How Emotion Detection Is Reshaping Voice AI (And How Traditional STT Leaves It Behind)


Learn why traditional speech-to-text loses emotional context and how Smallest AI’s Pulse STT adds built-in emotion detection for smarter call analysis.
Voice AI is rising rapidly across industries as organizations move beyond basic speech transcription to build faster support workflows, smarter automation, more natural user experiences. Analysis of conversations, be it calls, meetings, or lectures, is getting better day by day in the AI world. However, most of the systems using voice AI still depend on LLMs to understand the text-converted speech. This strategy misses out on a lot of information about how a particular sentence was spoken.
This is the gap that's driving adoption of emotion detection in voice and call analysis. Contact centers, QA teams, and customer success operations are realizing that transcripts alone create blind spots. When you only see what was said, you lose the context that predicts indicators like satisfaction or eagerness/reluctance to buy.
The reality is, emotion is the signal and not sentiment. It is measurable and structured, and it is already embedded in the audio you're processing. The question is whether you extract it or throw it away.
In this post, we break down why traditional speech-to-text loses this information, how emotion detection changes call analysis workflows, and how Smallest AI delivers it as part of Pulse STT without adding layers, delays, or guesswork.
Why Traditional Speech-to-Text Throws Away the Most Important Data
Traditional ASR pipelines are built to solve only the problem of converting speech into readable text as accurately as possible. They optimize for word error rate, normalize punctuation, and format numbers, dates, and speaker turns. All of this is outputted as a clean transcript.
But in that optimization, the acoustic features that carry emotional state get discarded. Here's how it works.
Phoneme extraction strips prosody. The encoder converts raw audio into phonetic representations, discarding the pitch contour, speech rate variation, and vocal intensity that carry emotional signal.
Decoder attention focuses on language. The decoder maximizes word-level accuracy — it attends to linguistic structure, not the spectral features (harmonic patterns) that reveal fear, sadness, or happiness.
Compression drops acoustic metadata early. To save memory and speed up inference, intermediate representations are aggressively compressed before emotional cues can be extracted.
Post-processing normalizes what's left. Punctuation restoration, number formatting, and speaker turn segmentation operate on text alone — the audio is already gone.
The result is clean transcripts built on incomplete data. QA teams flag calls after churn happens, escalation alerts fire too late, and sentiment analysis relies on text-based tools that misread sarcasm, detect false positives, and miss quiet disengagement entirely.
Emotions are not something you should quantify as part of a post-processing pipeline. They should be treated as features of the audio. This is something most STT systems were never designed to care about.
What Emotion Detection Actually Measures (and Why It Matters)
Emotion detection extracts structured, numeric signals from voice that represent emotional state across multiple dimensions. Unlike sentiment analysis, which tries to label entire interactions as "positive" or "negative," emotion detection returns per-emotion confidence scores for distinct categories:
Happiness – Warmth, satisfaction, openness
Sadness – Disappointment, resignation, low energy
Disgust – Rejection, aversion, dismissiveness
Fear – Uncertainty, anxiety, stress
Anger – Frustration, irritation, escalation risk
These scores are probabilistic, not binary. A single utterance can register moderate anger (0.65) alongside low fear (0.15) and negligible happiness (0.02). That granularity is what makes emotion detection operationally useful.
Where This Drives Real Impact
When you analyze recorded calls, emotion detection transforms what's possible:
Run systematic QA on 100% of calls – Flag emotional spikes (anger, fear) for targeted review rather than random sampling.
Score agent performance based on emotional trajectory – Identify which agents consistently de-escalate vs. which ones trigger frustration.
Enrich customer analytics pipelines – Tag CRM records with emotion profiles to predict churn, refine segmentation, and inform next-best-action models.
Train better models and scripts – Use emotion-labeled transcripts to refine coaching materials, identify high-risk phrases, and build escalation playbooks.
Support compliance and risk management – Surface calls where fear or anger indicate potential disputes, regulatory exposure, or reputational risk.
Most contact centers already record, store, and analyze calls post-interaction. Emotion detection makes that analysis context-aware rather than purely textual.
And the important part is that no one else in the market is delivering this at the transcription layer.
How Smallest AI Built Emotion Detection Into the STT Stack
Most platforms treat emotion detection as a separate service. You transcribe the call, export the audio, send it to an emotion API, and stitch the outputs back together. That introduces latency, cost, and integration overhead. It also means emotion scores and transcripts live in different systems, making correlation fragile and manual.
Smallest AI takes a different approach. Emotion detection is part of the speech-to-text response. You send audio to Pulse STT, and you get back transcription plus per-emotion confidence scores in a single API call.
Why This Architecture Matters
Single-Pass Processing: Audio is analyzed once, extracting both linguistic and paralinguistic features simultaneously.
Consistent Timestamps: Emotion scores and transcripts are naturally aligned because they come from the same audio segment.
Lower Latency: No round-trip to a secondary emotion API means faster results, even in batch.
Unified Data Model: Emotion sits alongside transcription in the same JSON response, making it trivial to store, query, and correlate.
This is a voice-native approach. Emotion is not an add-on. It's part of how Pulse STT interprets speech.
Real Use Cases (How Teams Use Emotion Detection in Production)
Emotion scores are only useful if they trigger action. Here's how contact centers, QA teams, and analytics operations use emotion detection from Pulse STT in practice.
1. Risk-Based QA Sampling
Instead of reviewing 2% of calls at random, QA teams flag calls where anger or fear exceed thresholds (e.g., > 0.60). This surfaces high-risk interactions for review while ignoring routine, low-emotion calls.
Impact: Reduced QA workload, faster identification of escalation patterns, better coaching targeting.
2. Agent Performance Benchmarking
Emotion trajectories show whether agents calm callers or escalate them. By comparing emotion scores at call start vs. call end, managers identify which agents consistently resolve tense situations and which ones struggle.
Impact: Data-driven coaching, clearer performance differentiation, reduced turnover from subjective feedback.
3. Churn Prediction and CX Analytics
Emotion scores feed into customer health models. High sadness + low happiness correlates with churn. High anger predicts complaints. These signals enhance CRM records and inform proactive outreach.
Impact: Earlier intervention, better segmentation, improved retention outcomes.
4. Compliance and Dispute Flagging
Calls with sustained anger or fear are flagged for compliance review, especially in regulated industries like debt collection, insurance, or healthcare. Emotion becomes an early warning system for potential disputes.
Impact: Reduced legal exposure, faster dispute resolution, stronger audit trails.
5. Training Data for AI Models
Emotion-labeled transcripts become training data for summarization models, sentiment classifiers, and agent assist systems. This improves model accuracy and reduces false positives in escalation detection.
Impact: Better AI models, more reliable automation, fewer human-in-the-loop interventions.
Why No One Else Is Doing This (and Why That Matters)
The market reality is that most STT providers don't expose emotion detection at all. And the ones that do treat it as a separate API layer with separate pricing, separate integrations, and separate data models.
That's not a technical limitation. It's an architectural choice.
Traditional STT platforms optimize only for text accuracy. They're built on encoder-decoder architectures that maximize word-level precision and minimize compute cost. Emotion detection requires access to raw acoustic features before they're compressed into phonemes and words. Most systems discard those features early in the pipeline to save memory and speed up inference.
Rebuilding the stack to preserve and analyze those features is expensive. It requires different model architectures, different training data, and different inference pipelines. Most vendors don't see the ROI, so they outsource emotion detection to third-party APIs or ignore it entirely.
Smallest AI built Pulse STT with paralinguistic signals as a first-class feature. The architecture is designed to extract emotion, speaker attributes, and acoustic metadata alongside transcription—without sacrificing speed or accuracy.
This is why Pulse STT can return emotion scores in the same response as the transcript. And why no other STT provider delivers this level of integration.
If you're building voice analytics, QA systems, or customer intelligence pipelines, that integration matters. It's the difference between patchwork data flows and a unified voice understanding layer.
Conclusion
At the end of the day, transcripts are necessary but insufficient. They tell you what was said. They don't tell you how it was said. It matters in contact centers, sales calls, and customer support, where feelings drive outcomes and future strategy.
Emotion detection closes that gap. It turns voice into structured, actionable data that supports better QA, smarter analytics, and earlier intervention. And when it's built into the STT layer, it becomes infrastructure rather than integration overhead.
Smallest AI delivers emotion detection as part of Pulse STT—no separate APIs, no data stitching, no guesswork. Just clean, consistent, confidence-scored emotion signals alongside every transcript.
If your team is analyzing recorded calls and building on transcription data, you're already halfway there. The question is whether you're capturing the full signal—or leaving the most predictive data on the floor.
Try It Yourself
Ready to see emotion detection in action? Head over to our quickstart guide on getting started with Smallest AI speech to text transcription. You can read emotion detection's feature page to enable it in your transcription requests.
We've also built an open-source example you can run in minutes.
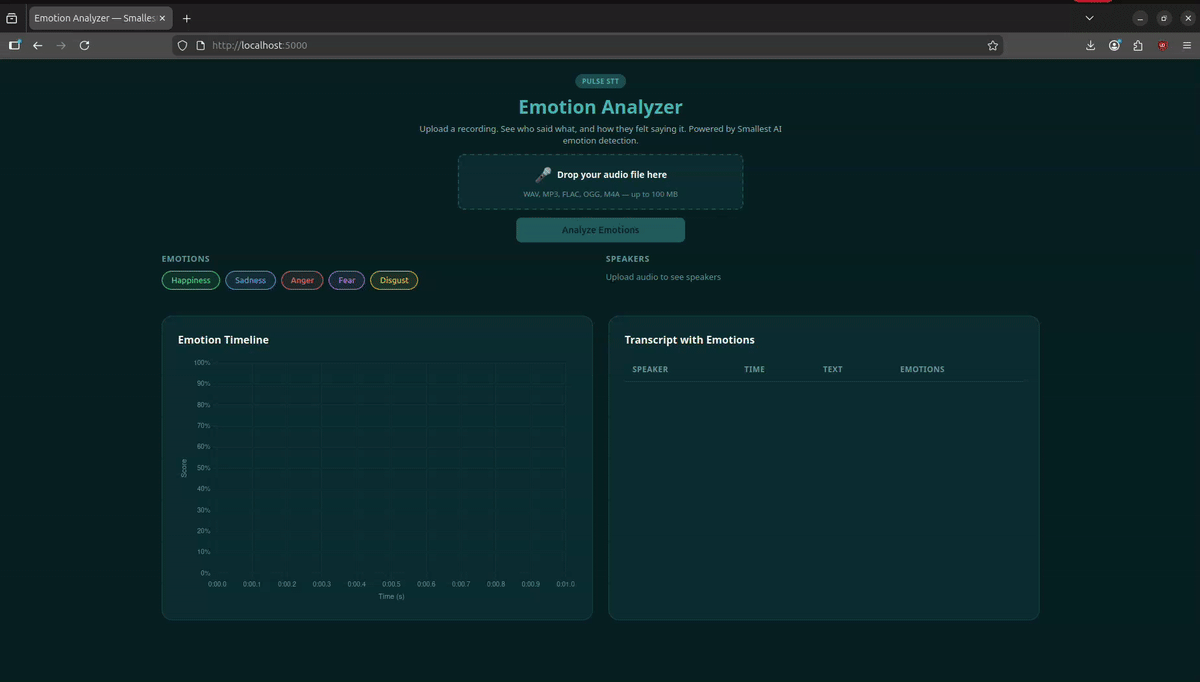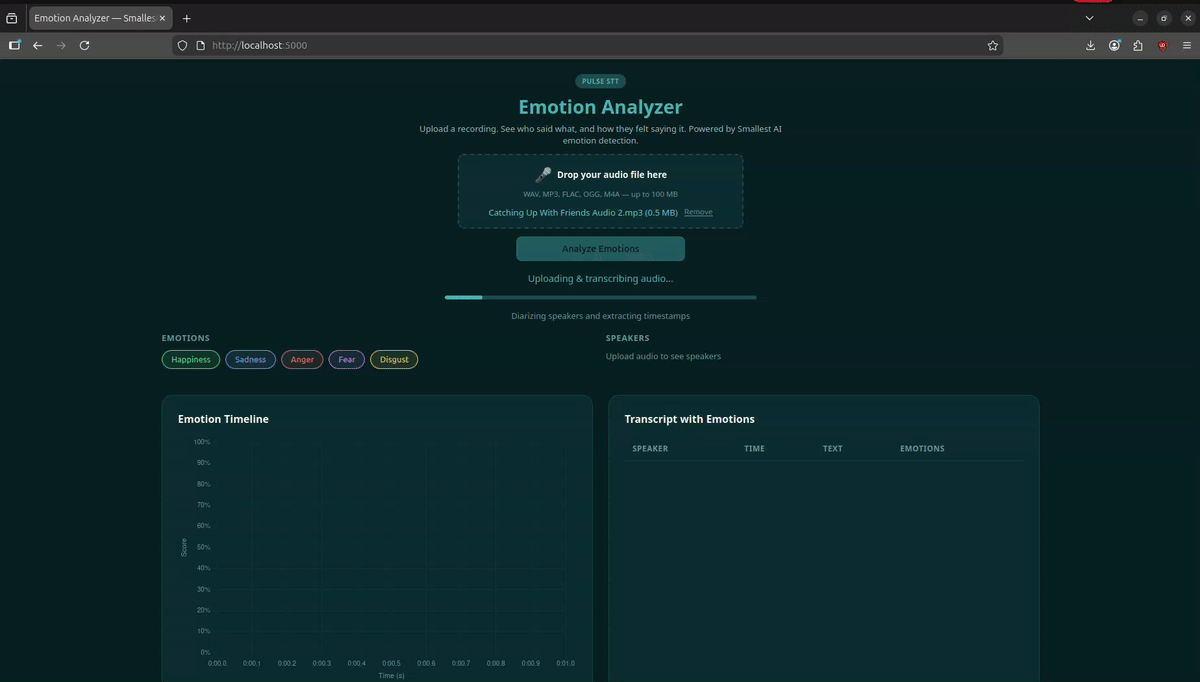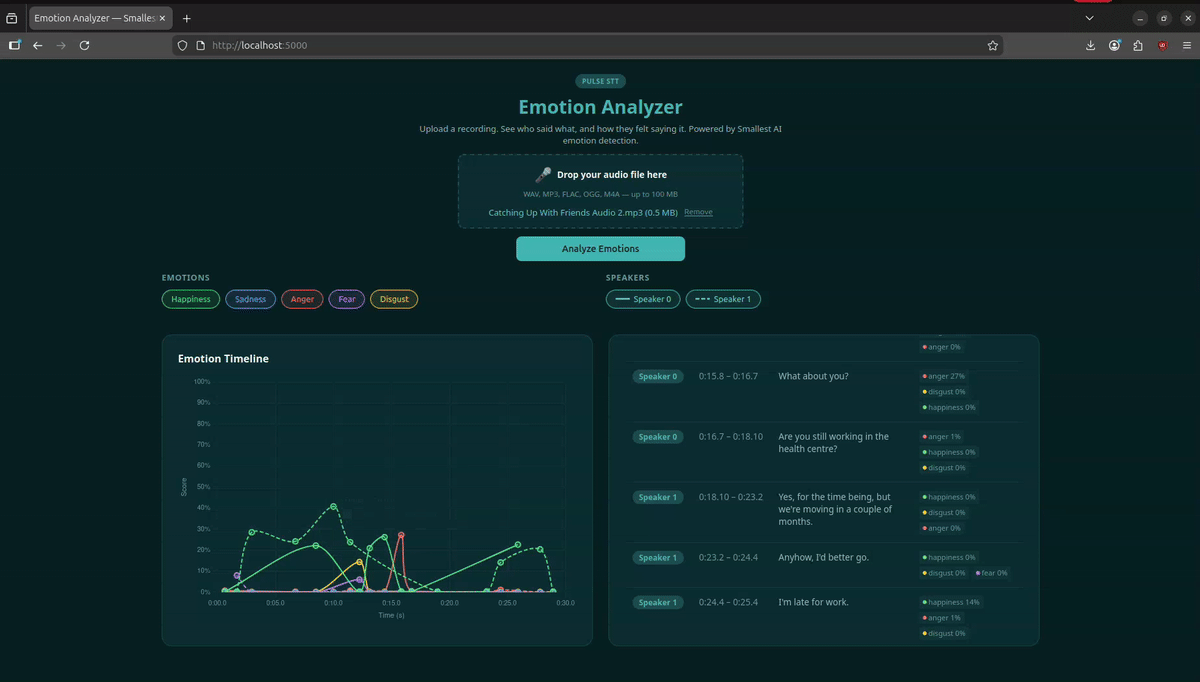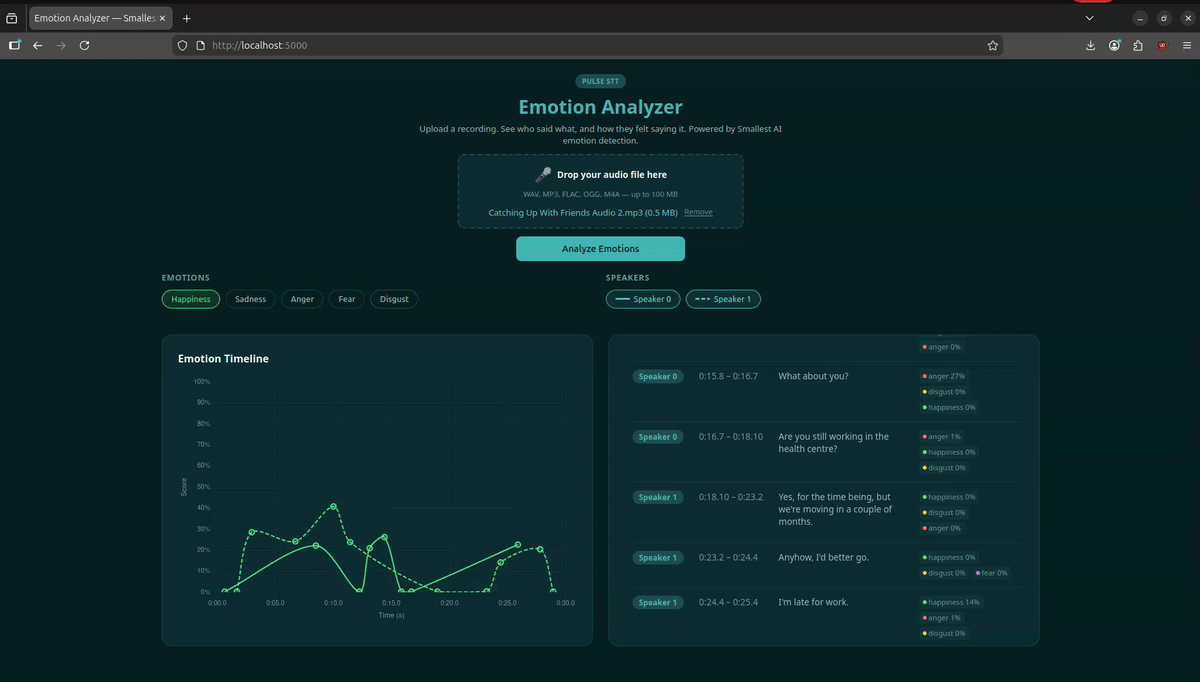
You can upload a recording and visualize all the speakers' emotions across the conversation with interactive timeline charts, speaker filters, and a full diarized transcript.
Find the source code in our cookbooks open source repository here.

