

AI voice generation for podcasts: real use cases, voice cloning vs stock voices, quality checks, workflow automation, and ethics for media teams.
AI voice generation has moved from experimental tooling to a practical part of modern media production. Teams now use synthetic voices to reduce recording bottlenecks, localize content, and maintain consistent audio across growing content libraries.
This piece is for podcasters, media producers, content strategists, and developers who want a clear view of what synthetic voice can do, where it actually saves time, and where the tradeoffs bite. The goal is practical: understand which workflows benefit most, how to judge voice quality, what ethical obligations come with the territory, and how to start building with the right tools.
What AI Voice Generation Actually Does
AI voice generation turns written text into spoken audio using neural networks trained on large datasets of human speech. The better systems do more than read words: they model prosody (the rise and fall of natural speech), pacing, emotional register, and even breath patterns. In the right context, the output can land close enough to a studio take that listeners may find the audio comparable to professionally recorded narration in many common use cases.
Modern neural voice systems have significantly improved intelligibility and naturalness across a wide range of listening environments. If your audience listens on trains, in cars, or through cheap earbuds, intelligibility is not an academic metric; it is the show.
Under the hood, most modern voice generation platforms follow the same three-part stack: a text normalization engine (to handle numbers, abbreviations, and punctuation), an acoustic model (to predict how phonemes should sound), and a vocoder (to turn those predictions into an actual waveform). The gap between consumer tools and production APIs shows up in the edges: proper nouns, technical jargon, mid-sentence tonal pivots, and cross-language phoneme mapping. That is where "good enough" becomes editing debt.
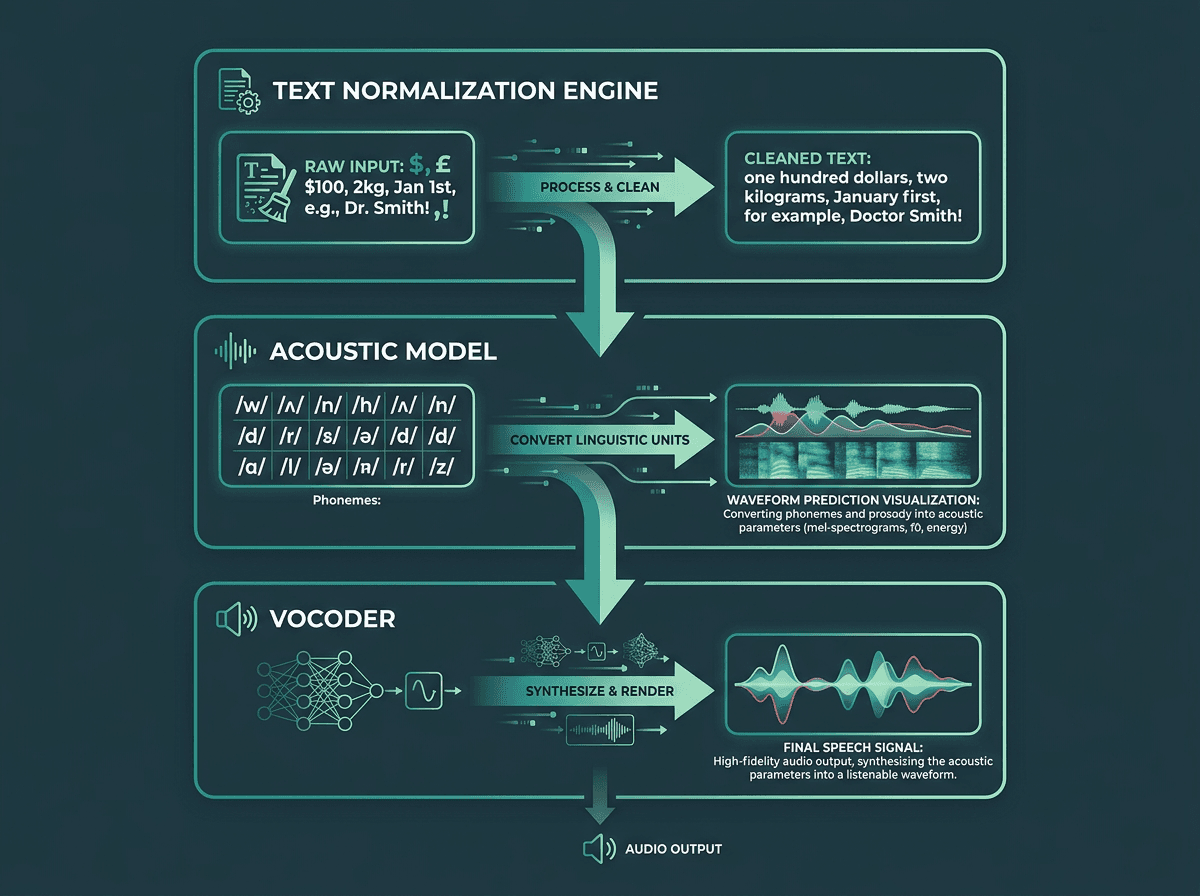
Three-layer stack powering production-grade **AI voice generation**: from raw text to final audio waveform.
Where Podcasters Are Actually Using This Technology
In podcasting, the patterns are pretty consistent: teams reach for synthetic voice when it removes a scheduling bottleneck or makes distribution meaningfully broader.
Where AI voice generation delivers real production value in podcasting:
Solo show narration: Writers who are not comfortable on the microphone can ship polished audio from scripts without booking recording sessions.
Ad insertion and sponsorship reads: Generate consistent, brand-safe ad reads in a host's cloned voice without pulling everyone back into the studio.
Multilingual episode versions: Translate and re-voice an episode in Spanish, Hindi, or Portuguese without hiring separate voice talent for each market. This is a common use case for multilingual voice dubbing.
Evergreen content refreshes: Fix a dated segment or swap sponsor messaging by regenerating only the lines that changed, not the entire episode.
Accessibility audio: Turn newsletters, blog posts, or transcripts into listenable audio for audiences who prefer ears-over-eyes consumption.
Trailer and promo production: Produce short promos quickly without blocking studio time.
Teams also use AI to automate the adjacent chores that quietly eat production hours: transcription, editing out filler words, generating show notes, and cleaning up audio with noise reduction. Voice generation sits near the front of that assembly line, but it pays off most when the rest of the pipeline is similarly streamlined. If you are already doing podcast transcription and feeding it back into editing and distribution, speech-to-text is the obvious companion to TTS.
Voice Cloning vs. Stock Voices: Choosing the Right Approach
Most AI voice decisions come down to one question: do you pick a stock voice from a library, or do you clone a specific person? Both are valid. Neither is automatically "better." The right call depends on how your audience relates to the show, what you are producing, and whether a particular voice carries real brand equity.
Factor | Stock / Library Voices | AI Voice Cloning |
|---|---|---|
Setup time | Instant: no training step | Needs voice samples (usually 30 seconds to a few minutes of clean audio) |
Audience familiarity | No built-in association with your brand | Keeps the host identity listeners already trust |
Consistency | Stable across all content | Stable to the cloned voice, quirks included |
Use case fit | New shows, anonymous narration, B2B content | Established shows, host-led brands, multilingual expansion |
Ethical complexity | Low | Higher: requires explicit consent and clear disclosure |
Cost model | Typically per-character or per-minute | Often per-character, plus a one-time clone setup |
If the host's voice is the product, AI voice cloning is often chosen when maintaining a recognizable host identity is important. It allows for voice cloning for brand consistency and lets a host keep publishing without being in front of a mic for every update. That flexibility also comes with additional responsibilities around consent, disclosure, and governance.
The Ethics Are Not Optional

Ethical AI voice use rests on three non-negotiable pillars: consent, transparency, and fair compensation.
Even if you only use stock voices, this part still applies. The norms around synthetic audio are shifting quickly, and listeners are getting better at spotting when something feels off.
Most ethical frameworks for AI voice generation boil down to three requirements: explicit consent before cloning any voice, transparency with audiences when synthetic voices are used, and fair compensation for voice owners whose recordings trained the model. These are not abstract ideals. In several jurisdictions, using someone else's voice without consent can trigger right-of-publicity claims, and regulation around synthetic media keeps tightening.
For podcast production, the practical version is simple. If you plan to clone a co-host and generate content while they are unavailable, get written permission first. If an episode uses AI-generated audio, say so. People tend to react badly when they feel tricked, and the reputational hit is usually bigger than whatever time you saved. Treated the right way, disclosure can also work in your favor: it signals you are being deliberate, not sneaky.
Evaluating Voice Quality: What the Specs Do Not Tell You
Most platforms sell the same trio of promises: "natural-sounding," "low-latency," "multilingual." Without tests, those words are basically decoration. When you are choosing a system for media production, a few concrete checks reveal more than any spec sheet.
Prosody under pressure. Give the model a sentence with a question inside it, a parenthetical aside, and a list. Weak models iron everything flat. Strong ones move emphasis and rhythm the way a good narrator would, without sounding like they are following a template.
Proper noun handling. Try your guest names, brand names, and the jargon your audience expects you to get right. If a tech show cannot pronounce "Nguyen" or "Kubernetes," listeners notice immediately. Look for phoneme-level overrides or pronunciation dictionaries so you can lock in the way your show says things.
Latency for live or near-live use. If you are building dynamic audio (personalized intros, real-time responses), latency stops being a nice-to-have and becomes a hard limit. Streaming TTS APIs that start emitting audio before the full text is processed behave very differently from batch systems that only return a file at the end.
Emotional range. Neutral narration is not enough for every format. Interview shows, true crime, and scripted storytelling often need urgency, warmth, or skepticism without veering into melodrama. Test with emotionally loaded scripts, not just clean marketing copy.
For developers wiring text-to-speech for podcasts into a production pipeline, consistency across API calls matters as much as a single great sample. If the voice shifts noticeably from one render to the next, you will spend the saved time patching transitions and re-leveling audio.
Building an AI-Powered Podcast Production Workflow

A fully AI-assisted podcast workflow reduces production time while maintaining consistent audio quality.
Automation works when it is designed into your process, not stapled on later. Below is a production architecture that has proven workable for both independent podcasters and larger media teams because it keeps the handoffs clean and the outputs predictable.
Stage 1: Script to audio. Write (or import) your script, then send it to a TTS API. For text-to-speech podcast solutions, you will want SSML (Speech Synthesis Markup Language) support if you need precise control over pauses, emphasis, and pronunciation. Render to WAV or a high-bitrate MP3, depending on what your editor and distribution pipeline expect.
Stage 2: Audio post-processing. Run the generated track through noise reduction and normalization. AI audio is usually cleaner than a home recording, but you still need loudness normalization to -16 LUFS, which is the standard target for podcast platforms.
Stage 3: Transcription and metadata. Send the finished audio through speech-to-text to produce a transcript. That transcript can pull triple duty: show notes, SEO content, and accessibility. Tools that handle podcast transcription with speaker diarization cut down the most annoying part of the job: cleaning up who-said-what by hand.
Stage 4: Multilingual versioning. Translate the script, generate a new voice track in the target language (either with a localized stock voice or a multilingual clone), then publish as a separate feed or episode variant. This used to mean weeks of scheduling translators, talent, and studio time. With the right pipeline, it can run in hours.
Advanced Considerations for Media Teams
At scale, the details start to matter. These are the issues that tend to separate a deployment that merely works from one that stays stable as your catalog and audience grow.
Voice consistency across a catalogue. Once you are generating hundreds of episodes or segments, voice drift is not theoretical. Platforms update models, and even subtle changes can make a cloned voice feel "off" across seasons. Pin production to a specific model version, and treat upgrades like you would any other release: test, compare, then roll forward.
Dynamic audio personalization. The most ambitious media products are moving past static episode renders toward personalized audio. Picture a news briefing that greets the listener by name, references local weather, and adjusts runtime to fit a commute. That is already happening in voice AI apps built on streaming TTS infrastructure. To make it work, you need low-latency generation that can handle variable input in real time; a batch-only system will not keep up.
Rights and licensing hygiene. Stock voice libraries are not all licensed the same way. Confirm that the terms cover commercial podcast distribution, including monetized episodes and sponsor reads. Some offerings only allow internal use, which is an easy way to stumble into legal exposure after you publish.
Audience disclosure strategy. Treat disclosure as part of the relationship, not a checkbox. When listeners hear upfront that a show uses AI-assisted production - and they understand the reason (scale, accessibility, multilingual reach) - they are typically more comfortable than when they discover it later. A short note in the show description or an episode intro is cheap insurance.

Four key considerations for scaling **AI Voice Generation** in media production at catalogue depth.
Key Takeaways and Next Steps
AI voice generation is not a license to ship sloppy audio. Used with intent, it removes the bottlenecks that keep small teams small: recording schedules, limited language coverage, and inconsistent sound. The tech is ready for production. The ethical expectations are well-defined. What determines the outcome now is how carefully you implement and govern it.
What to take away from this guide:
AI voice generation spans everything from straightforward narration to real-time personalized audio. Pick the tier that matches your actual use case.
Voice cloning and stock voices solve different problems. Cloning fits host-led brands; library voices are fine for new or anonymous formats.
Consent, transparency, and compensation are non-negotiable - and increasingly enforceable.
Ignore generic marketing claims and run real tests: prosody, proper nouns, emotional range, and API-to-API consistency.
The workflows that scale best connect voice generation, transcription, and multilingual distribution into one automated pipeline.
Most teams arrive at AI voice generation for the same reason: production bottlenecks limit how much they can publish, how many languages they can serve, and how quickly they can respond to demand. Smallest.ai's Lightning Text-to-Speech API is designed around that constraint. It delivers low-latency voice generation suitable for production workflows, supports voice cloning for brand-consistent output at scale, and integrates into production workflows through developer-friendly APIs and tooling. If you are ready to move from manual recording toward a more automated workflow, text-to-speech podcast solutions from Smallest.ai are a strong place to start.
How realistic does AI-generated podcast audio sound in 2026?
Can I use AI voice generation to create a podcast in multiple languages?
Do I need to disclose to my audience that I am using AI-generated voices?
What is the difference between a text-to-speech API and a voice cloning service?
How do I integrate AI voice generation into my existing podcast production workflow?

