Voice Cloning for Brand Consistency: How Teams Can Scale a Single Voice Across Products and Channels


Voice cloning can keep one brand voice consistent across IVR, apps, video, and localization. System design, deployment layers, and consent basics included.
Voice cloning is more than a novelty. It addresses a real operational headache: brands spend years building a recognizable sound, then splinter it the minute they have to ship at speed. One team records a voice for the app. Marketing hires a different narrator for ads. Support drops in a generic synthetic voice for the IVR. Before long, the company sounds like three different companies.
This is written for product managers, audio directors, and engineering leads who want to fix that fragmentation without turning every release into a casting session. You’ll get the technical model of how voice cloning works, the system design patterns that let one voice travel across channels, and the governance practices that keep the whole thing legal and unmistakably on-brand. The structure is deliberate: start with fundamentals, move into architecture, then deployment, and end with the uncomfortable questions teams usually discover after launch.
What Voice Cloning Actually Does (and What It Does Not)
People often assume voice cloning is just recording, neatly packaged. It isn’t. Voice cloning replicates a person’s voice using a text-to-speech (TTS) system, aiming to preserve characteristics like quality, naturalness, prosody, and timbre so the result closely resembles the target speaker. What you end up with is a generative model, not a folder of clips. Feed it new text and it produces speech that sounds like the original speaker said those words, even when they never did.
For brand teams, that difference is the whole point. You’re not licensing a finite set of takes; you’re commissioning a voice model that can generate new content on demand, at volume, without booking studio time. That’s how scale happens: the voice becomes a production primitive, not a scheduling constraint. If you want a more technical primer before you start making system decisions, how voice cloning works is a solid place to start.
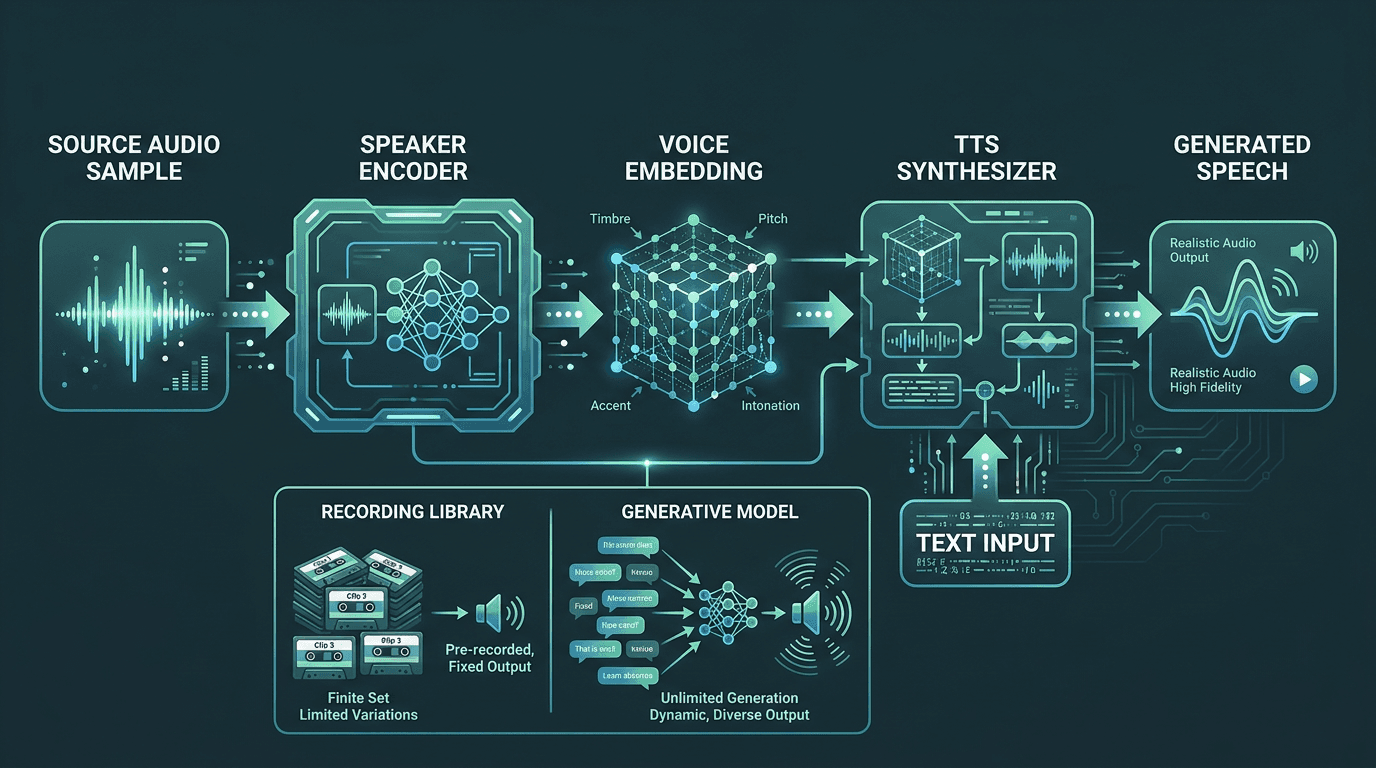
The voice cloning pipeline: from source audio to a generative model capable of unlimited new utterances.
Why Brand Consistency Breaks Down at Audio Scale
Brand consistency is about keeping a company’s presentation and values coherent across channels, so customers build recognition and trust. Visual teams have spent years building the tooling for this: design tokens, component libraries, style guides, and review workflows that make consistency the default. Most organizations don’t have an equivalent stack for audio.
The breakdown tends to follow a familiar script. First crack: talent availability. The narrator who voiced the original product walkthrough is suddenly booked, unavailable, or too expensive for the next sprint, so a substitute steps in. Then another. Eighteen months later, the product sounds like it’s been passed between three companies. Second crack: localization. Translating audio for new markets usually means hiring local talent who match the language but miss the original voice’s character. Third crack: channel proliferation. The voice that works for a long-form explainer is rarely the right fit for a real-time IVR system or a two-second push notification readout.
Brands are adopting voice cloning to blunt those specific failure modes: producing more content without a studio bottleneck, localizing for global markets while keeping tone consistent, and keeping key voices present in communications without new recording sessions for every update. The fix isn’t a slightly better recording workflow. It’s treating voice as a system: a voice identity architecture.
Building a Voice Identity Architecture
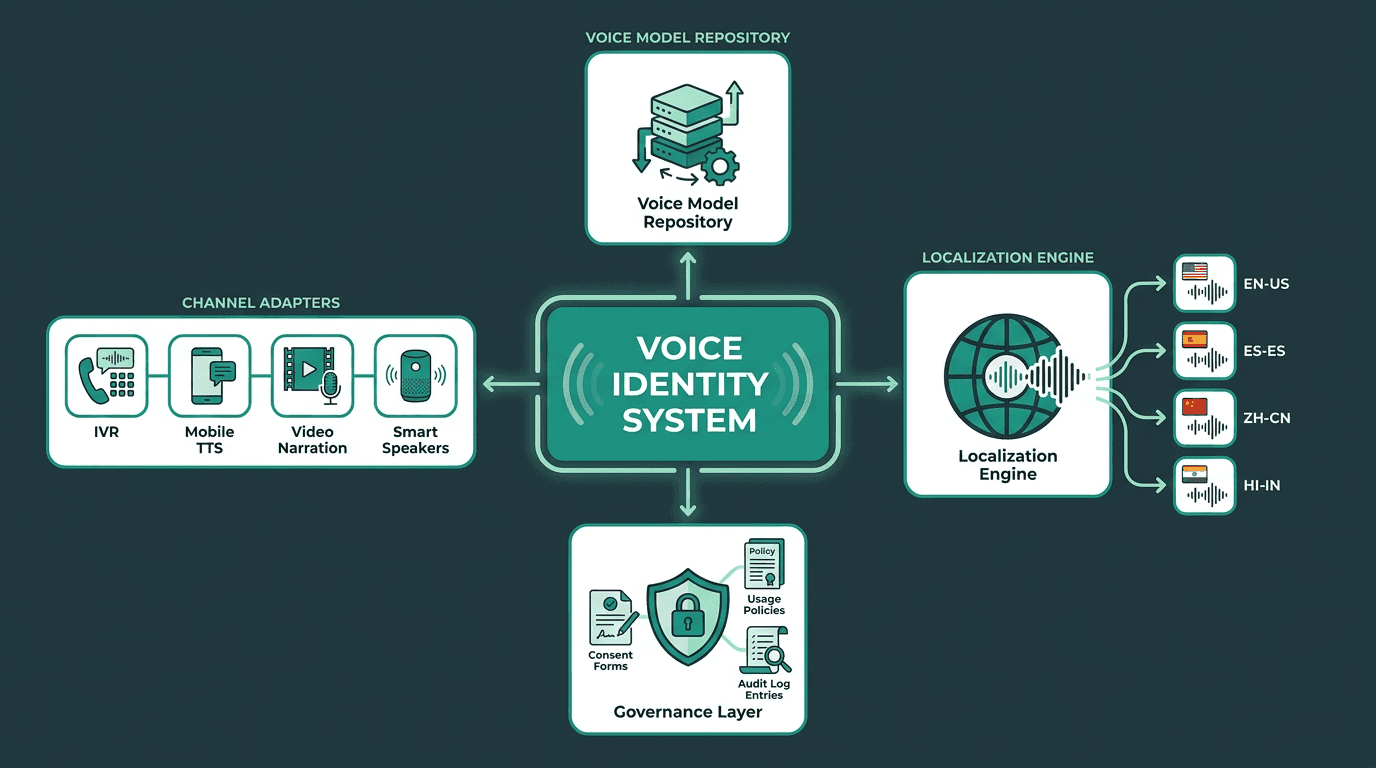
A voice identity architecture treats the cloned voice as infrastructure, not a one-off production asset.
The most useful mental shift is to treat a cloned voice like a design system or a brand font: a first-class infrastructure asset, not a file someone emails around. Once you make that shift, a few upfront decisions stop being optional and start being foundational.
Core components of a scalable voice identity system:
Voice model repository: One version-controlled source of truth for approved voice models. Every team pulls from it. No local copies and no ad-hoc recordings.
Channel-specific output configurations: One voice model, many renderings. A customer support IVR needs slower pacing and cleaner enunciation; a product walkthrough can move faster and carry more expression. Those differences should live in configuration parameters, not in separate models.
Localization pipeline: Language variants derived from the same core voice identity, keeping timbre and character intact even as the language changes. This is where deep learning and real-time TTS become operationally meaningful.
Governance layer: Usage policies, consent documentation, and audit logs. Every generated output should map back to an approved model and an authorized use case.
Teams that postpone governance usually end up paying for it later. The legal and ethical rules around synthetic voices are moving quickly, and the direction of travel is clear. The EU AI Act and multiple U.S. state laws now regulate digital replicas and require labeling of synthetic audio content. It’s far easier to build an audit trail on day one than to bolt one on after a compliance review or a public incident.
Practical Deployment: From Studio to API
Most voice cloning projects don’t fail because the model can’t sound good. They stall because everything around the model is underbuilt. The voice is the flashy part; integration is the work.
A production deployment usually has three layers. Layer one is the voice synthesis API: text goes in, audio comes out. Layer two is content management: scripts, approvals, and versioning happen here before anything hits the API. Layer three is delivery: caching, format conversion, and channel-specific encoding. Treating the system as a single “text in, audio out” step leads to brittle pipelines that snap the moment a channel needs a different codec, or a script change forces you to invalidate cached audio across environments.
If you’re thinking seriously about operating a voice agent at scale, model the cost structure early rather than after usage spikes. Synthesis costs add up fast. A pragmatic pattern is to cache high-frequency phrases (greetings, menu options, standard responses) and reserve real-time generation for the parts that actually need to be dynamic. You keep the flexibility that makes voice cloning attractive, without letting spend drift into “we didn’t expect this” territory.
What Most Teams Get Wrong About Voice Consistency
Consistency isn’t the same thing as uniformity. A brand voice should feel like the same person in every context, but that “person” still adapts. They speak differently in a crisis notification than in a product tutorial. The common failure is freezing one prosody configuration across every channel and calling the result consistent. What you actually get is a voice that’s stiff where it should be warm, or breezy where it should be precise. Real consistency keeps timbre, character, and identity stable while letting delivery shift with context. That’s why channel-specific prosody profiles matter; a single global setting doesn’t survive contact with real products.
Ethics, Consent, and the Legal Baseline

A compliance checklist for voice cloning deployments: consent, labeling, and audit trails are non-negotiable.
Ethics in voice cloning can’t be treated like a sidebar. A voice is part of a person’s identity, not just another dataset. For brand teams working with human voice talent, the non-negotiable is explicit, written consent that spells out scope: which products, which markets, and how long the permissions last.
Regulators are paying attention, and not quietly. The FTC ran a Voice Cloning Challenge to encourage tools for prevention, detection, and monitoring of synthetic voices, an unusually direct signal about how seriously the agency is taking the space. For brand teams, that’s a prompt to tighten documentation around consent and usage scope, not a reason to steer clear of the technology altogether.
Security deserves the same level of rigor. Some research has shown that a usable voice clone can be created from just three seconds of source audio. In other words: once your brand voice is public, it’s also clonable by bad actors. That makes recognizing and avoiding voice cloning scams relevant not only as consumer safety advice, but as a practical input to protecting your brand’s audio identity from impersonation.
Scaling Across Products: A Channel-by-Channel View
Every channel comes with its own constraints, and those constraints shape what “good” output even means. Teams that ignore them often build something that sounds impressive in a demo and then degrades in production, where codecs, latency, and environment do the real judging.
Channel-specific considerations for voice cloning deployment:
IVR and telephony: Needs low-latency synthesis (typically under 300ms for real-time interaction), 8kHz or 16kHz audio encoding, and prosody tuned for clarity more than expressiveness. Caching is essential for static prompts.
Mobile and web apps: Can run higher audio quality (24kHz+), support more expressive prosody, and tolerate slightly higher latency. Streaming synthesis improves perceived responsiveness for longer outputs.
Video narration and explainer content: Offline synthesis is fine. The priorities shift to naturalness, breath patterns, and pacing that lands cleanly on visual edit points. Version control matters because script changes require re-synthesis.
Smart speakers and voice assistants: Expect platform-specific audio format requirements. Synthesis should account for the acoustic environment (living room, kitchen) and the platform’s conversational register.
Localized markets: One voice model generates output in target languages. Prosody profiles usually need tuning per language because rhythm and stress patterns vary sharply across language families.
If you want a concrete example of what this looks like in a high-volume service environment, it’s worth studying how AI voice systems show up in real operations. AI enhancements in hotel customer service lays out how consistency plays out across many touchpoints, where customers notice mismatches immediately.
Advanced Considerations: Voice Model Governance at Enterprise Scale
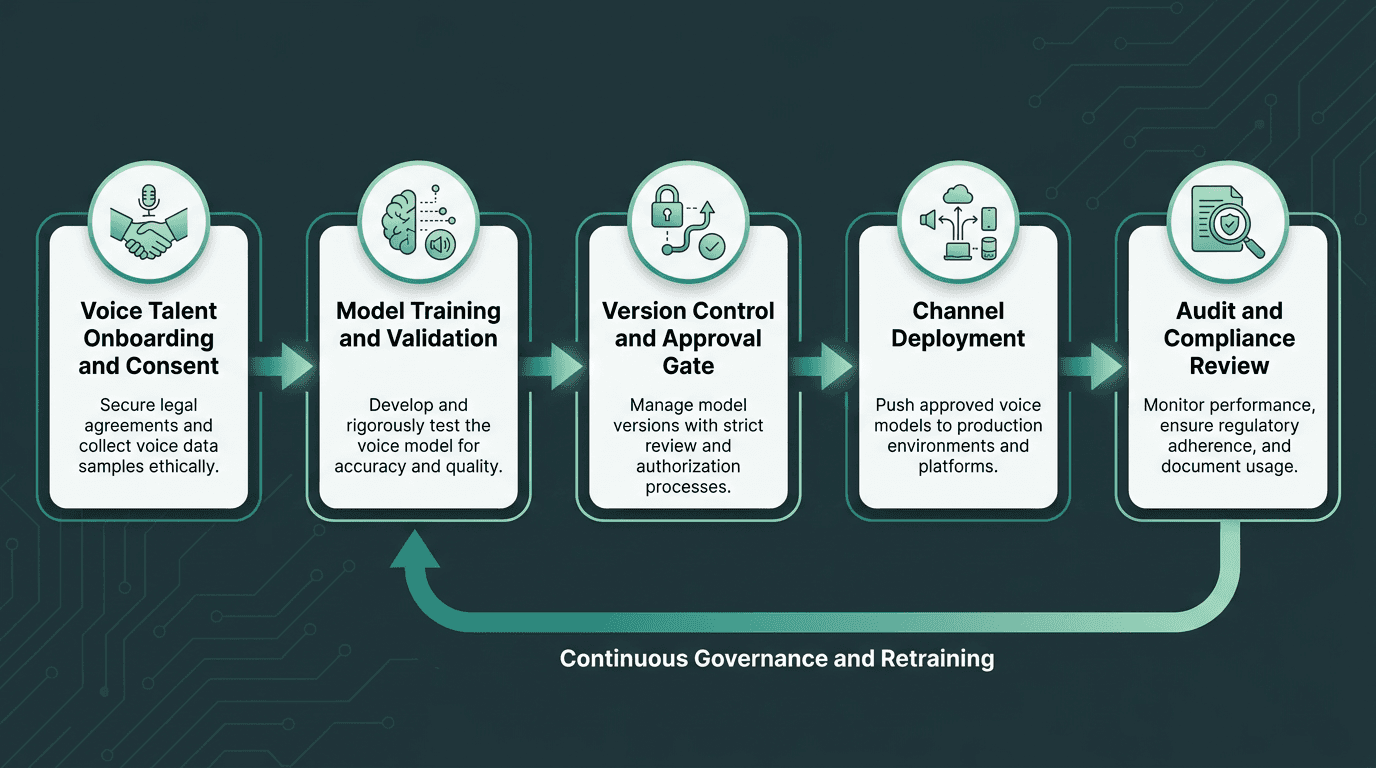
Enterprise voice governance: treating voice models with the same rigor as any other regulated brand asset.
At enterprise scale, governance stops being paperwork and starts being the product. Who can approve a new voice model? When a voice talent contract expires, do existing deployments keep running, or does the model get deprecated? If a cloned voice shows up in a context outside the original consent agreement, who owns the incident and what’s the remediation path?
These aren’t theoretical edge cases; they show up within twelve to eighteen months for organizations that deploy voice cloning broadly. The practical response is a governance policy with the same discipline you’d apply to other brand assets: version control, deprecation schedules, documented usage scope, and a clear approval chain for new use cases. Teams that adapt to your brand voice as a system tend to build this layer early, which makes later scaling less of a firefight.
Model drift is another issue that doesn’t get enough airtime. Voice models aren’t perfectly frozen in time: when the underlying TTS system changes, the same model weights can yield subtly different output. The fix looks a lot like standard software practice, set a baseline benchmark of reference phrases, then run regression tests after any system update to catch drift before it ships. In voice identity management, that kind of discipline is what keeps “consistent” from quietly decaying release by release.
Conclusion
Summary of key points:
Voice cloning generates new speech from a model, not a recording library. That’s what makes it a scaling mechanism rather than a mere production shortcut.
Brand audio fragmentation tends to follow three patterns: talent availability, localization, and channel proliferation. Voice cloning addresses all three when it’s deployed as infrastructure, not as a one-off tool.
A voice identity architecture needs a model repository, channel-specific output configurations, a localization pipeline, and a governance layer. Leave any one out and you’re creating technical debt that compounds fast.
Consent, labeling, and audit trails are legal baselines in many jurisdictions, not optional “nice-to-haves”.
Channel-specific prosody profiles are what make a voice feel consistent rather than uniformly flat. Consistency comes from a stable identity with context-aware delivery, not identical output everywhere.
Enterprise governance (version control, deprecation policies, and regression testing) is what separates a voice identity system from a voice identity liability.
The failure mode here is specific: brands build an audio identity, then lose it as soon as they need to scale across teams and channels. The remedy is just as specific: build the infrastructure so one approved voice can be deployed, configured, audited, and updated like any other core asset. Smallest.ai's voice cloning technology is designed for that deployment pattern. The Lightning TTS API targets low-latency synthesis for real-time channels, and the Waves API gives engineering teams programmatic access to voice models across products. Together, they turn “one voice everywhere” from a brand guideline into something you can actually ship and maintain. If you’re ready to move from fragmented audio to a single, scalable voice identity, Smallest.ai pricing plans are a practical place to start scoping what it looks like for your team.
How much source audio do I need for a high-quality voice clone?
Can one cloned voice work across languages without sounding off?
What legal requirements apply when using a cloned voice in commercial products?
How do I keep voice consistency when the underlying TTS system changes?
Is voice cloning fast enough for real-time uses like customer support IVR?