Streaming Speech-to-Text in Production: Handling Dropouts, Reconnects, and Duplicates


A practical guide to streaming speech-to-text reliability, covering dropouts, reconnect logic, duplicate segments, and transcript scoring.
Streaming speech to text is one of those technologies that looks straightforward until you try to run it in production. The demo works. The latency feels snappy. Then you deploy it to real users over real networks, and suddenly you are dealing with dropped connections, partial transcripts arriving out of order, the same words appearing twice, and no clear way to know whether the output you are getting is actually trustworthy.
This guide is written for developers and ML engineers who are past the 'hello world' stage and need to understand what actually goes wrong in a live streaming transcription system. By the end, you will know how to diagnose and handle dropout events, implement reconnect logic that does not corrupt your transcript, eliminate duplicate segments, and apply scoring methods that tell you whether a given output is worth acting on.
The global speech and voice recognition market was valued at $19.09 billion in 2025 and is projected to reach $23.70 billion in 2026 (Fortune Business Insights, 2026), which means the pressure to get this right is only growing.
How streaming transcription actually works
Before fixing problems, you need an accurate mental model of what is happening under the hood.
Streaming transcription is not a single request and response. It is a continuous bidirectional channel where audio chunks are sent to a recognition engine and partial or final transcript segments are returned asynchronously. Many production streaming systems surface partial results within a few hundred milliseconds under normal network conditions, though exact latency varies by provider, model, network quality, and audio chunking strategy.
Most production implementations use WebSocket connections because they maintain a persistent channel without the overhead of repeated HTTP handshakes. The audio is typically encoded as PCM or Opus and sent in frames of 20 to 100 milliseconds. The recognition engine maintains an internal acoustic context window, which is why a sudden dropout does not just lose a word. It can corrupt the context for the next several seconds of audio after reconnection.
The engine returns two types of results: interim results (flagged as unstable, subject to revision) and final results (committed, not revised). The distinction matters enormously for downstream logic. If you are feeding transcripts into a real-time display or a voice agent, treating interim results as final will produce a flickering, unreliable experience. If you are storing transcripts for compliance or search indexing, you should only ever persist final results.
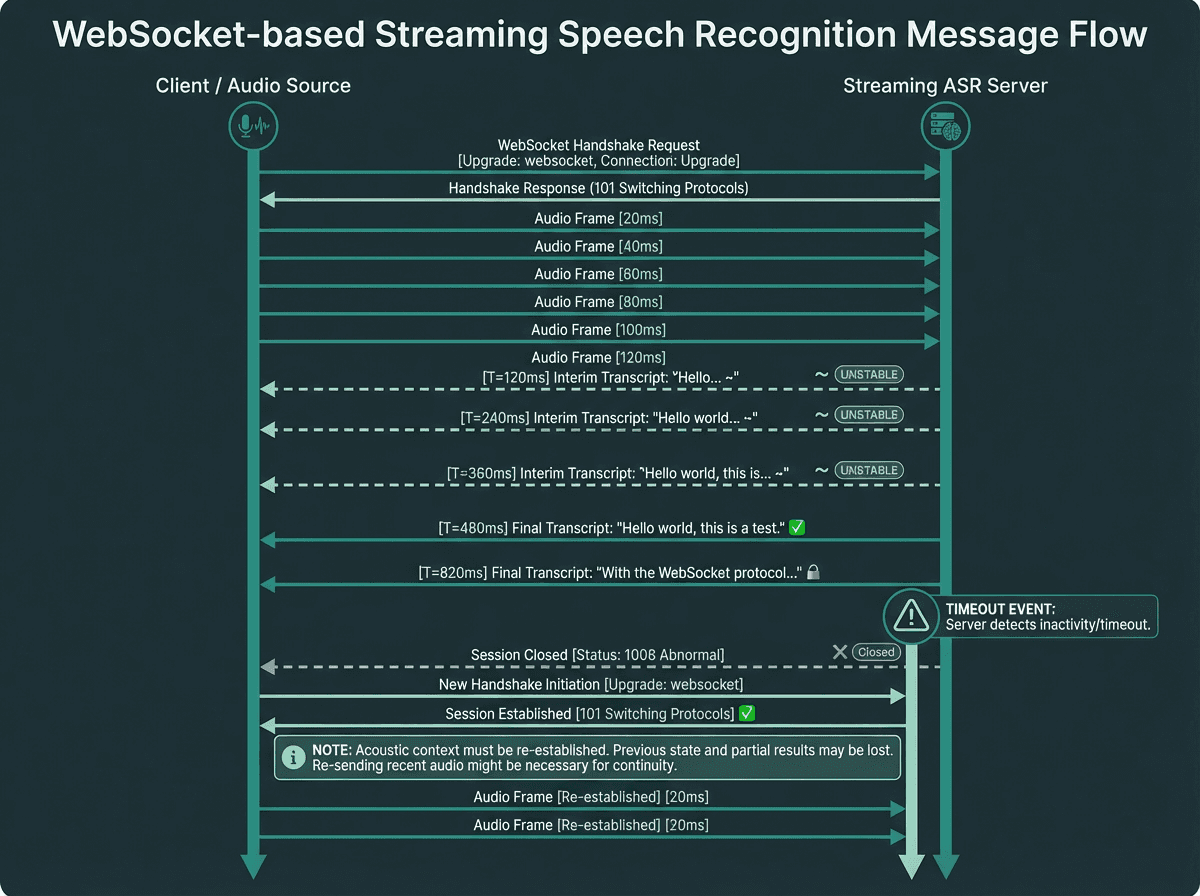
Interim results are unstable estimates; final results are committed. Reconnect logic must re-establish acoustic context, not just the connection.
Diagnosing and handling dropout events
A dropout is any event that interrupts the continuous flow of audio to the recognition engine. The causes split into two categories: network-side and client-side. Network-side dropouts include WebSocket disconnections, packet loss above the codec's concealment threshold, and server-side timeouts from inactivity. Client-side dropouts include microphone permission revocations, device switching (a user plugging in headphones mid-call), and application backgrounding on mobile.
The most important thing to instrument is the gap duration. A gap under 500 milliseconds is often recoverable with audio buffering and the engine may not even register it as a break. A gap between 500 milliseconds and 2 seconds will likely corrupt the acoustic context window and produce garbled output for the first sentence after reconnection. A gap over 2 seconds should be treated as a session termination, not a pause.
Practical dropout handling checklist:
Instrument all WebSocket close events with the close code and reason string. Code 1006 (abnormal closure) is the most common in unstable network conditions.
Maintain a client-side audio ring buffer of at least 2 seconds so you can replay missed audio after reconnection.
Track gap start and end timestamps. Log these alongside transcript segments so you can identify which outputs were produced after a context break.
Emit a dropout event to your application layer immediately, do not wait for reconnection to succeed. This lets UI components show a 'connection interrupted' state rather than silently degrading.
For gaps over 2 seconds, discard the acoustic context entirely and start a new session. Attempting to continue in the same session produces worse output than a clean restart.
Explore how Smallest.ai handles streaming reliability at the API level
Reconnect logic that does not corrupt your transcript
Most developers implement reconnect logic as a simple exponential backoff loop: wait, reconnect, resume sending audio. This works for maintaining a connection but it creates a subtler problem. When you reconnect and resume, you have two sessions with overlapping or adjacent audio. Without explicit session boundary tracking, your transcript assembly logic will not know where one session ends and the next begins.
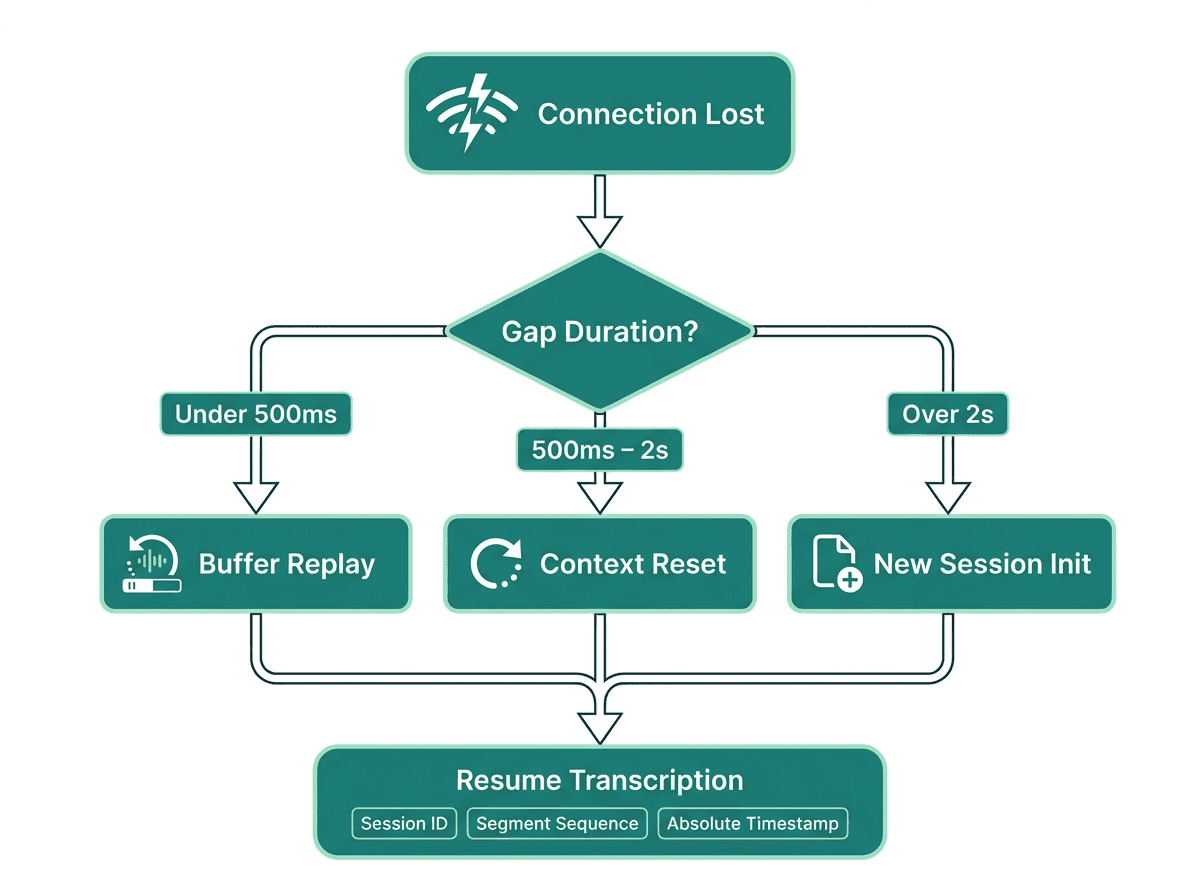
Gap duration determines whether to replay buffered audio, reset context, or start a fresh session entirely.
The fix is session metadata. Every transcript segment should carry a session ID, a segment sequence number within that session, and an absolute timestamp. When you assemble the final transcript, you sort by absolute timestamp, not by arrival order. This is critical because network jitter can cause segments from a reconnected session to arrive before the last segments of the previous session.
One thing most guides skip: you should also track the 'last committed word' before a dropout. When you reconnect and the engine starts returning results, compare the first few words of the new session against the last confirmed words of the previous session. If there is overlap, you have a duplicate segment. If there is a gap in the spoken content, you have a dropout artifact that should be marked in your transcript rather than silently omitted.
Eliminating duplicate segments
Duplicates in streaming transcription come from two distinct sources, and they require different solutions. The first source is interim-to-final promotion: the engine emits an interim result containing 'the meeting will start', then emits a final result containing 'the meeting will start at three'. If your display logic appends both, the user sees the phrase twice. The fix is straightforward: maintain a pointer to the last committed final result position and only display text beyond that point from interim results.
The second source is reconnect overlap. When you replay buffered audio after a dropout, the engine will re-transcribe audio it already processed. This produces semantically identical segments with different timestamps and session IDs. A naive deduplication approach using exact string matching will fail on any variation introduced by the re-transcription (punctuation differences, capitalization). A more reliable approach uses a sliding window edit distance check: if two segments share more than 85% of their tokens and their timestamps overlap, treat them as duplicates and keep the one with the higher confidence score.
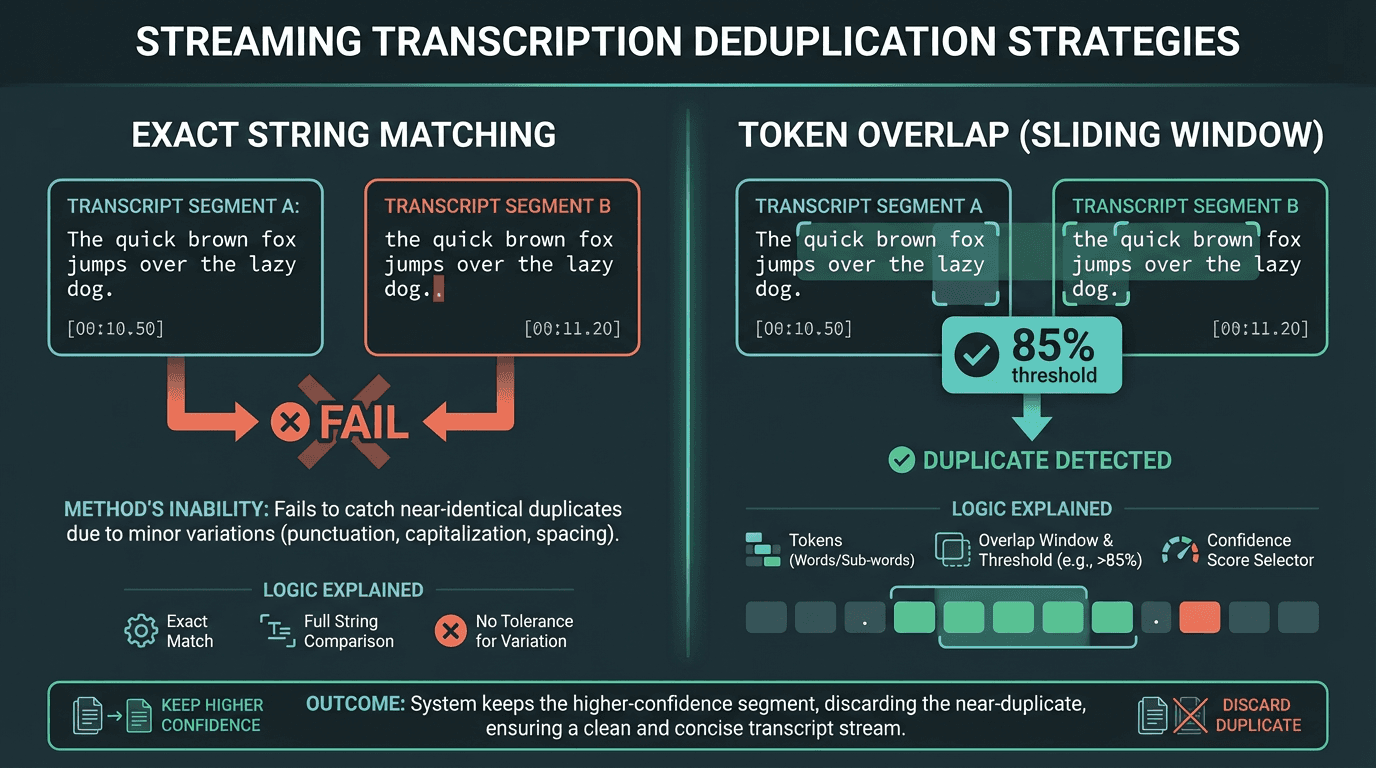
Token overlap deduplication handles the minor transcription variations that exact string matching misses after reconnect replays.
Scoring transcript output: what the numbers actually mean
The industry standard for measuring transcription accuracy is Word Error Rate (WER), which calculates the percentage of words incorrectly transcribed through substitutions, insertions, or deletions. WER is the standard accuracy metric in speech recognition evaluation, but what counts as acceptable depends heavily on the use case, audio quality, speaker variability, and domain vocabulary.
. In optimal conditions, modern systems can achieve high accuracy, but this drops significantly with background noise, strong accents, or domain-specific terminology.
WER is a post-hoc metric. You cannot compute it in real time without a reference transcript. For live scoring, most production systems rely on the per-word confidence scores that the recognition engine returns alongside each segment. These are probabilities between 0 and 1 assigned to each recognized word. A segment where all words score above 0.85 is generally reliable. A segment with multiple words below 0.6 should be flagged for review or held back from downstream systems.
The NIST Rich Transcription Evaluation program has been defining rigorous evaluation standards for speech recognition systems for decades, and their frameworks are worth studying if you are building a scoring layer for a compliance or legal application. For most product use cases, a simpler approach works: compute a segment-level quality score as the mean word confidence, apply a threshold (typically 0.75 for display, 0.85 for storage), and route low-confidence segments to a human review queue rather than discarding them.
See how Smallest.ai scores and surfaces confidence data through its speech-to-text API
Advanced considerations: acoustic context, language models, and edge cases
Skip this section if you are still working on basic dropout handling. Come back to it once your reconnect logic is solid.
Modern streaming recognition engines use a language model layer on top of the acoustic model. This means the engine is not just pattern-matching sounds to phonemes. It is also predicting likely word sequences based on prior context. This has a non-obvious implication for dropout recovery: even if your audio replay is acoustically perfect, a new session starts with no language model context. The engine will be more likely to mishear domain-specific terms in the first few seconds after reconnection because it has not yet built up context about the conversation topic.
One mitigation is to pass a custom vocabulary or context hint to the new session at initialization. If you know the conversation is about a specific domain (medical, legal, financial), priming the session with relevant terminology significantly improves accuracy in the post-reconnect window. The Mozilla Common Voice project has produced extensive research on how diverse training data affects recognition accuracy across accents and domains, and the underlying academic paper is worth reading if you are evaluating how well a given engine handles your specific user population.
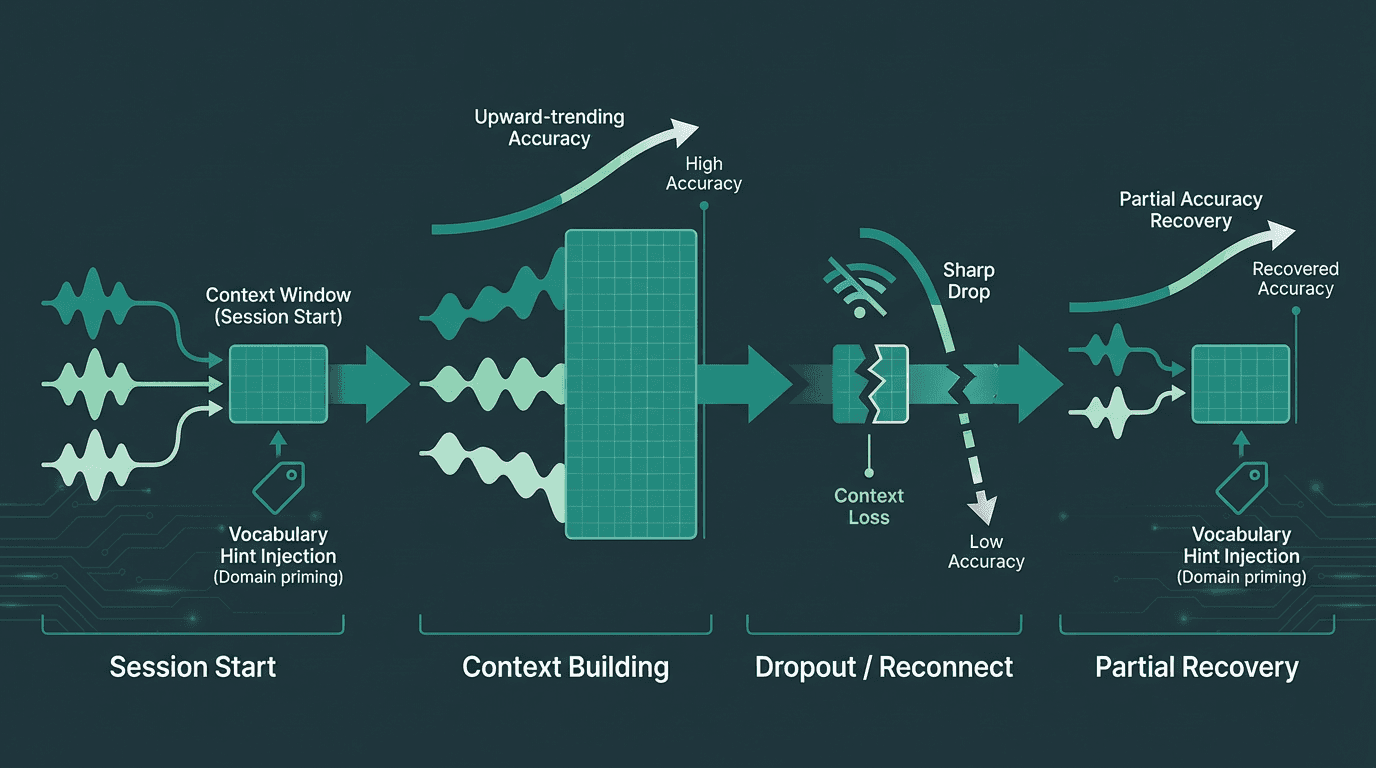
Language model context builds over a session. Reconnects reset it, making vocabulary hints at session start a meaningful accuracy recovery tool.
Another edge case worth handling explicitly: overlapping speakers during a reconnect window. If two speakers are talking when a dropout occurs and you replay buffered audio, the diarization labels from the pre-dropout session will not carry over. The engine will re-assign speaker labels from scratch, potentially reversing Speaker A and Speaker B for the remainder of the session. If speaker identity matters for your application, store the last confirmed diarization state and validate it against the first few speaker-attributed segments after reconnection.
Key takeaways and next steps
Reliable streaming transcription in production is an engineering discipline, not just an API call. The core principles: treat every dropout as a potential context break, instrument gap durations to decide between buffer replay and session restart, use session metadata and absolute timestamps for transcript assembly, apply token overlap deduplication for reconnect artifacts, and score output at the segment level using per-word confidence before routing to downstream systems.
Quick reference checklist before going to production:
WebSocket close event instrumentation with code and reason logging
Client-side audio ring buffer of at least 2 seconds
Session ID and sequence number on every transcript segment
Absolute timestamp sorting for transcript assembly
Token overlap deduplication with an 85% threshold
Per-word confidence scoring with routing logic for low-confidence segments
Vocabulary hint injection at session initialization for domain-specific use cases
Diarization state persistence across reconnect boundaries if speaker identity matters
For a broader view of how different providers approach these problems, the guide to speech-to-text transcription software covers the current landscape in detail. And if you are at the stage of evaluating speech-to-text accuracy across providers, the scoring framework in this guide gives you a concrete basis for comparison beyond marketing benchmarks.

Eight checkpoints that separate a demo-quality streaming transcription integration from a production-grade one.
The problems described throughout this guide, dropouts corrupting acoustic context, reconnect logic producing duplicate segments, confidence scores with no clear routing logic, all share a common root: they are infrastructure problems that the recognition API alone cannot solve. The application layer has to be built to handle them deliberately. Most teams discover this only after a production incident, which is an expensive way to learn.
Smallest.ai is built for exactly this kind of production environment, returning first partial results in under 300ms and per-word confidence scores on every segment. The streaming speech-to-text engine supports session context hints for domain-specific vocabulary and is designed for the kind of developer who has already read this far and knows what questions to ask. If you are building a voice agent, a live captioning system, or a real-time analytics pipeline and you need transcription that holds up when the network does not, that is the place to start. You can also browse our blog for more technical guides on building reliable voice AI systems.
Start building with Smallest.ai's streaming speech-to-text engine
What is the difference between an interim result and a final result in streaming speech to text?
How long of a dropout gap requires a full session restart?
What is Word Error Rate and how do I use it to evaluate my streaming transcription quality?
Why do I get duplicate words or phrases after a reconnect?
How does background noise affect streaming transcription accuracy and scoring?

