AI Audiobook Generation for Publishers: How to Turn Written Content Into Long-Form Audio at Scale


AI audiobook generation that scales: prep manuscripts, pick voices, build batch pipelines, and meet platform specs while cutting cost and production time.
Publishers that once planned audiobook production over several weeks can now use AI narration to test and produce audio editions much faster. Some academic publishers have reported reducing audio production costs by up to 80% without sacrificing quality.
This is for publishing teams, content ops managers, and technical leads who need a practical framework for building an audio pipeline that won’t fall apart at scale. You’ll get a clear view of how the tech works, where long-form production tends to break, how to keep quality from drifting over hours of narration, and what to look for in infrastructure when you’re converting a real catalog, not a one-off. The sections below start with fundamentals and then move into the production decisions that determine whether this is a pilot, or a program.
Why the Economics of Audiobook Production Have Shifted
Traditional audiobook production is a full studio workflow: book time, hire a narrator, run directed sessions, edit the raw takes, master to retail specs, then encode for distribution. For a 90,000-word novel, traditional production can take several weeks and cost several hundred dollars per finished hour, with total budgets rising based on narrator fees, editing, mastering, and production complexity.
AI narration rewrites that cost structure. The compute to synthesize a full-length audiobook is now measured in dollars, not thousands. Major platforms (including Google Play Books and Kobo) now accept AI-narrated titles. Spotify allows them with disclosure. Audible has also explored AI narration initiatives with select publishing partners.
Cost is the headline, but catalog depth is the real shift. If you’re sitting on 3,000 backlist titles that never penciled out for studio narration, you can now treat audio conversion as a realistic program instead of a wish list. Traditional production simply couldn’t open that door at anything resembling scale.
How AI Audiobook Generation Actually Works
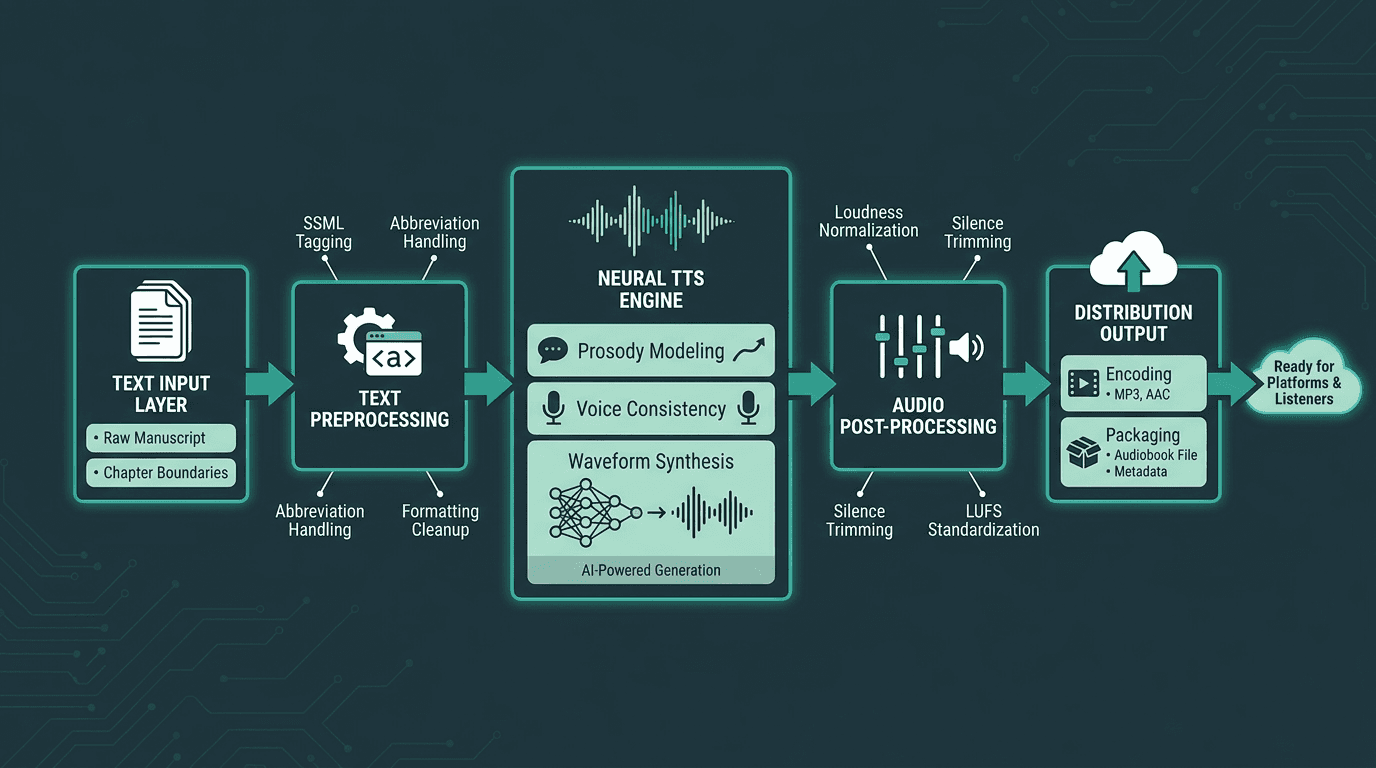
The four-stage pipeline behind AI audiobook production: from raw text to distribution-ready audio.
Modern AI narration runs on neural text-to-speech technology, where deep learning models trained on large corpora of human speech generate audio directly from text. This is a clean break from older concatenative systems that stitched together recorded phoneme fragments. Neural TTS produces speech waveforms end-to-end, which is why it can carry more natural prosody, rhythm, and emotional cadence.
A long-form production pipeline usually breaks into four stages. First comes preprocessing: identify chapter boundaries, clean special characters and formatting debris, and add markup for abbreviations, numbers, and proper nouns. Second, the TTS engine synthesizes audio in segments from the cleaned text. Third, post-processing brings those segments up to spec, silence normalization, loudness standardization for retail targets (typically -18 to -23 LUFS for audiobook platforms), and quality checks. Fourth, the masters are encoded and packaged for distribution.
Stage two is where long-form projects either feel professional or fall apart: context. Generating a sentence is easy. Keeping a narrator stable across paragraphs and chapters is not. If chapter one lands in a slightly warmer register, chapter twenty has to match it. The strongest neural TTS systems hold voice consistency across arbitrarily long documents, and that engineering gap is what separates production-grade APIs from demo tools that only sound good for a minute.
Preparing Your Manuscript for AI Narration
Manuscript prep is the unglamorous part that decides whether the output sounds polished or amateur. A clean, well-structured input file is the highest-leverage move you can make before you ever hit “synthesize.”
Essential preprocessing steps before sending text to any TTS engine:
Resolve ambiguous abbreviations. “Dr.” should expand to “Doctor” in narrative prose but may stay abbreviated in a bibliography. Getting this right up front avoids predictable mispronunciations.
Normalize numbers and dates. “1,847” should read as “one thousand eight hundred forty-seven” in prose. “2026” in a historical context should read as “twenty twenty-six,” not “two thousand twenty-six.”
Handle proper nouns and foreign words. Add pronunciation guides using SSML phoneme tags for names, places, and technical terms the model may not have encountered in training.
Strip or replace formatting artifacts. Footnote markers, em dashes used as interruptions in dialogue, and special Unicode characters all need explicit handling rules.
Mark chapter and section boundaries. These become natural pause points and let the pipeline process chapters as independent audio segments, which makes review (and targeted re-synthesis) much easier.
If you’re processing more than a handful of titles, it’s worth turning these rules into a preprocessing script instead of relying on manual cleanup. A solid preprocessing layer becomes shared infrastructure across your catalog, with only light per-title tuning. If you’re exploring how to turn written content into audio through no-code or low-code workflows, you’ll find automation patterns that cover a lot of this prep work as part of the flow.
Voice Selection and Consistency at Scale
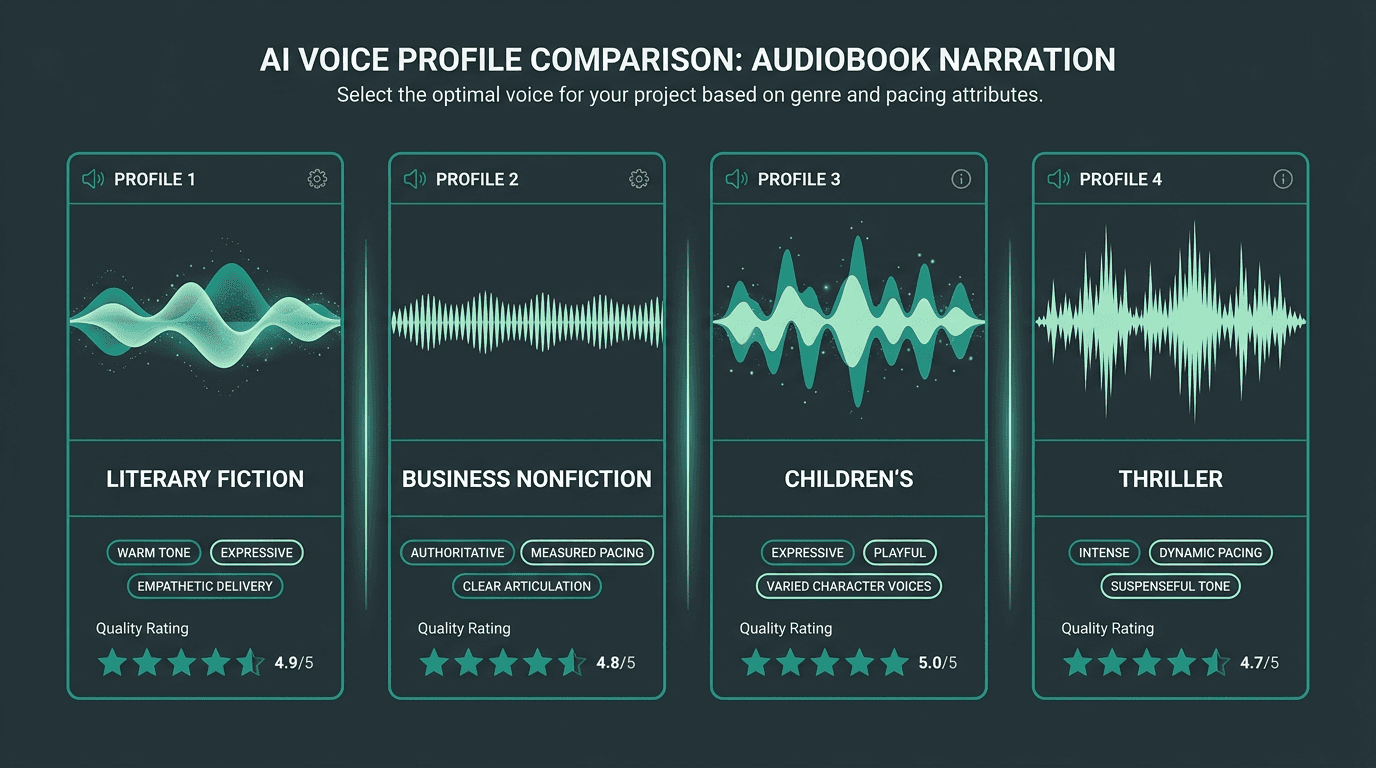
Voice selection for audiobooks requires matching tone, pacing, and genre expectations.
Voice selection is where publishers often stumble first: they choose a voice that dazzles in a 30-second demo, then realize it’s tiring over eight hours. Listeners aren’t judging a clip, they’re living with a narrator. Your criteria need to match that reality.
Treat it like a real audition. Synthesize a representative 10 to 15 minute sample pulled from the manuscript itself, not a generic demo paragraph, then listen the way your audience listens. That means earbuds on a commute, not studio monitors in a quiet room. Over that duration, fatigue, odd emphasis, and pacing drift stop hiding.
If you’re building a recognizable imprint identity, voice cloning can give you a proprietary narrator voice you can carry across hundreds of titles. That consistency matters in series fiction, where listeners expect the same narrator book to book, and it can also create a coherent “house sound” across a catalog. For a more detailed look at evaluation criteria and selection tradeoffs, the guide on how to choose an AI voice narrator walks through the process.
Building a Production Pipeline That Scales
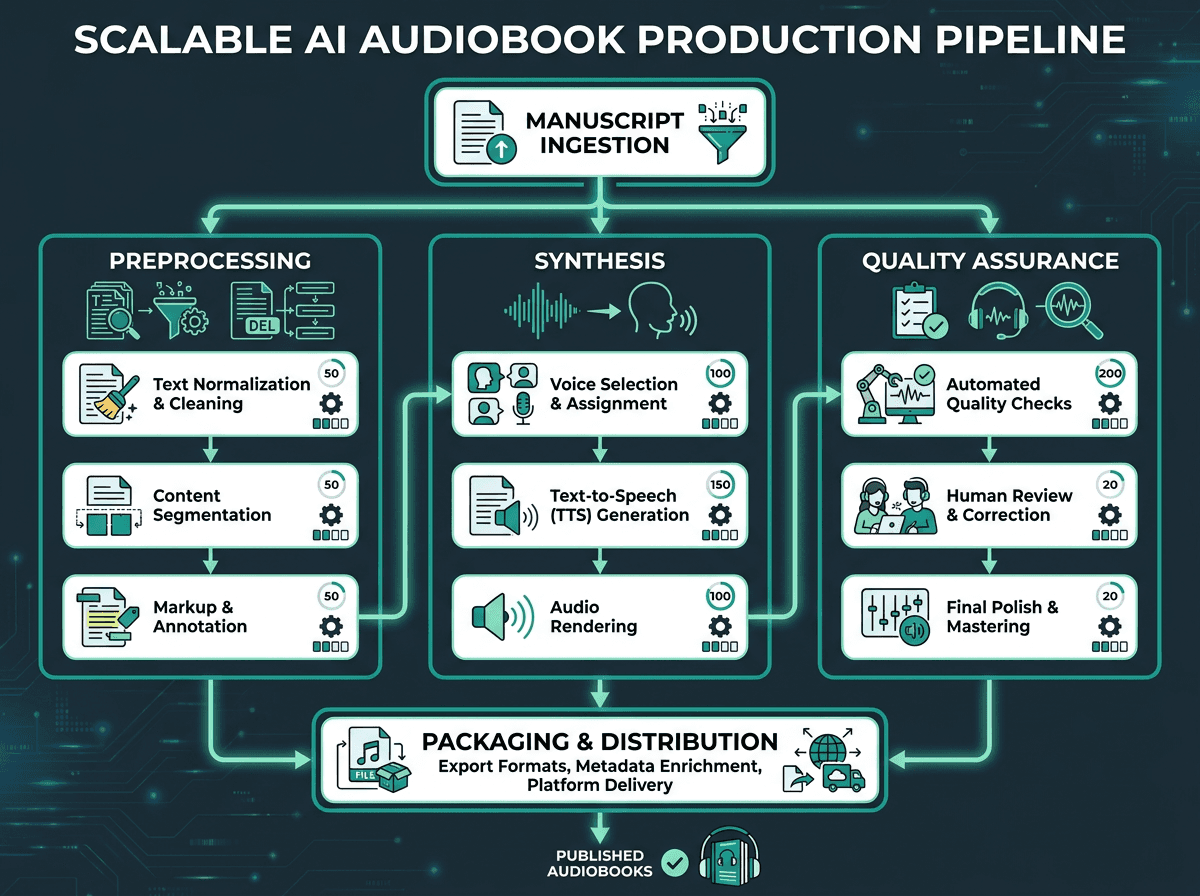
A parallel processing architecture allows publishers to run multiple titles simultaneously.
One title is a workflow. Fifty titles at once is an operational system. If you’re converting a backlist or launching a high-volume audio program, that difference quickly appears in throughput, error rates, and the amount of manual oversight required.
A production pipeline needs capabilities a single API call won’t give you: batch processing with job queues, error handling and retries for failed segments, and a QA layer that catches problems before you ship files downstream. QA is where many builds are thin. At minimum, you want checks for silence gaps beyond a defined threshold, clipping, and segments where the synthesis confidence score drops below your acceptable floor.
Your API choice sets the ceiling. A REST endpoint that effectively processes one request at a time will become your bottleneck. Look for support for concurrent synthesis jobs, structured metadata returned alongside audio, and enough control over synthesis parameters to apply preprocessing rules programmatically. Smallest.ai's text-to-speech for audiobooks is designed around this kind of production workload, with low-latency synthesis and the voice consistency and API surface area long-form audio demands.
Distribution, Rights, and Platform Requirements
AI-narrated audiobook distribution is still in motion, and platform rules don’t line up neatly. As of early 2026, Google Play Books and Kobo accept AI-narrated titles. Spotify allows them with disclosure. While Audible's ACX platform has historically required human narration for most standard submissions, the company is running programs with select publishing partners for AI-generated content. Because these policies are shifting, confirm requirements with each platform before you commit production time.
Rights are the other place teams get surprised. Publishers need to confirm they actually hold audio rights, and whether author contracts say anything about AI-generated audio specifically. Many contracts written before 2023 don’t mention AI narration at all. Some author organizations now recommend explicit consent clauses. Sorting that out in contract language is cheaper than trying to unwind it after a title is already live.
File specs also vary by destination. Most platforms want MP3 at 192 kbps or higher, stereo or mono, with defined loudness targets. If you bake those specs into your pipeline as configurable output profiles, you can generate platform-specific masters from a single synthesis run instead of doing manual per-platform re-encoding.
Advanced Considerations: Multilingual Catalogs and Character Voice Differentiation
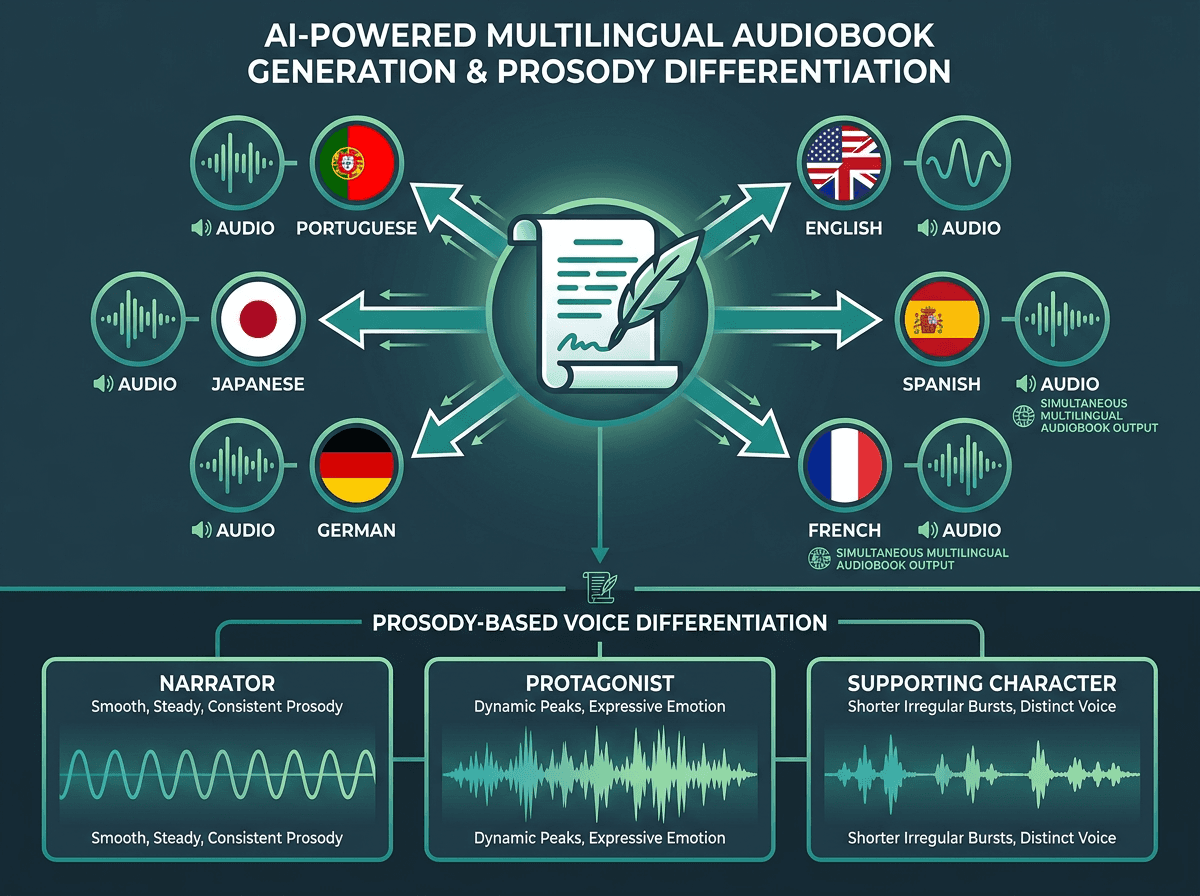
One manuscript, multiple languages and voices: advanced AI narration capabilities for complex productions.
Two features draw a clear line between basic AI narration and serious audiobook production: multilingual synthesis and character voice differentiation.
Multilingual synthesis lets publishers produce audio editions in multiple languages from a translated manuscript without lining up narrators market by market. That materially changes the economics. A title that once required separate studio schedules across five countries can now run in parallel. The quality bar for non-English output still varies a lot by language and model, so it’s worth testing with native-speaker listeners before you ship widely.
Character voice differentiation is trickier. A narrator handling a novel with fifteen speaking characters has to signal distinct identities without flipping to entirely different voices, which tends to create jarring transitions. The most reliable pattern is a primary narrator voice plus SSML-driven prosody shifts in dialogue, small changes in pitch, rate, and emphasis that cue “different speaker” without breaking continuity. That work belongs in preprocessing, where you can apply it consistently across the manuscript, not as a patchwork post-synthesis edit.
If you’re modeling total cost of ownership for these advanced use cases, you’ll also need clarity on commercial terms. Understanding pricing and plans for commercial use is part of the diligence before you commit to infrastructure at catalog scale, volume pricing, licensing terms, and API rate limits all land directly in your unit economics.
Key Takeaways and Next Steps
AI audiobook generation has moved from “interesting” to operational. Publishers are using it to expand audio catalogs, lower production costs, and finally give mid-list and backlist titles a path to listeners. The fastest movers aren’t automatically the biggest houses; they’re the teams that treated this like production engineering, clean manuscript workflows, disciplined voice selection, and API-based pipelines built to run titles in parallel.
The most important decisions in building an AI audiobook program:
Build preprocessing infrastructure before you ramp synthesis volume. Clean input is still the biggest quality multiplier.
Evaluate voices on long-form samples pulled from your manuscripts, not polished demo clips.
Design for batch processing from day one, even if the first step is a small pilot.
Confirm platform requirements and author contract language before production starts.
Validate multilingual output with native-speaker listeners before you commit to a language.
Pick an API partner whose pricing and commercial licensing terms match your target catalog volume.
Publishers keep running into the same constraint: plenty of titles deserve an audio audience, but traditional studio production can’t justify the spend. A production-grade AI narration pipeline changes that equation, if it’s built on an API designed for long-form from the start. Smallest.ai's Lightning TTS engine is built for voice consistency, synthesis speed, and the API architecture needed to convert backlist titles at scale while keeping a coherent sound across a catalog. If you want to scope what that looks like for your list, Smallest.ai pricing and the broader product suite are a straightforward place to start.
What is AI audiobook generation, and how does it differ from traditional text-to-speech?
Which audiobook distribution platforms currently accept AI-narrated titles?
How do I ensure voice consistency across a 10-hour audiobook?
Can AI narration handle multiple character voices within a single audiobook?
What should publishers look for when comparing AI audiobook generation solutions?

