Voice Fraud Detection for Contact Centers: Identifying Synthetic or Altered Speech in Real Time


Voice fraud detection for contact centers: attack types, real-time streaming architecture, threshold tuning, and layered defenses to flag synthetic speech fast.
Voice fraud detection is no longer a niche security project; for many contact centers, it has become table stakes. The FBI issued a public service announcement in May 2025 warning that malicious actors are using AI-generated voice messages to impersonate senior U.S. officials in targeted vishing campaigns (FBI public service announcement on AI-generated vishing). If attackers can make state-level impersonation work at scale, the same playbook applies to the voice authentication layer your agents rely on every day.
This is for contact center architects, security engineers, and operations leaders who need a practical mental model: how synthetic or altered speech enters a call, what real-time detection is actually doing under the hood, and what a defensible rollout looks like when it meets production constraints. The goal is straightforward: a clear view of the threat surface, the detection stack, and the concrete steps that harden the voice channel without breaking the call flow.
The Threat Landscape: What Contact Centers Are Actually Facing
This isn't a theoretical risk curve. Voice cloning tools can now produce convincing output from a few seconds of reference audio, and the same techniques used to impersonate public figures are being applied to contact center authentication layers. The three attack families, synthesis, conversion, and replay, are each exploiting different gaps in how voice channels are secured.
Most of what contact centers see in the wild falls into three buckets. Voice synthesis is the fully generated case: an attacker feeds text into a TTS model trained on a target’s voice samples and outputs speech that sounds like the person. Voice conversion starts with a real voice (live or recorded) and reshapes it to match a different speaker, sometimes in real time. Replay attacks are the blunt instrument: clean recordings of a legitimate customer played back to defeat voice biometrics, with no AI required. These aren’t interchangeable, and treating them as such is why single-tech defenses keep getting bypassed.
It helps to understand how AI voice cloning works at the model level, because it explains why the bar keeps moving. Modern voice cloning systems can produce convincing output from only a few seconds of reference audio, and some commercial systems advertise cloning from around five seconds of input, and the tells they leave behind are getting harder to spot. Detection isn’t getting simpler; it’s getting more adversarial.
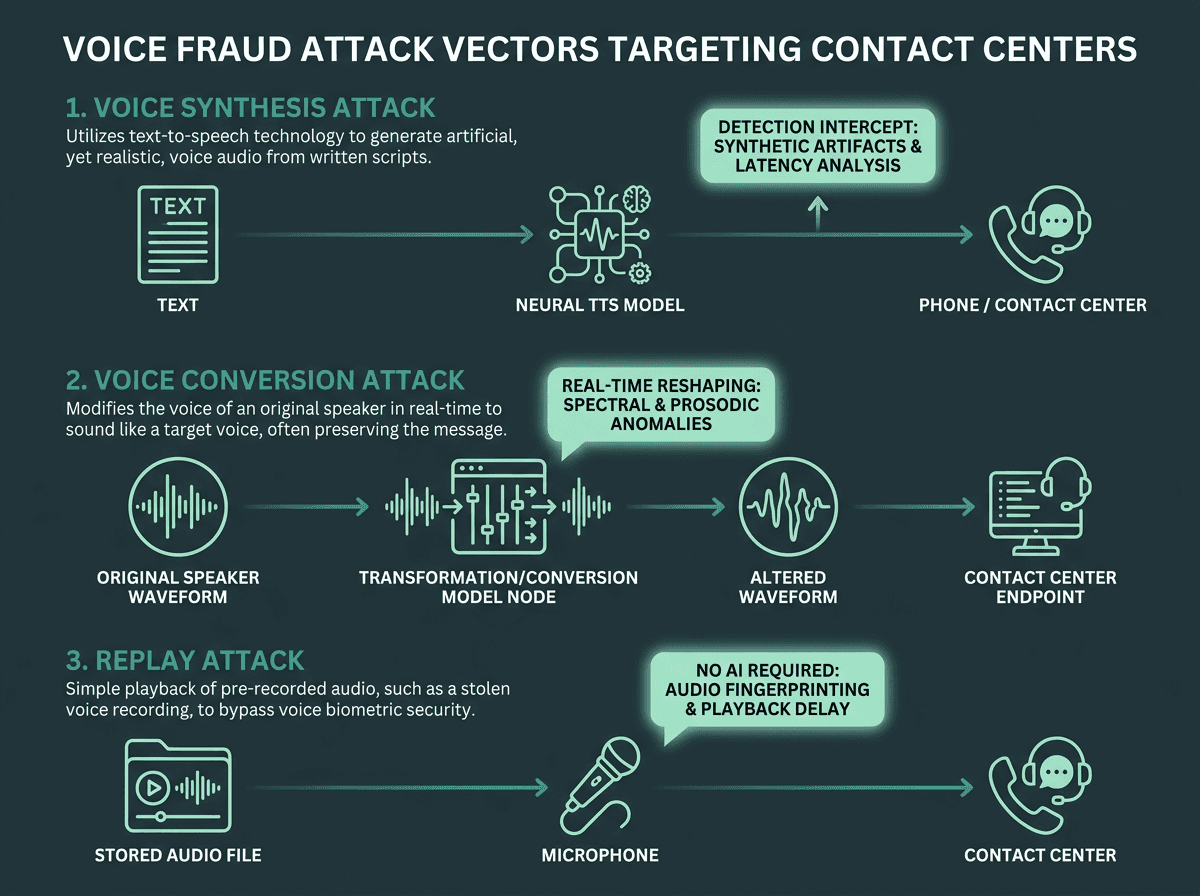
Voice synthesis, voice conversion, and replay attacks each exploit different weaknesses in contact center authentication.
How Real-Time Detection Systems Work
Real-time detection is, in practice, a streaming classification problem. You ingest the audio stream, extract features, and emit a risk score quickly enough that the contact center can respond before the call moves on. That “quickly enough” constraint is unforgiving: add more than roughly 300 to 500 milliseconds of processing delay and agents will feel it, customers will talk over prompts, and the system will start to sabotage the very workflows it’s meant to protect.
Acoustic Feature Extraction
The first layer looks at the physics of speech. Features like Mel-frequency cepstral coefficients (MFCCs), spectral flux, and formant trajectories capture the shape and movement you get from an actual vocal tract. Synthesized speech, even when it sounds “natural,” often shows up as overly smooth formant transitions and less micro-variation in pitch. You can measure those artifacts today, but the gap keeps narrowing as generative models improve.
Liveness and Anti-Spoofing Models
Anti-spoofing classifiers are purpose-built for the question acoustic features can’t fully answer: is this live human speech, or generated/replayed audio? They’re commonly trained on datasets like ASVspoof, learning from both genuine and spoofed samples to output a probability score per segment. The operational headache is distribution shift. Train on last year’s TTS families and you’ll watch accuracy slip as new architectures arrive, unless you keep feeding the model fresh spoofed samples.
Speaker Verification as a Complementary Layer
Speaker verification tackles a different problem: comparing the caller to a stored voiceprint for a claimed identity. It answers “is this the right person?” rather than “is this audio live?” You need both, because an attacker can show up with a perfectly real human voice that simply doesn’t belong to the account holder. Running anti-spoofing and speaker verification in parallel (not as a slow, serial chain) closes that gap while keeping latency under control. That’s also why Real-time speech analytics platforms increasingly bundle both checks into a single inference pass.
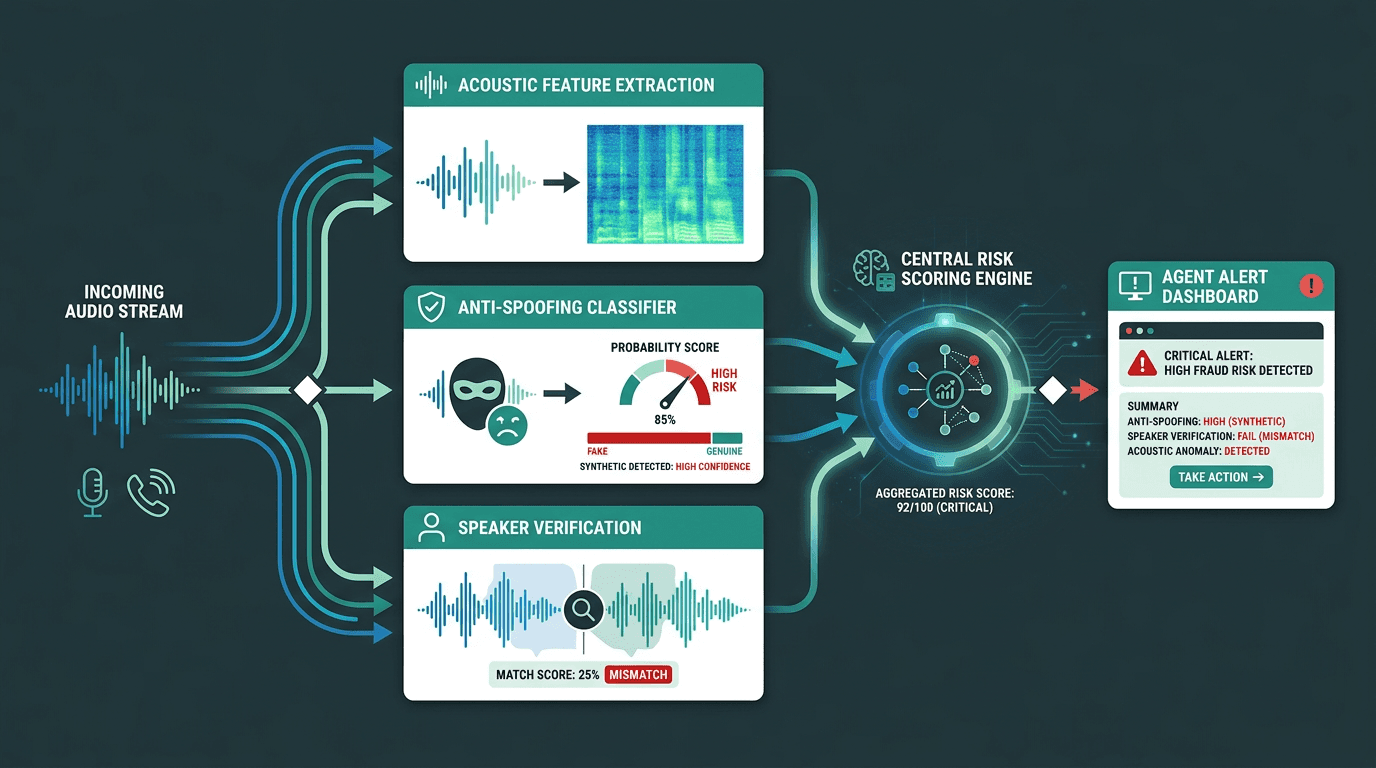
A robust detection stack runs acoustic analysis, anti-spoofing, and speaker verification in parallel to minimize both latency and false negatives.
Infrastructure Requirements: Why Streaming Is Non-Negotiable
Post-call batch processing has a role in investigations and reporting. It doesn’t stop fraud. Prevention means streaming: process audio in small chunks (typically 20 to 100 milliseconds per frame) and keep a rolling risk score as the conversation unfolds. When the score crosses a threshold, you can notify the agent, pull in a supervisor, or trigger step-up authentication while the attacker is still on the line.
That architecture has real consequences for how you build. You need low-latency ingestion, stateful session management so the system keeps speaker context across the call, and inference endpoints that can handle concurrency without turning into a queue. The part teams most often underweight is session state. Detection gets materially better when the model can use what it learned in the first 30 seconds to judge audio at the two-minute mark. Stateless inference discards that context and forces every segment to stand alone. If you want the infrastructure patterns and tradeoffs spelled out, the piece on streaming architecture for real-time voice walks through them in detail.
What Most Teams Get Wrong About Threshold Tuning
The most common failure mode is picking one global threshold and calling it done. Tune it to keep false positives low across the whole population and you’ll miss attacks aimed at high-value accounts. Tune it for maximum sensitivity and you’ll drown agents in alerts until they start treating the system as background noise.
What works in practice is risk-stratified thresholds. Calls tied to high-value transactions, account changes, or password resets should run “tighter” than routine balance checks. That only works if the detection stack knows the call intent up front, which means passing context from the IVR or CRM before the agent ever says hello. Most contact center platforms can send that metadata at call setup; the catch is you have to plan and implement the integration intentionally.
Practical threshold calibration steps:
Segment your call population by transaction risk tier before setting any thresholds.
Run the detection system in shadow mode for two to four weeks to collect baseline score distributions for each tier.
Set initial thresholds at the 95th percentile of legitimate call scores within each tier, then adjust based on observed false positive rates.
Build a feedback loop: agents who override alerts should log the reason, and that data should feed back into threshold review cycles.
Review thresholds quarterly at minimum, and immediately after any major TTS model release that could shift the spoofed sample distribution.
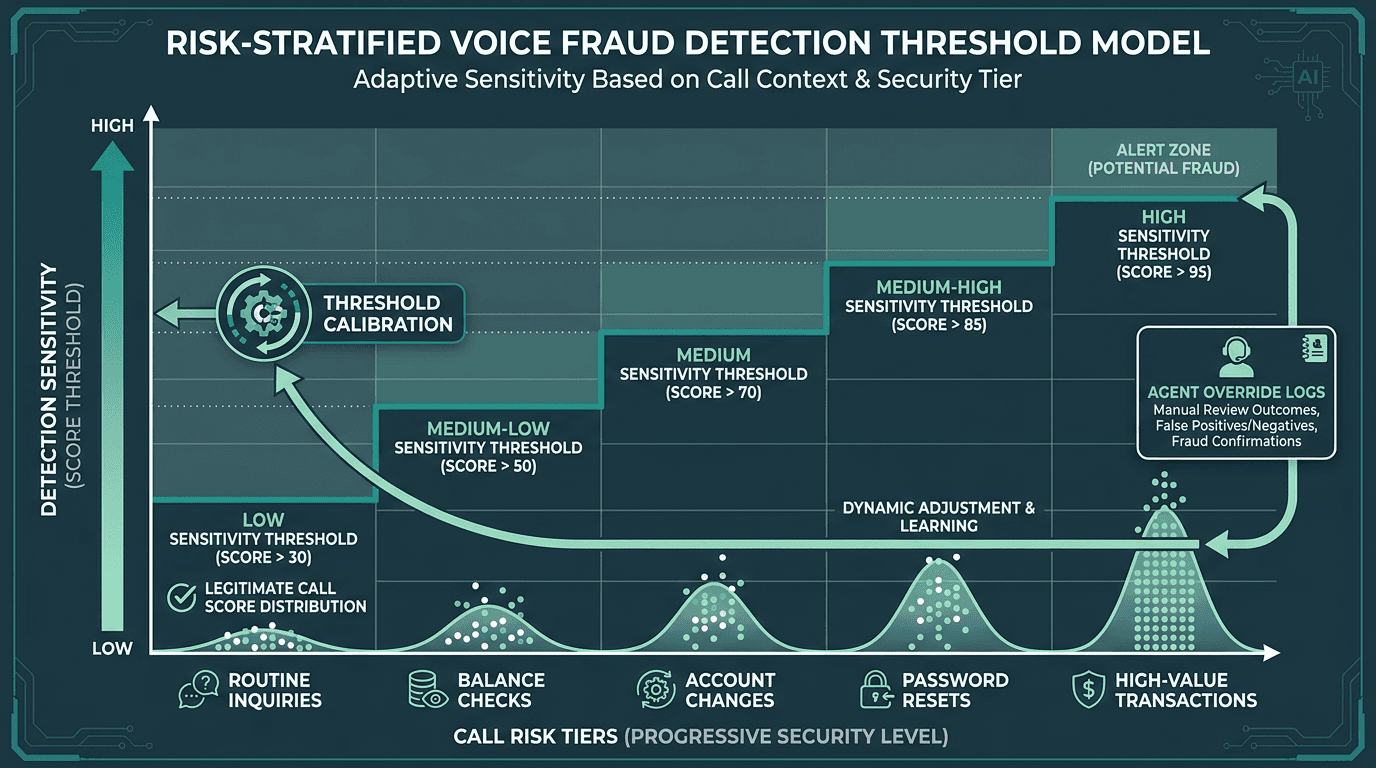
Risk-stratified thresholds prevent both alert fatigue on routine calls and missed detections on high-value transactions.
Practical Implementation: Building a Defensible Voice Fraud Stack
A defensible implementation doesn’t look like a single “fraud product” bolted onto the call center. It’s a layered stack, where each layer is there because the others have blind spots. The sequencing matters, too, because you’re balancing risk reduction against latency, integration complexity, and the caller experience.
Start with passive liveness detection at the IVR layer. Before the call ever reaches an agent, the IVR can run a lightweight anti-spoofing check during the authentication prompt. That tends to catch most replay attacks and low-quality synthesis with zero added friction for legitimate callers. The AI voice agents in the contact center context matters: if your IVR is already AI-powered, the audio stream is already flowing through real-time processing, so adding a liveness classifier is typically an incremental model addition, not a new infrastructure project.
Layer speaker verification on top for identity claims. Once the caller asserts an identity, compare their voiceprint to the enrolled template. Treat mismatches as a trigger for step-up authentication rather than an automatic rejection; it protects the experience for legitimate callers whose audio is degraded by noise, devices, or network conditions.
Add behavioral signals as a third layer. Purely acoustic systems can be tricked. Behavioral signals, call timing patterns, device fingerprints, and the velocity of account changes requested, add evidence from outside the waveform. Folding those signals into the risk score means wiring your detection stack into CRM and telephony metadata, but the lift pays off in accuracy. For the compliance and safety framing around this kind of integration, the guide on how to make your voice agents secure and safety compliant is a good reference before you lock the architecture.
Advanced Considerations: Edge Cases That Break Standard Pipelines
A handful of edge cases show up again and again: systems that score well in controlled tests, then stumble the moment they hit real contact center traffic.
Codec degradation. Contact center audio is often squeezed through lossy codecs (G.711, G.729), which can strip away the high-frequency artifacts many anti-spoofing models lean on. Train on clean audio and you should expect performance to drop on compressed telephony. The fix is unglamorous but essential: test the pipeline on audio that has gone through the same codec chain as your production calls.
Hybrid attacks. A common pattern is “human first, synthetic later”: a real person gets through authentication, then the attacker switches to synthesis mid-call once the initial checks are out of the way. Systems that only score at call start won’t see the swap. Continuous scoring across the entire call is the right posture here. The real-time insurance fraud detection use case is a good illustration of how continuous scoring changes outcomes when the stakes are high.
Adversarial audio. More sophisticated attackers are starting to add adversarial perturbations to synthesized speech specifically to fool anti-spoofing classifiers. This is active research, and no commercial system is fully robust today. The practical mitigation is ensemble detection: run multiple independent classifiers and require agreement, instead of betting everything on a single model’s score.
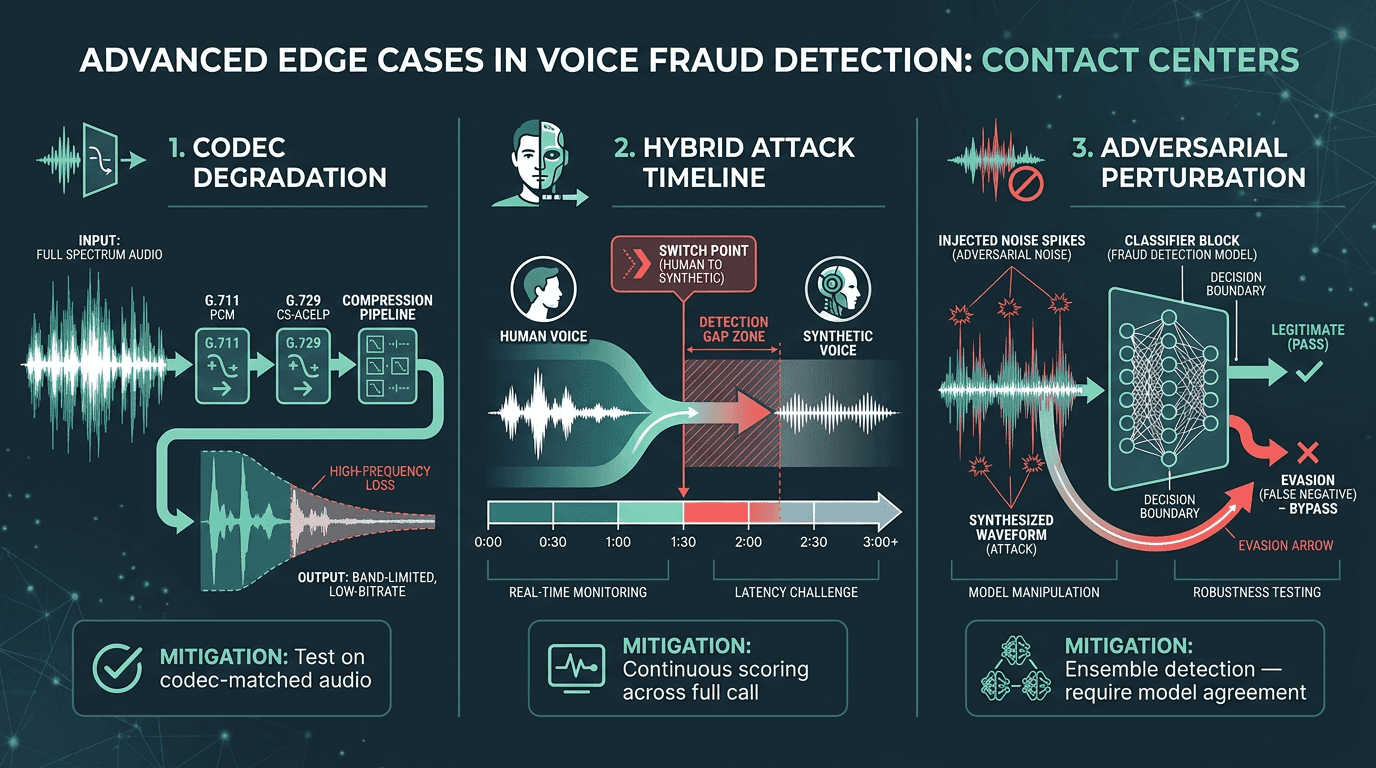
Codec degradation, mid-call voice switching, and adversarial perturbations are the edge cases most detection pipelines are not built to handle.
Market Context: Where Voice Fraud Detection Is Heading
The business side is moving with the threat. Two forces are doing most of the work: voice synthesis tools are easier to access than ever, and financial institutions are under increasing pressure to demonstrate active fraud controls on voice channels.
The tech is maturing along with it. Foundation models trained on large multilingual speech corpora are producing anti-spoofing classifiers that generalize better to novel synthesis architectures. The lag between a new TTS release and reliable detection is shrinking, even if it hasn’t disappeared. For global contact centers, multilingual coverage is not optional. Any vendor evaluation should be grounded in your actual language mix, not a generic benchmark report.
Key Takeaways and Next Steps
What to carry forward from this guide:
Voice fraud in contact centers spans three distinct attack types (synthesis, conversion, replay), and each requires different detection methods.
Real-time detection requires streaming architecture with stateful session management. Batch processing is forensics, not prevention.
Risk-stratified thresholds outperform global thresholds. Calibrate per transaction tier, not per call population.
Layer acoustic anti-spoofing, speaker verification, and behavioral signals. No single layer is sufficient.
Test your pipeline on codec-compressed audio that matches your production telephony environment.
Continuous scoring throughout the call catches hybrid attacks that start-of-call detection misses.
Plan for threshold and model refresh cycles. The threat distribution shifts every time a major synthesis model is released.
Voice fraud is solvable, but only if you treat detection like engineering work that never really “ships.” The teams that hold up under pressure are the ones that connect the agent floor to fraud ops and model owners, then run those feedback loops on a consistent cadence instead of waiting for the next incident to force a review.
If you’re building or hardening a contact center voice channel and you need speech infrastructure designed for real-time, low-latency processing, Smallest.ai's AI contact center platform is worth a look. The Atoms voice and text agent platform and the Pulse speech-to-text API are built for the streaming, session-aware architecture that voice fraud detection depends on in production. The voice agent architecture guide is a practical starting point for seeing how those components fit together.
What is voice fraud detection, and why does it matter for contact centers?
How accurate are current voice fraud detection systems?
Can voice fraud detection work without storing customer voiceprints?
How do I evaluate whether a speech AI platform is suitable for fraud detection use cases?
What regulations apply to voice fraud detection in contact centers?

