Guide To Voice Recognition: Technology, Benefits, and Applications


Learn how voice recognition works, its benefits, and how AI systems like Pulse STT enable accurate, real-time, and intelligent voice interactions.
Every time a voice assistant responds with “Could you repeat that,” friction enters the interaction. People repeat commands, conversations slow down, and teams begin to question whether their systems truly understand spoken input. This is often when organizations start looking at voice recognition as the technology that converts human speech into accurate, real-time actions.
Interest in voice recognition usually increases as businesses roll out conversational AI, automated IVR systems, and voice-enabled customer experiences. According to Statista, the global voice recognition market is expected to cross $50 billion by 2029, highlighting how quickly companies are adopting voice-driven interfaces across apps, support operations, and digital platforms.
In this guide, we explain how voice recognition works, where it fits within modern voice systems, and how organizations apply it across real-world workflows.
Key Takeaways
Voice Recognition Is Essential for Modern Workflows: Real-time, always-on voice systems are now a core part of operations, where speed, uptime, and compliance matter most.
Fast Response Times Drive Success: Sub-300 ms latency is critical for customer support, healthcare, and financial services to keep conversations smooth and accurate.
Edge and Hybrid Deployments Are Growing: On-device and on-prem solutions are gaining attention for privacy, offline use, and consistent performance.
Specialized Models Outperform Large Systems: Task-focused voice recognition handles accents, technical terms, and high call volumes more reliably than generic models.
High Value Lies in Real-Time Use Cases: Industries such as healthcare, BFSI, and contact centers benefit most, with faster workflows, stronger security, and better customer experiences.
What Is Voice Recognition?
Voice recognition is a technology that allows computers to listen to and understand human speech during conversations. Instead of depending on typing or manual input, people can speak naturally while systems capture information, respond instantly, and complete tasks in real time.
Spoken language is converted into structured data that supports commands, guides conversations, verifies speakers, and powers AI-driven voice interactions.
Although often confused with speech recognition, the two are not the same. Speech recognition mainly converts spoken words into text. Voice recognition goes further by analyzing how a person speaks, identifying who is speaking, interpreting intent, and enabling more intelligent responses during live conversations.
Key benefits include:
Natural and faster interaction without typing or manual navigation
Less repetitive data entry during calls or voice workflows
Better accessibility for users who rely on voice commands
Real-time automation during customer conversations
Scalable support systems that handle large call volumes efficiently
Today’s voice recognition systems use artificial intelligence, machine learning, and natural language processing to analyze tone, pronunciation, accents, and conversational context. This allows them to perform reliably across different speakers and real world conditions while maintaining consistent accuracy.
Because of this capability, businesses and product teams use voice recognition to make communication faster, reduce manual effort, and create smoother voice based experiences.
Also Read: Top Voice API Providers: Revolutionizing Speech Recognition
With a clear understanding of its benefits, it’s important to see how voice recognition differs from speech recognition and why that distinction matters.
Voice Recognition vs Speech Recognition vs Speaker Recognition: Key Comparison
While often used interchangeably, voice recognition and speech recognition are different. Speech recognition converts spoken words into text. Voice recognition goes further: it can identify speakers, understand intent, and guide systems to act intelligently. This difference becomes clearer when you look at the key features in practice:
Capability | Voice Recognition | Speech Recognition | Speaker Recognition |
Main Purpose | Understands speech and may identify speaker and intent | Converts spoken words into text | Identifies or verifies who is speaking |
Focus | Voice interaction, identity signals, and responses | Spoken language transcription | Voice biometrics and speaker identity |
Output | Actions, responses, identity signals, structured data | Written text from audio | Verified or matched speaker profile |
Key Function | Supports intelligent voice based interactions | Generates accurate transcripts | Confirms or detects speaker identity |
Common Use Cases | Voice assistants, IVR automation, AI conversations | Call transcription, captions, voice search | Secure login, fraud detection, call authentication |
Context Awareness | Can analyze tone, behavior, and conversation flow | Focuses mainly on words and language | Focuses on voice characteristics and patterns |
Security Role | Supports secure and personalized workflows | Minimal direct security role | Strong role in biometric verification |
AI Integration | Works with conversational AI and automation systems | Works with NLP for text analytics | Works with biometric and security systems |
Also Read: Top 8 Voice-to-Text Software for Real-Time and Production Use
Once we know the difference, we can explore the components that make modern voice recognition systems reliable and effective.
Key Components of Modern Voice Recognition Systems
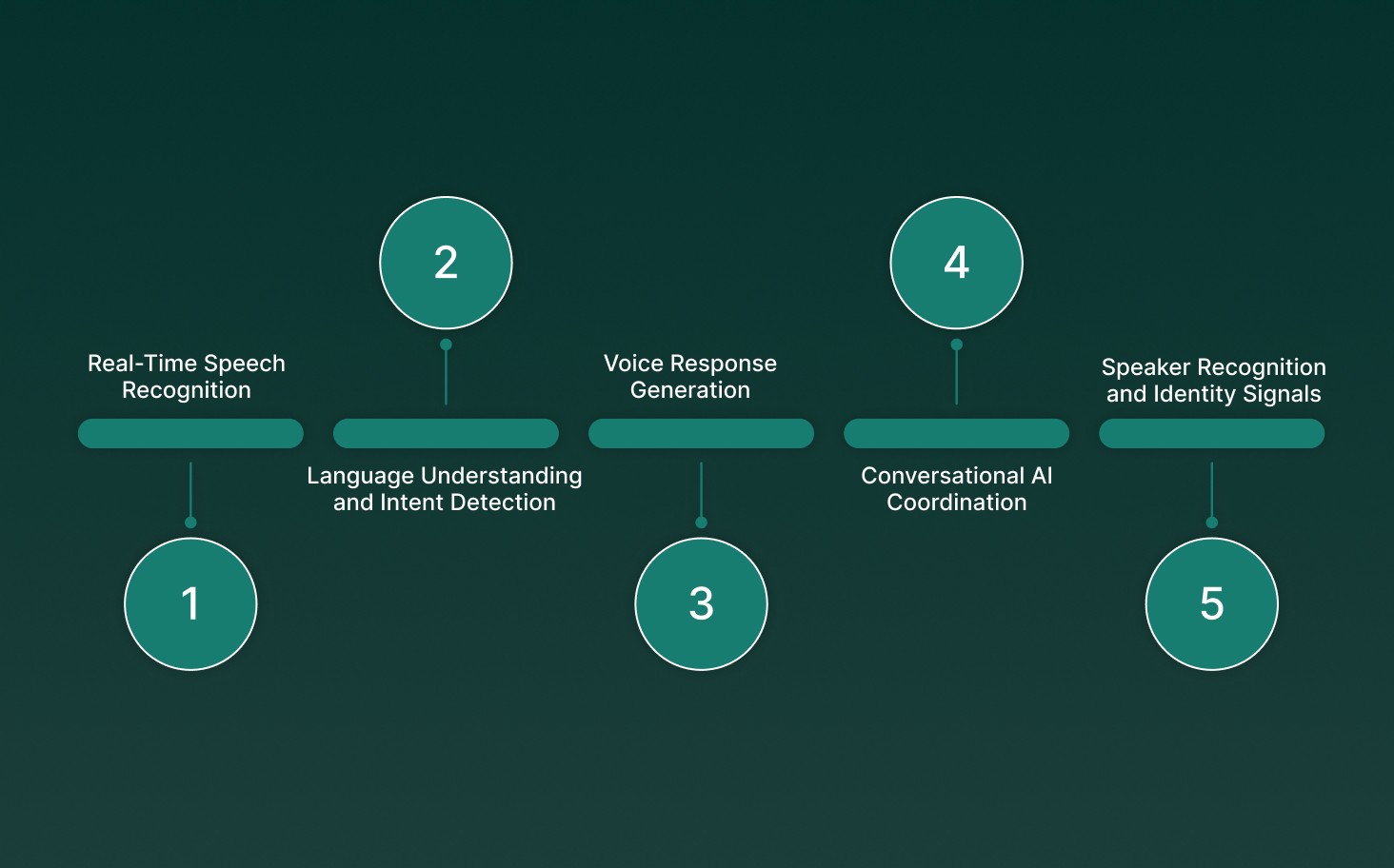
Modern voice recognition is not a single model. It works as a connected pipeline that captures, understands, and turns speech into meaningful actions during live conversations.
Each layer adds a specific capability that improves accuracy, response quality, and real-time performance across enterprise voice workflows.
Here are the core components that power today’s AI-driven voice recognition systems:
Real-Time Speech Recognition: The system first converts spoken audio into structured text. Enterprise engines such as Pulse STT focus on low-latency transcription, strong multilingual accuracy, and reliable performance even in noisy, high-volume call environments.
Language Understanding and Intent Detection: Once speech is transcribed, natural language processing analyzes meaning, detects user intent, extracts key details, and tracks conversational context. This allows systems to respond intelligently rather than just generate transcripts.
Voice Response Generation: After the intent is understood, the AI generates natural-sounding spoken replies using advanced text-to-speech models. Lightning voice technology produces clear, human-like responses that keep conversations smooth and consistent.
Conversational AI Coordination: Conversational engines manage turn-taking, interruptions, and real-time dialogue flow. Solutions such as Hydra help AI agents listen and respond simultaneously, enabling full-duplex voice interactions rather than delayed responses.
Speaker Recognition and Identity Signals: Voice biometrics analyzes vocal patterns to identify or verify speakers. This layer supports secure authentication, personalized experiences, and fraud detection during live calls.
Understanding these building blocks helps clarify how voice recognition processes speech, which leads us to the step-by-step workflow.
How Voice Recognition Turns Speech into Action?
Each step plays a specific role in helping systems listen accurately, interpret intent, and respond naturally during live conversations. Instead of working as separate tools, these layers function together as one connected AI pipeline.
Here is how a typical voice recognition process works from start to finish:
1. Audio Capture
The process begins when microphones or digital audio streams capture spoken voice and convert it into signals that AI models can process. Clean input improves overall accuracy and response quality.
Key factors that influence this stage include:
Microphone quality and audio clarity
Background noise and echo levels
Speaker tone, speed, and accent
Network stability and audio bandwidth
Real-time voice platforms prioritize low-latency audio capture to ensure conversations remain natural and uninterrupted.
2. Speech to Text Conversion
Next, speech recognition models convert spoken audio into structured text. The system analyzes sound patterns, pronunciation, and language structure to identify words and phrases accurately.
Here’s how AI engines analyze:
Acoustic patterns and phonemes
Pronunciation variations across speakers
Language probability models
Contextual word sequences
For example, Pulse STT (speech-to-text) engine supports real-time transcription and multilingual speech recognition, making it suitable for customer support calls, voice analytics, and conversational AI workflows.
3. Language Understanding and Intent Detection
After transcription, natural language processing analyzes the text to understand meaning and user intent. This stage allows systems to respond intelligently rather than just produce transcripts.
Key processes include:
Intent classification and context tracking
Entity and keyword recognition
Sentiment and conversational signals
Real-time reasoning and response planning
Lightweight models like Electron help systems interpret conversations quickly while maintaining fast response times.
4. Decision Making and Action Execution
Once intent is understood, the system decides what action to take. It may retrieve information, route a request, trigger automation, or generate a response.
This stage powers:
AI voice assistants and chat agents
Automated customer support workflows
Call routing and operational automation
Voice-driven enterprise applications
Modular AI components, such as Atoms, allow teams to build scalable voice agents that automate scheduling, support interactions, and handlerepetitive operational tasks.
5. Speech Output and Response Delivery
If the system needs to respond verbally, text-to-speech models convert system outputs into natural spoken responses. The goal is to keep conversations fluid and human-like.
Advanced voice engines such as Lightning, used within Smallest.ai’s Waves platform, generate clear speech with very low delay.
And multi-modal systems like Hydra combine listening, reasoning, and speaking into seamless, real-time conversations.
Together, these stages form a complete voice recognition pipeline that turns spoken input into structured understanding, intelligent actions, and natural voice responses across modern AI-driven communication systems.
After understanding the workflow, it’s crucial to consider the challenges enterprises face and how they can maintain accuracy and security.
Once challenges are addressed, teams can look ahead to future trends shaping the voice recognition market.
5 Core Challenges in Voice Recognition and How to Handle Them

Differences in how people speak, noisy surroundings, sensitive data, and changing language patterns can affect accuracy and reliability. Below are common challenges teams face when using voice recognition, along with practical ways to manage them.
1. Accent, Language, and Speaking Differences
Challenge: People speak with different accents, at different speeds, and with different language mixes. Systems may misinterpret words when speech patterns vary widely.
Best Practices:
Train models using speech data from multiple regions and accents
Update datasets regularly with new conversational samples
Apply adaptive learning to improve recognition for frequent users
Use multilingual speech engines that handle mixed-language conversations more effectively
2. Noise and Poor Audio Conditions
Challenge: Background sounds, low-quality microphones, or overlapping speakers can reduce transcription accuracy and slow down conversations.
Best Practices:
Use noise filtering and echo reduction during audio processing
Maintain consistent audio capture standards across devices
Monitor live audio quality and prompt users when clarity drops
Combine speech enhancement tools with low-latency voice pipelines
3. Numbers, Names, and Industry Terms
Challenge: Phone numbers, account details, brand names, or technical words are often harder for systems to interpret correctly.
Best Practices:
Add custom vocabulary and industry-specific language models
Use context-aware processing to understand surrounding phrases
Review conversation logs to find repeated recognition errors
Train systems with domain-focused datasets for better accuracy
4. Privacy and Data Protection
Challenge: Voice conversations may contain personal or financial information, which raises compliance and security concerns.
Best Practices:
Encrypt audio during transfer and storage
Control access using secure authentication and permissions
Apply anonymization where possible
Follow regulatory standards relevant to your industry and region
5. Ongoing Language Changes
Challenge: New slang, product names, and changing communication styles can slowly reduce recognition performance if models remain static.
Best Practices:
Retrain models periodically using updated speech data
Track recognition accuracy and error patterns
Collect user feedback to identify new words early
Use modular AI systems that allow frequent updates without service disruption
Once challenges are addressed, teams can look ahead to future trends shaping the voice recognition market.
5 Innovation Trends in Modern Voice Recognition
Enterprise voice teams are prioritizing infrastructure decisions that affect real-time performance, deployment resilience, and production scalability over model accuracy alone.
Runtime Multilingual Intelligence: Voice platforms are evolving to process code-switching, regional pronunciation, and mixed-language inputs without model reloads or increased inference delays.
Hardware Optimization for Voice Workloads: Dedicated voice AI processors and optimized inference stacks are replacing general-purpose GPUs in large-scale deployments to stabilize performance and control operational costs.
Shift Toward Unified Speech Models: Organizations are replacing multi-stage ASR→LLM→TTS pipelines with unified speech systems that reduce processing layers, lower latency, and maintain natural conversational flow during live interactions.
Edge-First Voice Deployment: On-device inference is becoming standard for use cases that require offline capability, faster response times, and compliance with regional data-processing regulations.
Advanced Voice Identity and Fraud Prevention: Enterprises are adding passive liveness detection, spoof resistance, and behavioral analytics alongside traditional voiceprint authentication to strengthen security in high-risk sectors.
The voice recognition market is moving toward real-time, production-ready infrastructure designed for continuous workloads, regulatory scrutiny, and human-level conversational responsiveness, not just benchmark accuracy.
Also Read: The Future of AI Voice-Driven Interactions and Their Impact
With these trends in mind, it’s clear how voice recognition is transforming real-world applications across industries.
Practical Use Cases of Voice Recognition in Production Environments
Today, organizations use it to automate conversations, streamline workflows, and extract real-time insights from spoken interactions. From customer support to enterprise analytics, voice AI is becoming a core operational layer rather than an optional feature.
The table below shows how different industries apply voice recognition to improve speed, reduce manual work, and deliver more natural user experiences.
Industry / Function | Key Use Cases | Business Impact |
Customer Support & Contact Centers | Real-time call transcription, automated IVR interactions, AI-powered routing, voice-based customer analytics | Faster resolution times, reduced agent workload, improved customer experience |
Media & Content Creation | AI voiceovers, audiobook narration, interactive storytelling, game character voices | Faster content production, scalable voice creation, and multilingual content delivery |
Healthcare & Professional Services | Voice-based appointment booking, clinical documentation, telemedicine conversations, and automated reminders | Reduced administrative work, improved documentation accuracy, and better patient engagement |
E-Commerce & Sales Automation | Voice shopping assistants, order tracking bots, automated outbound calls, conversational product recommendations | Higher conversion rates, faster support interactions, improved customer engagement |
Enterprise Automation & Analytics | Voice-driven dashboards, real-time meeting transcription, compliance monitoring, and business intelligence through voice analytics | Better decision-making, operational transparency, automated compliance tracking |
Across these sectors, modern voice platforms combine speech recognition, conversational AI, and analytics into unified workflows. This allows organizations to handle large-scale conversations while maintaining natural interactions and measurable operational efficiency.
After seeing its impact, it’s easy to understand why teams now consider Pulse STT when building production-ready voice recognition systems.
Why Enterprises Are Upgrading Voice Recognition with Pulse STT?
As voice technology moves from pilots to mission-critical workflows, enterprises are re-evaluating traditional voice recognition systems. Many older platforms struggle with large-scale deployment, real-time accuracy, and consistent performance, making AI-driven solutions like Pulse STT essential.
Enterprise teams rely on Pulse STT because it delivers reliability, speed, and actionable intelligence for high-volume operations:
Real-Time, Low-Latency Processing: Pulse STT converts speech into text and actionable intent almost instantly, keeping conversations smooth in customer support, sales, healthcare, and operational workflows.
Task-Specific AI Models: Domain-trained models in Pulse STT handle accents, industry terminology, and high call volumes with superior accuracy and stability compared to generic systems.
Flexible Deployment Options: Pulse STT supports on-device, cloud, and hybrid deployments, helping enterprises meet regulatory standards, reduce latency, and maintain consistent performance across distributed teams.
Scalable Performance for High Volumes: Designed for production-grade operations, Pulse STT manages thousands of concurrent interactions without delays or degradation, ensuring reliable real-time voice recognition.
Compliance and Data Security: Built-in encryption, access controls, audit trails, and alignment with SOC 2, HIPAA, GDPR, and DPDP standards make Pulse STT suitable for regulated industries like healthcare and BFSI.
By combining real-time accuracy, low latency, and enterprise-grade security, Pulse STT transforms voice recognition from a demo-level tool into a dependable foundation for live, revenue-critical workflows.
Conclusion
Voice recognition is becoming more than just a feature, it’s becoming the foundation for modern operations. Teams that treat it as core infrastructure see fewer delays, better control over response times, and systems that work reliably under real traffic. The market will keep growing, but the gap is widening between platforms built for demos and those ready for real, regulated workloads.
When teams test real-time voice recognition at scale, Pulse STT often comes into focus. With fast response times and deployment options that meet compliance and uptime needs, Smallest.ai is built for production voice, not experiments.
See how Lightning and real-time voice agents fit into your workflow, and discover what changes when delays no longer slow things down. Get in touch with us!
How does voice recognition work in real time?
Can voice recognition handle different accents and languages?
How secure is voice recognition for sensitive data?
Why do some voice recognition systems fail in noisy environments?
How can businesses improve the accuracy of voice recognition?

