

AI narrator voice selection for audiobooks in 2026, with a practical checklist for quality, throughput, pricing, licensing, multilingual support, and labeling.
The AI-generated voiceover narration market is on a steep growth curve, and the practical question for publishers has shifted from whether AI narration is viable to which platform is worth trusting for long-form production. For publishers, indie authors, and production studios, the practical question is the same: which text-to-speech model is actually worth trusting for long-form narration?
Choosing well means looking past the shiny demo and getting specific about what matters: voice quality, throughput and latency, pricing, licensing, multilingual coverage, and the ethical frameworks that are quickly becoming table stakes. If you are a solo author trying to ship one book or a publisher planning to scale across a catalog, the same criteria apply. You will see what makes a voice viable for audiobooks, which technical benchmarks are worth measuring, how pricing and licensing really work, what ethical and legal constraints you need to respect, and how to run a practical evaluation before you commit.
What Actually Makes a Voice 'Audiobook-Ready'
Most teams start with a demo clip. That is rational, but it is also a trap. Thirty seconds will not tell you how a voice behaves over eight hours, whether it keeps its footing across chapter transitions, or how badly it mangles your niche terminology by chapter four. Audiobooks demand a higher and different bar than a two-minute explainer or an IVR prompt.
The gap between "good enough" and audiobook-ready usually shows up in four places. First: prosody consistency. The voice has to carry rhythm, stress, and intonation across thousands of sentences without sliding into monotone or sprinkling odd emphasis where it does not belong. Second: emotional range. Fiction in particular forces the model to move cleanly between dialogue, interiority, and scene-setting without sounding like it is reading three different books. Third: pronunciation accuracy. Proper nouns, loanwords, and technical terms need reliable handling, ideally via phoneme-level control or strong SSML support. Fourth: clean audio. Clicks, breath weirdness, and pitch seams that you might ignore in a short sample become exhausting when a listener has been wearing headphones for hours.
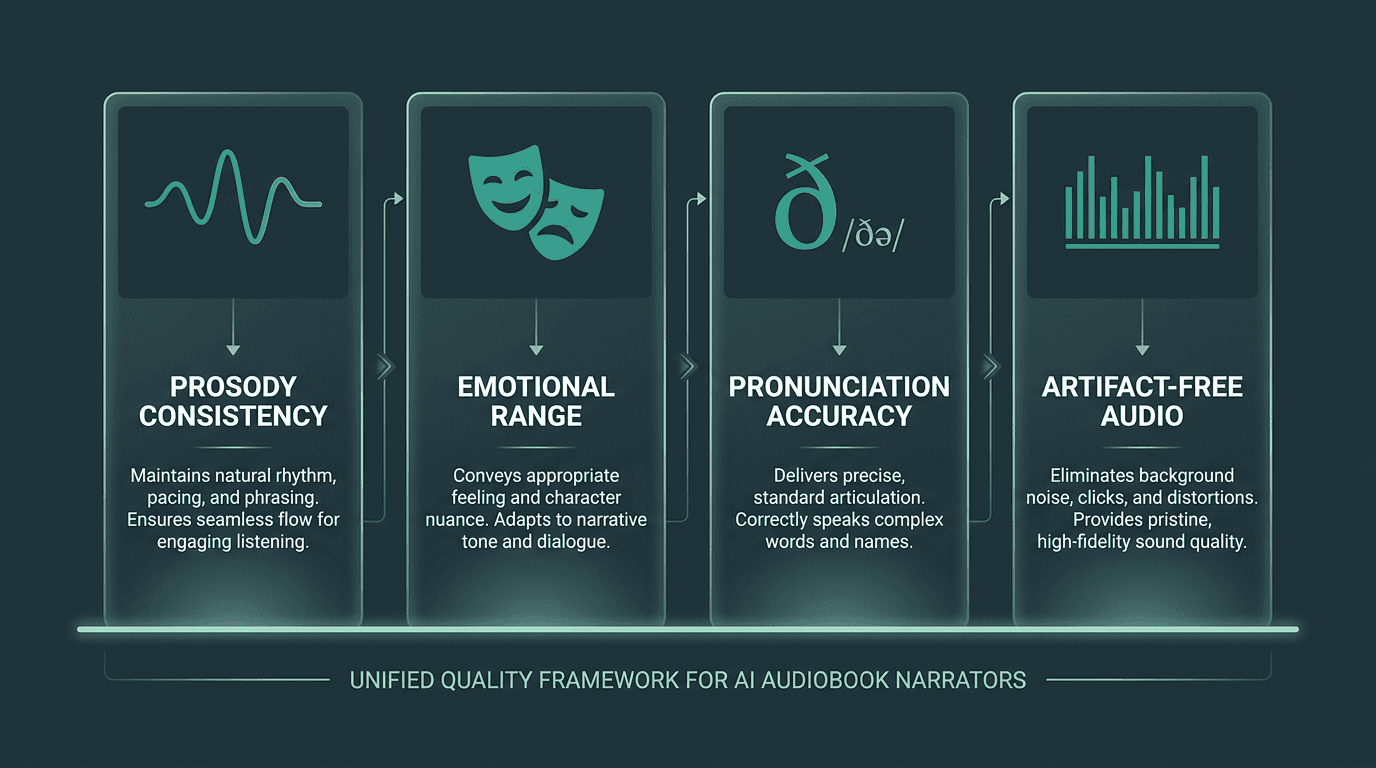
The four quality pillars that determine whether a TTS voice can sustain a full-length audiobook.
Technical Benchmarks Worth Measuring Before You Commit
Latency gets most of the attention in real-time voice agents, but audiobook production has its own version of the problem. If you are rendering chapters in batches, raw throughput matters more than first-token latency. A model that runs at 10x real-time can render a 10-hour audiobook in about an hour. A model that runs at 2x real-time needs roughly five hours. Once you are producing at volume, that delta stops being academic.
If you want a broader technical baseline before you start comparing vendors, understanding voice model architectures and use cases is a solid place to anchor your thinking. The architecture behind a TTS model (diffusion-based decoder, flow-matching approach, transformer-based vocoder) shows up directly in both output quality and throughput.
Specific benchmarks to request from any TTS vendor before signing up:
Throughput rate: Characters or words processed per second in batch mode, not just streaming mode.
Mean Opinion Score (MOS): Industry-standard perceptual quality rating, ideally from a third-party evaluation rather than the vendor's own testing.
Word Error Rate (WER) on domain-specific text: Test with your actual manuscript, not generic benchmark sentences.
SSML support depth: Can you control pauses, emphasis, phoneme pronunciation, and speaking rate granularly?
Audio format options: 24kHz minimum for audiobook distribution; 44.1kHz or 48kHz preferred for ACX and Findaway compliance.
Stability across long inputs: Does quality degrade after 500 words of continuous input? Test with 2,000-word chunks.
Pricing Realities: What You Are Actually Paying For
TTS pricing is messy enough that you cannot eyeball it; you have to do the math. Many providers charge per character (often per 1,000 characters). A typical audiobook lands around 60,000 to 100,000 words, or roughly 360,000 to 600,000 characters. At $0.015 per 1,000 characters (a common mid-tier rate), that works out to $5.40 to $9.00 per title in raw API spend. At $0.030 per 1,000 characters, you are at $10.80 to $18.00 for the same manuscript.
For a single book, those numbers feel almost too easy. Multiply by 50 titles a month and pricing tiers start to look like strategy, not trivia. You also need to budget for voice cloning fees (often a separate one-time or monthly add-on), storage for generated audio, and any per-seat licensing if multiple team members touch the API. Smallest.ai pricing is designed to stay transparent at volume, which matters when you are forecasting across a catalog rather than arguing about one project.
One recurring gotcha: a provider advertises an attractive per-character rate, then walls off the best voices behind premium tiers. Treat that as a product constraint, not an inconvenience. Test the exact voice you plan to ship, at the tier you plan to pay for; the demo voice and the production voice are not always the same thing.
The Ethical and Legal Layer You Cannot Ignore
Voice AI has been moving faster than the rules around it, and the gap is starting to close. The Audio Publishers Association issued naming guidelines in 2024 that draw an operationally useful line (APA AI Narration Naming Guidelines, 2024): “AI Voice” is a generic synthesized voice with no specific human source, while an “Authorized Voice Replica” (AVR) is cloned from a specific, licensed human voice actor. Those labels are not interchangeable, and using the wrong one on a product listing is increasingly about compliance, not marketing taste.
SAG-AFTRA’s 2023 actions made the stakes explicit: voice actor rights are now a legal variable in your production plan. If your workflow includes voice cloning, you need to know where that voice came from and what permissions sit behind it. A serious TTS provider should be able to state clearly whether models were trained on consented data and whether cloning requires explicit consent from the source voice actor.
Retail distribution is also tightening disclosure expectations. The APA guidelines are a strong proxy for current best practice, and aligning early is cheaper than doing retroactive cleanup later. The ethical and regulatory conversation around synthetic voice is moving quickly, which is why this labeling discipline is showing up as a production requirement now, not a future concern.
Multilingual Narration: A Capability Gap That Matters More Than It Used To
Global audiobook distribution has turned multilingual narration into a production requirement, not a bonus feature. A book that works in English can have real upside in Spanish, Portuguese, or Hindi. The hard part is deciding whether one TTS model can carry that workload with consistent quality, or whether you need separate models (and separate QA) per language.
Most enterprise TTS vendors will tell you they support 20 to 50+ languages. That number is not the same as “sounds good to native listeners.” A model can accept Hindi text and still produce audio that feels off in cadence, stress, or phonetics. Native-speaker evaluation is the only test that counts; language-count marketing is not. If you are planning for global reach, pre-trained multilingual voice models can reduce integration overhead compared to maintaining separate model pipelines per language.
Language support breadth and language quality are two different metrics. Global publishers need both.
Running a Practical Evaluation: A Framework That Actually Works
If you already run structured TTS evaluations with a rubric and a listener panel, you can move on. If you do not, this is a workable process that fits inside a week and leaves you with a decision you can defend internally.
Start with a test corpus that looks like your book, not a vendor’s canned paragraph. Pull three excerpts from the manuscript: a dialogue-heavy scene, a dense descriptive passage, and a section packed with proper nouns or technical terms. Those three clips will pressure-test what matters for your content. Run each excerpt through every model using identical SSML (or intentionally no SSML, if you want to measure baseline behavior rather than your ability to hand-tune it).
Evaluation scoring rubric (rate each dimension 1-5 for each model):
Naturalness: Does the voice sound like a human narrator, or does it feel synthetic?
Prosody accuracy: Does stress and rhythm match the intended meaning of each sentence?
Dialogue handling: Can the voice differentiate between character voices or narrative register shifts?
Proper noun pronunciation: Are names, places, and technical terms rendered correctly?
Artifact count: How many clicks, breath anomalies, or pitch breaks appear in a 500-word sample?
Listener fatigue: After 20 minutes of continuous listening, does the voice remain engaging?
Make it blind. Have at least three people score the samples without knowing which model produced which audio. Preference bias is real, and if you already like a vendor you will find ways to "hear" quality that is not there. Blind scoring forces the output to stand on its own.
Voice Cloning for Audiobooks: When It Makes Sense and When It Does Not
Voice cloning is not a blanket solution; it is a targeted tool. The cleanest use case is an author who wants to “narrate” their own book but cannot spend days in a booth, or an established narrator who wants to license their voice for titles they cannot personally record. In both scenarios, the clone comes from consented source audio, and the finished audiobook fits the APA’s definition of an Authorized Voice Replica.
The messy part shows up in high-volume catalog production, where a publisher wants one consistent voice across dozens of titles without paying per-title narration fees. The economics can look compelling. The legal risk is not theoretical if the underlying voice model is built on poorly licensed data. Any TTS provider offering cloning should be able to produce documentation for its consent framework. If they cannot, treat that as a serious red flag regardless of how good the samples sound.
If you want consistency without cloning, there are other paths. In practice, the choice between a cloned voice and a high-quality synthetic voice often comes down to brand consistency and rights management more than raw audio quality.
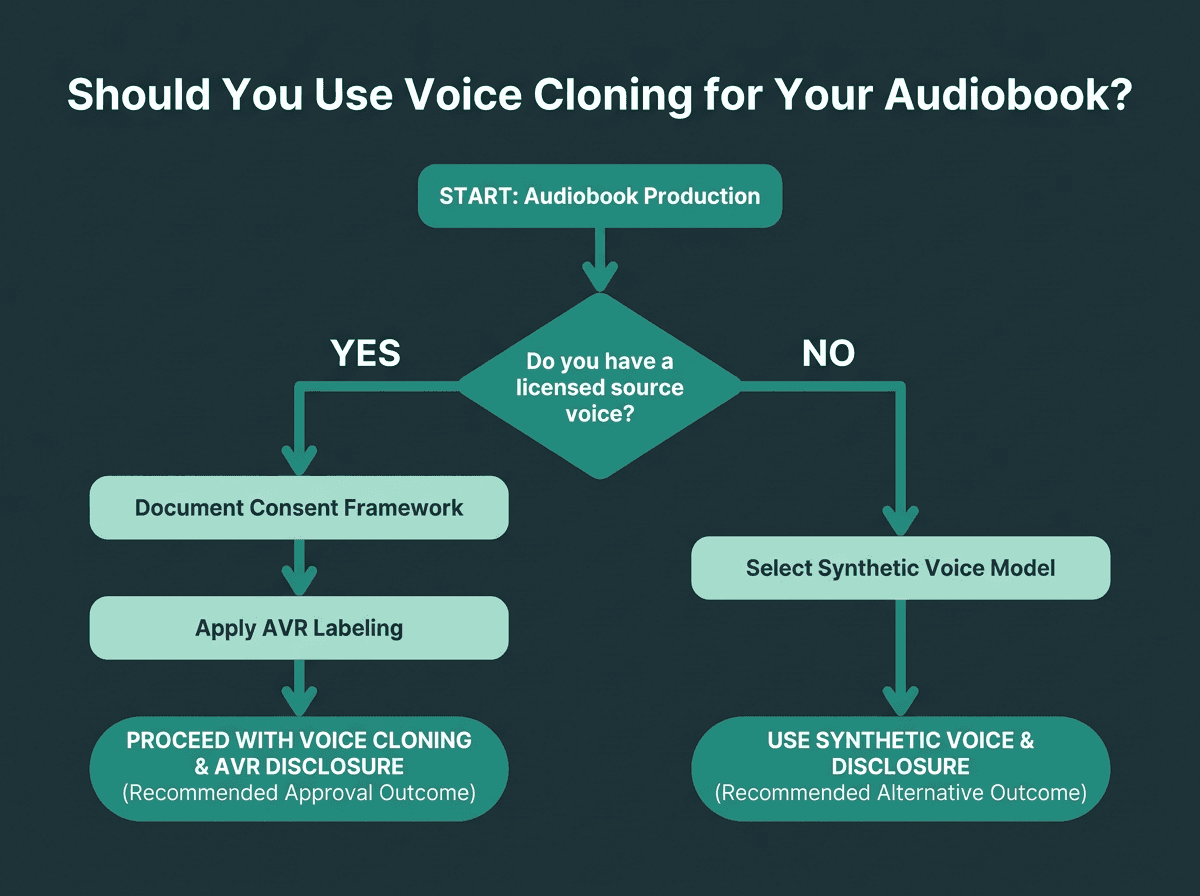
A structured decision path for determining whether voice cloning fits your audiobook production workflow.
How to Choose Your 2026 Voice Agent Stack for Audiobook Production
A TTS model is only one part of an audiobook pipeline. If you are producing at scale, you also need transcription to verify accuracy, post-processing for normalization and noise control, and distribution integrations that do not turn every release into a custom project. Evaluating TTS in isolation is how teams end up with painful integration surprises late in the schedule.
A single vendor can simplify billing and support, but it also concentrates dependency. Best-of-breed preserves flexibility, but you pay for it in integration time. There is no universal answer; it hinges on engineering capacity and production volume.
The vendor lineup in AI-generated narration will keep shifting as the market matures. If you lock yourself into proprietary formats or non-portable voice models now, you are effectively pre-paying switching costs later. Favor providers that output standard audio formats and back them with documented APIs.
Key Takeaways and Next Steps
The decisions that matter most when choosing an AI narrator voice for audiobooks:
Evaluate voice quality on your actual manuscript content, not vendor demo clips.
Measure throughput in batch mode, not just streaming latency.
Understand the pricing structure across the specific voice tier and volume you will actually use.
Verify the consent and licensing framework behind any voice cloning feature.
Align your output labeling with APA guidelines from the start.
Test multilingual quality with native-speaker evaluation, not language count.
Build your stack with portability in mind: standard formats, documented APIs.
Most publishers do not suffer from a lack of TTS options; they suffer from a lack of a decision process that matches long-form narration. Tools tuned for short-form content tend to fail in subtle ways on audiobooks, and you often do not notice until you are deep into production. A structured evaluation surfaces those issues early, when switching is still cheap.
For teams producing long-form narration at scale, Smallest.ai’s Lightning TTS API offers low-latency speech generation, SSML control, multilingual support, and voice cloning workflows built for production use. With sub-100ms latency, broad SSML support, and voice cloning built around a transparent consent framework, it targets the failure modes that tend to derail audiobook pipelines.
AI Voice vs. Authorized Voice Replica: what is the difference for audiobooks?
How many characters are in a typical audiobook, and what does that cost in TTS API fees?
Can one TTS model handle both fiction and non-fiction narration well?
What audio specs do major audiobook distribution platforms require?
How does Smallest.ai's Lightning API support long-form audiobook narration?

