A Complete Guide to Fast AI Speech Recognition for Live Transcription


Unlock fast AI speech recognition for real-time transcription with Azure's API. Capture audio, explore error correction, and enhance accuracy now!
If you are exploring fast AI speech recognition, it usually reflects a practical need rather than simple curiosity. Teams assessing voice workflows often require real-time transcription, live call handling, or AI agent automation before committing to budgets or enterprise-scale deployments.
The demand for real-time voice intelligence is growing rapidly. According to study reports, the global AI-powered speech recognition market is expected to reach USD 53.67 billion by 2030, driving higher expectations for instant transcription, contextual understanding, and workflow automation in customer service, healthcare, and enterprise operations. This trend encourages organizations to experiment with fast AI speech recognition to evaluate speed, accuracy, and integration before scaling.
In this guide, we explain how fast AI speech recognition works, its key features, and which solutions are best suited for early testing versus long-term implementation.\
Key Takeaways
Fast AI Speech Recognition Is Enterprise-Driven: Real-time deployments where latency, uptime, and compliance affect outcomes.
Low Latency Is Critical: Sub-300ms response times determine success in live customer support, healthcare, and sales workflows.
Edge and Hybrid Deployments Are Rising: Privacy, offline reliability, and deterministic performance drive adoption.
Regulated Verticals Gain Maximum Value: Healthcare, BFSI, and enterprise automation see the highest ROI.
Architecture Beats Model Size: Specialized, task-focused models outperform large general-purpose LLMs in live production environments.
What Is Fast AI Speech Recognition?
Fast AI speech recognition is a real-time voice intelligence system that converts spoken communication into structured signals that software platforms can interpret and act on immediately. Instead of waiting for post-call processing or delayed transcription, modern engines continuously analyze speech, enabling applications to respond while conversations are still active.
To understand how this modern approach differs from earlier speech tools, it helps to look at how continuous processing changes real-world communication, automation, and voice-based interaction workflows.
Audio streams are analyzed continuously rather than processed only after recordings are completed
Speech intelligence extracts meaning, conversational signals, and user goals during active dialogue
Voice interactions can initiate automated processes, trigger system actions, and update workflows instantly
Recognition systems adapt to natural conversation patterns, mixed languages, regional accents, and varied speaking speeds
Live monitoring captures conversation flow, behavioral cues, and interaction dynamics as they occur
Flexible system architecture connects easily with AI agents, communication platforms, automation engines, and operational software
Today’s real-time speech technology functions, such as Pulse STT, as a live processing layer within communication systems.
It supports interactive voice agents, instant meeting intelligence, automated call workflows, live captioning, and voice-driven operations that require immediate decision-making and action.
Also Read: AI Voice Cloning in Real-Time: A Deep Learning
Now that we know what it does, let’s compare it with traditional speech recognition to see why real-time processing matters.
Fast AI Speech Recognition vs Traditional Speech Recognition: Key Differences
While conventional systems mainly focus on converting spoken words into text, fast AI platforms process speech in real time, understand context, and enable immediate actions.
The following table outlines the key differences between fast AI speech recognition and traditional speech recognition, showing how modern systems improve accuracy, speed, and integration across real-world applications.
Feature | Fast AI Speech Recognition | Traditional Speech Recognition |
Processing Speed | Real-time, low-latency processing for live conversations | Processes audio after recording; often delayed |
Context Understanding | Interprets meaning, detects intent, and follows conversation flow | Focuses mainly on word-for-word transcription |
Accuracy Across Accents & Languages | Adapts to multiple accents, languages, and informal speech patterns | Limited support for diverse accents and languages |
Integration with Systems | Connects directly with AI agents, automation platforms, and voice-driven workflows | Typically standalone; requires manual integration |
Automation & Action | Triggers workflows, actions, and analytics during live conversations | Cannot initiate actions automatically; only outputs text |
Noise Handling | Maintains performance in noisy or unpredictable environments | Accuracy drops in noisy conditions or overlapping speech |
Analytics & Insights | Captures intent, sentiment, and conversational insights in real time | Provides raw transcripts; post-processing required for insights |
Use Cases | Customer support, AI-powered phone agents, live transcription, automated workflows, multilingual meetings | Dictation, meeting notes, basic transcription tasks |
Once you see the differences, let’s explore how fast AI speech recognition actually works in real-time systems.
How Does Fast AI Speech Recognition Work in Real-Time Systems?

Instead of isolated steps, modern voice systems connect transcription, reasoning, and voice output into one unified conversational AI workflow. Fast AI speech recognition operates as a continuous, real-time processing loop in which spoken input is captured, interpreted, processed, and translated into actions or responses within seconds.
Here’s how a modern fast AI speech recognition system functions from start to finish.
1. Live Voice Input and Streaming Capture
The process begins when audio is captured through microphones, call streams, or digital voice channels. Real-time streaming ensures speech is processed immediately rather than stored for later analysis.
Key elements that influence performance include:
Audio clarity and microphone quality
Background noise levels and echo control
Speaker accents, pacing, and tone variation
Network reliability and streaming stability
Technologies like Pulse focus on low-latency streaming to keep conversations fluid during live interactions.
2. Instant Speech-to-Text Processing
Once audio is captured, speech recognition models convert spoken language into structured text while the conversation is still ongoing. The system continuously analyzes speech patterns and predicts word sequences to maintain accuracy.
Core processing methods include:
Acoustic pattern analysis to match spoken sounds with language units
Adaptation to accents and pronunciation differences
Predictive language modeling to improve sentence flow
Context-aware transcription to reduce recognition errors
3. Context Analysis and Intent Recognition
After transcription, lightweight reasoning models such as Electron analyze the text to identify intent, entities, and conversational meaning. This step allows systems to interpret what the speaker wants rather than simply record what was said.
Key functions include:
Intent classification and conversation tracking
Entity and keyword extraction for actionable data
Sentiment and interaction pattern analysis
Real-time planning of next responses or system actions
4. Automated Decision Logic and Workflow Execution
Once intent is detected, the system automatically triggers operational actions. These actions connect voice interactions with backend processes and business systems.
Typical outcomes include:
Initiating automated workflows or task execution
Routing calls, tickets, or internal requests
Updating CRM or enterprise applications
Managing scheduling, support operations, or transaction handling
Platforms such as Atoms enable businesses to automate recurring tasks and operational workflows during live conversations.
5. Real-Time Voice Response and Speech Generation
When a spoken reply is needed, Lightning generates natural voice responses instantly, maintaining conversational continuity. Systems like Hydra combine listening, reasoning, and speaking into one speech-to-speech interaction cycle.
Key capabilities include:
Sub-100 millisecond response speed for near real-time dialogue
Natural voice generation for human-like conversations
Multi-language communication for global interactions
Continuous speech-to-speech processing for seamless voice exchanges
Also Read: Evaluating Lightning ASR Against Leading Streaming Speech Recognition Models.
With the workflow explained, let’s examine practical applications of fast AI speech recognition.
5 Practical Applications of Fast AI Speech Recognition
Fast AI speech recognition is now used to support real-time operations where immediate transcription, automation, and voice-driven interaction improve speed and workflow efficiency. Instead of waiting for post-processing, teams act while conversations are still active.
Here’s how fast AI speech recognition is applied across key functions today.
1. Real-Time Customer Interaction Management
Fast speech recognition helps support teams manage live conversations more effectively by providing instant visibility and automation.
Live transcription gives agents immediate conversation context.
Automated IVR flows respond to spoken requests without manual input.
Supervisors monitor interactions in real time for quality control.
Voice automation handles repetitive inquiries during active calls.
Business Insight: Shorter handling times, smoother interactions, and more consistent service delivery.
2. Digital Media Production Workflows
Content teams use fast speech recognition to accelerate content creation and manage spoken content more efficiently.
Interviews and recordings convert into transcripts instantly.
Production teams can quickly search for spoken content during editing.
Interactive media platforms respond to real-time voice input.
Live captioning supports accessibility and audience engagement.
Business Insight: Faster production timelines and improved content accessibility.
3. Clinical Communication and Medical Documentation
Healthcare professionals rely on fast speech recognition to reduce manual documentation and maintain accurate records during live interactions.
Voice-based patient intake simplifies administrative processes.
Consultations are transcribed instantly for clinical documentation.
Medical staff interacts with systems using spoken commands.
Telehealth sessions generate structured notes automatically.
Business Insight: Reduced paperwork, improved workflow efficiency, and clearer medical documentation.
4. Voice-Driven Commerce and Sales Support
Fast AI speech recognition enables real-time interaction throughout sales and purchasing journeys.
Voice assistants help customers browse and place orders naturally.
Automated systems handle delivery updates and transaction confirmations.
Sales calls are transcribed live for faster follow-up actions.
Spoken interactions trigger CRM updates automatically.
Business Insight: Increased sales efficiency and quicker customer response cycles.
5. Operational Intelligence and Live Business Insights
Organizations use fast speech recognition to capture insights directly from meetings and conversations as they happen.
Live meeting transcription supports collaboration and record-keeping.
Voice queries retrieve analytics from dashboards instantly.
Real-time keyword detection flags risks or compliance issues.
Speech analytics converts conversations into actionable operational insights.
Business Insight: Faster operational decisions and improved oversight of business activities.
Overall, fast AI speech recognition now functions as a real-time operational layer that connects spoken conversations with automation, analytics, and workflow execution across industries.
Once we understand applications, let’s look at future trends and why teams choose fast AI speech recognition.
Future Direction of Fast AI Speech Recognition and Real-Time Voice AI
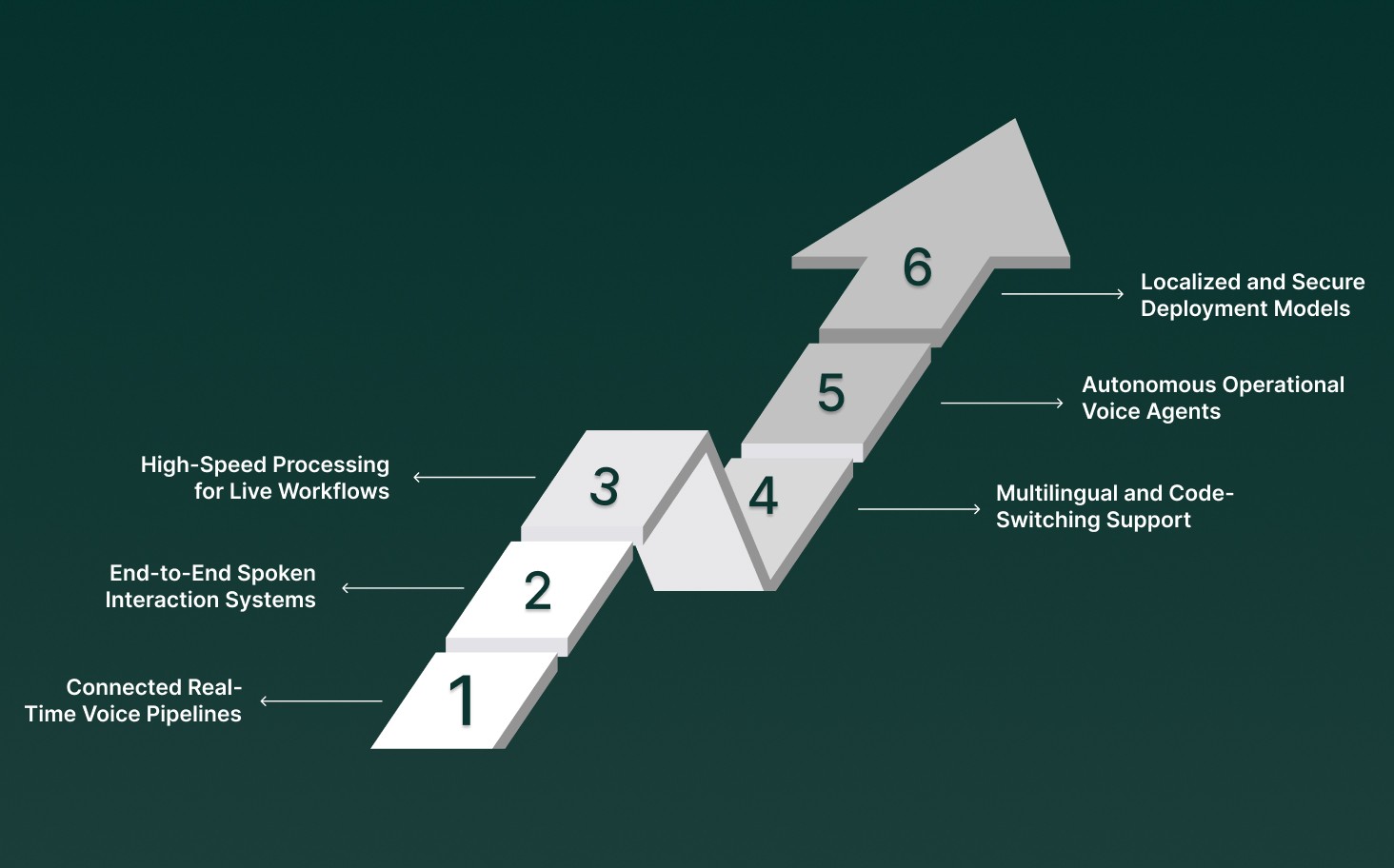
With integrated technologies such as Pulse for transcription, Lightning for voice output, Electron for conversational reasoning, and Hydra for speech-to-speech interaction, the industry is moving from standalone transcription tools to complete real-time voice platforms.
Key developments shaping the next phase include:
Connected Real-Time Voice Pipelines: Pulse handles instant transcription, Electron processes context and intent, and Lightning generates natural responses, keeping conversations continuous with minimal delay.
End-to-End Spoken Interaction Systems: Hydra enables systems to listen, interpret, decide, and respond within a single speech cycle, reducing layered processing and enabling smoother, real-time dialogue.
High-Speed Processing for Live Workflows: Pulse delivers immediate transcription for live calls, analytics, and automation, while Lightning supports rapid voice responses required for IVRs and AI voice agents.
Multilingual and Code-Switching Support: Advanced speech models manage mixed-language conversations and dialect shifts naturally, improving performance across global and multilingual environments.
Autonomous Operational Voice Agents: Fast speech recognition, combined with reasoning models like Electron, powers AI agents that manage inquiries, scheduling, and backend actions during active conversations.
Localized and Secure Deployment Models: Edge, on-device, and hybrid processing reduce response time while supporting data governance, regulatory compliance, and secure handling of sensitive voice interactions.
These trends indicate that fast AI speech recognition will become the backbone of real-time enterprise communication.
Why Voice Teams Are Choosing Fast AI Speech Recognition Like Pulse STT for Real-Time Transcription?
As voice technology becomes embedded in daily operations, teams are moving away from systems designed for delayed processing and shifting toward platforms built for live execution. Fast AI speech recognition, including solutions like Pulse STT is gaining adoption because it delivers immediate transcription that keeps pace with real-time conversations, automation workflows, and high-volume customer interactions.
Voice leaders evaluating fast AI speech recognition platforms such as Pulse STT for real-time transcription typically focus on the following decision drivers:
Continuous Live Transcription Performance: Speech is processed in real time, enabling teams to respond during live interactions rather than wait for post-call transcripts.
Lightweight Models Built for High-Speed Execution: Focused recognition models maintain stable accuracy during rapid conversations, multilingual discussions, and sustained operational workloads.
Real-Time Voice Automation Compatibility: Instant transcripts integrate seamlessly with agent-assistance tools, live captions, compliance monitoring, and automated voice workflows.
Large-Scale Voice Processing Capacity: Platforms are structured to manage massive volumes of simultaneous audio streams while maintaining consistent speed and reliability.
Deployment Flexibility for Secure Operations: Edge, on-premise, and hybrid environments help reduce processing delays while supporting organizational governance and regulatory standards.
Immediate Conversation Intelligence: Fast transcription enables instant keyword alerts, sentiment monitoring, and operational insights, allowing teams to respond while conversations are still active.
Voice teams are turning to fast AI speech recognition platforms like Pulse STT because real-time transcription has become essential to modern voice operations. When speed, uptime, and continuous processing matter, platforms built for production-grade execution stand out as foundational infrastructure rather than experimental tools
Conclusion
Fast AI speech recognition is becoming the base layer of modern voice systems. Teams that treat fast AI speech recognition as essential infrastructure see quicker real-time transcription, better control over delays, and platforms that stay stable under real traffic. The market will continue to grow, but the gap will increase between tools made for demos and systems built for live, large-scale voice operations.
When teams start testing real-time transcription in real conditions, Pulse STT becomes part of the discussion. With fast response times, flexible deployment options, and strong support for compliance and uptime, Smallest.ai focuses on reliable production voice workflows instead of experimental setups.
See how Lightning, Pulse STT, and real-time voice agents can work within your existing stack and notice the difference when delays no longer slow conversations. Reach out to learn more.
How does fast AI speech recognition reduce delays in real-time transcription?
Why is ultra-low latency more important than perfect accuracy in live voice systems?
How does fast AI speech recognition manage background noise and multiple speakers?
What technical setup supports fast AI speech recognition at high scale?
How does fast AI speech recognition streamline contact center operations?

