

Experience TTS clone in real-time with 30-sec voice replication and deep learning tech. Enhance content now. Click to discover more.
AI voice cloning is redefining communication, content creation, and customer interactions. From realistic voiceovers to automated customer service, businesses and creators are leveraging this technology to generate human-like speech instantly.
The global AI voice cloning market, valued at USD 2,430.3 million in 2024, is projected to skyrocket to USD 20,943.8 million by 2033—highlighting the rapid adoption of AI-powered speech synthesis across industries.
Real-time voice cloning is no longer just an experimental technology; it’s transforming media, education, gaming, accessibility, and enterprise automation. In this blog, we will explore how deep learning is reshaping AI voice cloning technology, the key challenges involved, and its real-world applications.
What is AI Voice Cloning?
AI voice cloning is the process of replicating a person’s voice using artificial intelligence. Unlike traditional text-to-speech (TTS) systems that use generic, pre-recorded voices, AI-powered voice cloning can generate speech that closely mimics the tone, pitch, and emotions of a specific speaker—even with minimal training data.
How AI Voice Cloning Works
At its core, voice cloning involves deep learning models trained on speech samples to understand and reproduce vocal characteristics. These models capture:
Pitch and Tone: The natural highs and lows of a speaker’s voice.
Speech Rhythm: The pauses and speed at which words are spoken.
Emotional Nuances: The way voice changes in different contexts (e.g., excitement, sadness).
Pronunciation & Accent: The unique way a speaker articulates words.
Real-Time vs. Traditional Voice Cloning
Traditional voice cloning methods required large datasets of recorded speech and extensive training time to produce convincing results. However, with advancements in deep learning and neural networks, modern AI can now clone a voice in real time using just a few seconds of audio input.
Aspect | Traditional Voice Cloning | AI-Based Real-Time Voice Cloning |
|---|---|---|
Data Required | Hours of recorded speech | A few seconds of audio |
Processing Time | Several hours to days | Instant, real-time synthesis |
Customization | Limited and rigid | Highly flexible and adaptive |
Emotional Expression | Often robotic and monotone | Can replicate emotions and tone |
This rapid progression has made real-time AI voice cloning accessible and scalable for various industries, from customer service automation to media production and accessibility tools.
The Deep Learning Approach Behind Real-Time Voice Cloning
AI-powered real-time voice cloning relies on deep learning architectures to accurately replicate a speaker’s voice in an instant. These models use large datasets of human speech to understand the nuances of vocal patterns, tone, and pronunciation. Let's break down the core technologies that make real-time voice cloning possible.
Key AI Technologies in Voice Cloning
1. Speech Representation Learning
Deep learning models need to extract meaningful features from human speech to clone a voice. This is done using:
Mel-Spectrograms – Converts audio into a visual frequency representation, making it easier for neural networks to process speech patterns.
Waveforms & Pitch Contours – Captures pitch variations and pronunciation.
2. Neural Network Models for Speech Synthesis
To generate high-quality tts cloned voices, neural networks are used for speech synthesis. Some of the most effective models include:
Tacotron 2 – A deep learning model that translates text into a natural-sounding speech waveform.
FastSpeech – A high-speed alternative to Tacotron that improves efficiency while maintaining voice quality.
WaveNet – A generative model developed by DeepMind that creates human-like speech by predicting the next audio sample based on previous ones.
VITS (Variational Inference Text-to-Speech) – Combines speech synthesis with variational inference, making real-time synthesis smoother.
3. Voice Embeddings and Speaker Adaptation
Instead of training a separate model for every speaker, voice embedding techniques allow AI to replicate voices using a small audio sample (5-10 seconds). The AI extracts key voice features and adapts them to generate new speech in the tts cloned voice.
Popular voice embedding methods:
Speaker Verification Models (SV2TTS) – Uses a three-step process to extract and apply voice features for cloning.
Zero-Shot Learning (ZSL) – Allows voice cloning from a speaker the AI has never seen before with just one short sample.
Transfer Learning – Improves voice adaptation by leveraging pre-trained speech models and fine-tuning them with new data.
Real-Time Latency Optimization
Real-time voice cloning requires ultra-fast processing with minimal latency. AI optimizes latency using:
Parallel WaveNet and FastSpeech models for near-instant speech generation.
On-device inference with lightweight models to reduce dependence on cloud-based servers.
AI acceleration techniques such as quantization and pruning to optimize model efficiency.
These techniques enable low-latency, high-quality voice cloning suitable for applications like customer support, media production, gaming, and accessibility tools.
Applications of Real-Time AI Voice Cloning
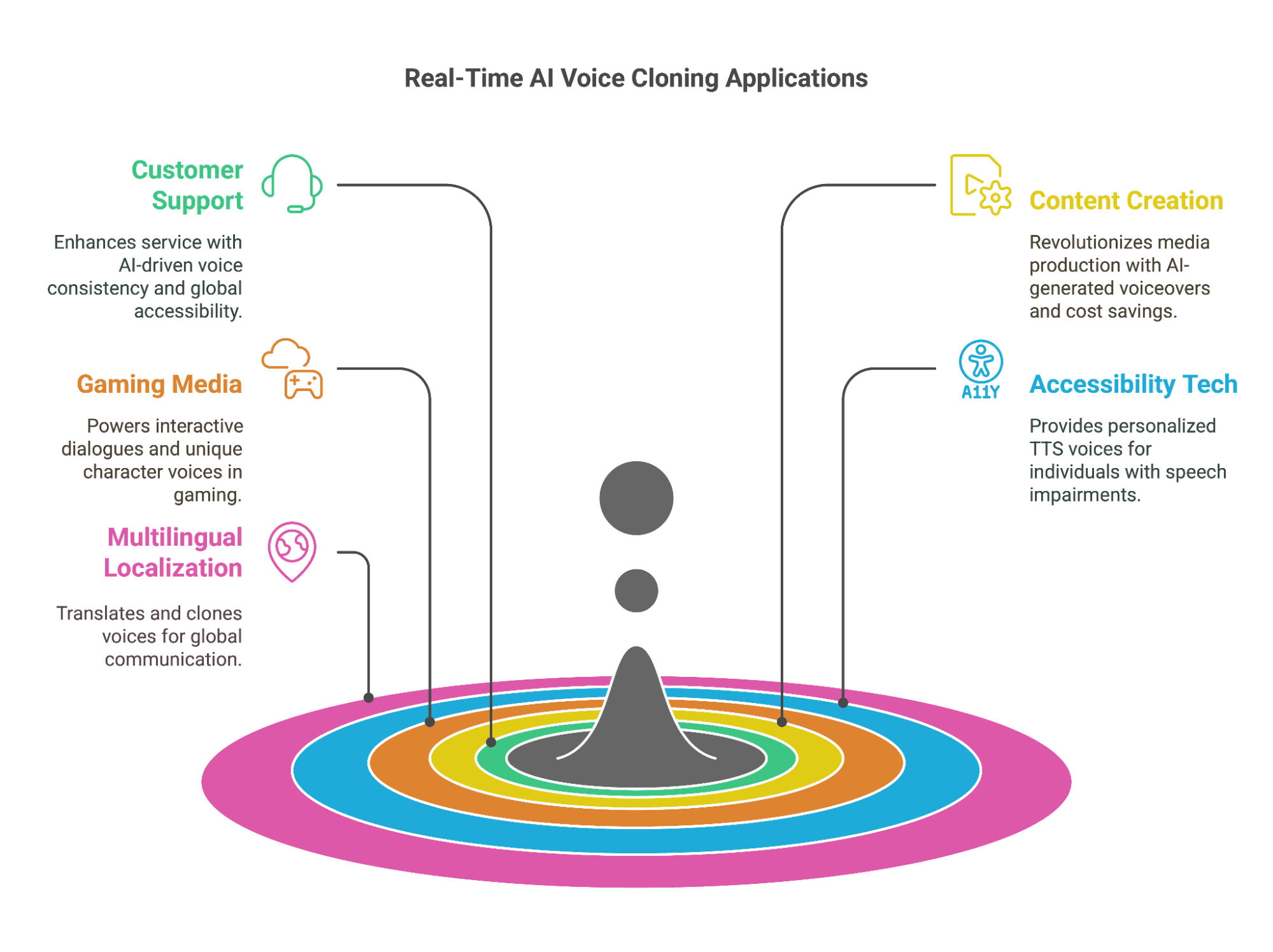
Real-time voice cloning has evolved from a futuristic concept to a practical tool used across multiple industries. With AI-driven deep learning models achieving low-latency, high-fidelity voice synthesis, businesses and developers are leveraging this technology for automation, personalization, and accessibility.
Here are the key areas where real-time AI voice cloning is making an impact:
1. Customer Support and Virtual Assistants
AI-powered customer service agents can instantly replicate a brand’s official voice, ensuring a consistent customer experience.
IVR (Interactive Voice Response) systems use tts cloned voices to guide users through automated processes, making interactions feel more natural.
AI-driven chatbots combined with voice cloning can speak in different accents and languages, offering global customer support.
2. Content Creation and Media Production
AI-generated voiceovers are revolutionizing content creation, enabling faster production of audiobooks, YouTube videos, and e-learning courses.
Voice cloning saves costs and time by eliminating the need for traditional recording sessions.
Creators can use AI to dub content into multiple languages, broadening their audience reach.
3. Gaming and Interactive Media
AI-cloned voices power NPC (Non-Player Character) dialogues in video games and virtual reality experiences.
Real-time voice cloning allows streamers and game developers to create unique AI-generated character voices dynamically.
AI-driven voice synthesis enables real-time interactions in metaverse environments and role-playing games (RPGs).
4. Accessibility and Assistive Technology
Voice cloning provides personalized text-to-speech (TTS) voices for individuals with speech impairments.
AI can generate synthetic voices for people who have lost their ability to speak, based on their past recordings.
Assistive apps use AI-cloned voices to read out documents, emails, and messages in the user’s preferred voice.
For instance, voice cloning is being used to help ALS patients retain their original voice, offering them a more personal and comfortable way to communicate.
5. Multilingual Translation and Localization
AI can translate and clone a speaker’s voice into multiple languages while preserving their original tone and speech style.
This is invaluable for global businesses, entertainment dubbing, and international marketing campaigns.
What Are the Challenges of Real-Time Voice Cloning?
Real-time AI voice cloning has made incredible advancements, but achieving high-quality, instant voice synthesis still comes with major hurdles. From latency concerns to ethical risks, these challenges impact the accuracy, efficiency, and scalability of voice cloning systems. Let’s take a closer look at the biggest obstacles:
1. Latency & Real-Time Processing Constraints
Generating human-like speech in real time requires ultra-fast processing. Traditional deep learning models for voice synthesis—such as Tacotron and WaveNet—are computationally expensive. Without optimized architectures, real-time performance suffers from high latency, making the cloned voice feel unnatural or delayed.
2. Synthetic Voice Quality & Naturalness
While AI-generated voices have improved significantly, many still lack the emotional depth and subtle nuances found in human speech. Issues like robotic intonations, unnatural pauses, or inconsistent pronunciation can make AI voices sound artificial. Achieving expressiveness and real-time adaptability remains a key challenge.
3. Voice Cloning Accuracy & Data Limitations
Most AI voice cloning models require a large dataset of recordings from a speaker to generate a high-quality replica. However, real-time applications demand instant cloning with minimal input—sometimes just a few seconds of audio. Achieving high fidelity with limited training data remains a major technical challenge.
4. Scalability for Large-Scale Applications
Businesses looking to integrate real-time AI voice cloning at scale—whether in customer service, content creation, or interactive applications—struggle with processing large volumes of audio while maintaining speed and quality. Many systems fail to scale efficiently, causing performance degradation under heavy workloads.
5. Ethical Concerns & Misuse Prevention
AI voice cloning poses serious ethical and security risks, including deepfake misuse, voice fraud, and impersonation attacks. Without proper safeguards, cloned voices can be used for malicious activities, leading to privacy violations and identity fraud. Ensuring responsible AI use, secure access, and consent-based cloning is crucial.
Advancements in Real-Time AI Voice Cloning: The Smallest AI Approach
Traditional text-to-speech (TTS) and voice cloning models have long struggled with latency, scalability, and speech quality—especially when operating in real-time applications like customer support, accessibility tools, and AI voice assistants. To address these challenges, Smallest AI has developed Lightning, a state-of-the-art, multi-lingual TTS model that pushes the boundaries of speed, efficiency, and naturalness in AI-generated speech.
Here’s how Lightning by Smallest AI overcomes the biggest challenges of real-time AI voice cloning:
1. Ultra-Low Latency & Real-Time Processing
Lightning can generate 10 seconds of high-quality speech in just 100 milliseconds, making it the fastest TTS model globally. Unlike traditional auto-regressive models that process speech step by step (causing delays), Lightning synthesizes entire audio clips simultaneously—eliminating lag and ensuring instantaneous voice output.
Real-time voice cloning for live applications (AI assistants, automated calls, interactive storytelling).
Sub-100ms latency ensures seamless, uninterrupted speech flow.
2. Natural-sounding, Emotionally Expressive Speech
Lightning achieves ultra-realistic voice synthesis by incorporating a Style Diffusor, a unique AI mechanism that models emotions, conversational tones, and speaker variations. This means:
Lifelike intonations and emotional expressions—ideal for content creation, virtual assistants, and accessibility tools.
Users can fine-tune speech style based on context, making AI-generated voices more engaging and human-like.
3. Few-Shot Learning for Instant Voice Cloning
Unlike other models requiring hours of training data, Lightning replicates a speaker’s voice from just 10 seconds of audio input. This few-shot learning capability enables:
Rapid voice cloning for personalization and branding (e.g., businesses can maintain a consistent brand voice across platforms).
Multilingual cloning, allowing a speaker’s voice to be used across different languages with accurate pronunciation.
4. Multi-Language & Accent Adaptation
Lightning is designed for global accessibility, currently supporting English and Hindi with multiple accents. Moreover, its phoneme-based input system enables:
Quick adaptation to new languages and accents—often requiring just an hour of training data for new voice styles.
Improved pronunciation accuracy, making TTS suitable for audiobooks, multilingual customer support, and global media applications.
5. Lightweight, Scalable & Easy to Deploy
Most high-quality TTS models demand significant computing power, limiting their real-time usability. However, Lightning requires less than 1GB of VRAM, making it:
Optimized for consumer devices and edge deployments—ideal for mobile apps, IoT devices, and embedded systems.
Cloud-ready with a simple REST API, eliminating the complexity of WebSocket-based integrations for developers.
6. Ethical AI Compliance & Secure Voice Watermarking
The growing risk of AI-generated deepfakes makes ethical AI voice cloning essential. Smallest AI ensures security through:
Built-in voice watermarking to prevent misuse of tts cloned voices.
Strict API-based access control, ensuring only authorized users can generate AI speech.
With Smallest AI’s Lightning TTS model, businesses and developers no longer have to choose between speed, quality, and scalability.
Conclusion
AI voice cloning in real-time has transformed industries by enhancing efficiency, reducing costs, and improving user experiences. Thanks to advancements in deep learning, voice cloning is now faster, more scalable, and highly customizable.
As businesses prioritize personalized interactions, real-time AI voice cloning presents exciting opportunities. It enables companies to deliver smooth, high-quality voice interactions that engage audiences and create lasting impressions.
However, scalability, latency, and quality remain key challenges. That’s where Smallest AI stands out. With Waves for instant voice cloning and Lightning for real-time speech synthesis, Smallest AI delivers highly customizable, near-instant AI-generated voices with minimal latency.
For businesses, developers, and content creators looking to integrate scalable, high-performance AI voice technology, Smallest AI offers an industry-leading solution—combining speed, accuracy, and affordability in a way that traditional TTS models simply can’t.
Want to experience real-time AI voice cloning firsthand? Try Smallest AI today and take your voice applications to the next level.

