

Looking for the most efficient and fastest Text-to-Speech APIs in 2026? Our comprehensive guide ranks leading solutions by speed, quality, and features. Find your ideal TTS API today!
Latency is the silent killer of voice experiences. A 500ms delay in a conversation doesn't just feel slow- it feels broken. Users hang up. Developers get blamed. Businesses lose revenue.
As real-time voice AI moves into customer service, conversational agents, IVR systems, and accessibility tools, the performance bar for text-to-speech APIs has never been higher. The best providers in 2025 aren't just fast — they're fast and high-fidelity, a combination that was nearly impossible just two years ago.
This guide breaks down the fastest TTS APIs available today, with verified latency numbers, pricing, and clear guidance on which use case each one is built for.
Why Latency Matters More Than You Think
For most TTS use cases, the metric that matters is Time to First Byte (TTFB) — how quickly the API returns the first audio chunk after receiving text input. For natural conversation, you generally need TTFB under 300ms. Go above that, and users start to notice.
But TTFB alone doesn't tell the full story. Here are the metrics that actually matter in production:
TTFB (Time to First Byte): The primary speed benchmark. Critical for conversational apps and voice agents where silence feels like a failure.
Real-Time Factor (RTF): Measures how fast the model generates audio relative to playback speed. An RTF of 0.3 means the model generates audio 3.3× faster than it plays — leaving ample headroom for real-time streaming without buffer issues.
Streaming protocol support: APIs that support WebSocket or Server-Sent Events (SSE) can start delivering audio before synthesis is complete, which dramatically reduces perceived latency for end users.
Concurrency handling: A TTS API that achieves great latency on a single request but degrades under 20 simultaneous requests isn't ready for production voice infrastructure.
Audio quality under speed: Some APIs achieve low TTFB by sacrificing audio fidelity. In blind listening tests, users consistently prefer natural-sounding audio even at slightly higher latency — so quality can't be an afterthought.
Further reading: For a technical deep-dive into TTFB measurement methodology for voice assistants, the Picovoice TTS Latency Benchmark on GitHub is an excellent open-source reference framework.
The Fastest TTS APIs in 2025
1. Smallest AI — Lightning v3.1
TTFB: ~200ms | RTF: 0.3 | Sample Rate: 44,100 Hz
Lightning v3.1 is the fastest TTS API that doesn't trade quality for speed. In independent blind listening tests across 1,088 samples in English, Hindi, Spanish, and Tamil, Lightning v3.1 was preferred by listeners 76.2% of the time against OpenAI's GPT-4o-mini-TTS — a 3.4× preference ratio. That's not a marketing claim; it's from a structured evaluation using an LLM-as-a-Judge framework on the Seed TTS dataset.
The numbers back it up across every dimension:
Metric | Score | What it means |
WVMOS | 5.06 | Broadcast-quality audio |
Naturalness | 4.33 / 5.0 | Predominantly human-like |
Pronunciation | 4.70 / 5.0 | Near-perfect articulation |
Intonation | 4.71 / 5.0 | Highly expressive pitch variation |
Prosody | 4.47 / 5.0 | Natural conversational rhythm |
Word Error Rate | 6.3% | 93.7% word-level accuracy |
RTF | 0.3 | Generates audio 3.3× faster than playback |
Native sample rate | 44,100 Hz | Highest fidelity in its class |
Architecture built for real-time: Lightning v3.1 supports HTTP, SSE, and WebSocket streaming endpoints, with geo-routed servers across the US (Oregon) and India (Hyderabad) for automatic lowest-latency routing by region.
Voice cloning built in: Instant cloning from just 5–15 seconds of audio for quick replication, and Professional cloning from 45+ minutes of audio for near-perfect voice reproduction — capturing intonation, accent, and emotional nuance.
Languages: Lightning V3.1 supports 15 languages, with more being added regularly. Best in class languages include English, Spanish, Hindi and Tamil. This also includes strong coverage across Europe with French, German, Italian, Portuguese, Swedish, and Dutch, along with Indic support with Hindi, Tamil, Telugu, Malayalam, Kannada, Marathi, and Gujarati.
Pricing: Lightning v3.1 is available on a pay-as-you-go plan at ~$0.25 per 10,000 characters (Pro plan, $9/month). Enterprise plans include custom pricing, on-premise deployment, guaranteed 99.99% uptime SLA, HIPAA zero data retention, and SOC2 compliance.
Plan | Price | Includes |
Free | $0/month | $1 test credits, 2 concurrent requests, basic TTS access |
Pro | $9/month | Lightning v3.1 access, pay-as-you-go at ~$0.25/10k chars, 5 concurrent requests |
Enterprise | Custom | On-prem, custom concurrency, SLA, HIPAA, SOC2, priority support |
Best for: Conversational AI agents, real-time IVR systems, voice-first applications, multilingual deployments, and any use case where audio quality and latency must coexist.
2. Deepgram- Aura-2

TTFB: ~184ms (mean) | Optimized: sub-200ms
Deepgram's Aura-2 is purpose-built for enterprise voice agents, prioritizing reliability and pronunciation accuracy over expressiveness. It handles thousands of concurrent requests with stable, consistent latency — making it a strong candidate for high-throughput, English-language enterprise deployments like contact centers and customer service automation.
Where Aura-2 leads: pronunciation accuracy for numbers, names, technical terms, and structured content. Where it falls short relative to Lightning v3.1: language coverage (7 languages vs. 4 for Smallest AI, though Deepgram's English support is broader) and audio quality — its WVMOS score of 4.64 trails Lightning v3.1's 5.06.
Pricing: Pay-per-character at $0.0135 per 1,000 characters. No subscription required.
Best for: English-language enterprise contact centers and customer service automation where pronunciation accuracy and high concurrency matter more than emotional expressiveness.
Reference: Deepgram's own TTS API comparison guide provides useful technical context on what to evaluate when choosing between providers.
3. OpenAI — TTS (GPT-4o-mini-TTS)

TTFB: ~200ms | Cost: $15 per million characters
OpenAI's TTS API offers clean, consistent audio across 32 languages with a simple pay-as-you-go structure. Its primary advantage is ecosystem integration — if your LLM layer is already running on OpenAI, consolidating your TTS on the same platform eliminates the complexity of managing a multi-vendor stack.
That said, in direct blind testing, Lightning v3.1 was preferred over GPT-4o-mini-TTS 76.2% of the time — a significant gap in audio naturalness that matters for user-facing voice applications.
For teams building full conversational pipelines, OpenAI's Realtime API bundles STT, LLM reasoning, and TTS into a single call — simpler to integrate, but with higher end-to-end latency than a best-in-class standalone TTS API.
Pricing: $15/million characters (standard); $30/million (HD); $0.60/million (Mini input tokens)
Best for: Developers already in the OpenAI ecosystem who prioritize stack simplicity and predictable pay-as-you-go pricing over maximum audio quality.
Reference: Vapi's ElevenLabs vs OpenAI TTS comparison offers an independent developer's perspective on latency and quality trade-offs across providers.
4. Google Cloud TTS

TTFB: ~300–500ms (varies by voice type and region)
Google Cloud TTS has the widest language and voice coverage of any provider in this list — 50+ languages, 220+ voices — and deep integration with Google Cloud Platform infrastructure. For teams with GCP-native stacks or requirements for broad language coverage, it's the pragmatic enterprise choice.
Speed is not its headline feature. WaveNet and Neural2 voices prioritize quality and naturalness over raw latency, putting it outside the sub-300ms range that real-time conversational applications typically require. For batch TTS, audio narration, or non-real-time accessibility tools, those trade-offs are acceptable.
Pricing: $4–$16 per million characters depending on voice type (Standard vs. WaveNet vs. Neural2).
Best for: Applications requiring extensive language coverage, GCP-native teams, or batch TTS workloads where latency is not time-critical.
5. Amazon Polly
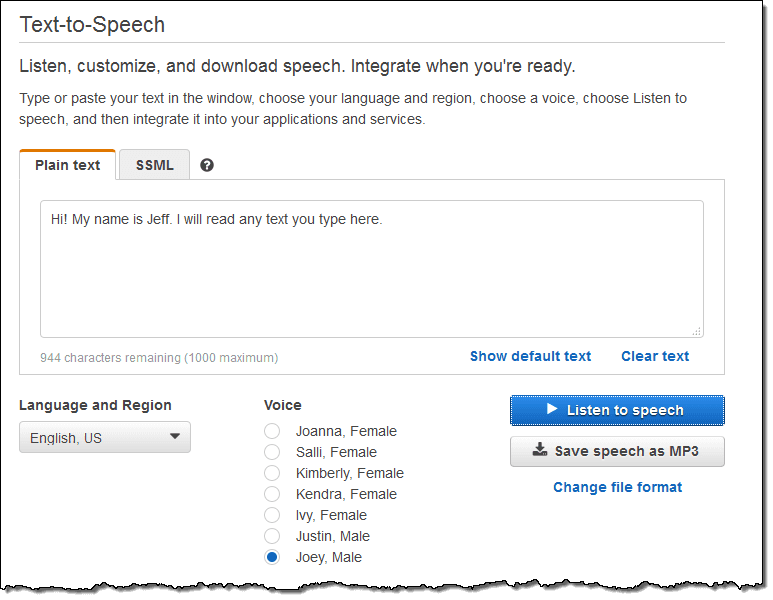
TTFB: ~300ms | Cost: $4 per million characters (Standard)
Amazon Polly is the cost-leader for AWS-native teams running high-volume, non-real-time TTS. It supports 60+ voices across 29 languages, with both standard (concatenative) and neural voice synthesis options. For notification systems, e-learning content, audiobook generation, or any batch-processing pipeline on AWS, Polly's pricing is hard to beat.
For real-time conversational use cases, its latency profile puts it behind the specialized providers in this list. It's not built for sub-300ms interactive applications.
Pricing: $4/million characters (Standard); $16/million (Neural). Free tier: 5 million characters/month for 12 months.
Best for: AWS-native teams running high-volume, cost-sensitive TTS for batch, notification, or non-conversational applications.
Head-to-Head Comparison
Provider | TTFB | RTF | Audio Quality (WVMOS) | Languages | Voice Cloning | Starting Price |
Smallest AI Lightning v3.1 | ~200ms | 0.3 | 5.06 | 15+ | Instant + Pro | $0 (Free tier) |
Deepgram Aura-2 | ~184ms | — | 4.64* | 7 | No | $0.0135/1k chars |
OpenAI TTS | ~200ms | — | — | 32 | No | $15/1M chars |
Google Cloud TTS | ~300–500ms | — | — | 50+ | No | $4/1M chars |
Amazon Polly | ~300ms | — | — | 29 | No | $4/1M chars |
*Deepgram WVMOS sourced from Smallest AI internal benchmarks on Seed TTS evaluation set.
Choosing the Right API for Your Use Case
Building a real-time conversational AI agent or IVR? You need TTFB under 250ms, WebSocket streaming, and audio quality that doesn't undermine user trust. Smallest AI Lightning v3.1 is the clear choice — it matches Deepgram Aura-2 on latency while delivering materially better audio naturalness and built-in voice cloning.
Building on OpenAI's LLM stack? OpenAI TTS simplifies your integration if you're already using GPT models. Be aware of the quality gap in naturalness vs. Lightning v3.1, particularly for user-facing voice applications.
Running high-volume batch TTS on AWS or GCP? Amazon Polly ($4/million characters) and Google Cloud TTS offer the most competitive pricing for non-real-time workloads, with deep cloud platform integration.
Need the widest language coverage possible? Google Cloud TTS (50+ languages) covers the broadest range, though latency rules it out for real-time use. For real-time multilingual deployments, Lightning v3.1 covers English, Hindi, Spanish, and Tamil with voice cloning support across all four.
Regulated industries (healthcare, finance)? Smallest AI Enterprise includes HIPAA zero data retention, SOC2, and on-premise deployment. Deepgram also supports enterprise compliance. Google Cloud and AWS offer enterprise compliance through their respective cloud platforms.
The Bottom Line
The TTS API landscape in 2025 is more competitive than it has ever been — but not all speed claims survive contact with production workloads.
Smallest AI Lightning v3.1 is the only API in this list that combines broadcast-quality audio (WVMOS 5.06, 44.1 kHz native output), an RTF of 0.3, sub-250ms real-time latency, and built-in voice cloning under a single platform. The 76.2% listener preference over GPT-4o-mini-TTS across 1,088 samples makes it the most independently validated choice for developers who can't afford to compromise on either speed or quality.
Smallest Lightning V3.1 is the right call for English-language enterprise contact centers prioritizing pronunciation accuracy and high concurrency. OpenAI TTS wins for teams already invested in the OpenAI stack. Google Cloud TTS and Amazon Polly lead on language breadth and cost-efficiency for batch workloads.
For real-time applications where your users will notice the difference- start with Lightning v3.1.
What is TTFB and why does it matter for TTS?
What is Real-Time Factor (RTF) in TTS?
Can I use TTS APIs for voice cloning?
How do I benchmark TTS APIs before committing?
Is 44,100 Hz sample rate important for TTS?
What compliance certifications should I look for in a TTS API?
How does pricing work for TTS APIs-per character or per minute?

