ASR Software Explained: Architecture, Deployment, and Enterprise Use


Learn how ASR software powers real-time voice AI, from deployment models and production integration to enterprise use cases shaping speech systems today.
If you have ever tried building a voice system that sounds natural, you know the real struggle starts long before the AI replies. Audio streams break, transcripts lag behind conversations, and suddenly your carefully designed workflow feels slow and disconnected. That is usually the moment teams begin researching ASR software seriously, looking for something that can keep up with real-time production environments. The right ASR software is not only about accuracy anymore, but it is also about keeping conversations stable under pressure.
Product and engineering teams often juggle tight latency targets, multilingual users, and compliance requirements at the same time, all while trying to ship features quickly. Choosing the wrong approach can lead to brittle integrations, unpredictable performance, and endless patch fixes after launch.
In this guide, we will walk through how modern ASR works, where it fits into enterprise voice systems, and what to consider before scaling it into production.
Key Takeaways
ASR Software Drives Real-Time Voice Infrastructure: Modern ASR software acts as a live input layer that controls latency, transcript stability, and how smoothly voice agents respond during conversations.
Deployment Model Impacts Performance And Compliance: Cloud, edge, and on-prem ASR architectures shape data control, response timing, and operational scalability across enterprise voice workflows.
Production Integration Requires Streaming Pipelines: Successful deployments rely on event-driven transcript handling, SDK-based streaming ingestion, and middleware that keeps speech aligned with application logic.
Enterprise Use Cases Extend Beyond Transcription: Debt collection agents, compliance monitoring, logistics voice workflows, and healthcare documentation all depend on ASR software as a decision layer, not a background tool.
Future ASR Software Focuses On Context And Personalization: Emerging systems prioritize conversational context windows, adaptive acoustic learning, and multi-modal speech intelligence to support natural enterprise voice interactions at scale.
What Is ASR Software and Why Does It Matter in Modern Voice Systems
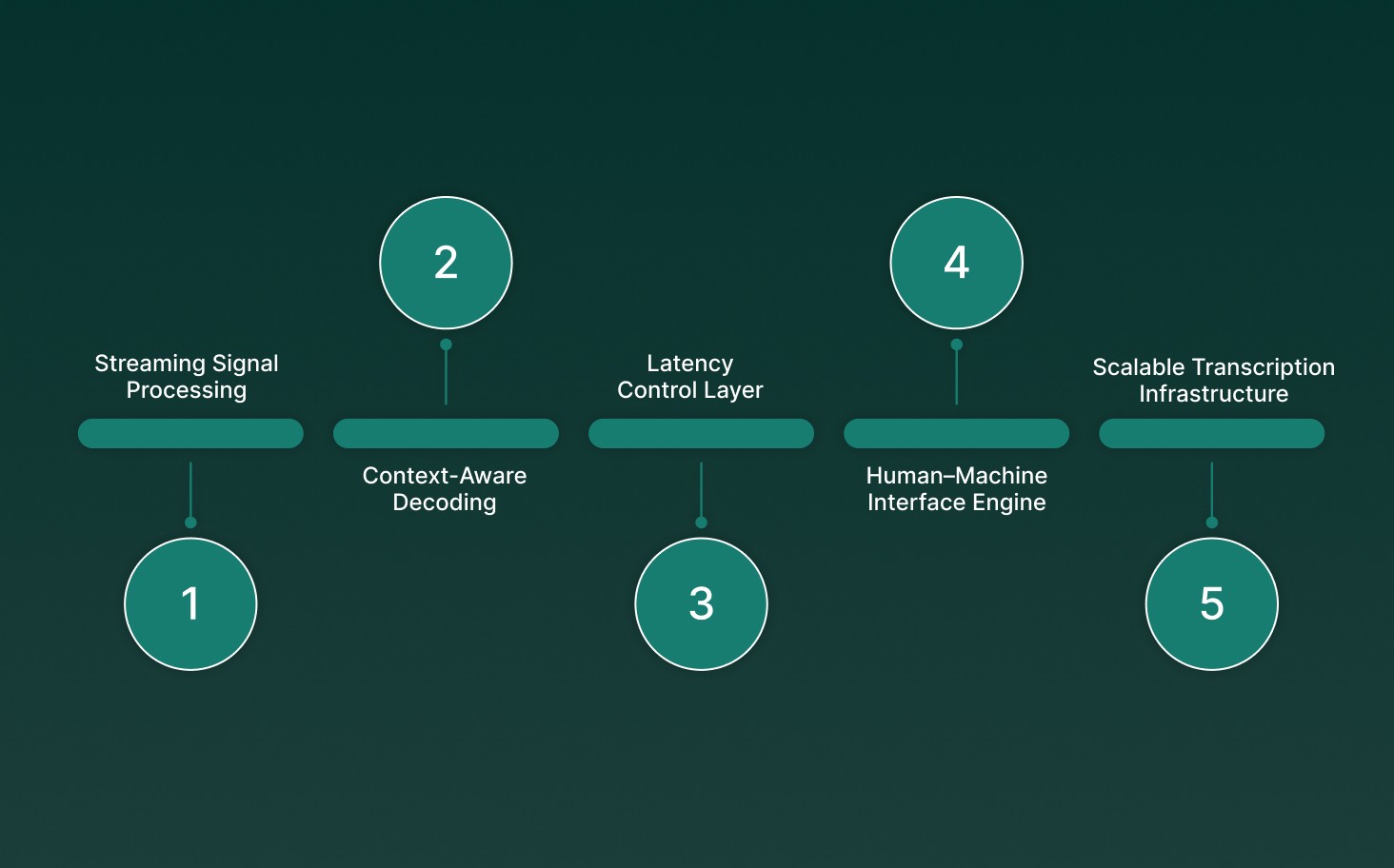
ASR software converts continuous speech streams into structured text signals that downstream voice agents can process in real time. In production voice systems, it acts as the entry layer that determines latency, intent accuracy, and conversational flow stability. Modern deployments rely on neural acoustic modeling, streaming inference, and contextual decoding to handle multilingual calls, interruptions, and noisy environments without breaking dialog continuity.
Key technical roles ASR plays inside modern voice infrastructure include:
Streaming Signal Processing: Converts live audio frames into partial transcripts within milliseconds, allowing real-time agent responses instead of delayed batch outputs.
Context-Aware Decoding: Uses language modeling to resolve homophones and domain terms, reducing substitution errors during finance, healthcare, or support conversations.
Latency Control Layer: Determines time-to-first-transcript and buffering behavior, directly impacting whether conversations feel natural or robotic.
Human–Machine Interface Engine: Translates spoken commands into structured tokens that power automation workflows, tool calling, and voice-driven UI actions.
Scalable Transcription Infrastructure: Handles concurrent audio streams with speaker separation and code-switching support, maintaining transcript clarity across multi-speaker enterprise calls.
ASR software sits at the core of voice-first systems because every downstream action depends on transcript quality and speed. When transcription fails, the entire conversational pipeline breaks.
How Automatic Speech Recognition Works
ASR software converts raw audio into structured transcripts through neural inference, probabilistic decoding, and contextual ranking. Instead of processing full files, modern systems stream audio in small chunks so transcripts update while a speaker is still talking.
The internal processing layers that power real-time transcription include:
Frame-Level Audio Encoding: Incoming audio splits into short frames, transformed into spectrogram embeddings that neural encoders process sequentially for low-latency streaming inference.
Neural Acoustic Alignment: End-to-end models align acoustic vectors with token probabilities using CTC or attention-based decoding to reduce alignment drift during fast speech.
Contextual Language Rescoring: Candidate transcripts pass through language models that rerank outputs based on conversation context, improving domain vocabulary handling without retraining the acoustic stack.
Beam Search Decoding Logic: Parallel transcript hypotheses compete during decoding, balancing accuracy and speed by pruning unlikely word sequences in real time.
Adaptive Vocabulary Injection: Runtime lexicons introduce product names, acronyms, or compliance phrases dynamically, preventing phonetic confusion without rebuilding the base model.
Understanding this internal flow explains why model architecture, decoding strategy, and runtime context control latency and transcript stability across enterprise voice workloads.
See how real-time benchmarks, multilingual accuracy, and low-latency decoding come together in Lightning ASR Performance Deep Dive: How Our Model Excels Across Languages, Accents, and Audio Conditions
Deployment Models: Cloud, Edge, and On-Prem ASR Software
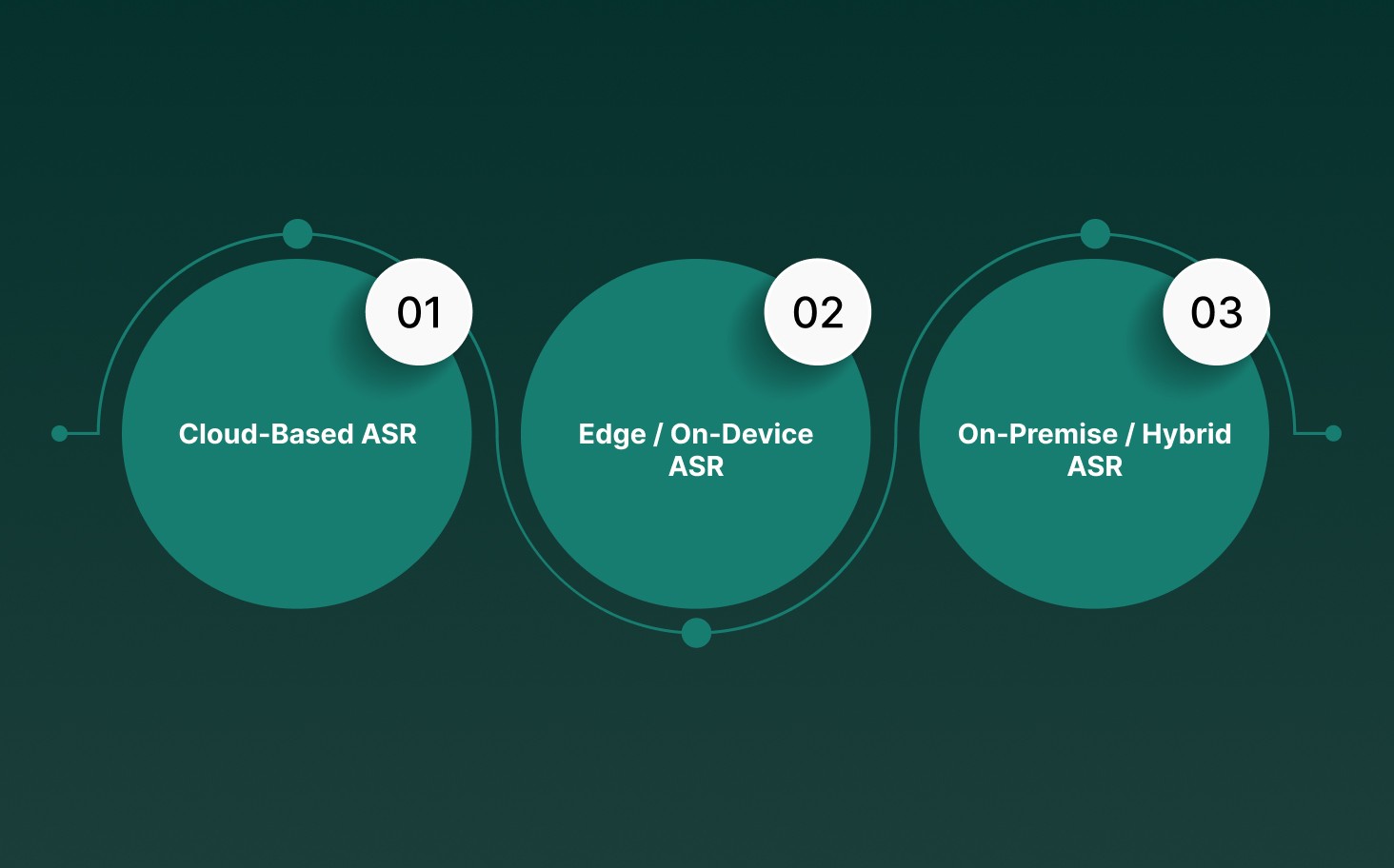
Modern ASR deployment choices directly affect latency budgets, compliance posture, hardware utilization, and operational cost. Each model optimizes transcription pipelines for different enterprise voice infrastructure constraints.
Cloud-Based ASR
Cloud ASR runs inference on remote GPU clusters, allowing teams to deploy high-capacity speech models without managing hardware while supporting quick scaling across distributed voice workloads.
Operational characteristics of cloud-based ASR deployments include:
Elastic GPU Scaling: Audio streams route through load-balanced endpoints that dynamically allocate compute, maintaining stable throughput during traffic spikes without manual provisioning.
Centralized Model Updates: Providers push acoustic or language model upgrades automatically, keeping recognition accuracy current without redeploying edge firmware or retraining local models.
Global Language Expansion: Large cloud deployments maintain multilingual checkpoints, allowing quick rollout of additional dialect support without rebuilding inference pipelines from scratch.
What it means for business: Cloud ASR accelerates experimentation and global rollout but introduces network dependency, ongoing compute costs, and regulatory considerations when sensitive voice data leaves controlled infrastructure.
Edge / On-Device ASR
Edge ASR executes speech recognition directly on embedded processors or mobile hardware, prioritizing deterministic latency, offline capability, and localized data handling for voice interfaces operating outside stable connectivity zones.
Technical traits shaping edge deployments include:
Embedded Acoustic Models: Quantized neural networks run on CPUs or NPUs, maintaining inference under tight memory limits while preserving acceptable transcription accuracy for command-driven interactions.
Wake Word Gating: Local recognition engines trigger only after detecting predefined activation phrases, reducing power usage and preventing continuous microphone streaming to remote services.
Deterministic Response Timing: Processing audio locally eliminates network jitter, allowing predictable transcript generation even in industrial environments with unstable connectivity.
What it means for business: Edge ASR strengthens privacy guarantees and reliability for field operations, though model size constraints may limit conversational depth compared to large-scale server deployments.
On-Premise / Hybrid ASR
On-prem ASR places transcription engines inside enterprise infrastructure while selectively using cloud orchestration for updates, monitoring, or overflow workloads, balancing control with scalability.
Key architectural elements defining on-premise deployments include:
Local Inference Clusters: Organizations run speech models on dedicated GPU servers within private networks, allowing full auditability and control over data retention policies.
Hybrid Traffic Routing: Real-time calls are processed locally, while batch analytics or model retraining pipelines synchronize with cloud environments to reduce internal compute overhead.
Compliance-Driven Isolation: Network segmentation ensures voice data never crosses external boundaries, supporting regulatory requirements across financial services, healthcare, and government workflows.
What it means for business: On-prem ASR delivers predictable latency and data sovereignty while demanding upfront infrastructure planning, internal DevOps expertise, and long-term capacity management.
Choosing between cloud, edge, and on-prem ASR is not a feature decision but an architecture choice that shapes scalability, compliance strategy, and conversational performance from day one.
Build voice systems that respond in real time with sub-70ms transcription, multilingual accuracy, and flexible on-prem or cloud deployment using Smallest AI Pulse STT.
Real-World Use Cases of ASR Software in Enterprise Voice AI
ASR software powers production voice systems by turning live conversations into structured signals that drive automation, analytics, and compliance workflows at enterprise scale. Modern deployments move past transcription toward real-time operational intelligence, where transcripts trigger actions, update systems, and guide AI agents during conversations.
Enterprise voice AI relies on ASR in several specialized operational scenarios:
Debt Collection Voice Agents: Streaming transcription captures payment intent, detects disputes, and triggers CRM actions during live calls without waiting for post-call analytics or manual review.
Healthcare Documentation Pipelines: Clinician speech converts into structured medical fields mapped to diagnosis codes, reducing after-visit documentation backlog while maintaining traceable transcript logs for compliance audits.
Financial Services Compliance Monitoring: Real-time transcripts flag regulated phrases, escalate risk signals, and attach conversation metadata directly to audit trails across trading desks and customer interactions.
Logistics Voice Workflows: Warehouse operators dictate inventory changes while moving, allowing ASR-driven commands to update order systems without scanning devices or pausing physical workflows.
Enterprise Support Automation: Contact centers use streaming transcripts to guide AI copilots that suggest responses, retrieve knowledge base entries, and summarize conversations before calls end.
ASR software drives measurable operational gains when integrated into voice-first workflows rather than used as passive transcription. Enterprise teams treat it as a live decision layer, not a background feature.
See how real-time latency, WER performance, and deployment flexibility compare across leading platforms in Comparative Analysis of Streaming ASR Systems: A Technical Benchmark Study
Top 6 ASR Software in 2026
The ASR software landscape in 2026 is shaped by real-time voice AI, multilingual speech understanding, and low-latency streaming pipelines. Enterprise buyers are moving toward platforms that support conversational agents, compliance workflows, and scalable speech infrastructure rather than standalone transcription tools.
Based on current benchmarks, comparisons, and industry rankings, these are among the most widely referenced ASR platforms right now.
Pulse STT
Pulse STT is built for real-time conversational speech recognition with ultra-low latency and enterprise-grade accuracy across multilingual production workloads.
Sub-70ms Time-to-First-Transcript and industry-leading WER performance across 30+ languages.
Real-time speech intelligence, including speaker diarization, emotion detection, and language identification.
Supports on-prem deployment for data sovereignty with SOC 2 Type II, HIPAA, and PCI-aligned security practices.
Deepgram
Deepgram provides a unified voice AI infrastructure where ASR operates as part of a larger pipeline combining speech-to-text, orchestration, and voice agent logic.
Streaming and batch ASR are available through a single API layer.
Customizable speech models designed for conversational AI and audio intelligence.
Self-hosted deployment options alongside scalable cloud infrastructure.
AssemblyAI
AssemblyAI delivers developer-first speech recognition models focused on transcription accuracy and speech understanding capabilities.
Streaming speech-to-text with low latency and precise end-of-turn detection.
Advanced diarization, multilingual recognition, and structured formatting of transcripts.
Processes large-scale audio workloads with millions of API calls and daily inference operations.
Happy Scribe
HappyScribe uses ASR technology to power automated transcription workflows centered around file-based audio and video processing.
AI transcription supporting 120+ languages with editable transcripts and export tools.
Speaker detection and multilingual processing are built into the transcription pipeline.
Designed primarily for uploaded content rather than continuous streaming speech.
Sonix
Sonix applies deep learning-based ASR to convert uploaded recordings into text with collaborative editing and analysis tools.
Automated transcription with speaker identification and smart punctuation.
Custom dictionaries improve recognition for domain-specific terminology.
Distributed cloud processing allows quick batch transcription turnaround.
Temi
Temi offers automated speech recognition focused on quick audio-to-text conversion for straightforward transcription workflows.
AI-based transcription is designed for fast processing of recorded audio.
Simple interface for generating transcripts without manual transcription.
Operates mainly as a batch transcription service powered by speech recognition models.
Across rankings and comparisons, modern ASR platforms are evaluated less on raw accuracy alone and more on streaming latency, integration flexibility, and enterprise deployment options.
How Developers Integrate ASR Software Into Production Systems
Developers integrate ASR into production by wiring streaming audio pipelines, managing inference endpoints, and routing transcripts into real-time application logic. Integration is less about transcription alone and more about orchestrating audio ingestion, model inference, and downstream event handling without breaking conversational flow or system reliability.
Production integration typically involves these technical layers within modern voice applications:
Streaming Audio Ingestion: Developers pipe WebRTC or telephony audio into ASR endpoints using chunked streaming buffers to maintain continuous transcription without blocking application threads.
Event-Driven Transcript Handling: Partial transcripts trigger application events, allowing systems to update UI states, trigger workflows, or fetch data before the speaker finishes a sentence.
SDK-Based Voice Pipelines: Node.js or Python SDKs handle authentication, websocket connections, and streaming callbacks, reducing latency caused by manual HTTP polling or file uploads.
Custom Vocabulary Injection: Developers configure runtime lexicons or keyword boosting through API parameters to improve recognition of product names, compliance phrases, or domain acronyms.
Post-Processing Middleware: Transcript outputs pass through formatting layers that normalize timestamps, speaker tags, and punctuation before being stored in analytics pipelines or CRM systems.
Integrating ASR successfully means treating it as a live infrastructure component rather than a standalone feature. Strong pipeline design keeps transcripts synchronized with business logic, preventing conversational delays.
Key Challenges Enterprise Teams Face With ASR Software
Enterprise teams often find that ASR challenges come from real-world audio behavior, system architecture limits, and domain-specific language patterns rather than accuracy claims alone. Successful deployment depends on identifying technical bottlenecks that impact transcript reliability, conversational flow, and scalability before going live.
Common technical barriers enterprise teams encounter during ASR adoption include:
Challenge Area | What Happens Technically | Why It Breaks Production Workflows |
Accent Drift And Dialect Variance | Acoustic models struggle when phoneme distributions shift across regional accents or when multilingual speakers switch mid-sentence. | Leads to unstable transcripts that disrupt downstream intent detection and automation triggers. |
Acoustic Noise And Channel Quality | Low signal-to-noise ratios, packet loss from VoIP streams, or poorly calibrated microphones degrade feature extraction accuracy. | Causes inconsistent transcript timing, forcing manual correction or fallback logic during live conversations. |
Continuous Speech Dynamics | Quick turn-taking, filler words, and overlapping speakers create ambiguous token boundaries during decoding stages. | Voice agents misinterpret end-of-turn signals, creating awkward interruptions or delayed responses. |
Vocabulary Drift In Specialized Domains | Generic language models fail to rank industry terminology correctly when context windows lack domain-specific patterns. | Financial, healthcare, or logistics workflows lose accuracy without runtime lexicon injection or custom training. |
Infrastructure And Cost Scaling | High concurrency audio streams increase compute utilization, raising inference costs or throttling throughput during traffic spikes. | Teams struggle to maintain predictable performance without optimizing deployment topology and resource allocation. |
Enterprise ASR challenges rarely come from one issue alone. Most production failures stem from the interaction between audio conditions, model behavior, and infrastructure decisions made early in deployment planning.
If you want a deeper breakdown of ASR pipelines, decoding stages, and practical enterprise use cases, start with Guide to Automatic Speech Recognition (ASR): How It Works and Real-World Applications
What is the Future Direction of ASR Software?
ASR software is shifting from passive transcription toward a conversational infrastructure that predicts intent and adapts to context inside real-time voice systems. Future development focuses on lower latency, stronger contextual reasoning, and autonomous speech understanding across multilingual and multi-modal environments.
Emerging technical directions shaping how ASR evolves in enterprise voice ecosystems include:
Conversational Context Modeling: Future models maintain rolling context windows across dialog turns, improving intent continuity without relying on rigid command grammars or isolated sentence decoding.
Self-Adapting Acoustic Pipelines: Active learning loops refine pronunciation patterns and domain vocabulary dynamically, reducing manual tuning cycles during long-running deployments.
Edge-Native Inference Architectures: Smaller neural models run directly on embedded hardware, allowing privacy-sensitive transcription without sacrificing real-time conversational responsiveness.
Multi-Modal Speech Intelligence: ASR integrates emotion signals, speaker intent, and conversational state to feed downstream reasoning models instead of producing flat transcripts.
Personalized Voice Profiles: Systems learn user-specific cadence, terminology, and phrasing patterns to stabilize recognition accuracy across recurring speakers in enterprise workflows.
The next phase of ASR software moves toward continuous learning and real-time contextual reasoning. Speech recognition becomes less about transcription accuracy and more about sustaining natural human-machine conversations at scale.
Final Thoughts!
Building with voice is no longer a side experiment for product teams. ASR has quietly shifted into a core infrastructure layer that shapes how systems listen, react, and adapt in real time. The difference between a tool that transcribes and a system that truly keeps up with live conversations comes down to architecture choices made early. Teams that treat speech as a live signal rather than a static input often see smoother deployments and fewer surprises after launch.
If you are looking to move faster without compromising performance, Smallest AI Pulse STT brings real-time transcription, multilingual accuracy, and flexible deployment into one developer-ready stack. It fits naturally into production pipelines where latency, reliability, and control matter every day.
Explore how Smallest AI can support your next voice build and see what happens when speech infrastructure finally keeps pace with your product vision. Get in touch with us!
How does ASR software handle overlapping speakers during live conversations?
Can ASR software adapt to industry-specific terminology without retraining the entire model?
What role does buffering play in real-time ASR software performance?
Is ASR software suitable for low-bandwidth environments?
How do developers monitor ASR software performance in production?

