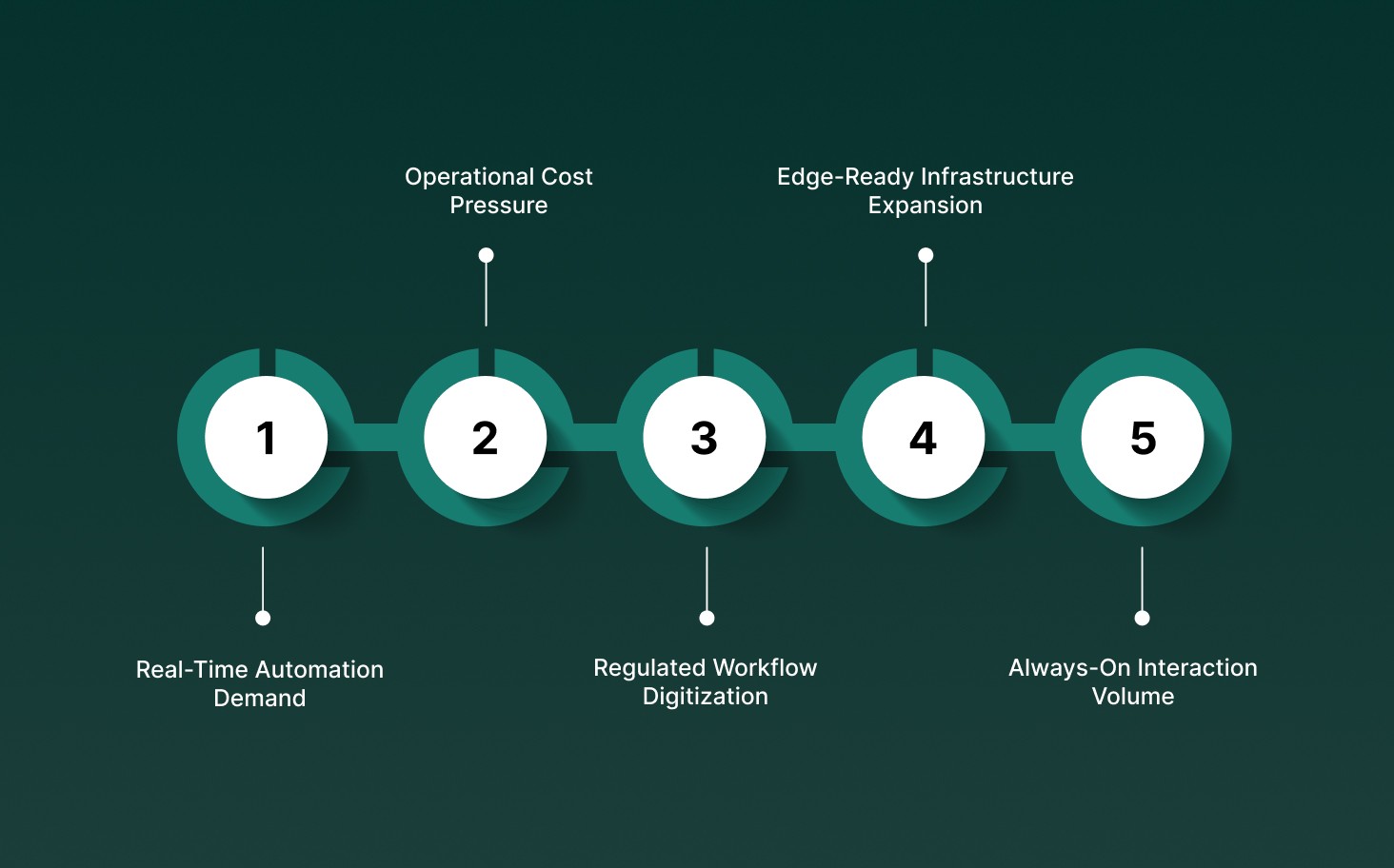
Enterprise adoption of voice recognition is accelerating as technical constraints around latency, accuracy, and scale are finally being removed in production environments.
Real-Time Automation Demand: High-volume workflows like collections, support, and scheduling require voice systems that respond within conversational thresholds, not batch or delayed inference.
Operational Cost Pressure: Enterprises are replacing human-first call handling with voice agents to cut per-interaction costs while maintaining availability across millions of monthly conversations.
Regulated Workflow Digitization: Healthcare and BFSI are digitizing voice-heavy processes under strict compliance, forcing the adoption of auditable, deterministic speech systems.
Edge-Ready Infrastructure Expansion: Wider availability of embedded AI silicon allows low-latency voice processing without cloud round-trip, unlocking offline and data-sovereign deployments.
Always-On Interaction Volume: Voice traffic continues to rise across mobile, IVR, and in-product assistants, increasing demand for systems that sustain parallel conversations without degradation.
Market growth is driven less by novelty and more by infrastructure readiness, voice recognition now meets enterprise requirements for speed, scale, and operational predictability.
Key Challenges Limiting Voice Recognition Adoption
Despite strong demand, enterprise teams face technical and structural blockers that prevent voice recognition from performing reliably under real production conditions.
Latency Accumulation: Cascaded pipelines introduce serial delays across ASR, reasoning, and synthesis, pushing response times past human conversational tolerance during live interactions.
Accent and Phonetic Drift: Models trained on narrow datasets fail with regional accents, mixed phonemes, and code-switching, forcing costly fine-tuning for each new deployment region.
Compliance Friction: Voice data qualifies as biometric information, triggering strict storage, consent, and deletion requirements under GDPR, DPDP, and sector-specific mandates.
Noise and Domain Jargon: Industrial environments and domain-heavy speech expose accuracy gaps when models encounter overlapping speakers, background noise, or specialized terminology.
Operational Cost Overhead: Large models demand sustained GPU capacity, driving unpredictable inference costs and limiting viability for high-volume, always-on voice workloads.
Adoption stalls when voice systems fail under latency pressure, regulatory exposure, and real-world audio conditions that differ sharply from controlled benchmarks.
Build real-time voice workflows with Smallest AI using sub-300 ms latency, streaming-first inference, and edge-ready deployments built for regulated, high-volume production environments.
Cloud vs On-Prem Voice Recognition Deployment
Enterprise teams choosing a voice recognition stack must balance latency, compliance exposure, operational cost, and reliability under real conversational load. Deployment architecture determines whether voice works in production or fails at scale.
Deployment Dimension | Cloud Voice Recognition | On-Prem / Edge Voice Recognition |
Latency Profile | Network-bound inference introduces variable delays, especially under peak traffic or poor connectivity | Local inference delivers predictable sub-second responses without network round trips |
Data Control | Voice data traverses third-party infrastructure, increasing audit and retention complexity | Audio and transcripts stay within controlled environments, simplifying regulatory compliance |
Scalability Model | Elastic scaling supports burst workloads but ties cost directly to usage spikes | Capacity is provisioned upfront, allowing stable costs for high-volume, always-on traffic |
Update Cadence | Models can be refreshed frequently but risk regressions without tight version control | Updates are deliberate and validated, favoring deterministic behavior over quick iteration |
Failure Modes | Performance degrades with network outages or regional cloud disruptions | Systems continue operating offline, critical for vehicles, hospitals, and call centers |
Cloud favors experimentation and burst scale, while on-prem and edge deployments win when latency, compliance, and operational predictability define success.
See which tools deliver accurate transcription under live conditions in Top 8 Voice-to-Text Software for Real-Time and Production Use
Voice Recognition Market by End-User Industry

Voice recognition adoption varies sharply by industry, shaped by latency tolerance, regulatory exposure, audio complexity, and volume economics. The strongest demand comes from sectors where voice directly replaces high-cost human workflows.
Industries driving adoption and spend across production voice deployments include:
Consumer Electronics: Always-on wake words, multilingual ASR, and on-device inference power smartphones, wearables, and smart speakers at a massive consumer scale.
Healthcare: Ambient dictation and EHR-bound transcription require sub-second latency, medical vocabulary tuning, and strict HIPAA-aligned data handling.
BFSI: Voice biometrics allow passive authentication during live calls, reducing AHT while blocking social-engineering fraud without adding customer friction.
Automotive: Embedded voice OS handles navigation, diagnostics, and cabin control offline, avoiding cellular dependency and meeting hands-free safety mandates.
IT and Telecommunications: Real-time transcription, QA monitoring, and AI voice agents support high-volume contact centers with predictable latency under load.
Industries investing fastest in voice recognition treat it as core infrastructure, not a UI layer, prioritizing reliability, latency, and compliance over experimentation.
Competitive Landscape: Why Voice Quality and Latency Matter
In enterprise voice systems, competitive advantage is decided by two measurable factors: how accurately speech is understood and how fast the system responds during live conversations.
Performance dimensions shaping competition across leading voice platforms include:
Word Error Rate Control: Low WER across accents, jargon, and noisy audio separates enterprise-grade systems from consumer and open-source baselines.
Time To First Token: Sub-200 ms response keeps conversations natural; delays break turn-taking and reduce task completion in live calls.
Conversational Stability: Consistent timing across long sessions prevents overlap, interruptions, and agent talk-over in support and collections workflows.
Edge Inference Capability: On-device ASR and TTS remove network jitter, delivering predictable latency in vehicles, hospitals, and regulated environments.
Domain-Tuned Models: Healthcare, BFSI, and automotive workloads demand custom acoustic and language models to avoid accuracy collapse under real conditions.
Vendors win when voice feels instant and dependable under pressure, not when demos look good in isolation. Latency and accuracy decide who scales in production.
Explore how real-time voice systems are reshaping enterprise workflows in The Future of AI Voice-Driven Interactions and Their Impact
What Enterprise Buyers Should Look for in Voice Recognition Platforms
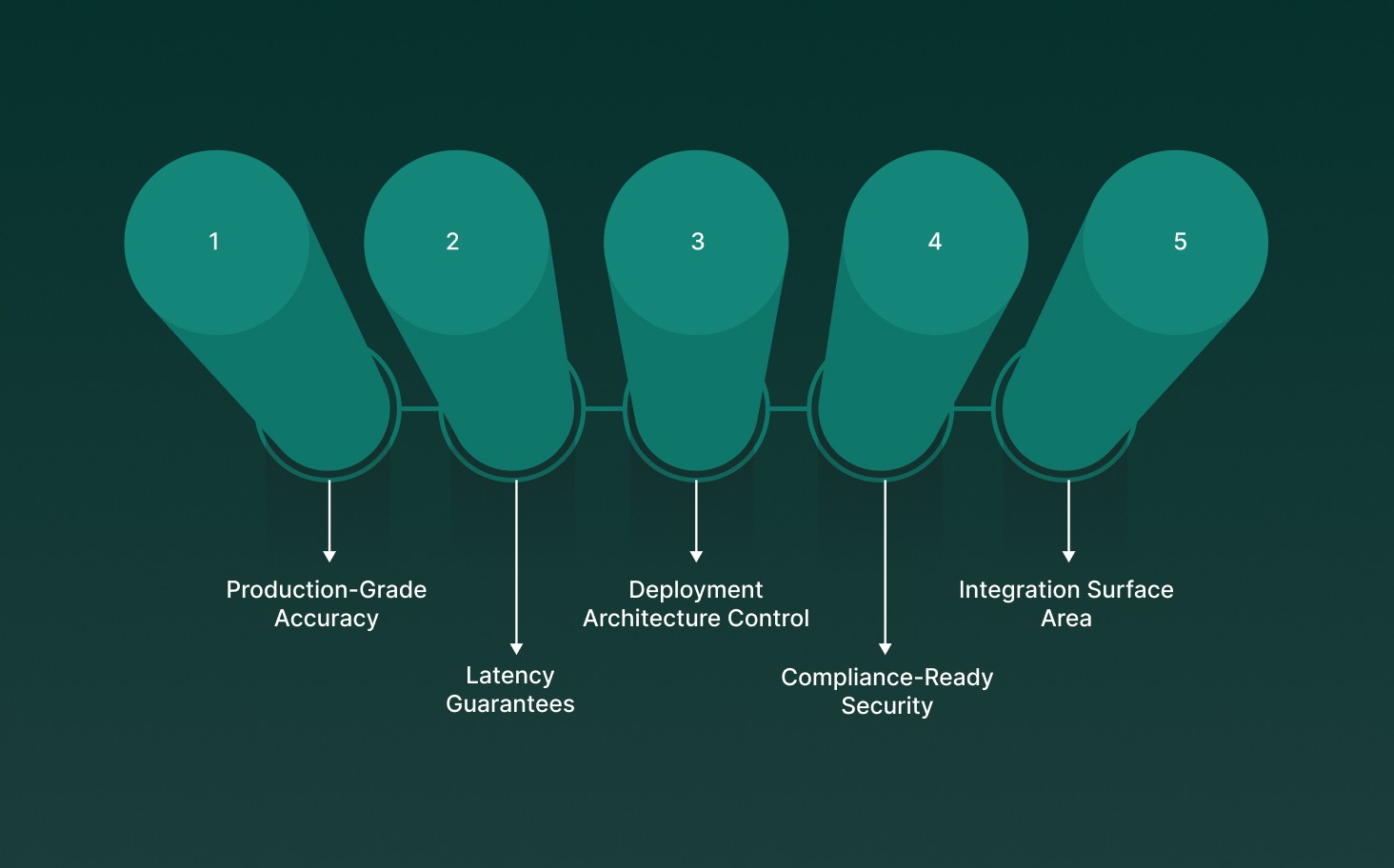
Enterprise voice platforms succeed or fail in production environments, not demos. Buyers need systems that stay accurate, fast, and compliant under real operational load.
Evaluation criteria that enterprise teams prioritize when selecting voice recognition platforms include:
Production-Grade Accuracy: Low word error rates across accents, jargon, and noisy audio, validated on live call traffic rather than curated test datasets.
Latency Guarantees: Sub-300 ms time-to-first-token with consistent response timing to support real-time conversations in support, collections, and clinical workflows.
Deployment Architecture Control: Clear support for cloud, edge, or hybrid inference to meet privacy, uptime, and network reliability requirements.
Compliance-Ready Security: Built-in controls for GDPR, HIPAA, SOC 2, and DPDP, with configurable data retention, encryption, and audit logging.
Integration Surface Area: SDKs and APIs that plug directly into CRMs, EHRs, IVRs, and agent platforms without fragile middleware layers.
Enterprise buyers should prioritize platforms engineered for live operations, not feature checklists. Accuracy, latency, and control determine whether voice automation scales safely.
Voice Recognition Market Outlook for 2026–2031
From 2026 through 2031, the voice recognition market shifts from experimentation to infrastructure. Growth is driven by production-grade edge inference, regulated deployments, and vertical-specific monetization.
Dimension | 2026 Baseline | 2031 Projection | What Changes in Practice |
Global Market Size | USD 22.49B | USD 61.71B | Voice moves from feature to core system of record |
Growth Rate (CAGR) | — | 22.38% | Buyers prioritize ROI-backed automation, not pilots |
Dominant Deployment | Cloud (61.6%) | Cloud + Edge Hybrid | Latency-sensitive workloads shift closer to devices |
Fastest-Growing Tech | Edge Voice AI | 24.6% CAGR | Offline inference becomes standard in regulated flows |
Fastest-Growing Vertical | BFSI | 22.7% CAGR | Voice biometrics replace knowledge-based authentication |
Fastest-Growing Region | Asia Pacific | 32%+ share | Multilingual demand and local silicon drive adoption |
Critical Device Category | Smartphones | Wearables, Automotive | Always-on microphones reshape interaction patterns |
Between 2026 and 2031, voice recognition platforms that win will be low-latency, compliance-native, and edge-capable. Market leaders will be built for production scale, not demos.
Why Enterprise Voice Teams Are Evaluating the Pulse STT for Real-Time Voice Recognition
As voice moves from experimentation into revenue-critical workflows, enterprise teams are reassessing platforms that were built for demos, not live operations. The Pulse STT is being evaluated because it was designed for real-time execution from day one.
Enterprise voice leaders evaluating Pulse STT typically focus on the following decision drivers:
Ultra-Low Latency Architecture: Streaming-first inference delivers sub-300 ms response times, keeping conversations fluid in collections, support, and clinical voice workflows.
Specialized Model Design: Small, task-specific models outperform oversized LLMs in accuracy and stability under sustained call volumes.
Edge and Hybrid Readiness: Native support for on-device, on-prem, and hybrid deployments simplifies compliance without sacrificing performance.
Production-Proven Scale: Systems are engineered to handle millions of concurrent voice interactions without degradation or cold-start delays.
Compliance-First Foundations: Built to meet SOC 2, HIPAA, GDPR, and DPDP requirements with deterministic data handling and auditability.
Enterprise teams evaluate Pulse STT because it behaves like infrastructure, not a research experiment. When latency, uptime, and compliance matter, architecture wins.
Conclusion
Voice recognition is moving from a feature to a foundation. Teams that treat it like core infrastructure are the ones seeing fewer handoffs, tighter control over latency, and systems that hold up under real traffic. The market will keep growing, but the gap will widen between voice stacks built for demos and those designed for live, regulated workloads.
If your teams are pressure-testing real-time voice at scale, this is where Pulse STT tends to enter the conversation. From sub-second response paths to deployment models that respect compliance and uptime realities, Smallest AI is built for production voice, not experiments.
Explore how Lightning and real-time voice agents fit into your stack and see what changes when latency stops being the bottleneck. Get in touch with us!
How does edge inference change cost structures in the voice recognition market?
Why do latency benchmarks matter more than accuracy benchmarks in the voice recognition market?
How does data retention policy impact vendor selection in the voice recognition market?
What role does voice activity detection play in scaling the voice recognition market?
Why are enterprises in the voice recognition market moving away from general-purpose LLMs?

