
Evaluating Lightning ASR Against Leading Streaming Speech Recognition Models


This benchmark evaluates streaming ASR performance across nine languages, comparing SmallestAI, Deepgram Nova, and GPT-4o Mini Transcribe using real-world audio sources. The study highlights differences in word error rate (WER) under various conditions, providing actionable insights for multilingual voice applications and developers seeking robust transcription solutions.
Lightning ASR Overview
Lightning ASR is Smallest AI's streaming-first model optimized for sub-300ms latency across 15+ languages. It features adaptive noise suppression, speaker diarization, and punctuation restoration while minimizing compute requirements
We benchmarked streaming transcription models across multiple languages to see how they perform in real-world, low-latency conditions. Unlike offline transcription, streaming ASR needs to be accurate and fast, making this evaluation especially important for live use cases.
Deepgram (Nova 3, and Nova 2 for Polish)
OpenAI GPT-4o Mini Transcribe
SmallestAI Lightning ASR
*AssemblyAI’s streaming model was excluded since it currently supports only English.
All tests were run in streaming mode with a curated multilingual dataset covering different accents, speaking styles, and vocabularies.
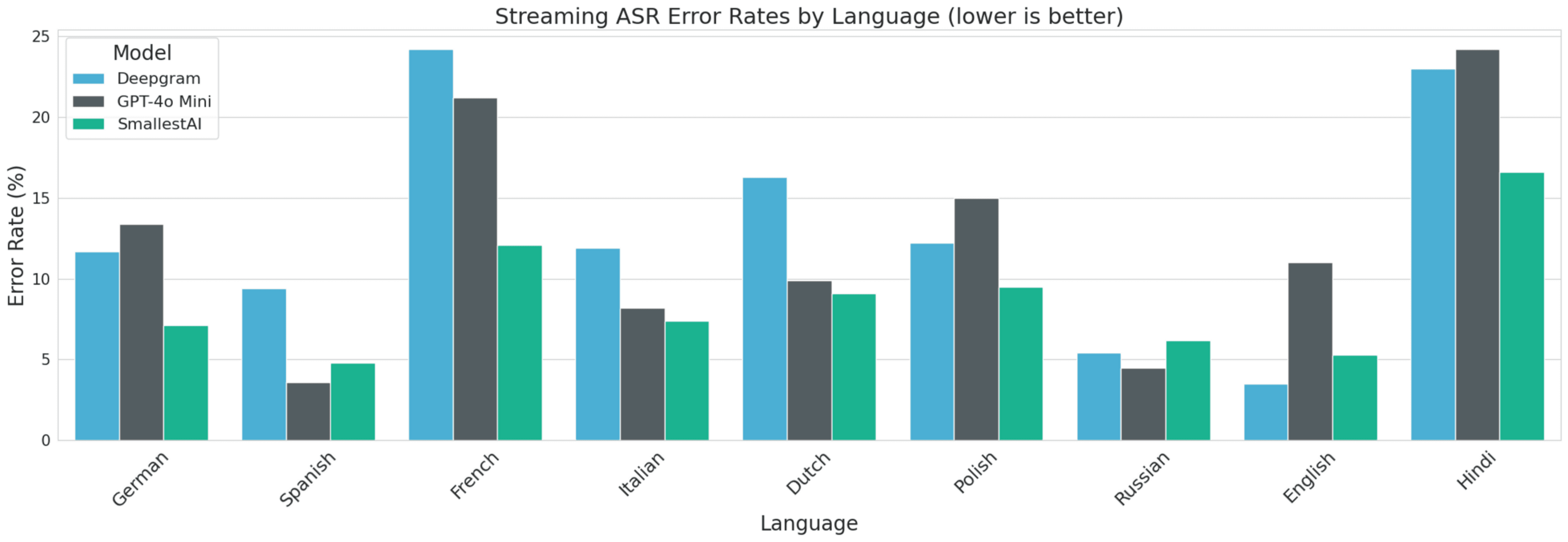
Results - Word Error Rate (lower is better)
Language | Deepgram Nova | GPT-4o Mini | Lightning ASR |
|---|---|---|---|
de - German | 11.7% | 13.4% | 7.1% |
es - Spanish | 9.4% | 3.6% | 4.8% |
fr - French | 24.2% | 21.2% | 12.1% |
it - Italian | 11.9% | 8.2% | 7.4% |
nl - Dutch | 16.3% | 9.9% | 9.1% |
pl - Polish | 12.2% | 15.0% | 9.5% |
ru - Russian | 5.4% | 4.5% | 6.2% |
en - English | 3.5% | 11.0% | 5.3% |
hi - Hindi | 23.0% | 24.2% | 16.6% |
Category wise WER
Note: Category-wise analysis uses English-only data since accented speech samples are only available in English, ensuring uniform comparison across all categories.
Model | Accented | Technical | Rapid Speech | Noisy | Multi-Speaker |
|---|---|---|---|---|---|
Lightning ASR | 5.1% | 4.6% | 5.3% | 5.8% | 5.7% |
GPT-4o Mini | 10.3% | 10.8% | 10.4% | 12.1% | 11.4% |
Deepgram Nova | 3.8% | 2.9% | 3.0% | 4.1% | 3.7% |
Word Error Rate Distribution
Latency
Model | Time to first Transcript |
|---|---|
Smallest AI | 295ms |
Deepgram | 310ms |
Open AI GPT-4o-Mini | 480ms |
Dataset
Our evaluation dataset comprises 1,680 audio samples across 9 languages, totaling approximately 4.5 hours of audio content (average 10 seconds per clip). The dataset was internally curated from call center conversations, broadcast clips, studio recordings, and news segments to reflect real-world streaming scenarios.
The samples cover a wide variety of speech conditions, including accented speech (30%) with Indian, various European, and Middle Eastern accents, technical terms (22%) spanning medical, scientific, and mathematical domains, tongue twisters and rapid speech (8%), noisy audio (30%) with background sounds such as street noise, overlapping conversations and music, and multi-speaker scenarios (10%).
Note: Test Data in Accented Speech is not available for all languages and hence is restricted to English language.
English Audio Examples:
1. Technical
"mitochondrial oxidative phosphorylation generates energy through chemiosmotic coupling driven by proton gradients across the inner membrane and electron transfer"
2. Noisy
"this is the history of our universe how it began and how everything around us came to be"
3. Accented
"these take the shape of a long round arch with its path high above and its two ends apparently beyond the horizon"
Methodology
All audio was standardized to 16kHz mono with volume normalization. Both reference and model transcripts were normalized using lowercase conversion, punctuation removal, unicode normalization (NFKD), and whitespace collapse.
WER was calculated as (Substitutions + Deletions + Insertions) / Total Reference Words. Streaming used 250ms chunks with interim results enabled. Each language contains minimum 200 samples for statistical significance.
Key Insights
SmallestAI leads in German, French, Italian, Dutch, Polish and Hindi while staying competitive in other languages.
GPT-4o Mini dominates in Spanish and Russian.
Deepgram continues to shine in English, showing its maturity in that space.
Conclusion
These benchmarks highlight how different ASR models excel in different languages. While English ASR is fairly saturated, multilingual performance is still an open frontier. For products operating across regions, choosing the right ASR model per language can make a significant difference.
The results show that Lightning ASR delivers highly competitive multilingual streaming transcription, outperforming other systems in several key languages. Its strong performance across both clean and challenging audio conditions demonstrates that optimized, lightweight ASR models can rival larger systems, making them a compelling choice for real-time, multi-lingual voice applications.

