Hydra
Introducing Hydra: Our Speech to Speech model.
The first native speech-to-speech model built for businesses that can't afford to wait.








Hydra
Introducing Hydra: Our Speech to Speech model.
The first native speech-to-speech model built for businesses that can't afford to wait.
Hydra
Introducing Hydra: Our Speech to Speech model.
The first native speech-to-speech model built for businesses that can't afford to wait.
Cascaded voice AI was never meant to scale
Multimodal model means speech and text work together simultaneously, each informing the other in real-time.
Cascaded voice AI was never meant to scale
Multimodal model means speech and text work together simultaneously, each informing the other in real-time.

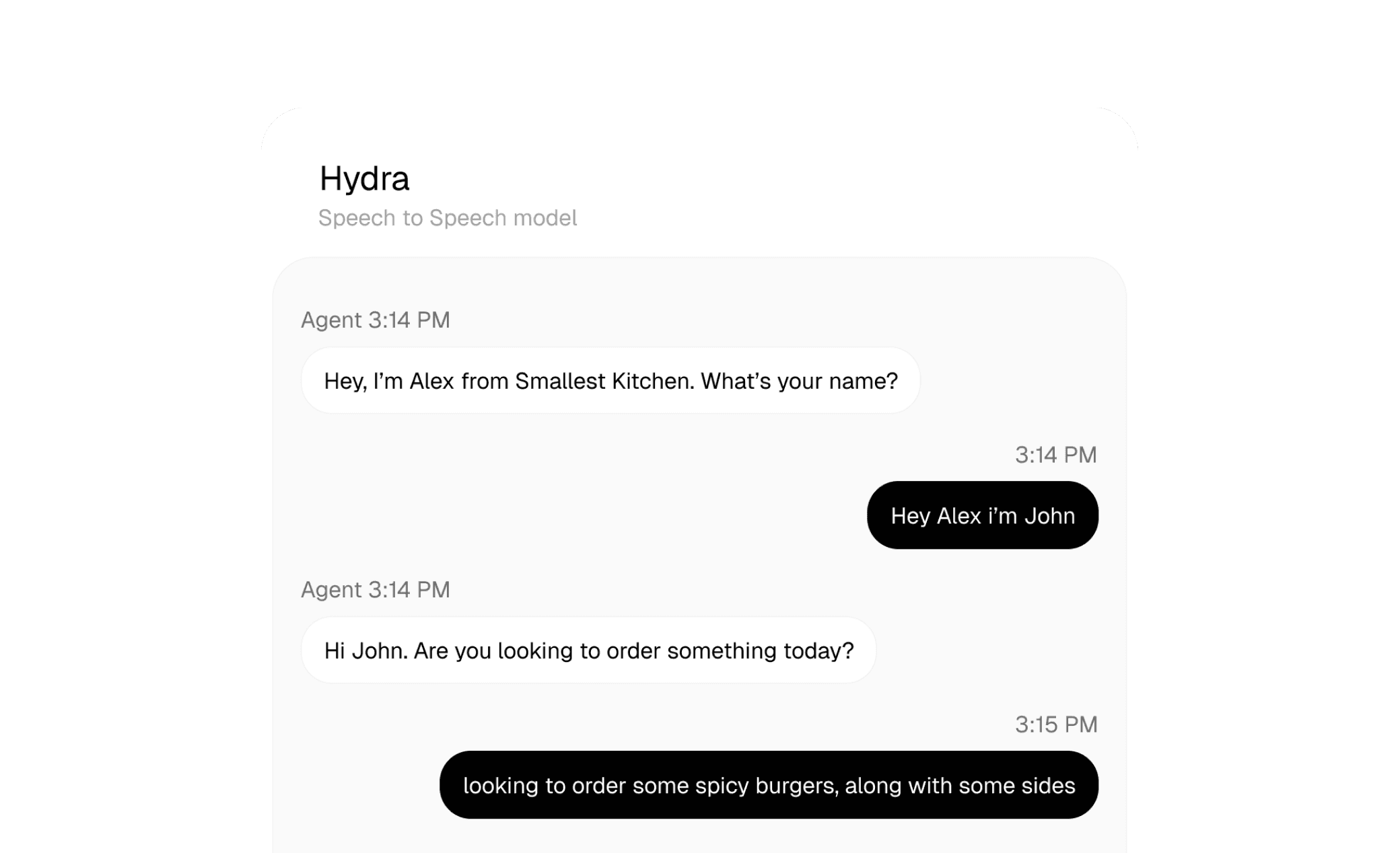
Hear, be heard. Behold.
One model. Speed, duplex, emotion, and language all built in.
Hear, be heard. Behold.
One model. Speed, duplex, emotion, and language all built in.
Sub-300ms Latency
Hydra's unified architecture eliminates sequential overhead in cascaded systems.
Sub-300ms Latency
Hydra's unified architecture eliminates sequential overhead in cascaded systems.
Sub-300ms Latency
Hydra's unified architecture eliminates sequential overhead in cascaded systems.
True Full Duplex
Hydra hears you even while responding handling interruptions, overlaps, and
True Full Duplex
Hydra hears you even while responding handling interruptions, overlaps, and
True Full Duplex
Hydra hears you even while responding handling interruptions, overlaps, and
Emotional Fidelity
When speech hears emotion and text understands meaning at the same time,
Emotional Fidelity
When speech hears emotion and text understands meaning at the same time,
Emotional Fidelity
When speech hears emotion and text understands meaning at the same time,
15+ languages
Speak and get text. Type and hear a response. Send both, receive both.
15+ languages
Speak and get text. Type and hear a response. Send both, receive both.
15+ languages
Speak and get text. Type and hear a response. Send both, receive both.
On premise deployment
No waiting for conversion between modalities. Speech and text inform each other
On premise deployment
No waiting for conversion between modalities. Speech and text inform each other
On premise deployment
No waiting for conversion between modalities. Speech and text inform each other
Enterprise security
When speech hears emotion and text understands meaning at the same time,
Enterprise security
When speech hears emotion and text understands meaning at the same time,
Enterprise security
When speech hears emotion and text understands meaning at the same time,
The voice AI your team has been waiting for
The voice AI your team has been waiting for
The voice AI your team
has been waiting for
We're choosing our first partners carefully. High-volume teams get in first. Once the first cohort is full, the waitlist closes.
We're choosing our first partners carefully. High-volume teams get in first. Once the first cohort is full, the waitlist closes.

Get Early Access
Get priority access to production-ready,
native speech-to-speech AI.
No spam
SOC 2 Compliant
No credit card
Frequently
asked questions
What makes Hydra different from other voice AI platforms?
What does "full - duplex" mean and why does it matter for my business?
Is Hydra compliant for regulated industries like healthcare and finance?
What industries is Hydra built for?
How do I get access and what does pricing look like?
Ready to leave cascaded AI behind?
311 California Street, Suite 320
San Francisco, CA 94104
Documentation
Initiatives
Ready to leave cascaded AI behind?
311 California Street, Suite 320
San Francisco, CA 94104
Documentation
Initiatives
Ready to leave cascaded AI behind?
311 California Street, Suite 320
San Francisco, CA 94104
Documentation
Initiatives