Text to Speech for Ecommerce: Automated Order Updates, Returns & Delivery Notifications


Learn how to implement text to speech for ecommerce order updates, returns, and delivery notifications. Covers architecture, voice quality, multilingual support, and scaling.
Text to speech has become one of the most practical tools in the ecommerce communication stack. Its most valuable application is post-purchase communication: telling customers where their package is, what happened to their return, and when the driver is arriving. These are critical touchpoints that define brand loyalty.
If you are a developer looking to implement voice notifications that work at scale, reduce operational overhead, and improve the customer experience, this article is for you.
Why Voice Notifications Belong in Your Ecommerce Stack
An unread email or missed SMS creates friction. A phone call, even an automated one, carries urgency and accessibility that text channels cannot replicate for every customer segment. Elderly customers, visually impaired users, and people in hands-free situations like driving or cooking all benefit from audio-first notifications. This audience is larger than most product teams assume.
The numbers support the investment. The voice commerce market is projected to grow from $150.34 billion in 2025 to $194.03 billion in 2026 (The Business Research Company, 2026). Gartner forecasts that conversational AI will reduce contact center labor costs by $80 billion in 2026. When customers receive proactive voice updates about their orders, inbound "where is my order" (WISMO) calls drop significantly, which is a direct operational saving.
The Psychology of Voice: Urgency and Trust
A spoken message conveys tone, urgency, and empathy in a way plain text cannot. For high-value orders or time-sensitive deliveries, a voice notification provides reassurance that an SMS alert lacks. This matters most during exception handling. A calm, clear voice explaining next steps can de-escalate a frustrating situation, whereas a cryptic text message amplifies it.
Measuring the ROI of Voice Notifications
The business case rests on measurable KPIs. The most significant is the reduction in WISMO inquiries. Track call, email, and chat volumes related to order status before and after launching voice alerts to calculate direct savings in agent time. Proactive voice alerts that provide clear instructions resolve issues without agent interaction. Other key metrics include customer satisfaction scores on post-purchase surveys and the rate of successful first-attempt deliveries, which voice alerts improve by reminding customers of delivery windows.
The Technical Architecture for Text to Speech Order Notifications
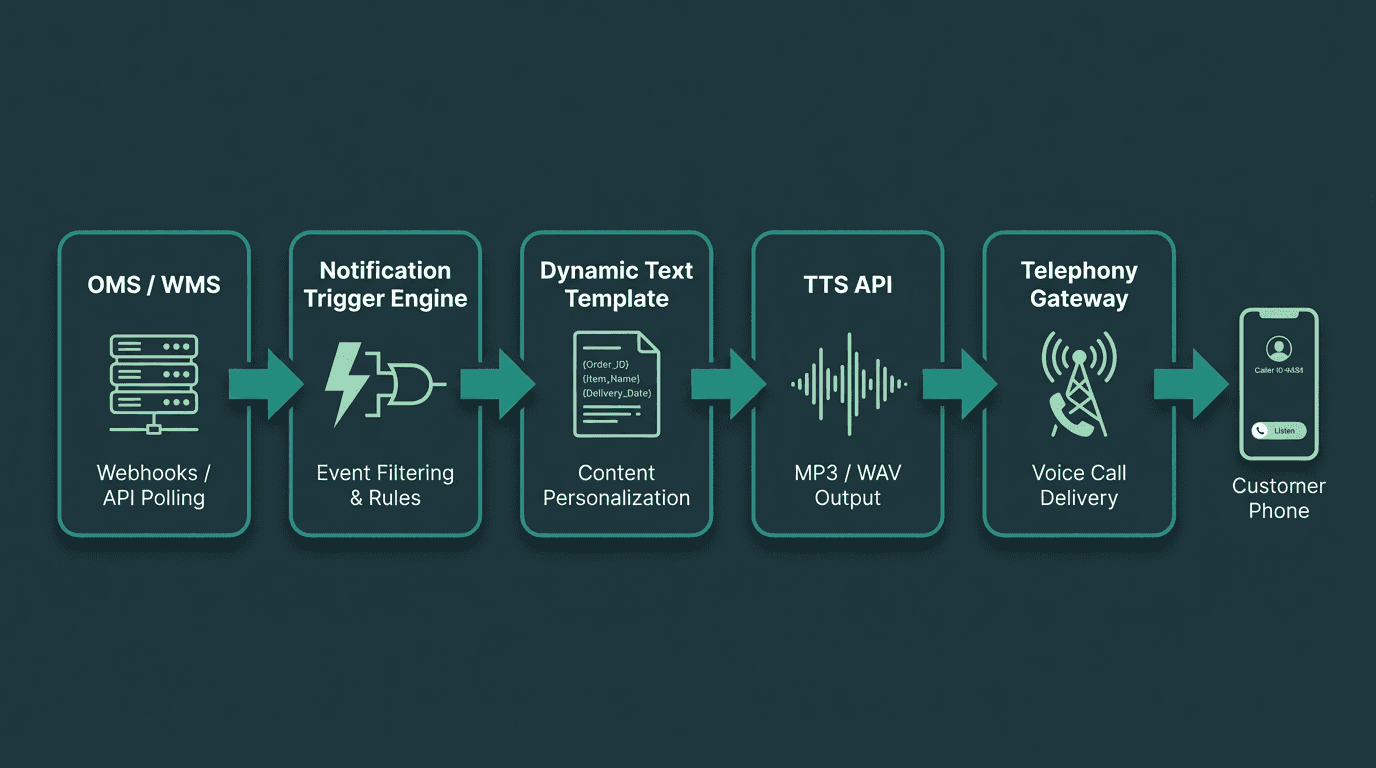
A clean TTS notification pipeline connects your OMS to the customer's phone in under a second.
The core pipeline has four components: your order management system (OMS) or warehouse management system (WMS), a notification trigger layer, a TTS API, and a telephony gateway. The trigger layer is where most business logic lives. It listens for state changes from the OMS, such as "order shipped", "out for delivery", "delivery failed", or "return received", then constructs a text string using dynamic variables pulled from the order record.
Component 1: The Data Source (OMS/WMS)
Your OMS or WMS is the source of truth. It contains customer name, phone number, order details, and real-time carrier status updates. Integration is typically achieved via webhooks or API polling. Webhooks are strongly preferred for real-time systems. They push data to your trigger layer the moment a status change occurs, minimizing latency between the event and the customer notification.
Component 2: The Notification Trigger Layer
This is the brain of the system. It ingests events from the OMS and decides if, when, and how to send a notification. Key responsibilities include: Event Filtering:* Not every status change warrants a notification. This layer filters out minor or internal updates that would overwhelm customers. Business Rule Application:* It enforces rules like "Do not send notifications between 10 PM and 8 AM local time" or "Only send a delivery failed alert after the second attempt." Template Selection and Population:* Based on the event type, it selects the appropriate message template and populates it with dynamic data such as customer first name, product name, and carrier tracking URL. Consent Management:* It checks the customer's profile for consent to receive automated calls, respecting opt-out preferences to comply with regulations like the TCPA in the US and PECR in the UK.
Component 3: The TTS API
Once the trigger layer constructs the final text string, it sends it to a TTS API, which converts the text into a natural-sounding audio file. When selecting a provider, focus on: Latency:* For real-time alerts like "your driver is arriving now," the time from API request to first audio byte should be under 300ms. Explore the fastest text-to-speech APIs to benchmark providers before committing. Voice Quality:* Listen to samples with complex content like addresses and tracking numbers, not just clean demo sentences. SSML Support:* The API should support Speech Synthesis Markup Language for fine-grained control over pronunciation, pacing, and emphasis. Scalability:* The provider must handle your peak notification volume without performance degradation, particularly during sale events.
Component 4: The Telephony Gateway
The telephony gateway places the call and plays the audio file generated by the TTS API. Providers like Twilio, Vonage, or Telnyx offer APIs for this purpose. Your system passes the customer's phone number and the URL of the generated audio file to the gateway. It also returns call status data, whether answered, busy, or failed, which your trigger layer should log for analytics and retries.
Template construction matters more than most developers expect. "Your order for two items has shipped" is far less useful than "Hi Sarah, your wireless headphones have shipped and will arrive Thursday by 8 PM." The second version requires pulling SKU descriptions, customer names, and estimated delivery windows from your data layer, but it dramatically reduces follow-up contacts. Build that specificity in from the start, and keep templates version-controlled so non-technical team members can iterate on message content without engineering involvement.
For latency-sensitive scenarios like out-for-delivery alerts, you need a TTS API that synthesizes and returns audio in real time. Batch pre-generation is not viable when the delivery window is dynamic. The same infrastructure can also handle inbound delivery queries, as explored in how AI voice agents transform logistics communication.
Handling Returns and Exception Notifications Without Sounding Robotic
Returns are emotionally loaded interactions. A customer whose expensive item arrived damaged does not want to hear a flat, mechanical voice reading a case number. The quality of your speech synthesis and your control over its output are paramount here. The difference between a customer who feels handled and one who feels helped often comes down to pacing and emphasis, not just the words.
The best speech synthesis systems support prosody controls through SSML, allowing you to adjust speaking rate, pitch, and emphasis at the word or sentence level. A slightly slower pace on a return confirmation signals care. A clear, direct delivery on an exception message, with emphasis on the action step, reduces confusion. See how human-like AI voices handle emotional context to understand what is technically achievable today.
Using SSML for Tonal Control: A Practical Example
Consider a notification for a processed refund. Without SSML, the delivery is entirely flat. With SSML, you add meaningful nuance:
clearer. The break tag adds a slight pause for better comprehension. These adjustments make the automated message sound significantly more professional without requiring a different voice model or a human agent.
Notification types that benefit most from tonal differentiation:
Return label issued: Confirm the action and explain where to find the label. "I've just sent a return label to your email address on file."
Refund processed: State the amount and timeline clearly with a positive, brief tone.
Delivery exception or failed attempt: Be action-oriented. "The driver could not complete the delivery. A new attempt is scheduled for tomorrow."
Damaged item reported: Use an empathetic pace with explicit next steps. "We are very sorry to hear your item was damaged. A support agent will call you within the hour."
Return received at warehouse: Use a neutral, confirmatory tone. "We've received your return. Your refund will be processed within two business days."
Multilingual Support and Voice Consistency at Scale
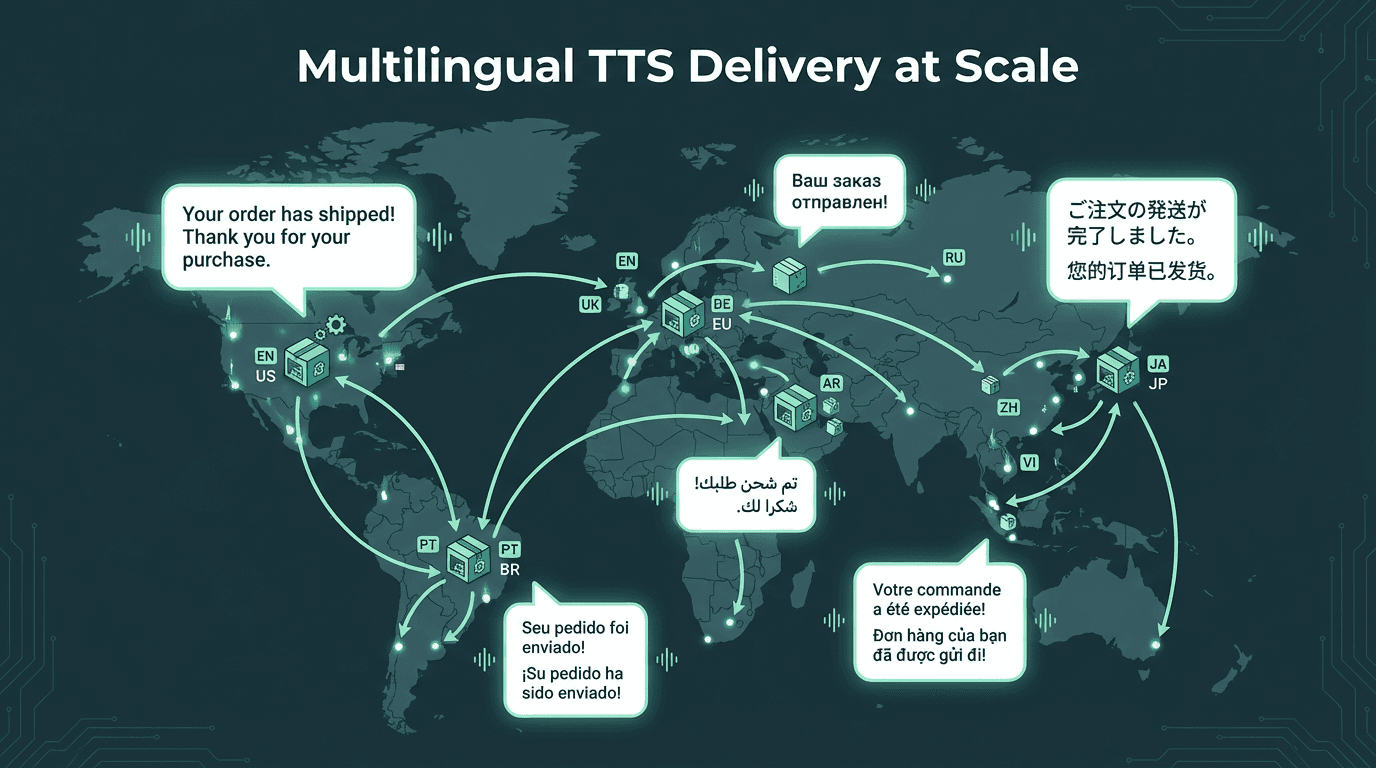
Global ecommerce operations require TTS systems that handle multiple languages without voice inconsistency.
If you operate across multiple markets, voice consistency becomes a real engineering concern. Customers who receive order updates in one voice on Monday and a noticeably different voice on Wednesday will notice, even if they cannot articulate why. Establish a voice persona for each locale and lock it to a specific model and voice ID in your TTS configuration. Document this as part of your brand guidelines, treated with the same rigor as your visual identity.
Language detection should happen at the customer profile level, not at the notification trigger level. Pull the customer's preferred language from your CRM or account settings before constructing the template string. This is far more reliable than inferring language from shipping destination. Some TTS providers handle code-switching poorly, so test these cases explicitly before going live, especially in markets like Canada (English/French) or Singapore (English/Mandarin/Malay).
Localization vs. Translation
Effective multilingual support goes beyond translation. Localization means adapting notification templates to cultural norms and linguistic nuances. Dates, times, and currency are formatted and spoken differently across countries, and a good TTS system handles these conventions correctly when given the appropriate locale information. Dialects matter too. A TTS voice trained on Castilian Spanish may sound unnatural to customers in Mexico or Argentina. Choose a provider that offers regional accents matching your customer base, and test each locale with native speakers before launch.
Advanced Considerations for Production Deployments
Three issues consistently surface at scale. First, audio caching: for high-frequency, low-variability messages like "your order has shipped," pre-generating and caching audio files reduces API costs and latency. For dynamic messages containing names and tracking numbers, real-time synthesis is unavoidable. A routing layer should decide which path each message takes based on its variability. Second, fallback handling: if your TTS API returns an error or times out, the pipeline must not fail silently. It should automatically fall back to SMS so the customer always receives the notification. Third, branded voice: several providers, including Smallest.ai, offer custom voice cloning. For high-volume retailers, a branded voice creates a recognizable auditory experience that a generic model cannot replicate.
Cost modeling deserves attention before you scale. Speech generation APIs typically charge per character or per second of audio. A 200-character order update sent to 500,000 customers daily adds up quickly. Analyze your expected message volume and length to project costs accurately. Review text-to-speech API pricing models carefully and negotiate volume tiers with your provider before hitting production traffic. The investment is typically offset by operational savings from reduced call center volume, but only if you have modeled the numbers in advance.
Security and Handling Personally Identifiable Information
Your notification strings will contain personally identifiable information such as customer names and addresses. Ensure your TTS provider has strong data security and privacy policies, and review their data retention policies for both the text you send and the audio they generate. Choose providers compliant with GDPR and CCPA, use secure authenticated API endpoints, and encrypt data in transit. Treating PII handling as a first-class concern from the start is far less costly than retrofitting security controls later.
A/B Testing and Continuous Optimization
Do not treat your notification scripts as static assets. Run A/B tests on different message phrasings, voices, or send times. Does "Your package will arrive today" perform better than "Your package is out for delivery"? Track customer engagement, call-back rates, and delivery success rates for each variant. Even small improvements in message clarity can translate into meaningful reductions in support contacts at scale.
Key Takeaways and Next Steps
The global TTS market was valued at $4.92 billion in 2025 and is projected to reach $11.49 billion by 2030 at an 18.5% CAGR (The Business Research Company, 2026). Ecommerce is one of the primary drivers of that growth. Customers want to know where their order is, and voice synthesis reaches them faster and more accessibly than most other channels. The teams that get this right treat speech generation as a first-class part of their notification infrastructure, not something bolted on after the fact. Smallest.ai is built for exactly this use case, offering sub-100ms text to speech latency, multilingual voice models, SSML support, and custom voice cloning for brands that want a consistent, recognizable audio identity across every order update, return, and delivery notification they send.
Where to focus next:
Audit your current notification touchpoints. Identify which events have the highest correlation with inbound WISMO calls. These are your prime candidates for an initial voice notification rollout.
Select a TTS provider. Focus on vendors with sub-300ms latency, high-quality voices, strong SSML support, and multilingual capabilities matching your customer geography.
Build dynamic templates. Start with your top five most frequent notification types. Script them for clarity and brevity, and have them reviewed by your support team.
Instrument your pipeline for measurement. Before going live, ensure you can track the deflection rate: how many inbound calls, emails, and chats drop after voice notifications are activated.
What is the minimum latency I should expect from a production TTS API for real-time delivery notifications?
Can I use the same TTS voice across order updates, returns, and marketing calls without confusing customers?
How do I handle customers who do not want voice notifications?
What happens when the TTS API is unavailable during a high-traffic period like a sale event?
How do I evaluate whether a TTS provider is suitable for ecommerce notifications specifically?

