Voice Authentication in Contact Centers: A Practical Guide to Secure Customer Verification


Voice authentication for contact centers, explained: active vs. passive enrollment, UK GDPR compliance, fraud attack vectors, and a pilot-to-production checklist.
Voice authentication has moved past the pilot phase. Contact centers are where its growth gets operationalized: millions of identity-sensitive interactions a day, constant fraud pressure, relentless handle-time targets, and compliance teams watching the data trail more closely than ever.
This is for contact center architects, security leads, and product teams who are evaluating voice-based identity verification or already living with it in production. It covers the mechanics of how voice authentication works, where it fits in a real security stack, the compliance obligations you cannot hand-wave away, and the failure modes that vendor decks tend to gloss over. The goal is a decision framework: when active vs. passive enrollment makes sense, which attacks you should assume will happen, and how your speech AI infrastructure either reinforces your controls or quietly undermines them.
What Voice Authentication Actually Does (And What It Doesn't)
Voice authentication verifies a claimed identity using acoustic and behavioral signals in speech. Your voice carries a set of distinctive characteristics shaped by anatomy (vocal tract, nasal passages) and by habit (cadence, articulation, learned patterns). A voice biometrics engine turns those signals into features, often represented as a mathematical embedding, then compares the live sample to a stored reference template created during enrollment.
It also helps to be precise about the job you’re asking the system to do. Authentication answers: “is this the person they say they are?” by matching one voice sample to one stored voiceprint. Identification answers: “who is this?” by searching across a database of voiceprints. In contact centers, authentication is the default path: the caller supplies an account number or other identifier, then the system checks the voice against that specific template. Identification shows up in fraud screening, where the call is quietly compared against a watchlist of known bad actors.
What voice authentication doesn’t do is eliminate the rest of your controls. It’s a factor, not a verdict. If a caller matches a voiceprint but fails knowledge-based checks, or their device and call metadata look wrong, you still need a step-up path. The risky pattern is treating “voice match” as a binary gate that overrides everything else around it.
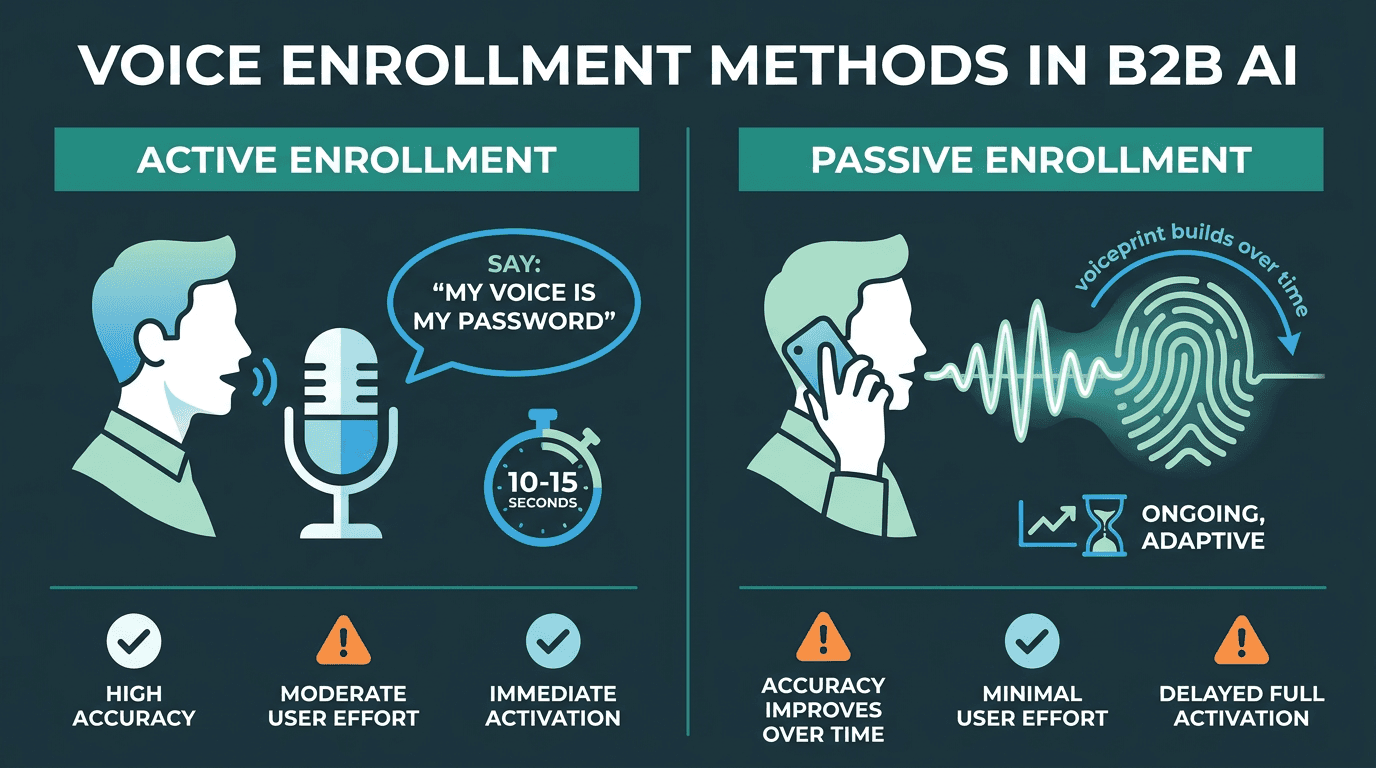
Active enrollment requires deliberate user action; passive enrollment builds a voiceprint silently during natural conversation
Active vs. Passive Enrollment: Choosing the Right Model
Active enrollment is the explicit version: you ask the caller to speak a specific phrase or repeat a prompted set of words during a dedicated enrollment step. The upside is speed and sample quality; many systems can produce a strong voiceprint with a short duration of clear speech, often in the range of 10 to 30 seconds. The downside is friction. Infrequent callers may not remember ever enrolling, and guided flows can shed users fast when the experience feels like a hurdle.
Passive enrollment works in the background during normal conversation, often across multiple calls. From the customer’s perspective, nothing changes. The system accumulates speech until it hits a confidence threshold, which may require a cumulative audio duration in the range of 45 to 90 seconds or more. Only then does passive verification start paying dividends on future calls. That makes it a good fit for high-frequency callers, but it delays the benefit and complicates consent: enrollment is happening without a clear “yes, enroll me” moment.
In practice, many enterprise rollouts converge on a hybrid. Offer active enrollment at the end of a successful interaction (“Would you like to set up voice ID for faster service next time?”), then use passive verification on later calls to keep the template current. You get the quality of a deliberate enrollment sample without dragging every customer through a scripted setup. It also keeps consent explicit and auditable, which matters under UK GDPR and similar regimes.
The Compliance Layer You Cannot Shortcut

Core compliance obligations for any contact center collecting and processing voice biometric data
Under UK GDPR, biometric data used for identification purposes is classified as sensitive personal data. That classification brings real requirements with it: explicit consent, a lawful basis for processing, and retention and deletion policies you can document and defend. Treat those as optional and you’re inviting enforcement action and significant fines.
For contact centers, compliance tends to land in four buckets. (1) Consent has to be freely given, specific, informed, and unambiguous; pre-ticked boxes and vague terms-and-conditions language don’t clear that bar. (2) Voiceprint templates (the embeddings, not raw audio) still need strong protection: encryption at rest and in transit, plus access controls that restrict who can query or export them. (3) Customers must be able to withdraw consent and request deletion, which means you need a deletion workflow that actually propagates across every storage layer, including backups. (4) If a third-party vendor processes voiceprints, the relationship needs a data processing agreement aligned to the jurisdictions you operate in.
Teams often stumble on one specific distinction: call recordings versus voiceprint embeddings. Many contact centers already keep raw call audio for QA. Embeddings are a separate category of data with their own governance requirements. If your data inventory treats them as the same thing, auditors will treat that as a gap, not a nuance.
Attack Vectors: What Sophisticated Fraud Actually Looks Like
The threat from AI-generated audio is a significant concern for security teams. As voice cloning tools become more accessible, the risk of synthetic voices being used to bypass authentication systems increases. Deepfake audio detection is an active field, with ongoing work to identify the subtle artifacts that distinguish synthetic from human speech.
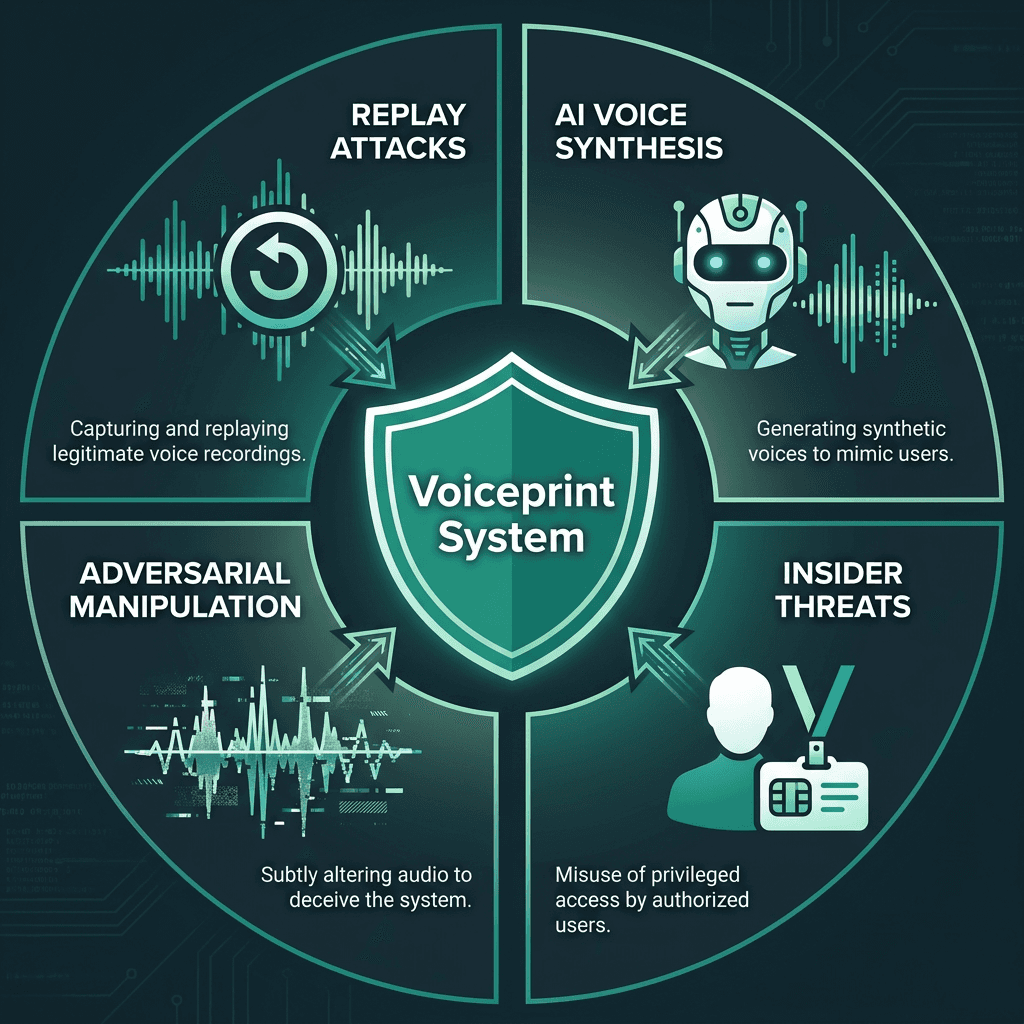
The primary attack categories a contact center voice authentication system needs to defend against:
Replay attacks: A fraudster records a legitimate customer's voice (from a phone call, social media, or a public video) and plays it back to the authentication system. Liveness detection, which checks for spontaneous speech characteristics, is the primary countermeasure.
Voice synthesis attacks: AI text-to-speech systems can now clone a voice from a short audio sample. The countermeasure is deepfake detection models trained to identify synthesis artifacts, though this is an ongoing arms race.
Adversarial audio manipulation: Attackers can use AI to modify synthetic audio to remove detectable artifacts, making it appear more like genuine speech to detection systems. Some techniques involve re-recording synthetic audio, which can make it harder for detection models to identify.
Social engineering combined with partial biometric match: A fraudster who has some personal information about the target may attempt multiple calls to incrementally build a passing voiceprint score, particularly against passive systems with lower per-call thresholds.
Insider threats: An agent or administrator with access to the voiceprint database or the ability to override authentication results represents a non-technical but significant risk vector.
As government bodies like NIST note in their work on digital identity guidelines, such as SP 800-63B, the expanding use of voice interfaces increases the incentive for attackers to find ways to compromise them.
Four primary attack categories that a contact center voice authentication deployment must account for
Where Speech AI Infrastructure Meets Security Architecture
Voice authentication lives inside a broader call flow: telephony, IVR or conversational AI, CRM lookups, and the logic that decides when to hand off to an agent. That plumbing isn’t neutral. The way you build the speech layer shows up directly in reliability, match accuracy, and overall security posture.
Latency is where this becomes painfully concrete. If your speech-to-text layer adds delay, the voiceprint extraction pipeline often runs on buffered audio that may have been resampled along the way. Each codec conversion is an opportunity to lose signal quality; moving from a higher-bandwidth codec like G.711 to a compressed one like G.729, for instance, can affect matching accuracy by altering the audio data the system relies on. Contact centers running AI voice agents need low-latency, high-fidelity audio handling if they want voice authentication to hold up under real call conditions.
The adoption of voice biometrics is growing, driven by its application in zero-trust security architectures. Zero-trust assumes every interaction is untrusted until proven otherwise, and it favors ongoing verification over a single check at the start. In a contact center, that means the opening voiceprint match should be one signal in a stream of signals, not a one-time badge that grants the rest of the session a free pass.
If you’re building contact center automation, decide early where authentication signals land downstream. A handoff caused by a failed biometric check should not look like a handoff caused by a customer request. When authentication is modeled as a one-and-done event, gaps appear: logic branches that never see risk state, agents who never get context, and workflows that attackers can probe repeatedly.
Operational Reality: Handle Time, Enrollment Rates, and What the Numbers Mean
Voice biometrics can reduce average handle time, a key metric for contact center efficiency. By automating a portion of the identity verification process, agents can resolve issues more quickly. At contact-center scale, even small time savings per call add up to significant operational gains. That kind of math tends to accelerate timelines, sometimes faster than the underlying risk work is ready to support.
Enrollment rate is the metric that quietly decides whether any of this matters. If only 20% of customers enroll, you don’t get broad fraud reduction, and 80% of calls see none of the handle-time upside. Enrollment is shaped by how clearly you explain the benefit, how much friction you introduce, and how much customers trust your handling of biometric data. Teams that communicate plainly about their privacy policy and data practices typically see stronger enrollment than teams that treat disclosure as a legal formality.

Handle time savings and enrollment funnel are the two operational metrics that determine real-world ROI
Implementation Checklist: From Pilot to Production
Pilots that stall out rarely fail because the model can’t match voices. They fail because the integration surface area was misread. Before you sign a vendor contract, you want crisp answers to the questions below.
Pre-deployment requirements to validate before going to production:
Audio path audit: Map every codec conversion and compression step between the customer's phone and your voiceprint engine. Identify where audio quality degrades and whether it falls below the minimum sample quality your vendor specifies.
Consent workflow design: Define exactly when and how enrollment consent is captured, stored, and linked to the customer record. This must be auditable.
Deletion workflow: Build and test the voiceprint deletion process before enrollment begins, not after. Confirm it propagates to all storage layers.
Fallback authentication: Define the alternative verification path for callers who have not enrolled, whose voiceprint match falls below threshold, or whose enrollment is flagged as potentially compromised.
Fraud escalation logic: Determine what score threshold triggers a fraud alert, what happens next (agent review, call termination, silent flagging), and who owns that decision.
Vendor data processing agreement: Confirm the agreement is in place and covers the specific regulatory jurisdictions where your customers are located.
Liveness detection coverage: Confirm your vendor's liveness detection is tested against current synthesis models, not just replay attacks.
If you’re implementing this alongside conversational AI, the customer service voice bots integration guide lays out the surrounding architecture: IVR handoffs, agent routing, and session context management, and how authentication state should travel through those layers.
The Expert-Level Consideration Most Guides Skip
Voiceprints don’t stay still. Voices shift with age, illness, stress, background noise, and the device a person calls from. A template captured three years ago on a landline can struggle when today’s call arrives over a compressed mobile codec in a loud environment. Production systems need adaptive enrollment: refresh the template using recent, high-confidence matches instead of treating the original enrollment sample as permanent truth.
Then there’s the case where the account is already compromised somewhere else. If a fraudster changes the linked phone number or email through a web portal and calls in, matching the legitimate customer’s voiceprint doesn’t resolve the underlying account state. Voice authentication verifies a voice, not the integrity of the profile behind it. That’s why session context, including recent account changes, belongs in the risk score alongside the biometric result. Building secure and safety compliant voice agents demands this kind of layered reasoning across the full interaction lifecycle, not just the first ten seconds of a call.
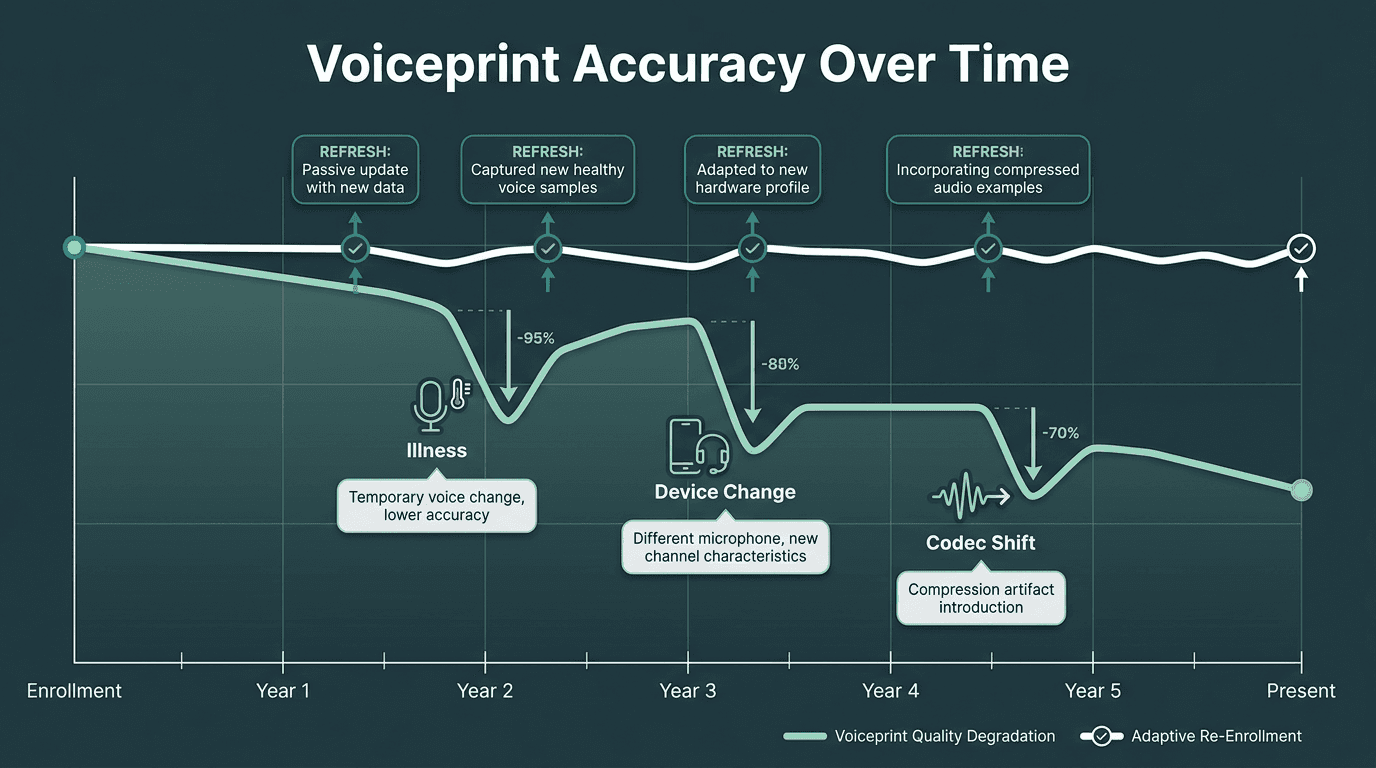
Voiceprints degrade over time; adaptive re-enrollment maintains accuracy across the customer lifecycle
Key Takeaways and Next Steps
Voice authentication is mature enough to deploy with confidence, and dynamic enough to demand ongoing attention. The underlying biometric techniques are well established. The threat environment, especially AI voice synthesis, is moving faster than many roadmaps admit. Meanwhile, jurisdictions that treat biometrics as sensitive data leave very little room for improvisation.
The teams that do this well tend to look similar: authentication is treated as one signal in a multi-layer security stack, enrollment UX gets the same seriousness as model selection, and consent and deletion workflows are built before the first voiceprint is collected.
If you’re building or scaling voice AI in the contact center, the speech layer under the biometric check matters as much as the biometric engine itself. Latency, codec handling, and audio fidelity show up directly in match performance. Smallest.ai's Atoms platform provides voice and text agent infrastructure for running authentication-aware conversational flows at production scale, with low-latency speech processing that voice biometrics depends on. If you’re mapping how voice authentication fits into a broader AI for the contact center strategy, start there.
How much audio does a voice authentication system need to create a reliable voiceprint?
Can voice authentication work with AI-generated voices used in contact center IVR systems?
What is the difference between voice authentication and voice identification in a fraud context?
Is consent required every time a customer calls after enrolling their voiceprint?
How should a contact center handle a caller whose voiceprint match score falls just below the acceptance threshold?

