Voice Activity Detection for Real-Time Voice Apps: Latency, False Triggers, and Production Tuning


Voice activity detection tuning for voice apps: pick frame sizes, thresholds, and padding to reduce latency and avoid false triggers in production.
Voice activity detection is the bouncer at the front of every real-time voice app. Before a single token hits your speech recognition engine, VAD makes a blunt call: is this audio worth processing? Nail that decision and the product feels snappy. Miss it and you either spend compute transcribing silence, or you shave off words in a way users notice instantly.
As voice interfaces move from demos to core infrastructure, voice activity detection stops being a checkbox and starts being load-bearing. This piece breaks down what VAD is doing frame by frame, where it tends to fail, how to tune it against real traffic, and what production-grade setups look like when you’re chasing both low latency and low false-trigger rates.
What Voice Activity Detection Actually Does
Voice activity detection comes down to a binary decision repeated thousands of times: is this frame speech, or not? The “binary” part is the easy description; the hard part is making that call continuously, under tight latency constraints, without knowing what the next few frames will look like.
A VAD module ingests audio in short windows (usually 10ms to 30ms) and emits a label per frame. Those labels control downstream behavior: open the gate and start streaming to ASR, close it and hold, flush, or stop. In VoIP, VAD prevents you from shipping silence across the network, cutting bandwidth and server spend. In a voice agent, it’s the signal that tells the system when the user might be done speaking and it could be safe to respond.
The catch is that VAD rarely gets clean audio. It gets whatever the mic hears: keyboard clacks, HVAC rumble, a TV in the next room, or a user who trails off to think mid-sentence. Your detector has to separate intent from chaos, in real time, without the luxury of looking ahead and “fixing it in post.”
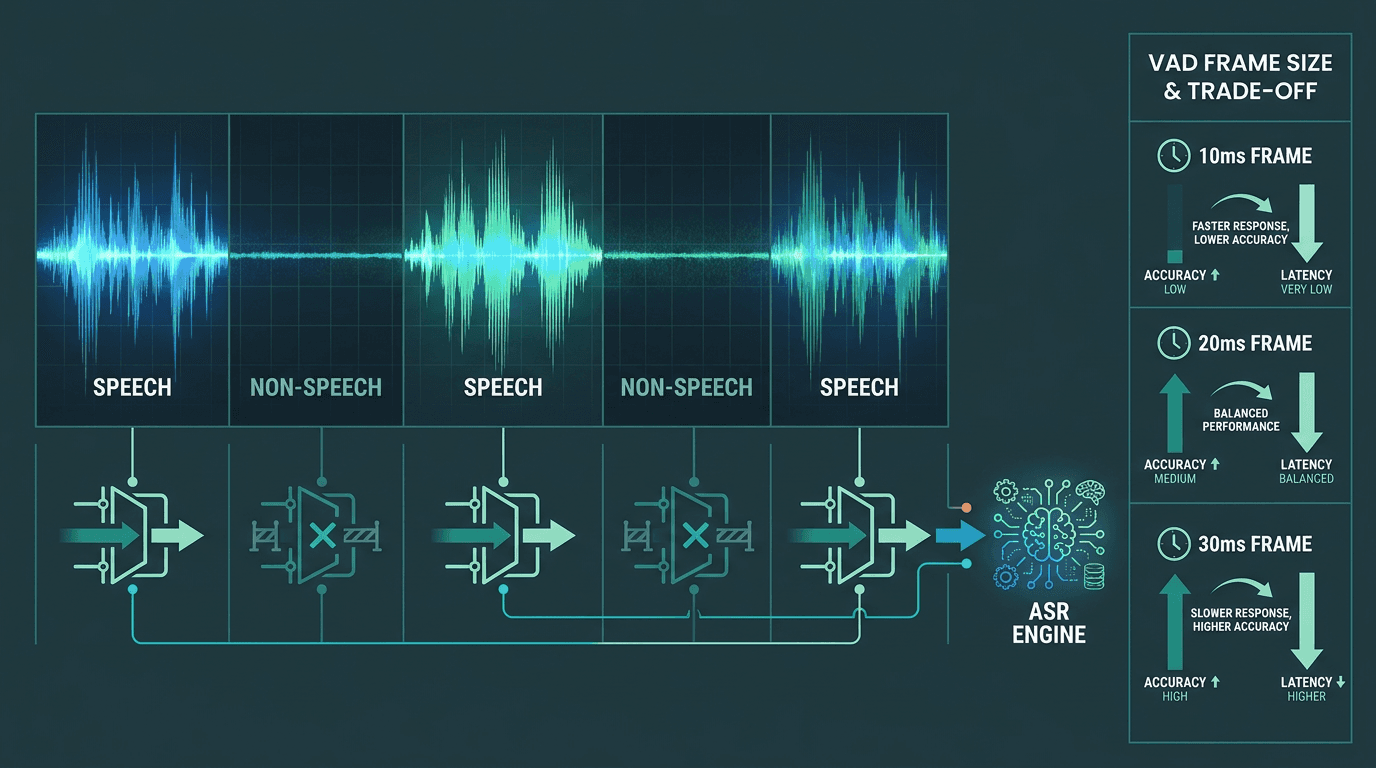
VAD classifies each audio frame as speech or non-speech before passing it to other systems.
The Latency-Accuracy Trade-off You Cannot Ignore
If you tune only one thing, it’s frame size, and that knob sits right on top of the latency/accuracy trade-off. Short frames (around 10ms) catch speech onset quickly, but they’re easier to confuse when the environment is noisy. Longer frames (around 30ms) give the classifier more context and usually behave better, but they also delay the moment your ASR pipeline gets the first “speech” signal.
This isn’t academic. While general audio engineering guidance puts acceptable one-way voice call latency in the range of 150ms, human conversational turn-taking often happens in a 200ms to 500ms window. Once you layer VAD on top of network round trips and ASR inference, small delays stack fast. A 30ms VAD frame sounds harmless until you’re building a conversational agent where users expect a response in that sub-500ms window. Now that frame is a significant fraction of the entire budget before you’ve even started decoding words.
The lesson isn’t “always pick the smallest frame.” It’s “pick a frame size that matches your audio reality.” A call center with standardized headsets can safely run more aggressive settings than a consumer mobile app that lives in kitchens, cars, and noisy sidewalks. Before you lock anything in, measure false triggers under the kinds of noise your users actually produce, not the noise you wish they had.
Classical vs. Neural VAD: Choosing the Right Approach
The WebRTC Voice Activity Detector is the baseline you keep running into for a reason: it’s widely deployed and it works. Under the hood it uses Gaussian Mixture Models (GMMs) over spectral and temporal features to decide “speech” vs “not”. The upside is straightforward: it’s cheap, runs on-device without a GPU, and its latency is easy to reason about. For many products, that’s enough.
Neural VAD, often a small recurrent model or a compact transformer, tends to hold up better when the world gets messy. Extensive research on neural voice activity detection has found that learned feature extraction often beats hand-crafted spectral features when the background noise is non-stationary. You pay for that robustness in inference cost, and in sensitive deployments you often end up needing hardware acceleration to keep the pipeline responsive.
When to prefer each approach:
Classical GMM-based VAD: Embedded or on-device deployments, tight compute budgets, controlled acoustic environments, and cases where deterministic latency matters more than noise robustness.
Neural VAD: Server-side processing with GPU availability, consumer apps where noise is unpredictable, scenarios where false triggers hit UX directly, and multilingual deployments where phoneme diversity is high.
Hybrid approaches: Some production stacks put a lightweight classical VAD in front as a first gate, then hand off to a more expensive neural model only when needed, keeping latency low while reducing false triggers.
VAD vs. Endpointing: Detecting Turns in Conversation
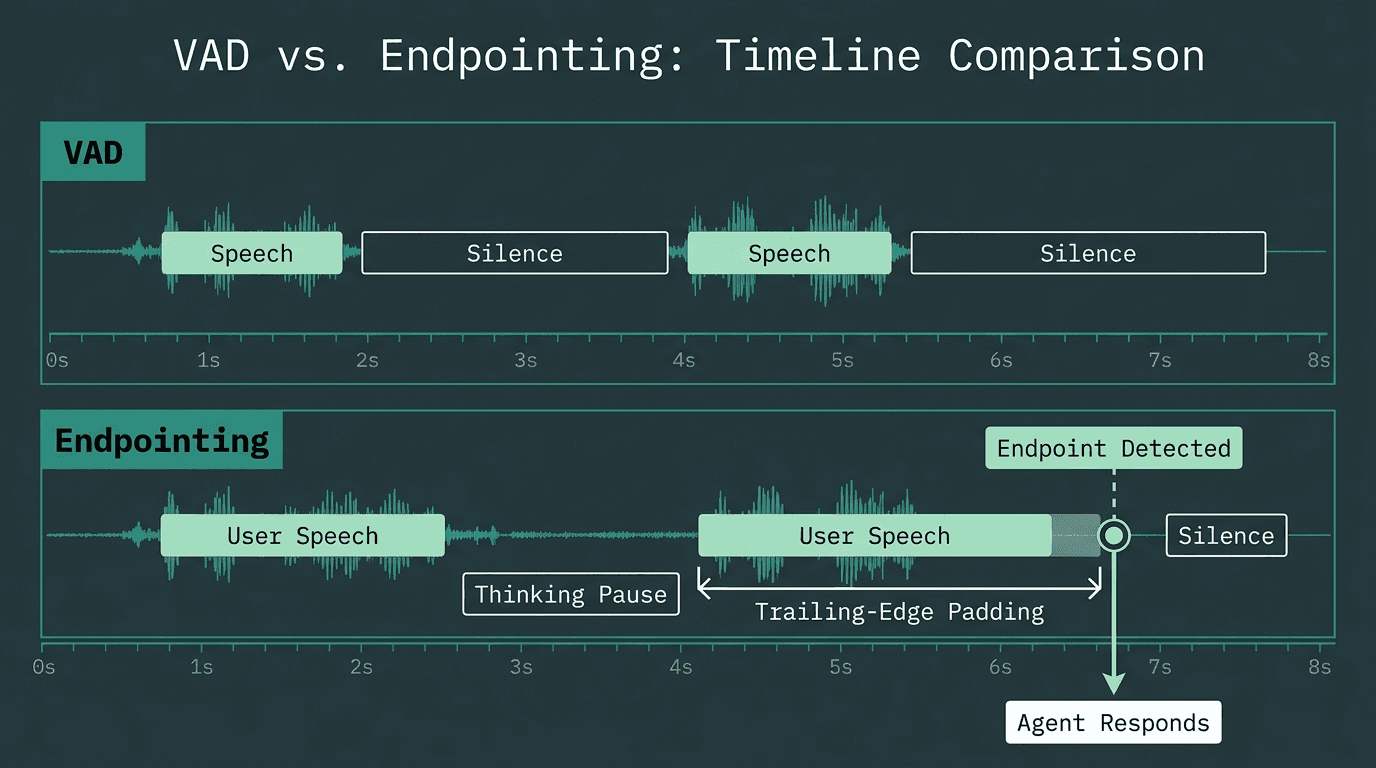
VAD detects speech activity; endpointing decides when the user's turn is over.
VAD answers the question, “Is someone speaking right now?” Endpointing (or end-of-speech detection) answers a more subtle question: “Is the user finished with their turn?” They are not the same, and confusing them is a common source of bugs in conversational AI. VAD is a low-level signal processor, classifying audio frames in real time. Endpointing is a higher-level decision process that uses VAD output, along with other cues, to manage conversational flow.
A simple endpointing strategy might just be a VAD-based rule: if there is silence for more than a set duration (e.g., 800ms), declare the turn over. This is easy to implement but often fails. A user might pause to think, causing the system to interrupt them when it tries to respond. More sophisticated endpointing logic analyzes the partial transcription, looking for semantic completeness, or uses dedicated models trained to recognize conversational turn-taking patterns. This allows the system to distinguish between a mid-sentence pause and a true end of utterance, which is critical for natural interaction.
False Triggers: Where Most Implementations Break

False positives waste compute; false negatives clip speech. Both degrade the user experience.
False triggers are where voice apps quietly lose users. A false positive (noise mislabeled as speech) pushes junk audio into ASR. Sometimes you get obvious gibberish. The more dangerous case is “reasonable” text that’s completely wrong, because it looks actionable. In a voice agent, that’s how you end up with the system responding to a cough or a door slam as if it were a request.
False negatives fail in the opposite direction: VAD misses the beginning of speech and clips the first syllable or word. People catch this immediately. They repeat themselves, over-enunciate, or stop trusting the interface. In AI voice chat products (where the whole point is conversational flow) clipped onsets don’t feel like a minor bug; they feel like the system isn’t listening.
In production, most false triggers cluster around a few repeat offenders:
Non-stationary noise: Music, television, or multiple speakers create spectral patterns that overlap with speech. GMM-based detectors trained around stationary noise tend to stumble when the noise keeps changing.
Breath and lip sounds: Acoustically, these can resemble fricatives. If your thresholds are too aggressive, you’ll “detect speech” where there isn’t any.
Hesitation sounds: “Um,” “uh,” and other fillers are speech, but they’re often quiet and short. That makes them easy to miss right at utterance start, especially when the system is tuned to avoid false positives.
Practical Tuning: Getting VAD Right in Your Pipeline
Problem | Likely cause | What to adjust |
First word gets clipped | Threshold too high / no leading padding | Lower activation threshold, add pre-roll buffer |
Agent responds too late | Padding too long / endpointing too conservative | Reduce trailing silence window |
Background noise triggers ASR | Threshold too low / weak noise suppression | Increase threshold, add noise suppression before VAD |
VAD flickers on/off | Signal near threshold | Add hysteresis smoothing |
Agent triggers on its own TTS | Echo leakage during playback | Add AEC and separate playback-mode VAD settings |
Tuning VAD isn’t about finding a universal “right” setting. It’s about mapping your actual error distribution and then deciding which mistakes you can live with. Start by logging VAD decisions alongside raw audio for a representative slice of real traffic. Synthetic test sets are useful for regression, but they rarely match the noise profiles you’ll see in the wild.
Most stacks give you two knobs that matter day to day: activation threshold (the confidence score needed to call a frame “speech”) and padding duration (how long you keep labeling frames as speech after the signal drops). Lower thresholds catch more real speech but invite more false positives. More padding protects utterance endings from being chopped, but it also delays end-of-utterance detection, which means your agent waits longer before responding.
For conversational agents, a solid baseline is 200–300ms of trailing-edge padding. It’s usually enough to ride through natural micro-pauses without keeping the pipeline open forever. On the leading edge, bias toward sensitivity. Dropping the first word is a visible quality hit; occasionally firing on a breath is annoying, but it’s easier to recover from.
If you’re building on a streaming architecture for real-time agents, VAD mistakes get expensive fast. A false positive doesn’t just waste a frame; it can kick off an entire ASR run on audio that never should’ve entered the system. That’s latency, compute, and downstream confusion, all paid for by a bad gate decision at the very start.
Advanced Considerations for Production Voice Systems
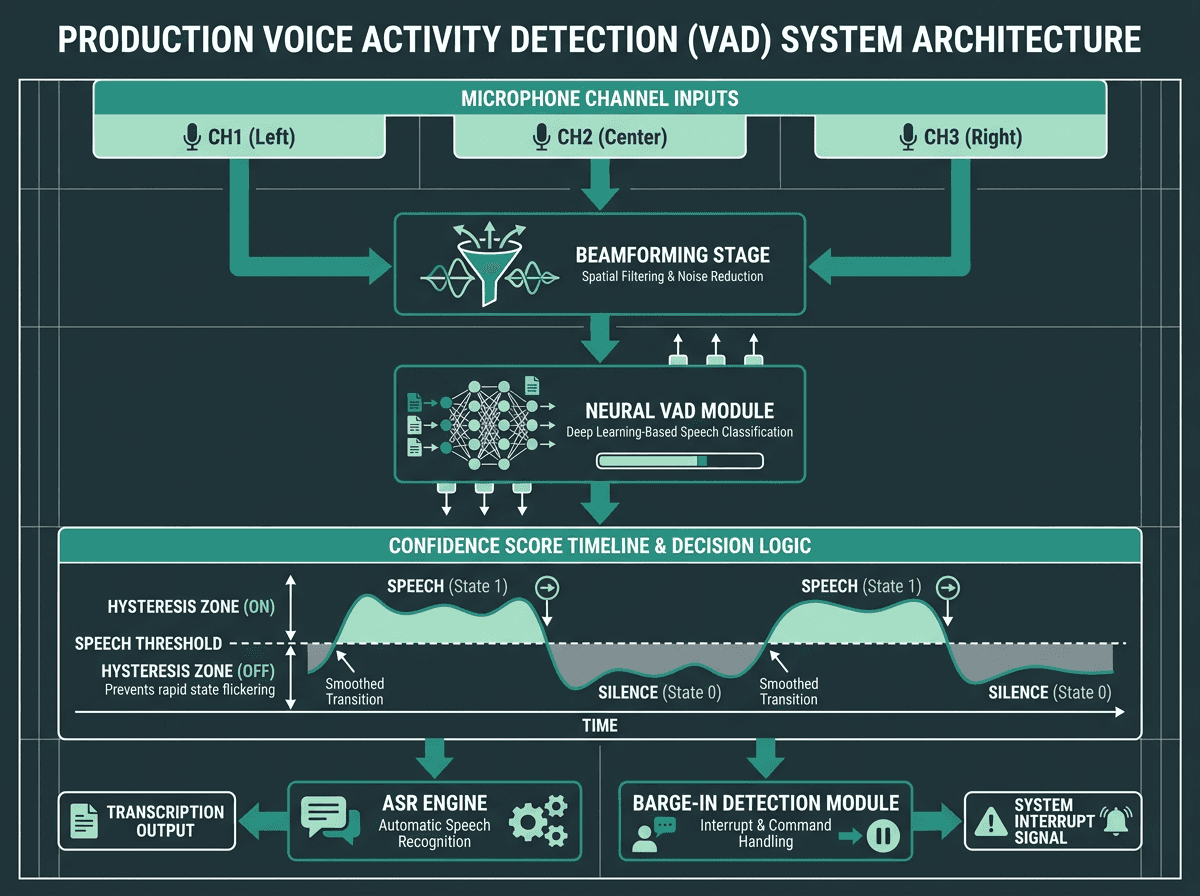
Production VAD systems often combine beamforming, neural classification, and hysteresis smoothing.
Most write-ups stop at “tune the threshold.” In production, VAD is rarely a standalone widget; it’s a component that lives inside a messy, stateful pipeline. A few integration patterns make the difference between something that demos well and something that survives real traffic.
Hysteresis smoothing is the fix for rapid toggling when the signal hovers near the decision boundary. Instead of flipping speech/non-speech on adjacent frames, you require the signal to stay above (or below) threshold for a minimum run before switching states. That one constraint removes most of the “chatter” that makes VAD output jittery and hard to use for other components.
Barge-in handling is its own category of pain for voice agents: the system is speaking and the user interrupts. Now VAD has to find the user’s voice while the agent audio is blasting from the same device or a nearby speaker. The use of acoustic echo cancellation is table stakes, but you also need separate sensitivity calibration for “during playback” vs “during silence.” Treating those as identical operating modes is a reliable way to miss interruptions or trigger on your own TTS.
Multi-channel VAD shows up wherever you have more than one microphone. The technique of beamforming improves signal-to-noise ratio by spatially filtering the signal before classification, which can materially improve SNR in noisy rooms. Feed that cleaner audio into VAD and you often cut both false positives and false negatives without touching the model. When accuracy, latency, and real-time performance are all hard constraints, this kind of front-end work tends to pay for itself quickly.
Where VAD Fits in the Broader Voice Stack
VAD is one link in a chain that usually includes acoustic echo cancellation, noise suppression, ASR, and (if you’re building a conversational system) a language model and a text-to-speech layer. Placement matters. Run noise suppression before VAD and you can often tighten thresholds because the detector sees a cleaner signal. Put VAD first and it has to be more cautious, because it’s judging raw audio with all the ugliness intact.
For real-time transcription software, VAD quality is upstream of transcription quality in a very literal sense. Frames that should have been gated out contaminate the ASR input. Frames that get gated incorrectly turn into missing words. No model can “recover” audio it never received.
The relationship between VAD and emotion detection in voice AI deserves a callout as well. Prosody-based models depend on complete, unbroken utterances, so clipped onsets or dropped low-amplitude cues can reduce the quality of downstream emotion detection.
Key Takeaways and Next Steps
The core principles to carry forward:
Frame size is your main latency lever. Smaller frames cut onset delay, but they assume cleaner audio or stronger upstream noise handling.
False positives and false negatives hurt in different ways. Set your activation threshold based on which failure mode is more costly for your product.
VAD detects speech activity, while endpointing determines when a conversational turn is complete. They are related but distinct problems.
Trailing-edge padding controls how quickly an agent can respond. 200–300ms is a sensible baseline for conversational agents.
Hysteresis smoothing removes most boundary “chatter” without changing the underlying model.
Barge-in needs separate VAD calibration for playback vs silence. Treating them the same is a common production mistake.
VAD quality sets the ceiling for other systems: transcription accuracy, emotion detection, and conversational naturalness all depend on complete, correctly segmented utterances.

Six principles that separate robust VAD implementations from fragile ones.
Conclusion
Voice activity detection is simple to describe but difficult to implement correctly at scale. Every real-time voice application operates on a latency budget, and VAD is one of the first components that can either consume or conserve it. When VAD is not configured properly, the negative effects extend beyond a slightly slower system; they impact the entire processing stack, as subsequent components must work with flawed audio segmentation. If you are developing production voice applications and need a platform with a speech pipeline engineered for performance, Smallest.ai offers Pulse for speech-to-text and Atoms for full conversational voice agents. Pulse delivers real-time transcription with low latency and high accuracy, while Atoms provides the framework for building sophisticated, responsive voice agents. Both products are designed to address the challenges of low latency, high accuracy, and scalable audio processing.
What is voice activity detection, and why does it matter for voice apps?
How does Smallest.ai handle VAD in its voice products?
What causes false triggers in voice activity detection?
What is the difference between classical and neural VAD?
How does frame size affect VAD latency and accuracy?

