Voice bot architecture represents the comprehensive, end-to-end system design that connects real-time speech processing (ASR/TTS), conversational orchestration, tool integrations, and telephony control into a cohesive system capable of human-like interactions. As user expectations evolve, the stakes have never been higher; customers demand sub-second response times, enterprises require complete auditability and compliance capabilities , and developers need clear, maintainable patterns to build production systems at scale.
This deep dive explores the foundational components of modern voice bot architecture through the lens of Smallest AI's Atoms SDK.
We'll examine core SDK concepts like AtomsApp and AgentSession coordination, production-ready patterns including multi-node architectures and tool chaining, performance optimizations that enable natural conversation flow, and how smallest.ai's real-time ASR/TTS infrastructure serves as the high-performance foundation for voice experiences that feel genuinely human.
What Is Voice Bot Architecture?
At its core, a voice bot architecture orchestrates a sophisticated flow: audio from a microphone streams through real-time Automatic Speech Recognition (ASR), which feeds transcribed text to an agent orchestration layer where Large Language Models (LLMs) reason about intent and invoke tools as needed, before Text-to-Speech (TTS) synthesis converts the response back into natural audio delivered to the speaker.
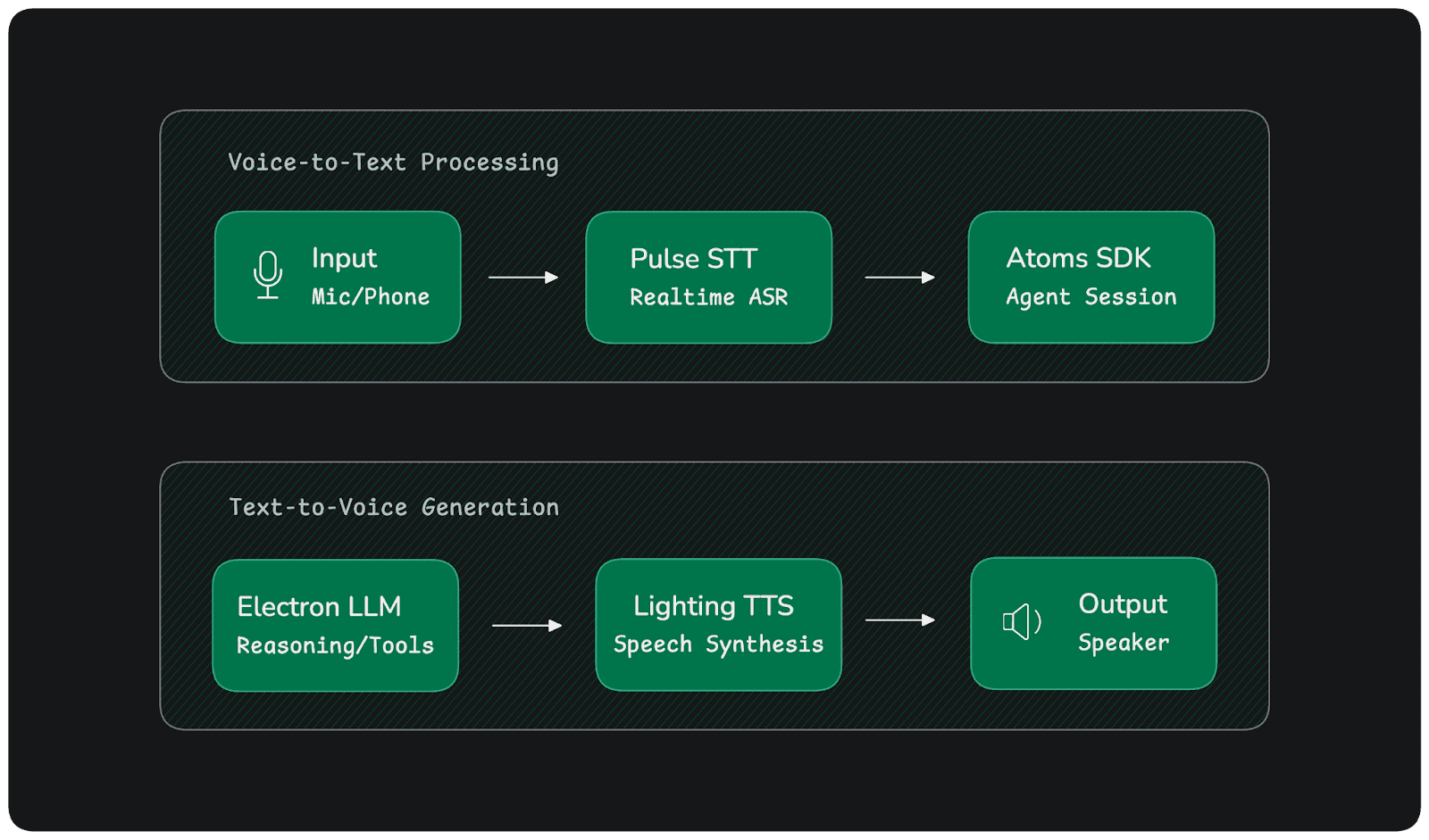
This architecture consists of four critical layers that work in concert:
Speech I/O Layer: Handles bidirectional audio streaming with WebSocket connections for minimal latency
Session & Node Management Layer: Coordinates conversation state, multi-node workflows, and event-driven communication
Tool & Action Layer: Integrates backend systems, databases, and APIs to execute user requests
Observability & Compliance Layer: Provides audit logging, monitoring, and regulatory compliance capabilities
The contrast with traditional Interactive Voice Response (IVR) systems is stark. Where legacy IVR forces users through menu-driven, stateless navigation with hardcoded flows, modern AI voice bots leverage intent-driven understanding, maintain stateful context across the conversation, and employ sophisticated reasoning to adapt dynamically to user needs.
smallest.ai plays a pivotal role in this ecosystem by delivering the high-performance speech infrastructure that makes natural conversation possible. Pulse STT achieves 64ms time-to-first-transcript latency across 32 languages with a 4.5% English Word Error Rate, while Lightning TTS synthesizes studio-grade 44.1kHz audio with just 175ms latency, enabling the sub-800ms end-to-end turn times that define truly conversational AI.
Core Components of a Modern Voice Bot
Real-Time Speech Ingestion (ASR)
Streaming WebSocket ASR forms the foundation of low-latency voice experiences. Rather than waiting for complete utterances, modern ASR systems process audio incrementally, emitting partial transcripts as speech continues and finalizing results upon detecting natural speech boundaries. This approach dramatically reduces perceived latency in the critical window where users decide whether the system is responsive or broken.
Pulse STT exemplifies this streaming architecture with 64ms time-to-first-transcript and support for 32 languages, delivering the accuracy and speed required for production voice systems. For always-on assistants, capabilities like wake-word detection and intelligent endpointing ensure the system activates only when needed and accurately determines when users have finished speaking.
Agent Orchestration Layer
The Atoms SDK structures voice bot logic around three fundamental primitives: AtomsApp, AgentSession, and Nodes. This design enables clean separation of concerns while maintaining the tight coordination required for real-time conversation.
Here's a minimal example showing the AtomsApp lifecycle and setup_handler pattern:
import os
from smallestai.atoms.agent.nodes import OutputAgentNode
from smallestai.atoms.agent.clients.openai import OpenAIClient
from smallestai.atoms.agent.server import AtomsApp
from smallestai.atoms.agent.session import AgentSession
from smallestai.atoms.agent.events import SDKSystemUserJoinedEvent
class MyAgent(OutputAgentNode):
def __init__(self):
super().__init__(name="my-agent")
self.llm = OpenAIClient(
model="gpt-4o-mini",
api_key=os.getenv("OPENAI_API_KEY")
)
self.context.add_message({
"role": "system",
"content": "You are a helpful assistant. Be concise and friendly."
})
async def generate_response(self):
response = await self.llm.chat(
messages=self.context.messages,
stream=True
)
full_response = ""
async for chunk in response:
if chunk.content:
full_response += chunk.content
yield chunk.content
if full_response:
self.context.add_message({"role": "assistant", "content": full_response})
async def on_start(session: AgentSession):
agent = MyAgent()
session.add_node(agent)
await session.start()
await session.wait_until_complete()
if __name__ == "__main__":
app = AtomsApp(setup_handler=on_start)
app.run()import os
from smallestai.atoms.agent.nodes import OutputAgentNode
from smallestai.atoms.agent.clients.openai import OpenAIClient
from smallestai.atoms.agent.server import AtomsApp
from smallestai.atoms.agent.session import AgentSession
from smallestai.atoms.agent.events import SDKSystemUserJoinedEvent
class MyAgent(OutputAgentNode):
def __init__(self):
super().__init__(name="my-agent")
self.llm = OpenAIClient(
model="gpt-4o-mini",
api_key=os.getenv("OPENAI_API_KEY")
)
self.context.add_message({
"role": "system",
"content": "You are a helpful assistant. Be concise and friendly."
})
async def generate_response(self):
response = await self.llm.chat(
messages=self.context.messages,
stream=True
)
full_response = ""
async for chunk in response:
if chunk.content:
full_response += chunk.content
yield chunk.content
if full_response:
self.context.add_message({"role": "assistant", "content": full_response})
async def on_start(session: AgentSession):
agent = MyAgent()
session.add_node(agent)
await session.start()
await session.wait_until_complete()
if __name__ == "__main__":
app = AtomsApp(setup_handler=on_start)
app.run()import os
from smallestai.atoms.agent.nodes import OutputAgentNode
from smallestai.atoms.agent.clients.openai import OpenAIClient
from smallestai.atoms.agent.server import AtomsApp
from smallestai.atoms.agent.session import AgentSession
from smallestai.atoms.agent.events import SDKSystemUserJoinedEvent
class MyAgent(OutputAgentNode):
def __init__(self):
super().__init__(name="my-agent")
self.llm = OpenAIClient(
model="gpt-4o-mini",
api_key=os.getenv("OPENAI_API_KEY")
)
self.context.add_message({
"role": "system",
"content": "You are a helpful assistant. Be concise and friendly."
})
async def generate_response(self):
response = await self.llm.chat(
messages=self.context.messages,
stream=True
)
full_response = ""
async for chunk in response:
if chunk.content:
full_response += chunk.content
yield chunk.content
if full_response:
self.context.add_message({"role": "assistant", "content": full_response})
async def on_start(session: AgentSession):
agent = MyAgent()
session.add_node(agent)
await session.start()
await session.wait_until_complete()
if __name__ == "__main__":
app = AtomsApp(setup_handler=on_start)
app.run()Output:
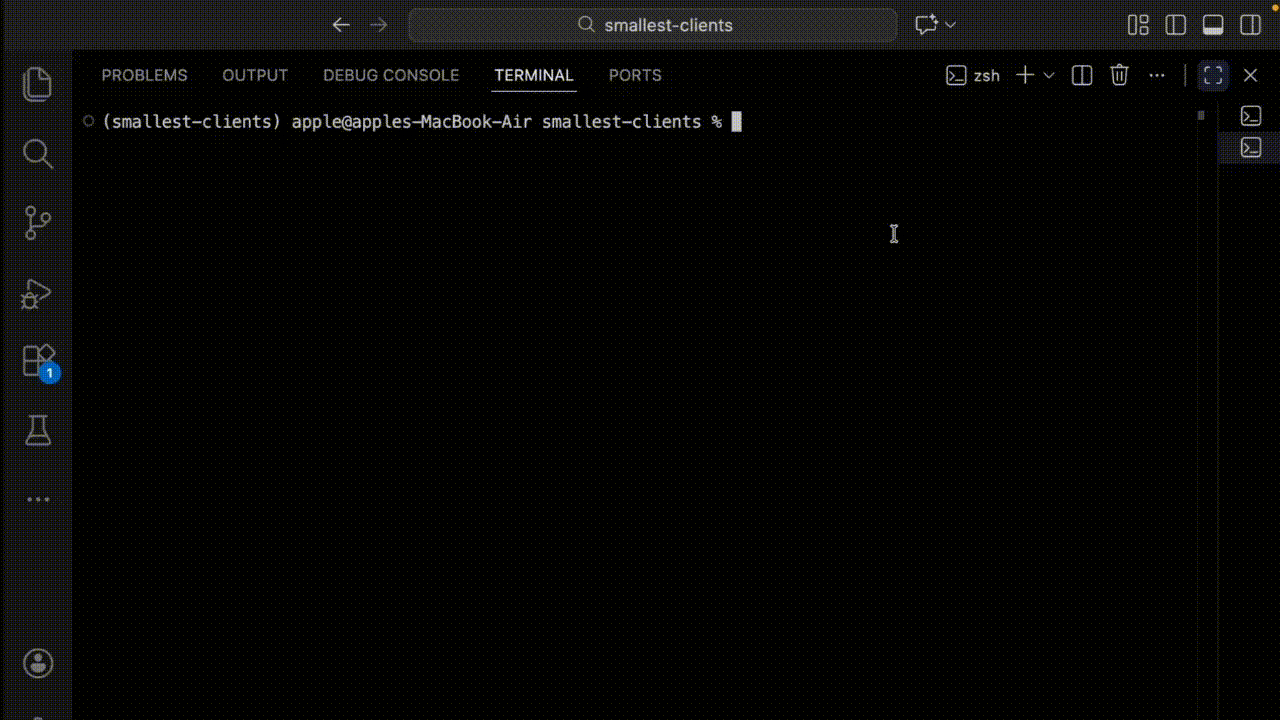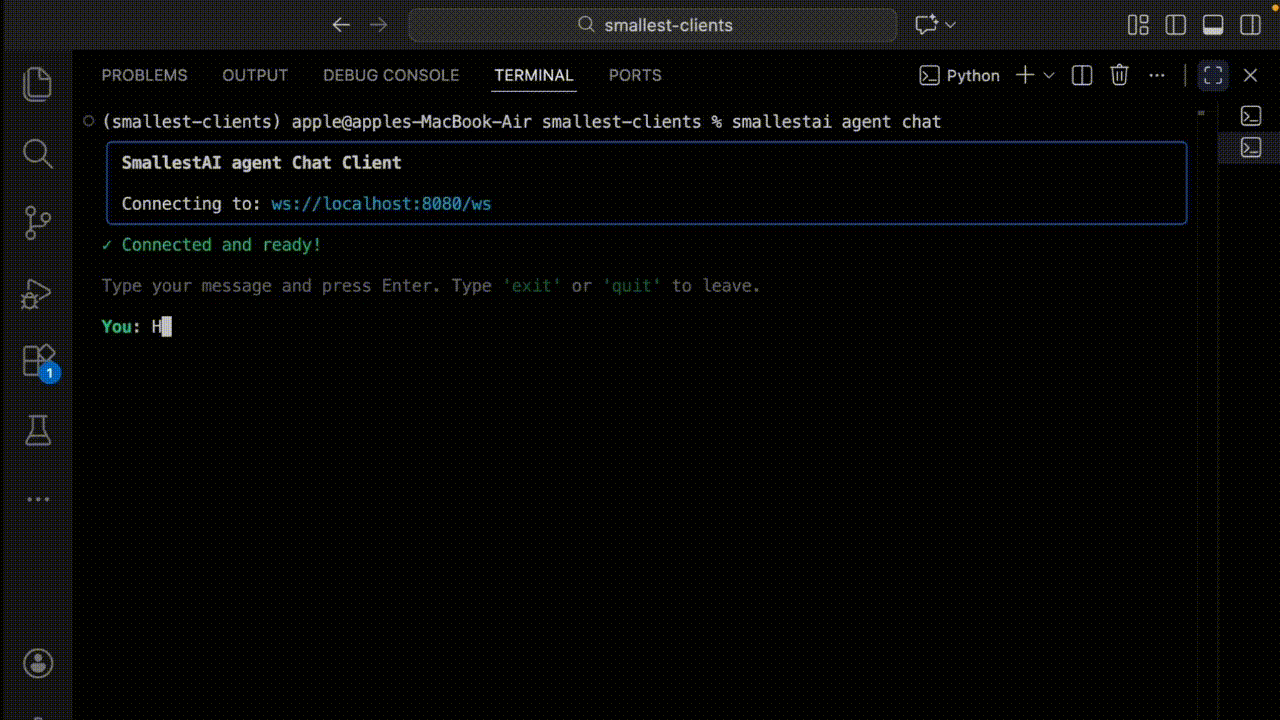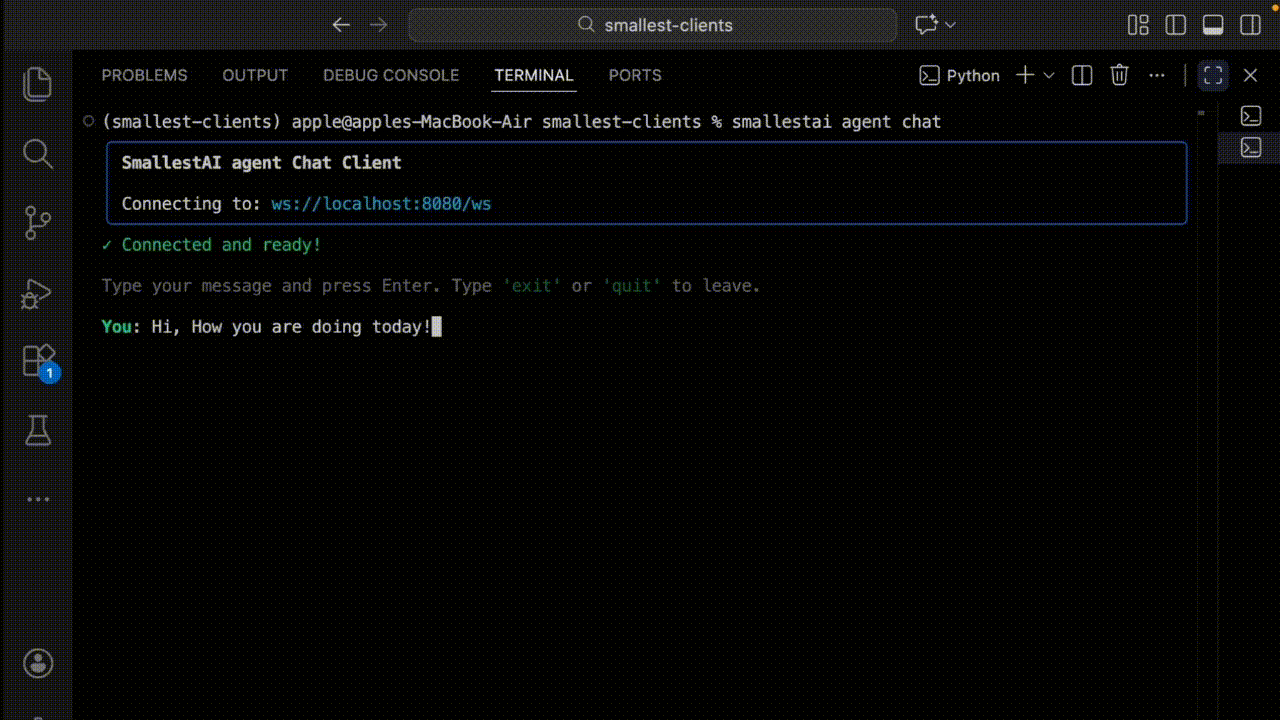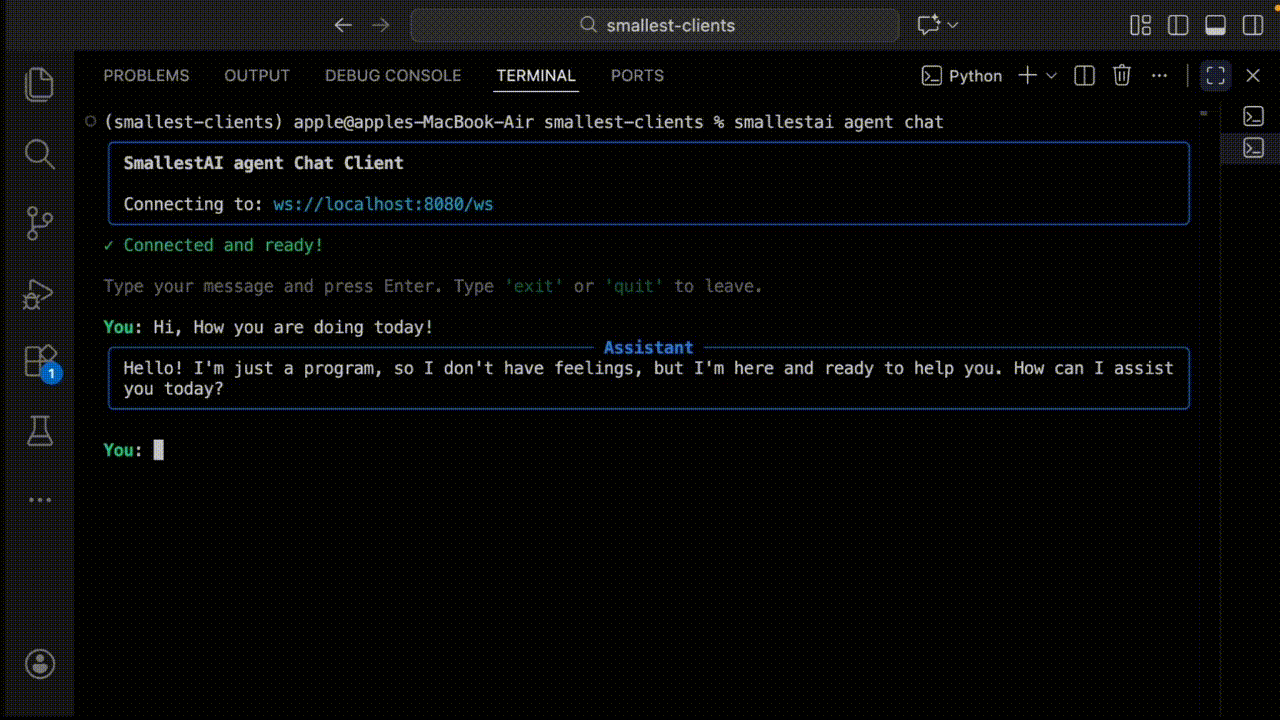
The AgentSession acts as the runtime container, managing WebSocket connections, event dispatch, and node lifecycle, for a detailed overview checkout quickstart guide.
Each session creates a sandbox that ensures total isolation, variables and state from one conversation never leak to another.
Nodes represent the functional building blocks. OutputAgentNode handles conversational interactions, streaming LLM responses to users while managing context and state. BackgroundAgentNode processes events silently in parallel, perfect for audit logging, sentiment analysis, or real-time monitoring without impacting conversation latency.
Conversational Flow and Tool Execution
Real-world voice bots must bridge conversation with action. The Atoms SDK's tool system uses a decorator pattern with automatic discovery, making it straightforward to expose Python functions as callable tools for LLMs:
import os
from smallestai.atoms.agent.nodes import OutputAgentNode
from smallestai.atoms.agent.clients import OpenAIClient
from smallestai.atoms.agent.server import AtomsApp
from smallestai.atoms.agent.session import AgentSession
from smallestai.atoms.agent.tools import ToolRegistry, function_tool
from smallestai.atoms.agent.clients.types import ToolCall, ToolResult
class AssistantAgent(OutputAgentNode):
def __init__(self):
super().__init__(name="assistant-agent")
self.llm = OpenAIClient(model="gpt-4o-mini", api_key=os.getenv("OPENAI_API_KEY"))
self.tool_registry = ToolRegistry()
self.tool_registry.discover(self)
self.tool_schemas = self.tool_registry.get_schemas()
self.context.add_message({ # added
"role": "system",
"content": "You are a helpful weather assistant. Be concise."
})
@function_tool()
def get_weather(self, city: str) -> str:
"""Get the current weather for a city.
Args:
city: The city name to check weather for.
"""
return f"The weather in {city} is sunny, 72°F"
async def generate_response(self):
response = await self.llm.chat(
messages=self.context.messages,
stream=True,
tools=self.tool_schemas
)
tool_calls = []
full_response = ""
async for chunk in response:
if chunk.content:
full_response += chunk.content
yield chunk.content
if chunk.tool_calls:
tool_calls.extend(chunk.tool_calls)
if not tool_calls: # added
self.context.add_message({"role": "assistant", "content": full_response})
return
yield "One moment while I check that for you. "
results = await self.tool_registry.execute(tool_calls=tool_calls, parallel=True)
self.context.add_messages([ # added
{
"role": "assistant",
"content": "",
"tool_calls": [
{"id": tc.id, "type": "function",
"function": {"name": tc.name, "arguments": str(tc.arguments)}}
for tc in tool_calls
],
},
*[
{"role": "tool", "tool_call_id": tc.id, "content": str(result.content or "")}
for tc, result in zip(tool_calls, results)
],
])
final_response = await self.llm.chat(messages=self.context.messages, stream=True) # added
final_text = ""
async for chunk in final_response:
if chunk.content:
final_text += chunk.content
yield chunk.content
self.context.add_message({"role": "assistant", "content": final_text})
async def on_start(session: AgentSession):
agent = AssistantAgent() # fixed: was MyAgent()
session.add_node(agent)
await session.start()
await session.wait_until_complete()
if __name__ == "__main__":
app = AtomsApp(setup_handler=on_start)
app.run()import os
from smallestai.atoms.agent.nodes import OutputAgentNode
from smallestai.atoms.agent.clients import OpenAIClient
from smallestai.atoms.agent.server import AtomsApp
from smallestai.atoms.agent.session import AgentSession
from smallestai.atoms.agent.tools import ToolRegistry, function_tool
from smallestai.atoms.agent.clients.types import ToolCall, ToolResult
class AssistantAgent(OutputAgentNode):
def __init__(self):
super().__init__(name="assistant-agent")
self.llm = OpenAIClient(model="gpt-4o-mini", api_key=os.getenv("OPENAI_API_KEY"))
self.tool_registry = ToolRegistry()
self.tool_registry.discover(self)
self.tool_schemas = self.tool_registry.get_schemas()
self.context.add_message({ # added
"role": "system",
"content": "You are a helpful weather assistant. Be concise."
})
@function_tool()
def get_weather(self, city: str) -> str:
"""Get the current weather for a city.
Args:
city: The city name to check weather for.
"""
return f"The weather in {city} is sunny, 72°F"
async def generate_response(self):
response = await self.llm.chat(
messages=self.context.messages,
stream=True,
tools=self.tool_schemas
)
tool_calls = []
full_response = ""
async for chunk in response:
if chunk.content:
full_response += chunk.content
yield chunk.content
if chunk.tool_calls:
tool_calls.extend(chunk.tool_calls)
if not tool_calls: # added
self.context.add_message({"role": "assistant", "content": full_response})
return
yield "One moment while I check that for you. "
results = await self.tool_registry.execute(tool_calls=tool_calls, parallel=True)
self.context.add_messages([ # added
{
"role": "assistant",
"content": "",
"tool_calls": [
{"id": tc.id, "type": "function",
"function": {"name": tc.name, "arguments": str(tc.arguments)}}
for tc in tool_calls
],
},
*[
{"role": "tool", "tool_call_id": tc.id, "content": str(result.content or "")}
for tc, result in zip(tool_calls, results)
],
])
final_response = await self.llm.chat(messages=self.context.messages, stream=True) # added
final_text = ""
async for chunk in final_response:
if chunk.content:
final_text += chunk.content
yield chunk.content
self.context.add_message({"role": "assistant", "content": final_text})
async def on_start(session: AgentSession):
agent = AssistantAgent() # fixed: was MyAgent()
session.add_node(agent)
await session.start()
await session.wait_until_complete()
if __name__ == "__main__":
app = AtomsApp(setup_handler=on_start)
app.run()import os
from smallestai.atoms.agent.nodes import OutputAgentNode
from smallestai.atoms.agent.clients import OpenAIClient
from smallestai.atoms.agent.server import AtomsApp
from smallestai.atoms.agent.session import AgentSession
from smallestai.atoms.agent.tools import ToolRegistry, function_tool
from smallestai.atoms.agent.clients.types import ToolCall, ToolResult
class AssistantAgent(OutputAgentNode):
def __init__(self):
super().__init__(name="assistant-agent")
self.llm = OpenAIClient(model="gpt-4o-mini", api_key=os.getenv("OPENAI_API_KEY"))
self.tool_registry = ToolRegistry()
self.tool_registry.discover(self)
self.tool_schemas = self.tool_registry.get_schemas()
self.context.add_message({ # added
"role": "system",
"content": "You are a helpful weather assistant. Be concise."
})
@function_tool()
def get_weather(self, city: str) -> str:
"""Get the current weather for a city.
Args:
city: The city name to check weather for.
"""
return f"The weather in {city} is sunny, 72°F"
async def generate_response(self):
response = await self.llm.chat(
messages=self.context.messages,
stream=True,
tools=self.tool_schemas
)
tool_calls = []
full_response = ""
async for chunk in response:
if chunk.content:
full_response += chunk.content
yield chunk.content
if chunk.tool_calls:
tool_calls.extend(chunk.tool_calls)
if not tool_calls: # added
self.context.add_message({"role": "assistant", "content": full_response})
return
yield "One moment while I check that for you. "
results = await self.tool_registry.execute(tool_calls=tool_calls, parallel=True)
self.context.add_messages([ # added
{
"role": "assistant",
"content": "",
"tool_calls": [
{"id": tc.id, "type": "function",
"function": {"name": tc.name, "arguments": str(tc.arguments)}}
for tc in tool_calls
],
},
*[
{"role": "tool", "tool_call_id": tc.id, "content": str(result.content or "")}
for tc, result in zip(tool_calls, results)
],
])
final_response = await self.llm.chat(messages=self.context.messages, stream=True) # added
final_text = ""
async for chunk in final_response:
if chunk.content:
final_text += chunk.content
yield chunk.content
self.context.add_message({"role": "assistant", "content": final_text})
async def on_start(session: AgentSession):
agent = AssistantAgent() # fixed: was MyAgent()
session.add_node(agent)
await session.start()
await session.wait_until_complete()
if __name__ == "__main__":
app = AtomsApp(setup_handler=on_start)
app.run()
Output:
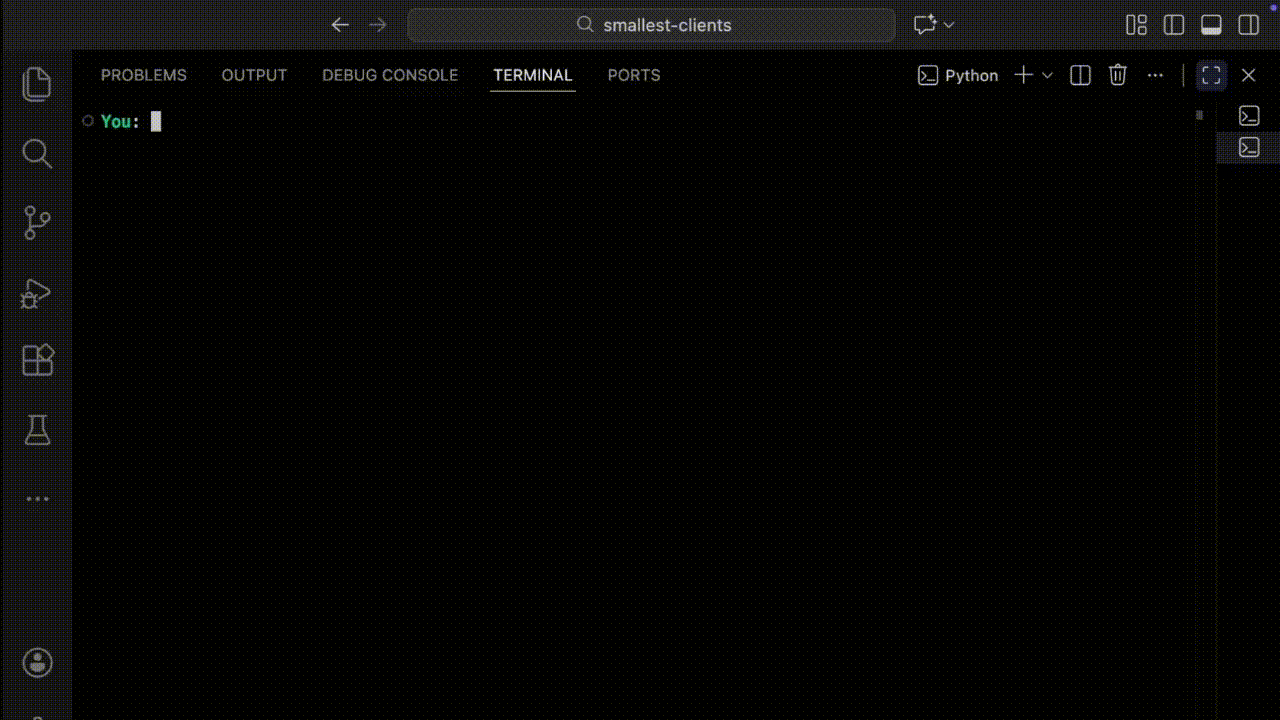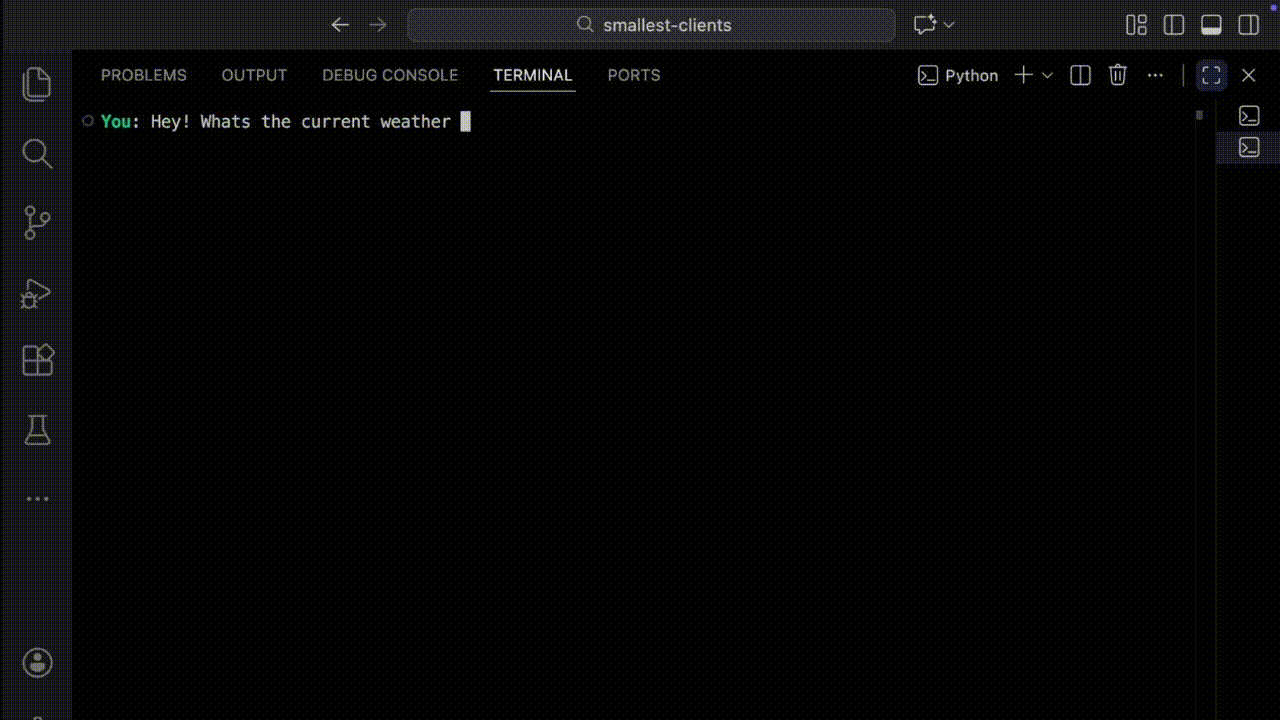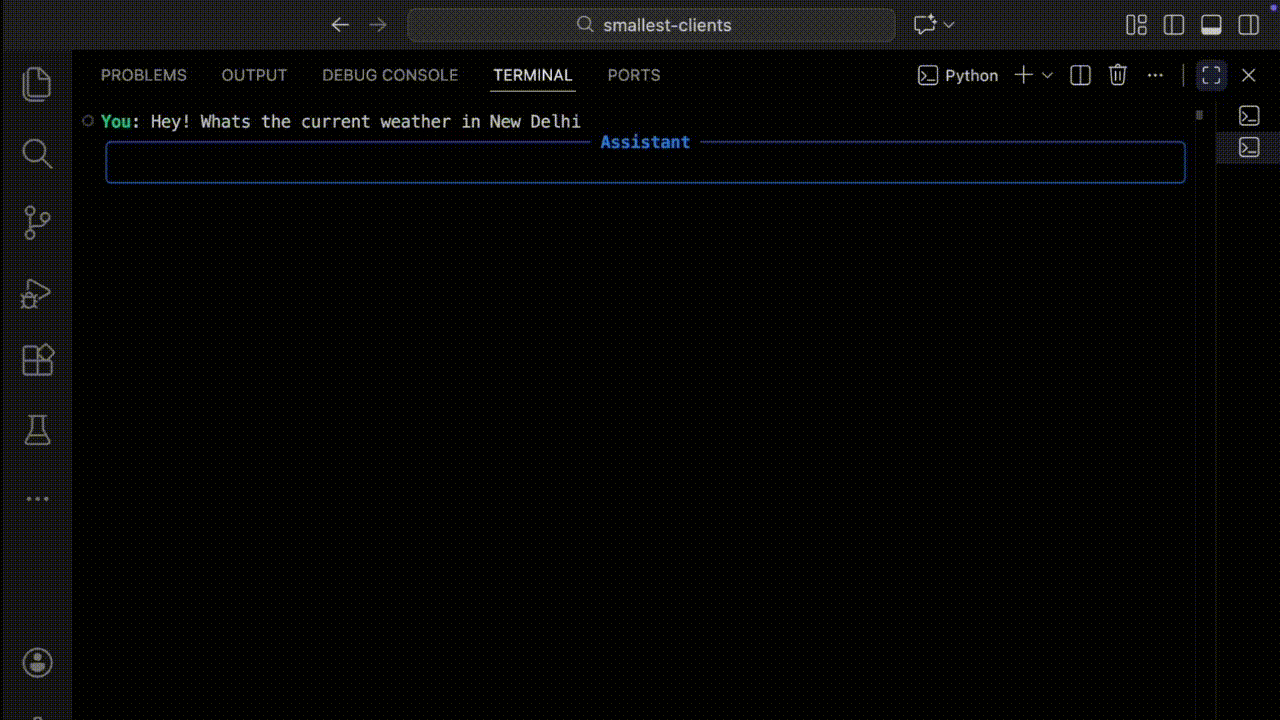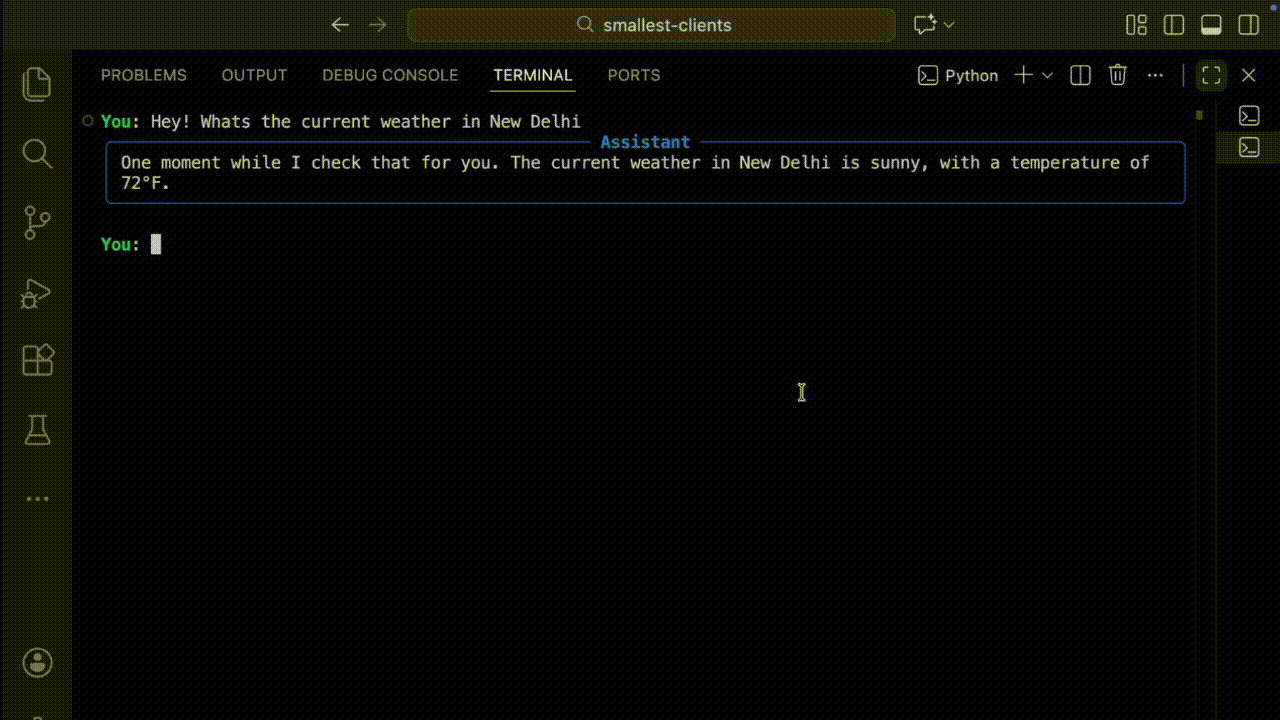
The Weather Agent example demonstrates the core tool execution loop where the agent handles a complete request cycle: receiving a natural language query, selecting the right tool, executing it, and synthesizing the result into a conversational response — all within a single turn. For example, a user asking "What's the weather in New Delhi?" triggers a lookup → response chain that fetches current conditions and presents them naturally, without the user ever knowing a tool was called.
Speech Output (TTS)
Streaming TTS synthesis reduces perceived latency by beginning audio playback before the complete response finishes generating. Lightning TTS delivers this capability with 175ms latency and studio-grade 44kHz output quality across multiple voice options.
The key optimization technique involves dynamic text splitting—breaking LLM output into sentence-level chunks and streaming each to TTS immediately rather than waiting for the full response. This creates the perception of real-time synthesis even as generation continues in the background.
Production Patterns and Best Practices
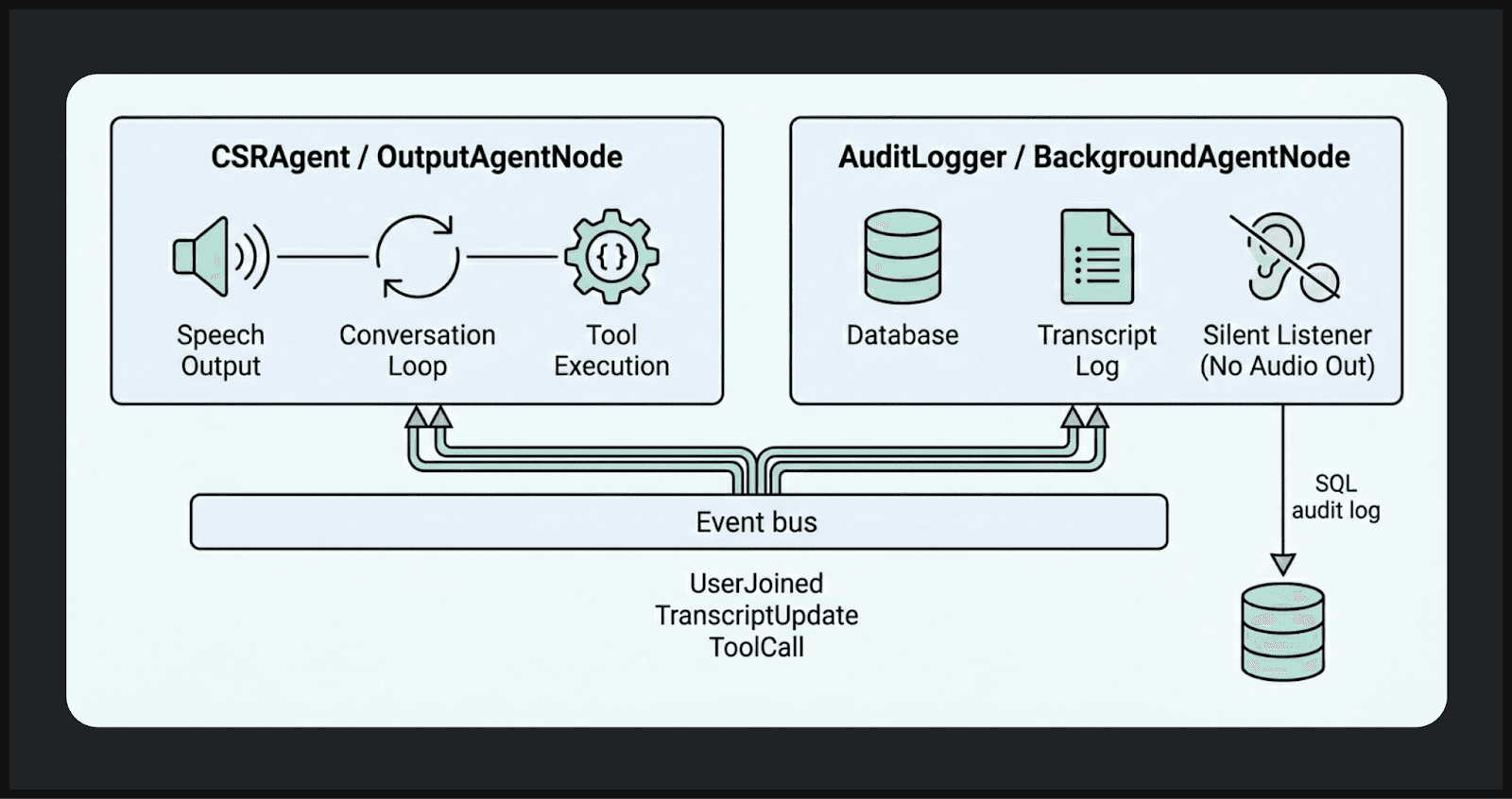
Multi-Node Architectures for Compliance and Observability
Production voice systems demand comprehensive audit trails without sacrificing conversational performance. The dual-node pattern achieves this by running a silent BackgroundAgentNode in parallel with the conversational agent, logging every event, tool call, and state change to a compliance database:
from smallestai.atoms.agent.nodes import BackgroundAgentNode
from smallestai.atoms.agent.events import SDKEvent, SDKAgentTranscriptUpdateEvent, SDKSystemUserJoinedEvent
class AuditLogger(BackgroundAgentNode):
def __init__(self, db):
super().__init__(name="audit-logger")
self.db = db
self._call_start = None
self._transcript = []
async def process_event(self, event: SDKEvent):
if isinstance(event, SDKSystemUserJoinedEvent):
self._call_start = datetime.utcnow().isoformat()
self.db.log_audit("CALL_START", json.dumps({"timestamp": self._call_start}))
elif isinstance(event, SDKAgentTranscriptUpdateEvent):
entry = {"role": event.role, "content": event.content}
self._transcript.append(entry)
self.db.log_audit("TRANSCRIPT", json.dumps(entry))
def log_tool_call(self, tool_name: str, args: dict, result: str):
self.db.log_audit("TOOL_CALL", json.dumps({
"tool": tool_name,
"arguments": args,
"result_preview": result[:500] if result else ""
}))
async def setup_session(session: AgentSession):
db = BankingDB()
# Background audit logger -- silent compliance node
audit = AuditLogger(db=db)
session.add_node(audit)
# Main conversational agent
csr = CSRAgent(db=db, audit=audit)
session.add_node(csr)
await session.start()from smallestai.atoms.agent.nodes import BackgroundAgentNode
from smallestai.atoms.agent.events import SDKEvent, SDKAgentTranscriptUpdateEvent, SDKSystemUserJoinedEvent
class AuditLogger(BackgroundAgentNode):
def __init__(self, db):
super().__init__(name="audit-logger")
self.db = db
self._call_start = None
self._transcript = []
async def process_event(self, event: SDKEvent):
if isinstance(event, SDKSystemUserJoinedEvent):
self._call_start = datetime.utcnow().isoformat()
self.db.log_audit("CALL_START", json.dumps({"timestamp": self._call_start}))
elif isinstance(event, SDKAgentTranscriptUpdateEvent):
entry = {"role": event.role, "content": event.content}
self._transcript.append(entry)
self.db.log_audit("TRANSCRIPT", json.dumps(entry))
def log_tool_call(self, tool_name: str, args: dict, result: str):
self.db.log_audit("TOOL_CALL", json.dumps({
"tool": tool_name,
"arguments": args,
"result_preview": result[:500] if result else ""
}))
async def setup_session(session: AgentSession):
db = BankingDB()
# Background audit logger -- silent compliance node
audit = AuditLogger(db=db)
session.add_node(audit)
# Main conversational agent
csr = CSRAgent(db=db, audit=audit)
session.add_node(csr)
await session.start()from smallestai.atoms.agent.nodes import BackgroundAgentNode
from smallestai.atoms.agent.events import SDKEvent, SDKAgentTranscriptUpdateEvent, SDKSystemUserJoinedEvent
class AuditLogger(BackgroundAgentNode):
def __init__(self, db):
super().__init__(name="audit-logger")
self.db = db
self._call_start = None
self._transcript = []
async def process_event(self, event: SDKEvent):
if isinstance(event, SDKSystemUserJoinedEvent):
self._call_start = datetime.utcnow().isoformat()
self.db.log_audit("CALL_START", json.dumps({"timestamp": self._call_start}))
elif isinstance(event, SDKAgentTranscriptUpdateEvent):
entry = {"role": event.role, "content": event.content}
self._transcript.append(entry)
self.db.log_audit("TRANSCRIPT", json.dumps(entry))
def log_tool_call(self, tool_name: str, args: dict, result: str):
self.db.log_audit("TOOL_CALL", json.dumps({
"tool": tool_name,
"arguments": args,
"result_preview": result[:500] if result else ""
}))
async def setup_session(session: AgentSession):
db = BankingDB()
# Background audit logger -- silent compliance node
audit = AuditLogger(db=db)
session.add_node(audit)
# Main conversational agent
csr = CSRAgent(db=db, audit=audit)
session.add_node(csr)
await session.start()Both nodes receive identical event streams but serve distinct purposes: the CSRAgent handles conversation while the AuditLogger silently records everything for compliance, analytics, and training data generation. Because the background node operates asynchronously, it introduces zero latency to user-facing interactions .
Identity Verification and Guardrails
Banking voice agents must authenticate users before exposing sensitive information. The Knowledge-Based Authentication (KBA) pattern implements tiered access control with session-based verification state:
@function_tool()
def verify_customer(
self,
name: str = "",
dob: str = "",
account_last_four: str = "",
city: str = "",
debit_card_last_four: str = ""
) -> str:
"""Verify customer identity using Knowledge-Based Authentication.
Level 1 (info queries): 2 matching factors
Level 2 (banking actions): 3 matching factors
Args:
name: Customer's full name
dob: Date of birth (YYYY-MM-DD)
account_last_four: Last 4 digits of savings account
city: City from address
debit_card_last_four: Last 4 digits of debit card
"""
if self.is_verified:
return f"Customer already verified at Level {self.verification_level}"
# Fetch ground truth from database
row = self.db.execute_read_query(
"SELECT c.name, c.dob, c.city, a.account_number, ca.last_four AS debit_last_four "
"FROM customers c JOIN accounts a ON a.customer_id = c.id "
"JOIN cards ca ON ca.customer_id = c.id WHERE ca.type = 'debit'"
)
truth = row[0]
factors_matched = []
if name and name.strip().lower() == truth["name"].strip().lower():
factors_matched.append("name")
if dob and dob.strip() == truth["dob"]:
factors_matched.append("dob")
if account_last_four and account_last_four.strip() == truth["account_number"][-4:]:
factors_matched.append("account_last_four")
# ... additional factor checking
n = len(factors_matched)
if n >= 3:
self.is_verified = True
self.verification_level = 2
return "Level 2 verification successful -- high-risk actions allowed"
elif n >= 2:
self.is_verified = True
self.verification_level = 1
return "Level 1 verification successful -- info queries allowed"
else:
return "Verification failed -- insufficient matching factors"@function_tool()
def verify_customer(
self,
name: str = "",
dob: str = "",
account_last_four: str = "",
city: str = "",
debit_card_last_four: str = ""
) -> str:
"""Verify customer identity using Knowledge-Based Authentication.
Level 1 (info queries): 2 matching factors
Level 2 (banking actions): 3 matching factors
Args:
name: Customer's full name
dob: Date of birth (YYYY-MM-DD)
account_last_four: Last 4 digits of savings account
city: City from address
debit_card_last_four: Last 4 digits of debit card
"""
if self.is_verified:
return f"Customer already verified at Level {self.verification_level}"
# Fetch ground truth from database
row = self.db.execute_read_query(
"SELECT c.name, c.dob, c.city, a.account_number, ca.last_four AS debit_last_four "
"FROM customers c JOIN accounts a ON a.customer_id = c.id "
"JOIN cards ca ON ca.customer_id = c.id WHERE ca.type = 'debit'"
)
truth = row[0]
factors_matched = []
if name and name.strip().lower() == truth["name"].strip().lower():
factors_matched.append("name")
if dob and dob.strip() == truth["dob"]:
factors_matched.append("dob")
if account_last_four and account_last_four.strip() == truth["account_number"][-4:]:
factors_matched.append("account_last_four")
# ... additional factor checking
n = len(factors_matched)
if n >= 3:
self.is_verified = True
self.verification_level = 2
return "Level 2 verification successful -- high-risk actions allowed"
elif n >= 2:
self.is_verified = True
self.verification_level = 1
return "Level 1 verification successful -- info queries allowed"
else:
return "Verification failed -- insufficient matching factors"@function_tool()
def verify_customer(
self,
name: str = "",
dob: str = "",
account_last_four: str = "",
city: str = "",
debit_card_last_four: str = ""
) -> str:
"""Verify customer identity using Knowledge-Based Authentication.
Level 1 (info queries): 2 matching factors
Level 2 (banking actions): 3 matching factors
Args:
name: Customer's full name
dob: Date of birth (YYYY-MM-DD)
account_last_four: Last 4 digits of savings account
city: City from address
debit_card_last_four: Last 4 digits of debit card
"""
if self.is_verified:
return f"Customer already verified at Level {self.verification_level}"
# Fetch ground truth from database
row = self.db.execute_read_query(
"SELECT c.name, c.dob, c.city, a.account_number, ca.last_four AS debit_last_four "
"FROM customers c JOIN accounts a ON a.customer_id = c.id "
"JOIN cards ca ON ca.customer_id = c.id WHERE ca.type = 'debit'"
)
truth = row[0]
factors_matched = []
if name and name.strip().lower() == truth["name"].strip().lower():
factors_matched.append("name")
if dob and dob.strip() == truth["dob"]:
factors_matched.append("dob")
if account_last_four and account_last_four.strip() == truth["account_number"][-4:]:
factors_matched.append("account_last_four")
# ... additional factor checking
n = len(factors_matched)
if n >= 3:
self.is_verified = True
self.verification_level = 2
return "Level 2 verification successful -- high-risk actions allowed"
elif n >= 2:
self.is_verified = True
self.verification_level = 1
return "Level 1 verification successful -- info queries allowed"
else:
return "Verification failed -- insufficient matching factors"
This approach verifies once per session, maintaining state across turns so users don't face repeated authentication challenges. Level 1 access enables balance queries and spending analysis; Level 2 permits transactions like breaking fixed deposits .
Call Control and Escalation
Voice bots must handle escalations gracefully. The Atoms SDK provides structured events for ending calls and transferring to human agents with full context preservation:
from smallestai.atoms.agent.events import (
SDKAgentEndCallEvent,
SDKAgentTransferConversationEvent,
TransferOption,
TransferOptionType,
WarmTransferPrivateHandoffOption,
WarmTransferHandoffOptionType
)
@function_tool()
async def transfer_to_human_agent(self) -> None:
"""Cold transfer: immediate handoff to human agent."""
await self.send_event(
SDKAgentTransferConversationEvent(
transfer_call_number=os.getenv("TRANSFER_NUMBER"),
transfer_options=TransferOption(
type=TransferOptionType.COLD_TRANSFER
),
on_hold_music="relaxing_sound"
)
)
return None
@function_tool()
async def warm_transfer_to_supervisor(self, reason: str) -> None:
"""Warm transfer: brief supervisor first, then connect customer.
Args:
reason: Summary of customer issue for supervisor briefing
"""
await self.send_event(
SDKAgentTransferConversationEvent(
transfer_call_number=os.getenv("TRANSFER_NUMBER"),
transfer_options=TransferOption(
type=TransferOptionType.WARM_TRANSFER,
private_handoff_option=WarmTransferPrivateHandoffOption(
type=WarmTransferHandoffOptionType.PROMPT,
prompt=f"Customer escalation: {reason}"
)
),
on_hold_music="uplifting_beats"
)
)
return Nonefrom smallestai.atoms.agent.events import (
SDKAgentEndCallEvent,
SDKAgentTransferConversationEvent,
TransferOption,
TransferOptionType,
WarmTransferPrivateHandoffOption,
WarmTransferHandoffOptionType
)
@function_tool()
async def transfer_to_human_agent(self) -> None:
"""Cold transfer: immediate handoff to human agent."""
await self.send_event(
SDKAgentTransferConversationEvent(
transfer_call_number=os.getenv("TRANSFER_NUMBER"),
transfer_options=TransferOption(
type=TransferOptionType.COLD_TRANSFER
),
on_hold_music="relaxing_sound"
)
)
return None
@function_tool()
async def warm_transfer_to_supervisor(self, reason: str) -> None:
"""Warm transfer: brief supervisor first, then connect customer.
Args:
reason: Summary of customer issue for supervisor briefing
"""
await self.send_event(
SDKAgentTransferConversationEvent(
transfer_call_number=os.getenv("TRANSFER_NUMBER"),
transfer_options=TransferOption(
type=TransferOptionType.WARM_TRANSFER,
private_handoff_option=WarmTransferPrivateHandoffOption(
type=WarmTransferHandoffOptionType.PROMPT,
prompt=f"Customer escalation: {reason}"
)
),
on_hold_music="uplifting_beats"
)
)
return Nonefrom smallestai.atoms.agent.events import (
SDKAgentEndCallEvent,
SDKAgentTransferConversationEvent,
TransferOption,
TransferOptionType,
WarmTransferPrivateHandoffOption,
WarmTransferHandoffOptionType
)
@function_tool()
async def transfer_to_human_agent(self) -> None:
"""Cold transfer: immediate handoff to human agent."""
await self.send_event(
SDKAgentTransferConversationEvent(
transfer_call_number=os.getenv("TRANSFER_NUMBER"),
transfer_options=TransferOption(
type=TransferOptionType.COLD_TRANSFER
),
on_hold_music="relaxing_sound"
)
)
return None
@function_tool()
async def warm_transfer_to_supervisor(self, reason: str) -> None:
"""Warm transfer: brief supervisor first, then connect customer.
Args:
reason: Summary of customer issue for supervisor briefing
"""
await self.send_event(
SDKAgentTransferConversationEvent(
transfer_call_number=os.getenv("TRANSFER_NUMBER"),
transfer_options=TransferOption(
type=TransferOptionType.WARM_TRANSFER,
private_handoff_option=WarmTransferPrivateHandoffOption(
type=WarmTransferHandoffOptionType.PROMPT,
prompt=f"Customer escalation: {reason}"
)
),
on_hold_music="uplifting_beats"
)
)
return None
Cold transfers immediately connect users to agents—ideal for straightforward handoffs. Warm transfers brief the receiving agent with context before connecting the customer, enabling seamless continuity for complex issues .
Performance and Latency Optimization
Achieving sub-second conversational latency requires streaming throughout the entire pipeline. Each component must process data incrementally rather than in batch mode: ASR streams partial transcripts, the LLM streams token-by-token responses, and TTS synthesizes sentence-level chunks on-the-fly.
The intermediate feedback pattern maintains engagement during tool execution. When calling external APIs or databases, the agent yields acknowledgment phrases like "One moment while I check that for you" before invoking tools. This prevents awkward silence and signals system responsiveness even as backend operations complete .
smallest.ai's infrastructure enables these optimizations with Pulse STT delivering 64ms first-transcript latency and Lightning TTS achieving 175ms synthesis time. Combined with efficient orchestration, total turn times under 800ms become achievable—the threshold where conversations feel truly natural.
Real-World Use Cases
Banking Voice Agent (Bank CSR)
The Bank CSR example demonstrates enterprise-grade voice AI handling complex financial workflows. When a customer asks "How much did I spend on Amazon since January 2024?", Orchestrates a multi-step process:
First, the agent verifies the customer's identity using KBA, requiring two matching factors for account information access. Once authenticated, it executes a SQL query against the transaction database:
@function_tool()
def execute_query(self, sql: str) -> str:
"""Execute a SELECT query against the banking database.
Args:
sql: Valid SELECT statement
"""
# Validate query is read-only
if not re.match(r"(?i)^\s*SELECT\b", sql.strip()):
raise ValueError("Only SELECT queries allowed")
rows = self.db.execute_read_query(sql)
return json.dumps(rows)@function_tool()
def execute_query(self, sql: str) -> str:
"""Execute a SELECT query against the banking database.
Args:
sql: Valid SELECT statement
"""
# Validate query is read-only
if not re.match(r"(?i)^\s*SELECT\b", sql.strip()):
raise ValueError("Only SELECT queries allowed")
rows = self.db.execute_read_query(sql)
return json.dumps(rows)@function_tool()
def execute_query(self, sql: str) -> str:
"""Execute a SELECT query against the banking database.
Args:
sql: Valid SELECT statement
"""
# Validate query is read-only
if not re.match(r"(?i)^\s*SELECT\b", sql.strip()):
raise ValueError("Only SELECT queries allowed")
rows = self.db.execute_read_query(sql)
return json.dumps(rows)
The raw query results then feed into a deterministic analysis function that computes totals, identifies trends, and formats output—ensuring mathematical operations occur in pure Python rather than relying on potentially hallucinogenic LLM arithmetic:
@function_tool()
def analyze_data(self, data_json: str, analysis_type: str) -> dict:
"""Perform deterministic analysis on query results.
Args:
data_json: JSON string of query results
analysis_type: One of 'total', 'trend_yearly', 'comparison'
"""
rows = json.loads(data_json)
if analysis_type == "total":
total = sum(self._get_amount(r) for r in rows)
return {"total": total, "count": len(rows), "currency": "INR"}
elif analysis_type == "trend_yearly":
# Group by year, compute YoY changes
yearly = defaultdict(int)
for row in rows:
year = row["date"][:4]
yearly[year] += self._get_amount(row)
return {"yearly_totals": dict(yearly)}@function_tool()
def analyze_data(self, data_json: str, analysis_type: str) -> dict:
"""Perform deterministic analysis on query results.
Args:
data_json: JSON string of query results
analysis_type: One of 'total', 'trend_yearly', 'comparison'
"""
rows = json.loads(data_json)
if analysis_type == "total":
total = sum(self._get_amount(r) for r in rows)
return {"total": total, "count": len(rows), "currency": "INR"}
elif analysis_type == "trend_yearly":
# Group by year, compute YoY changes
yearly = defaultdict(int)
for row in rows:
year = row["date"][:4]
yearly[year] += self._get_amount(row)
return {"yearly_totals": dict(yearly)}@function_tool()
def analyze_data(self, data_json: str, analysis_type: str) -> dict:
"""Perform deterministic analysis on query results.
Args:
data_json: JSON string of query results
analysis_type: One of 'total', 'trend_yearly', 'comparison'
"""
rows = json.loads(data_json)
if analysis_type == "total":
total = sum(self._get_amount(r) for r in rows)
return {"total": total, "count": len(rows), "currency": "INR"}
elif analysis_type == "trend_yearly":
# Group by year, compute YoY changes
yearly = defaultdict(int)
for row in rows:
year = row["date"][:4]
yearly[year] += self._get_amount(row)
return {"yearly_totals": dict(yearly)}
Throughout this workflow, the silent AuditLogger records every query, tool call, and verification attempt for compliance audit trails. The agent concludes by synthesizing a natural language response: "Your total Amazon spend since January 2024 was three lakh seventy-six thousand rupees across 13 transactions" .
Customer Support and IVR Replacement
Modern voice bots replace frustrating menu-driven IVR systems with intent-driven conversation. The background_agent example demonstrates real-time sentiment analysis running in parallel—monitoring frustration levels and automatically escalating to human agents when patterns indicate dissatisfaction:
class SentimentAnalyzer(BackgroundAgentNode):
def __init__(self):
super().__init__(name="sentiment-analyzer")
self.frustration_count = 0
async def process_event(self, event: SDKEvent):
if isinstance(event, SDKAgentTranscriptUpdateEvent):
if event.role == "user":
sentiment = await self._analyze_sentiment(event.content)
if sentiment in ["negative", "frustrated"]:
self.frustration_count += 1
if self.frustration_count >= 3:
# Automatically trigger escalation
await self.notify_main_agent_to_escalate()class SentimentAnalyzer(BackgroundAgentNode):
def __init__(self):
super().__init__(name="sentiment-analyzer")
self.frustration_count = 0
async def process_event(self, event: SDKEvent):
if isinstance(event, SDKAgentTranscriptUpdateEvent):
if event.role == "user":
sentiment = await self._analyze_sentiment(event.content)
if sentiment in ["negative", "frustrated"]:
self.frustration_count += 1
if self.frustration_count >= 3:
# Automatically trigger escalation
await self.notify_main_agent_to_escalate()class SentimentAnalyzer(BackgroundAgentNode):
def __init__(self):
super().__init__(name="sentiment-analyzer")
self.frustration_count = 0
async def process_event(self, event: SDKEvent):
if isinstance(event, SDKAgentTranscriptUpdateEvent):
if event.role == "user":
sentiment = await self._analyze_sentiment(event.content)
if sentiment in ["negative", "frustrated"]:
self.frustration_count += 1
if self.frustration_count >= 3:
# Automatically trigger escalation
await self.notify_main_agent_to_escalate()This combination of intent recognition, adaptive escalation, and comprehensive analytics enables voice bots to handle customer interactions with a sophistication that legacy IVR systems simply cannot match .
Key Takeaways
Voice bot architecture synthesizes multiple disciplines: real-time speech processing through low-latency ASR and TTS, sophisticated agent orchestration managing conversation state and tool execution, robust compliance infrastructure with audit logging and identity verification, and performance optimization achieving sub-second round-trip times. Success requires streaming data throughout the pipeline, leveraging multi-node patterns for separation of concerns, and providing intermediate feedback during tool execution. smallest.ai delivers the foundational speech and agent infrastructure—Pulse STT, Lightning TTS, and the Atoms SDK—enabling developers to build production voice systems without reinventing low-level components.
Conclusion
A well-architected voice bot feels like a capable employee: fast, accurate, contextually aware, and able to take action on behalf of users. The patterns explored here—from basic AtomsApp setup through sophisticated multi-node compliance architectures—provide a roadmap for building production systems that meet enterprise requirements while delivering consumer-grade experiences. Start with the Atoms SDK's quickstart patterns, integrate smallest.ai's real-time ASR and TTS capabilities, and progressively layer in business-specific tools and workflows. The infrastructure exists today to build voice experiences that genuinely transform how organizations interact with their customers. Explore Pulse STT, Lightning TTS, and the Atoms agent framework at smallest.ai to begin your journey into production voice AI.



