Voice Cloning AI in Production: Architecture, Latency, and Ethical Safeguards


Modern voice cloning can make a computer sound like a specific person. This guide covers how it works, how to deploy it at scale, and the security and consent safeguards that make it viable.
For decades, the goal of speech synthesis was to make a computer sound like a human. Today, we have achieved something far more complex which is, making a computer sound like a specific human. This shift from 'generic' to 'cloned' has transformed the voice from a mere interface into a valuable piece of corporate intellectual property and a massive security liability.
At the center of this shift is voice cloning AI, the ability to generate synthetic speech that sounds indistinguishable from a specific human speaker. Where traditional text-to-speech systems offered generic, robotic voices, modern voice cloning AI can replicate a brand's spokesperson, a customer service agent persona, or even a doctor's voice for patient communication, all from a short audio sample and a few API calls.
But production deployment brings hard challenges. Latency is the most immediate, a voice response that takes more than 800ms feels unnatural in conversation, and anything above a second breaks the illusion entirely. Data requirements for high-quality voice cloning have dropped dramatically (some systems now work from as little as 30 seconds of audio), but quality still scales with sample size and cleanliness. Security concerns are serious, the same technology that enables a personalized banking assistant can be weaponized for synthetic voice fraud or deepfake impersonation.
This article explores how modern voice cloning AI systems are built, how they operate at production scale, and the safeguards required for responsible deployment.
What Is Voice Cloning AI?
Voice cloning AI refers to deep learning systems capable of replicating a person's voice characteristics such as tone, cadence, pitch, accent, and speaking style using short audio samples. The output is a model that can synthesize arbitrary text in the target speaker's voice, producing synthetic voice generation that is perceptually similar or identical to the original speaker.
It is worth distinguishing voice cloning from related technologies that are often conflated:
Technology | Description | Use Case |
|---|---|---|
Text-to-Speech (TTS) | Pre-trained, generic voice models | Audiobooks, navigation, notifications |
Voice Cloning | Replicates a specific speaker's identity | Brand voices, personalized assistants |
Voice Conversion | Converts one speaker's speech to sound like another in real time | Live dubbing, privacy masking |
Voice cloning sits at the intersection of speaker verification (identifying who is speaking) and speech synthesis (generating speech). A voice cloning system learns a speaker embedding, a mathematical representation of a voice's unique characteristics and conditions the speech synthesis model on that embedding to produce output that matches the target speaker.
Voice cloning accuracy has improved dramatically with modern neural architectures. Zero-shot voice cloning (cloning a voice from a single short sample without any fine-tuning) is now commercially viable. Few-shot systems using 30 seconds to 5 minutes of audio can achieve results that trained listeners struggle to distinguish from real recordings. Professional-grade cloning using longer samples can produce results that even audio forensic tools have difficulty flagging.
The distinction between text-to-speech and voice cloning matters for production decisions. TTS is cheaper, faster to deploy, and avoids consent and privacy complexities. Voice cloning is more expensive, requires source audio, and carries legal obligations but delivers meaningfully better user experience for applications where a consistent, recognizable voice matters.
AI voice replication is also increasingly used for voice preservation (cloning a person's voice before they lose it to illness), content localization (dubbing content in a speaker's own voice across languages), and accessibility tools for people who cannot speak. Understanding the full spectrum of use cases is essential for making ethical deployment decisions.
How Voice Cloning Works (Technical Pipeline)
Understanding how voice cloning works at a technical level is essential for making good architectural decisions in production. The pipeline from raw audio to generated speech involves several distinct stages, each with its own quality and latency tradeoffs.
The diagram below illustrates the voice cloning pipeline used in modern AI speech systems.
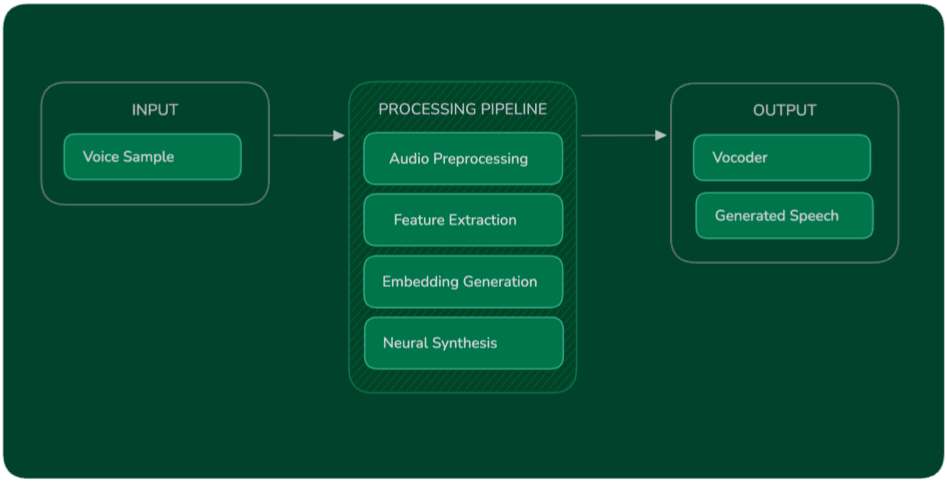
The following sections explain how voice data is collected, transformed into machine-readable representations, and ultimately used to synthesize speech that matches the target speaker.
Data Collection
The quality of a cloned voice is directly bounded by the quality of the source audio. Recordings should be made in a quiet environment with a consistent, high-quality microphone; background noise, room reverb, and codec compression artifacts all degrade the learned speaker representation. Modern zero-shot systems can work from a single 5–30 second clip, but professional-grade clones benefit from 5–30 minutes of clean, varied speech that covers the speaker's full phonetic and prosodic range.
Dataset size requirements have dropped significantly with advances in speaker encoders. Where earlier systems needed hours of data, state-of-the-art models like those used by smallest.ai's Lightning TTS can produce high-quality clones from very short samples thanks to large-scale pretraining on diverse multilingual speech corpora.
Audio Feature Extraction
Raw audio waveforms are not fed directly into neural networks. Instead, they are converted into compact representations that capture the perceptually relevant properties of speech. The most common representations are:
Mel spectrograms: A 2D time-frequency representation that mirrors how the human auditory system processes sound. Mel spectrograms are the dominant intermediate representation in modern TTS and voice cloning systems.
MFCCs (Mel-Frequency Cepstral Coefficients): A compact, historically important feature set derived from the mel spectrogram. Less common in modern deep learning pipelines but still used in speaker verification components.
Prosody features: Pitch (fundamental frequency), energy, and duration patterns that encode the rhythmic and intonational characteristics of a speaker's style. Capturing prosody is what separates convincing voice clones from robotic ones.
Speaker Embeddings
The speaker embedding is the heart of voice cloning. It is a fixed-length vector (typically 256–512 dimensions) that encodes the speaker's unique voice identity and their voice fingerprint. The speaker encoder is a neural network trained on a large, diverse dataset of speakers to produce embeddings that are close together for samples from the same speaker and far apart for different speakers.
At inference time, a short audio clip from the target speaker is passed through the speaker encoder to produce their embedding. This embedding is then used to condition the speech synthesis model, telling it to generate output that sounds like the target speaker rather than any other.
Speech Generation
Given the text to synthesize and the speaker embedding, the acoustic model predicts a mel spectrogram of the target speech. This spectrogram captures what the speech should sound like but it is not yet audio. A vocoder (or neural vocoder) converts the predicted spectrogram back into a raw audio waveform.
Modern neural vocoders like HiFi-GAN and WaveGrad can produce 44kHz studio-quality audio in real time. smallest.ai's Lightning v3.1 TTS operates at 44kHz with 175ms synthesis latency, achieved by streaming mel spectrogram chunks to the vocoder incrementally rather than waiting for the full spectrogram to be computed.
Voice Cloning with the smallest.ai SDK
Here is a practical example of uploading a voice sample and creating a voice profile using the smallest.ai Python SDK:
Before running the code:
Create an API key from the Smallest AI Dashboard.
Set this key as
YOUR_API_KEYin the code examples below.
For a complete walkthrough of the voice cloning workflow, refer to the Smallest AI Voice Cloning Documentation.
Input Audio:
Step 1: Upload a sample voice
Step 2: Generate cloned voice
Output Audio:
The SDK handles authentication, audio encoding, and streaming internally, a developer can go from a raw WAV file to a cloned voice generating speech in under 20 lines of code.
Neural Architectures Behind Modern Voice Cloning
Modern voice cloning systems are composed of three specialized neural network components that work together; a speaker encoder, an acoustic model, and a neural vocoder. Understanding the role of each helps in evaluating platforms, diagnosing quality issues, and making informed decisions about tradeoffs.
Speaker Encoder
The speaker encoder's job is to convert a raw audio clip into a compact speaker embedding that captures voice identity. It is trained using metric learning specifically, the generalized end-to-end loss to produce embeddings where samples from the same speaker cluster together and samples from different speakers are pushed apart. Well-trained speaker encoders generalize to unseen speakers at inference time, enabling zero-shot voice cloning without any fine-tuning.
Acoustic Model
The acoustic model takes two inputs, a text or phoneme sequence and a speaker embedding and predicts the mel spectrogram of the synthesized speech. Early systems used Tacotron 2, an attention-based sequence-to-sequence model that directly maps text to mel spectrograms. Tacotron-based systems remain widely used but suffer from robustness issues for example attention alignment can fail on long texts or unusual phoneme sequences, producing garbled or skipped audio.
More recent architectures address these issues:
VITS (Variational Inference with adversarial learning for end-to-end Text-to-Speech): An end-to-end model that combines the acoustic model and vocoder into a single jointly trained network using normalizing flows and adversarial training. VITS produces high-quality output with better robustness than Tacotron-based systems.
Diffusion models: Diffusion-based TTS systems (such as Grad-TTS and ElevenLabs' proprietary architecture) model speech generation as a progressive denoising process. They can produce exceptionally natural-sounding output but are historically slower to sample from a challenge being actively addressed with consistency distillation and flow matching techniques.
Language model-based systems: Systems like VALL-E treat speech synthesis as a token prediction problem, using a large language model to predict discrete audio codec tokens. These systems show remarkable in-context voice cloning ability but require significant computation.
Neural Vocoder
The vocoder sits at the end of the pipeline and converts predicted mel spectrograms into audible waveforms. HiFi-GAN is the workhorse of production systems, a GAN-based vocoder that generates 22kHz or 44kHz audio in real time with high perceptual quality. WaveGrad and other diffusion vocoders can produce slightly higher quality output but at greater computational cost.
Model Size and Efficiency
An important and often misunderstood point, efficient voice models under 10 billion parameters can outperform larger general-purpose models when optimized specifically for speech tasks. The speech domain has well-characterized structure phonetics, prosody, and speaker characteristics that allows compact, task-specific models to outperform massive general models on quality, latency, and cost metrics. smallest.ai's Electron, their voice-optimized small language model, demonstrates this principle: sub-500ms reasoning latency with speech-specific optimizations that larger general models cannot match.
Real-Time Voice Cloning and Latency Constraints
Latency is the defining engineering challenge of production voice cloning. A voice interface that responds slowly does not just feel slow it feels broken. Human conversation has a natural cadence, and deviations of more than 500–800ms create awkward pauses that destroy the sense of talking to an intelligent agent.
The key performance targets for production voice cloning systems are:
Metric | Target | Notes |
|---|---|---|
Time to first audio | < 200ms | First audio chunk reaching the user |
Full turn latency | < 800ms | End of user speech → start of agent response |
Speech generation speed | ≥ 1× real-time | Must generate audio at least as fast as playback |
Speaker embedding extraction | < 50ms | Should be cached after first extraction |
Why Streaming Is Non-Negotiable
The only way to achieve sub-200ms time-to-first-audio is to stream at every stage of the pipeline. This means:
ASR streams partial transcripts as the user speaks the system starts processing before the user finishes their sentence.
The LLM streams tokens as it generates the first tokens are sent to TTS before the full response is complete.
TTS streams audio chunks as it synthesizes the first audio chunks are sent to the user before the full response has been synthesized.
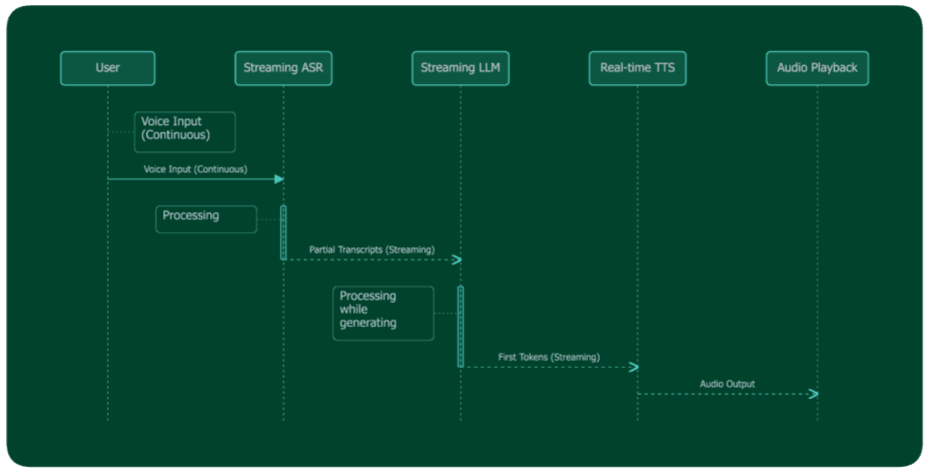
This pipeline means the user begins hearing the response while the LLM is still generating it. The perceived latency is the time from end of user speech to first audio chunk not the time to complete the full response.
Smallest.ai Atoms Architecture Pattern
The Atoms platform orchestrates this architecture behind a clean SDK interface. Here is how voice cloning integrates into an Atoms voice agent:
The voice_id parameter on OutputAgentNode tells the Atoms runtime to route all TTS synthesis through Lightning using the specified cloned voice profile. No additional configuration is needed; the streaming pipeline, speaker embedding lookup, and audio delivery are handled by the platform. For detailed information referrer to blog dedicated to voice agent architecture
Security, Ethics, and Compliance
Voice cloning is one of the most ethically significant AI capabilities in production deployment. The same technology that enables a personalized healthcare assistant can be used to impersonate a CEO in a financial fraud scheme. Production deployment without robust safeguards is both irresponsible and increasingly illegal.
Consent
Explicit, informed consent is non-negotiable before cloning any person's voice. Consent must be specific: the person must understand that their voice will be cloned, for what purpose, and how the clone will be used. Blanket terms-of-service acceptance does not constitute meaningful consent for voice biometric data collection.
Best practice is to implement a voice consent workflow: the speaker records a consent statement ("I, [name], consent to the cloning of my voice for [specific use]"), which is stored alongside the voice profile as an auditable consent artifact. This protects both the user and the deploying organization.
Privacy and Voice Biometric Protection
Voice recordings are biometric data. Under GDPR (Article 9), biometric data is a special category requiring explicit consent and heightened protection. Under HIPAA, voice data associated with patients requires the same protections as other protected health information. SOC 2 Type II compliance is the baseline expectation for enterprise voice cloning platforms handling customer data.
Voice profiles should be stored encrypted at rest, with access controls limiting which services and personnel can invoke synthesis using a given voice profile. Deletion requests must remove both the source audio and the derived speaker embedding retaining either constitutes continued processing of biometric data.
Deepfake Prevention and Watermarking
Responsible voice cloning platforms implement audio watermarking such as imperceptible, cryptographically verifiable signals embedded in synthesized audio that allow the audio to be identified as AI-generated even after compression, re-encoding, or editing. Watermarking does not prevent misuse but creates an evidentiary trail for forensic investigation.
Deepfake voice detection systems use classifier models trained to distinguish real from synthetic speech. Detection accuracy is an active research area detection and generation capabilities in an ongoing arms race. No detection system is foolproof, which is why watermarking (provenance-based) is more reliable than detection-based approaches for production compliance.
Usage policies should explicitly prohibit synthesis of voices not covered by active consent agreements, impersonation of real individuals, and use in fraud, harassment, or deception. Rate limiting and anomaly detection on synthesis endpoints can flag unusual usage patterns for human review.
Compliance Checklist
Requirement | Implementation |
|---|---|
GDPR consent | Recorded consent artifact stored with voice profile |
Data minimization | Store embeddings, not raw audio, after processing |
Right to erasure | Delete voice profile + embedding on request |
HIPAA | Encrypted storage, access audit logs, BAA with vendor |
SOC 2 | Platform-level compliance that verify vendor certification |
Watermarking | Embed on all synthetic audio outputs |
Usage policy | Prohibit impersonation, fraud, non-consented cloning |
Best Practices for Deploying Voice Cloning Systems
Collect clean audio. Background noise, room reverb, and codec compression are the most common sources of quality degradation in cloned voices. Record in a treated acoustic environment with a broadcast-quality microphone. If collecting audio remotely, provide speakers with recording guidelines and reject samples that don't meet quality thresholds.
Verify speaker identity before cloning. Implement identity verification with photo ID, liveness detection, or a verified consent call before accepting a voice submission for cloning. This prevents bad actors from submitting third-party voice recordings.
Implement watermarking on all outputs. Every piece of synthesized audio should carry an embedded watermark identifying it as AI-generated and linking it to the voice profile and timestamp. This is non-negotiable for production deployments.
Maintain comprehensive audit logs. Log every synthesis request: timestamp, voice profile ID, text synthesized, requesting service, and output hash. These logs are essential for investigating misuse and demonstrating compliance in regulated industries.
Restrict voice profile access with least-privilege controls. A voice profile created for a customer service bot should not be accessible to unrelated internal services. Implement API key scoping so each service can only invoke the voice profiles it is authorized to use.
Test for edge cases before production launch. Unusual phonemes, proper nouns, numbers, and code-switching between languages all stress-test voice cloning quality. Build a regression test suite of challenging inputs and evaluate output quality systematically before deploying.
Plan for voice profile lifecycle management. Voices change over time, consent agreements expire, and spokespeople change roles. Implement processes for renewing consent, refreshing voice profiles with updated samples, and retiring profiles when the authorization period ends.
Future of Voice Cloning AI
The near-term trajectory of voice cloning is toward greater realism, lower latency, and richer expressivity but the most significant developments are at the intersection of voice with other modalities and capabilities.
Real-time voice translation is emerging as a production capability: systems that can translate a speaker's words into another language while preserving their cloned voice. This enables truly multilingual voice agents that sound like the same person regardless of the caller's language, a significant step beyond current systems that typically switch to a generic TTS voice for non-primary languages.
Emotional voice synthesis is advancing rapidly. Current production systems can modulate speaking style (fast/slow, formal/casual) but emotional expressivity, sadness, enthusiasm, concern remains difficult to control precisely. Next-generation models trained on emotionally labeled speech data will offer fine-grained prosodic control, enabling voice agents that adapt their emotional register to the context of the conversation.
Multimodal voice models will combine visual, textual, and acoustic signals. A voice agent that can see (via a shared screen or camera feed) and hear simultaneously can respond to visual context "I see you're looking at the error on line 12" while maintaining a consistent cloned voice persona.
Personalized AI assistants that maintain a consistent voice identity across long-term relationships remembering preferences, adapting speaking style to individual users, and updating their voice model as the speaker's voice naturally changes over time represent the long-term endpoint of this technology trajectory.
How much audio is needed for voice cloning?
Is voice cloning AI legal?
Can voice cloning work in multiple languages?
How accurate is voice cloning AI?
Can voice cloning detect deepfakes?
What industries use voice cloning?

