

AI voice generation for product demos: how TTS, voice cloning, and real-time synthesis speed updates, keep voice consistent, and scale localization.
AI voice generation turns written text into natural-sounding speech using machine learning models trained on large collections of real voice recordings. In the context of product demos, it means you can ship a clean, studio-style voiceover without booking time in a booth, lining up a narrator, or burning days on back-and-forth revisions.
Product teams are increasingly treating voice as reusable infrastructure rather than a one-time production asset. As product update cycles accelerate, the ability to regenerate narration quickly has become a practical requirement rather than a nice-to-have feature.
What AI Voice Generation Actually Does
AI voice generation starts with a simple exchange: you provide text, the system returns audio that sounds like someone reading it aloud. What has changed is the quality ceiling. Early text-to-speech (TTS) often landed in the uncanny valley: flat pacing, awkward emphasis, and a telltale robotic timbre. Modern systems lean on neural architectures, especially transformer-based and diffusion models, to produce speech with believable prosody, sensible pauses, and intonation that matches the sentence rather than fighting it.
Generative voice AI converts digital text into AI-generated human speech and supports use cases ranging from customer service automation to voiceovers for product demos and e-learning. The practical difference from older TTS is in how the audio is produced: generative models are not just assembling pre-recorded phoneme fragments. They synthesize new speech patterns end to end, which is why the output can sound convincingly human.
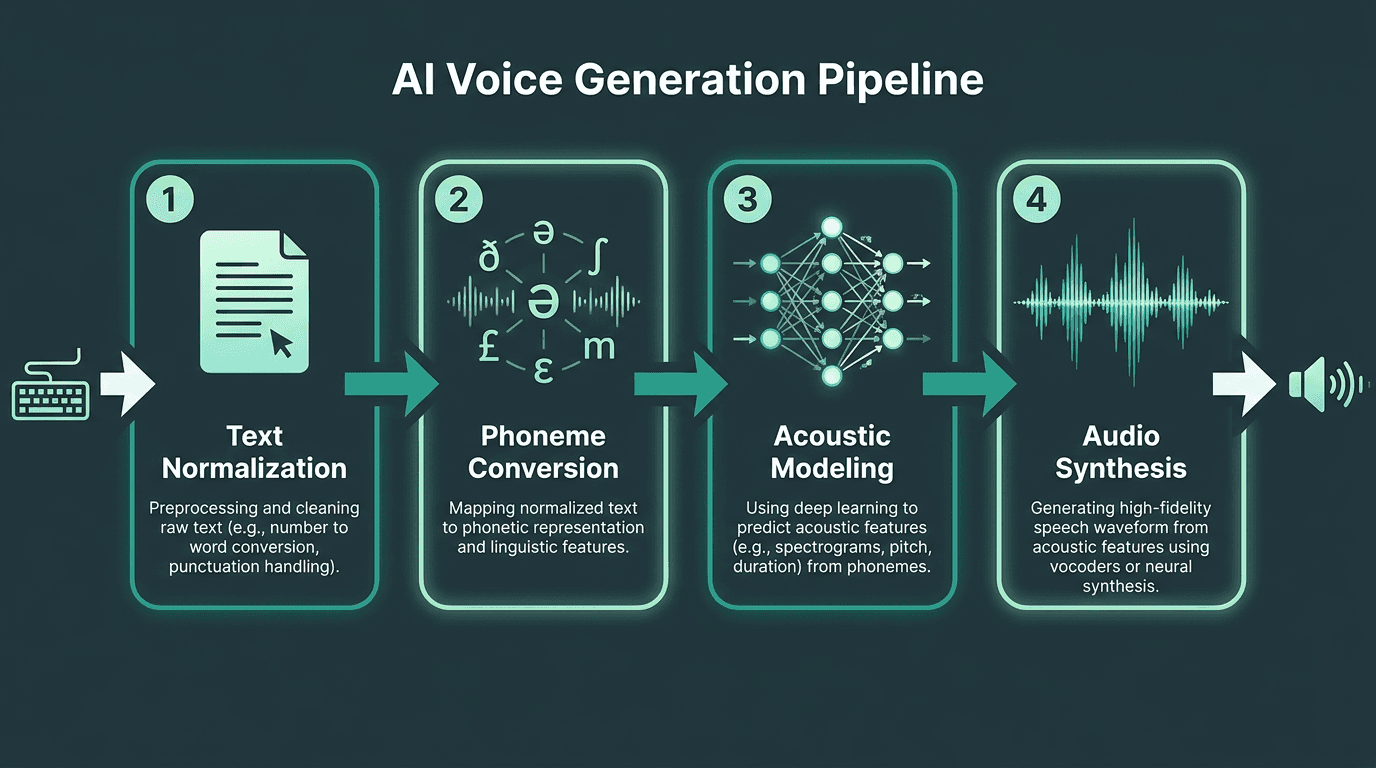
Modern AI voice generation moves through four neural stages before producing natural-sounding speech.
In a product demo, the voiceover is not background noise. It sets the pace, signals confidence, and quietly tells the viewer whether this is worth their attention. When the voice sounds synthetic or rushed, people notice the narration instead of the product. When it sounds natural and well-timed, the audio disappears and the demo does its job.
Why Product Teams Are Adopting Voice AI for Demos
The old demo pipeline is familiar: write the script, book a voice actor, record, edit, and then do it again the moment the UI changes. It is slow, it is expensive, and it turns every small product update into an audio production project. AI voice generation compresses that loop.
A primary use case for AI voice generation is creating voiceovers for content like product demos, advertisements, and YouTube videos, which allows creators to scale production without needing a human narrator for each iteration. For a product team shipping weekly, that matters: update the script, regenerate the narration, and publish the refreshed demo the same day. Traditional voice production rarely moves at that cadence.
Concrete reasons product teams are switching to AI voice generation:
Speed: Update the script and generate a new voiceover in seconds, which makes same-day demo revisions realistic after product changes.
Cost efficiency: Cuts recurring studio time and talent fees for every new version or localized variant.
Brand consistency: One custom voice can run across every demo surface. Maintaining brand consistency with a single voice is an underrated win for teams trying to keep messaging tight across product, marketing, and sales.
Global reach: Teams can localize product videos with multilingual voice dubbing without re-recording in each language.
Scalability: The workflow that outputs one demo can output fifty, without hiring a larger production team.
Types of AI Voice Generation Technology
AI voice generation is not one monolithic feature, and the differences show up fast in demo production. Most tools fall into three buckets: standard TTS, voice cloning, and real-time speech synthesis. They overlap, but they solve different problems.
Type | How It Works | Best For Product Demos | Latency |
|---|---|---|---|
Standard TTS | Turns text into speech using a catalog of pre-built neural voices | Batch-produced explainer demos and tutorials | Low (seconds) |
Voice Cloning | Builds a synthetic replica of a specific voice from audio samples | Brand-voice demos and personalized outreach videos | Low to medium |
Real-Time Speech Synthesis | Produces speech on the fly from streaming text input | Interactive demos, live walkthroughs, and conversational AI demos | Ultra-low (milliseconds) |
Standard text-to-speech platforms can handle straightforward narration workflows. Teams usually begin evaluating more advanced capabilities when they need custom brand voices, multilingual production, or real-time voice generation for interactive experiences. That is where voice cloning and real-time synthesis matter, and where specialized offerings, including Smallest.ai's Lightning Text-to-Speech API, tend to stand out.
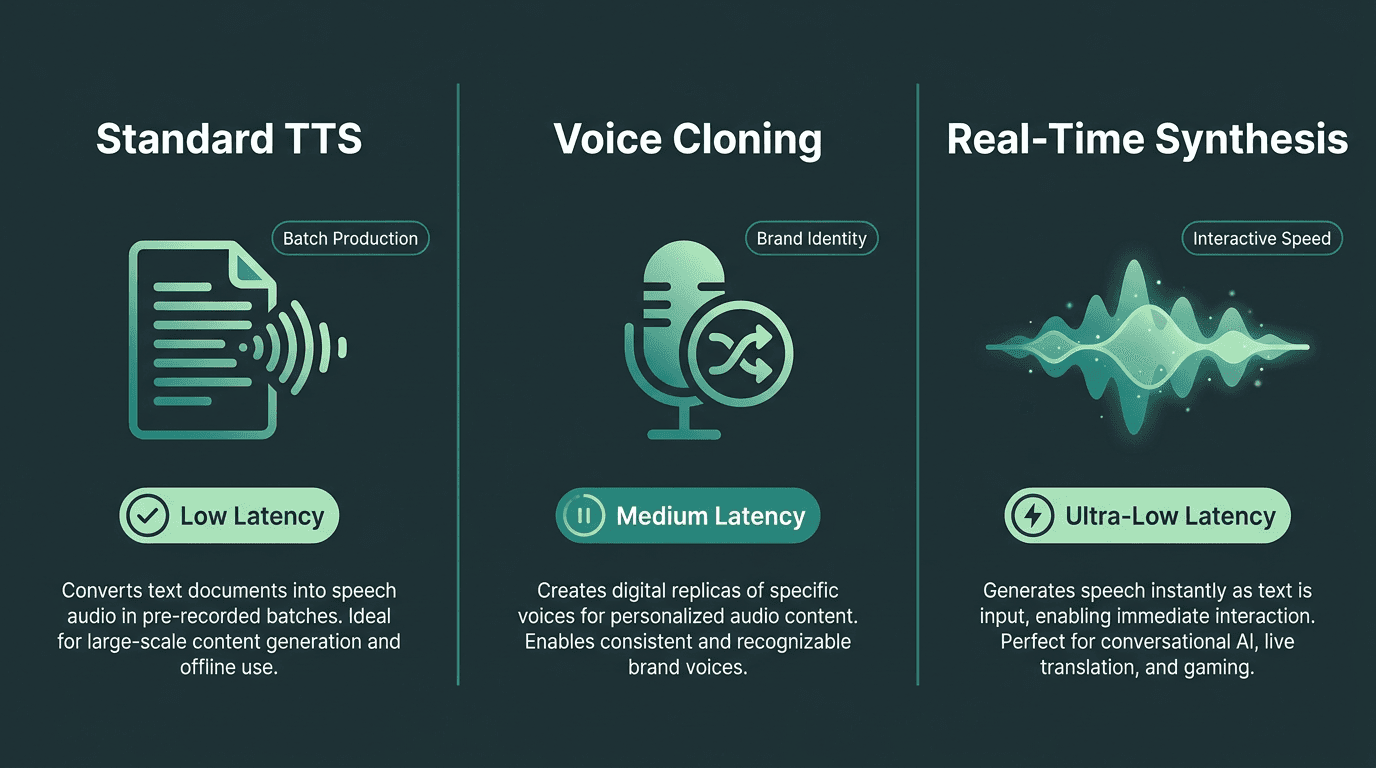
Three AI voice generation types, each solving a distinct challenge in product demo production.
What to Look for in an AI Voice Generation Tool for Demos
The result of increased demand for TTS solutions is a crowded market with lots of overlapping claims, which makes tool selection feel murkier than it should be.
Speech naturalness is the first filter, but demo teams usually outgrow that checkbox quickly. You also need to look at API flexibility (can this plug into your production pipeline?), voice controls (can you tune speaking rate, emphasis, and tone by segment?), and latency (does a five-second render time break your experience, or is it fine?). If you ship globally, language and accent coverage moves from "nice" to required.
Voice cloning is also moving from novelty to default expectation. AI voice technology can create a unique, custom voice to represent a brand across all customer touchpoints, ensuring consistency. In demo terms, that consistency shows up everywhere: the landing page video, the sales deck clip, and the onboarding walkthrough can all sound like they came from the same product, not three different vendors. If you are comparing options, best AI voice cloning tools is a useful starting point.

From speech naturalness to voice cloning, these six criteria cut through a crowded AI voice market.
Common Misconceptions About AI Voice Generation
Misconception 1: AI voices always sound robotic. That used to be a fair critique of early concatenative TTS, where speech was assembled from recorded fragments. It does not hold for current neural voice models. In controlled listening tests, many modern systems produce audio that most listeners cannot reliably separate from a human recording. For standard demo narration, the gap that mattered five years ago has narrowed dramatically.
Misconception 2: You need a large audio dataset to clone a voice. Earlier generations of voice cloning did demand hours of clean, consistent audio. Few-shot models have changed that math: a usable replica can be created from a few minutes of samples, sometimes less. That makes custom brand voices feasible even when you do not have a deep archive of a spokesperson's recordings.
Misconception 3: AI voice generation is ethically uncomplicated. If anything, the ethical load increases because synthetic voices are easy to scale and easy to misuse. Consent, deepfakes and scams, clear disclosure when a voice is AI-generated, and bias in training data that can exclude accents or dialects all matter. Accountability and transparency are central obligations for organizations deploying synthetic voice. Before putting cloned voices into production, teams should also review ethical safeguards for voice cloning.

Modern AI voice tools have outpaced the myths teams still rely on.
Real-World Applications in Product Demo Workflows
SaaS teams often use AI voice generation to keep feature announcement videos in lockstep with sprint cycles. Instead of waiting for talent availability after every release, product marketing updates the script and regenerates audio that same afternoon. The demo can go live before the announcement email hits inboxes.
E-commerce platforms tend to push voice AI in a different direction. Rather than a static video, they build interactive product discovery flows where a voice agent guides a shopper through options in real time. It is adjacent to demos but not the same category, and how AI voice assistants improve ecommerce product discovery is worth mapping if your "demo" experience extends into guided shopping.
Enterprise vendors with global customers lean heavily on multilingual voice generation to scale localized demos without a recording schedule for every market. One script can be rendered in a dozen languages with voices that sound native to each language, expanding the demo library without matching increases in production cost.
Key Takeaways
What to remember about AI voice generation for product demos:
AI voice generation turns text into natural-sounding speech using neural models, which replaces human narrators for most demo workflows.
The tech generally falls into three approaches: standard TTS, voice cloning, and real-time synthesis, each matching a different demo format.
Speed, cost, and consistency are the operational reasons product teams adopt it.
Voice cloning makes it possible to keep a persistent brand voice across landing pages, sales calls, and onboarding.
Consent and transparency are not optional; ethical and legal obligations come with synthetic voices.
Interactive demo experiences generally benefit from low-latency speech generation because long delays can make conversations feel less natural.
Multilingual voice generation removes the localization bottleneck for global demo production.

Seven essentials every product team should know before adopting **AI voice generation**.
The Problem This Solves, and Where Smallest.ai Fits
The problem AI voice generation solves for product teams is timing: products change quickly, and traditional voice production does not. A UI tweak, a renamed feature, or a pricing update can make a demo sound wrong overnight. Rebuilding narration through conventional recording takes days, so prospects end up watching demos that no longer match the product while sales teams paper over the gaps.
Smallest.ai is built for teams that do not have room for that delay. The delivers natural voice output with low latency and is designed to slot into demo production, whether you are generating voiceovers for a video library or running a real-time conversational demo through the Smallest.ai Voice Agents platform. With voice cloning, the same brand voice can carry from the first prospect touchpoint through onboarding. For interactive product experiences, the Hydra speech-to-speech product and Electron conversational language model extend that setup into fully dynamic demo environments. See the Lightning Text-to-Speech API to match the right product to your team's demo production needs.
Create Product Demos Without Re-Recording Every Update
Product demos change as fast as products do. Smallest.ai's Lightning Text-to-Speech API helps teams generate natural voiceovers, maintain a consistent brand voice, and update demo content without waiting on recording sessions. Whether you're creating narrated walkthroughs, multilingual product videos, or interactive demo experiences, Lightning provides the voice infrastructure needed to scale production.
What is AI voice generation, and how is it used in product demos?
Can I use a custom brand voice instead of a generic AI voice for demos?
How can I localize product demos into multiple languages with AI voice generation?
What ethical issues should teams consider when using AI-generated voices in demos?
What makes Smallest.ai different for AI voice generation in product demos?

