

Compare latency and accuracy in voice recognition to evaluate ASR performance, improve user experience, and choose the right speech-to-text solution.
If you’re building a product with voice, you’re navigating a three-way tradeoff between accuracy, latency, and cost. Get it right, and you create a fluid user experience. Get it wrong, and you ship a frustrating, expensive, or unusable feature. This guide is for developers, product managers, and founders who need to make informed decisions about implementing automatic speech recognition (ASR). We’re not going to talk about ‘revolutionary’ tech. We’re going to talk about the numbers, the constraints, and the hard-won lessons from shipping real systems.
By the end, you’ll understand how to evaluate automatic speech recognition software, benchmark performance realistically, and choose a solution that fits your product’s specific needs and budget. This isn't just theory; it's a practical map for building with voice in 2026.
Understanding the Core Metrics: Accuracy, Latency, and Cost
Before comparing providers or models, we need a shared vocabulary. These three metrics are in constant tension. Improving one often degrades another. Your job is to find the right balance for your specific use case.
Accuracy: Measured by Word Error Rate (WER), this is the percentage of words the ASR system gets wrong. A lower WER is better. It’s calculated as (Substitutions + Deletions + Insertions) / Total Words. A 5% WER means the system misinterprets 1 in 20 words. Lab benchmarks often boast sub-5% WER, but real-world performance is what matters. For example, a study on noisy audio found that WER can increase by 20-30 percentage points when moving from a clean test set to a challenging real-world environment (Ko et al. 2025) due to noise, accents, and domain-specific jargon.
Latency: This is the delay between when a sound is spoken and when its transcription is returned. For real-time applications like live captioning or voice commands, anything over 300 milliseconds is noticeable and disruptive. For batch transcription of audio files, latency is less critical than overall throughput.
Cost: Typically billed per minute or per hour of audio processed. Pricing models vary, with providers like Google Cloud Speech-to-Text offering different tiers based on model complexity and features. Hidden costs can include data storage, egress fees, and the engineering time spent integrating and maintaining the API.
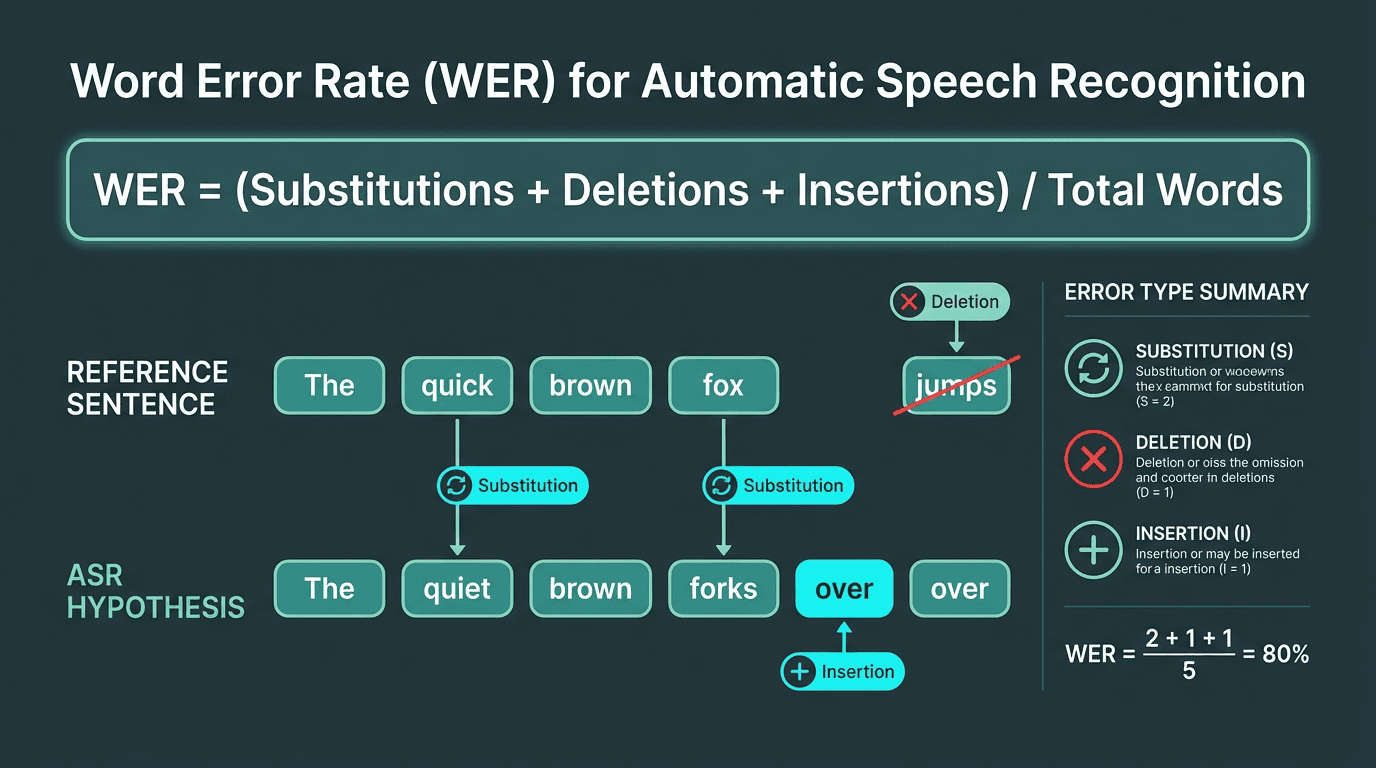
WER is the industry standard for ASR accuracy, but it doesn't capture the full user experience.
The Real-World Accuracy Problem: Why Benchmarks Lie
We learned this the hard way. Early in our development, we were obsessed with public benchmarks. We’d celebrate a 0.5% WER improvement on a clean dataset like LibriSpeech. Then we deployed the model to production and watched it fail spectacularly on real customer audio. The problem is that benchmarks are sterile environments.
Here’s a breakdown of what kills accuracy in the wild:
What most people get wrong about ASR accuracy:
Noise: Background chatter, car engines, and microphone static are not present in most academic datasets. A model trained only on clean audio will struggle to separate signal from noise.
Accents & Dialects: A model trained predominantly on American English will have a higher WER for speakers with Scottish, Indian, or Australian accents. This isn't just a technical problem; it's a product inclusion problem.
Domain Mismatch: If you're building a medical dictation tool, a generic ASR model will transcribe ‘myocardial infarction’ as ‘my oh card eel in fashion’. You need models fine-tuned on domain-specific terminology.
Audio Quality: Low-bitrate audio from a VoIP call (8kHz) contains far less information than high-fidelity studio audio (48kHz). The model can only be as good as the data it receives.
The only way to know true accuracy is to test with your own data. Record audio from your actual users in their real environments. Create a test set of a few hundred samples, manually transcribe them to create a ‘ground truth’ reference, and then measure the WER of any potential ASR provider against that set. This is non-negotiable.
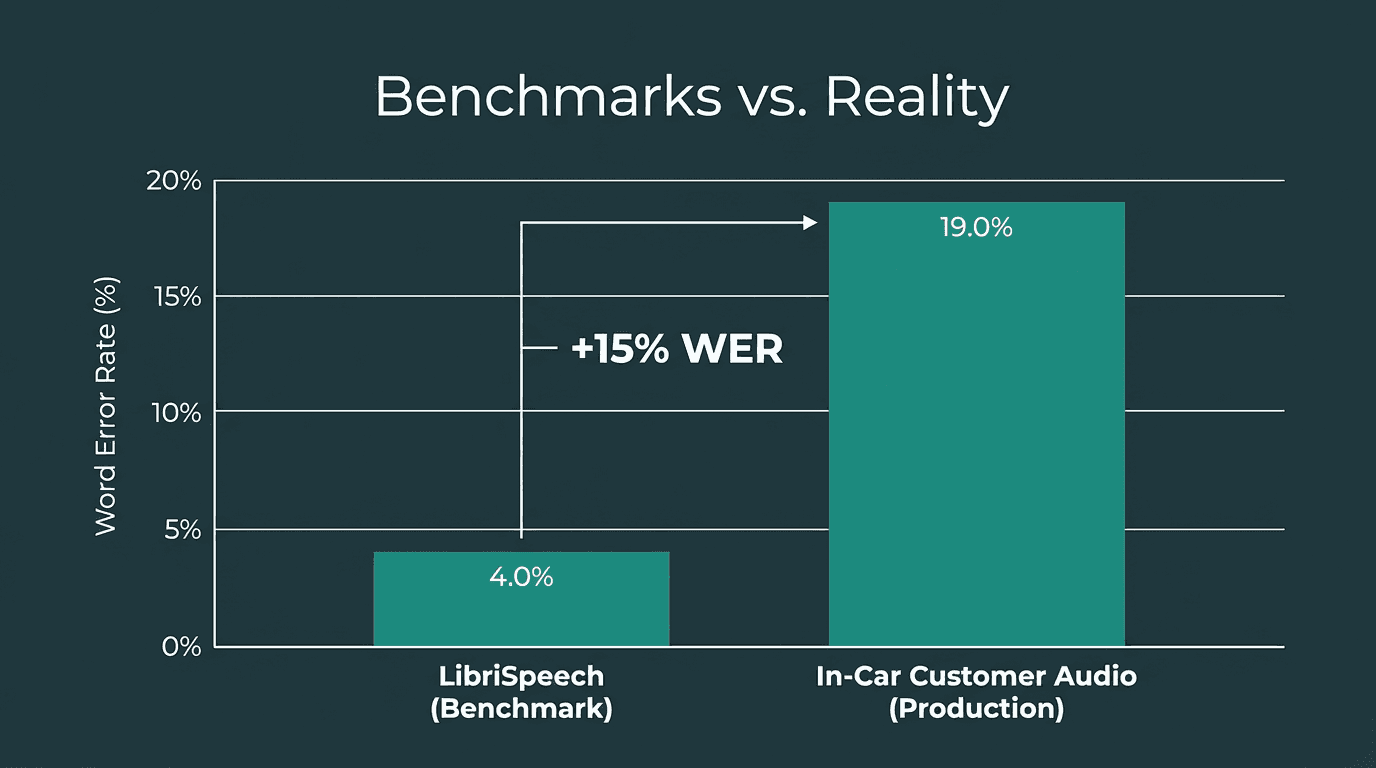
Production audio consistently degrades ASR performance compared to clean academic benchmarks.
Choosing Your Latency Budget: Real-time vs. Batch
Your application dictates your latency requirements. This choice has significant architectural and cost implications. There is no single ‘best’ latency; there is only the right latency for the job.
Use Case 1: Real-Time Transcription (Low Latency is Critical)
Think voice assistants, live meeting captions, or drive-thru ordering systems. Here, the user is waiting for a response. As mentioned, perceived latency for human interaction starts to degrade above 200-300ms. To achieve this, you need a streaming ASR API. These APIs process audio in small chunks as it arrives, returning partial transcripts almost immediately and refining them as more context becomes available. This is technically complex and often more expensive, but essential for conversational interfaces. For example, a streaming API might cost $0.016 per minute, while the same provider's batch service is only $0.008 per minute.
Use Case 2: Batch Processing (Throughput is Key)
Think transcribing voicemails, podcasts, or call center recordings for later analysis. Here, the user isn't waiting. A 30-second delay to transcribe a one-hour file is perfectly acceptable. For these jobs, you use batch or asynchronous APIs. You upload the entire audio file and get a notification when the transcript is ready. These services are optimized for high throughput and are generally much cheaper per hour of audio than their real-time counterparts. They can also use larger, more complex (and often more accurate) models because they don't have the same tight time constraints.
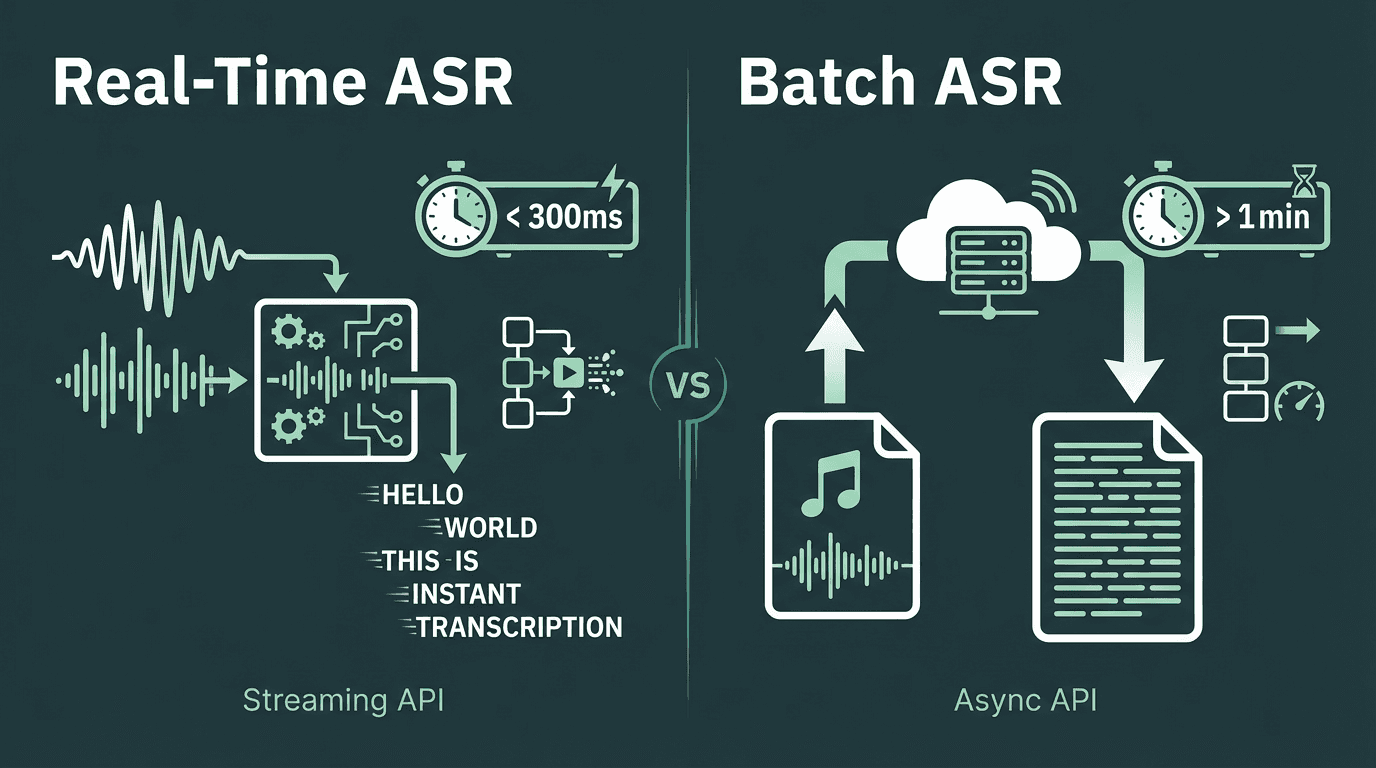
Your application's needs determine whether you optimize for low latency or high throughput.
Decoding the Cost: How to Model and Control ASR Expenses
ASR pricing can be opaque. The per-minute rate is just the beginning. To build a sustainable product, you need to understand the full cost structure.
Here’s what we learned about modeling costs:
Primary Cost Drivers:
Usage Volume: The most obvious factor. Most providers offer tiered pricing, where the per-minute rate decreases as your volume increases. Forecast your expected monthly audio hours carefully.
Model Tier: Basic models are cheaper. Advanced models with features like speaker diarization (who spoke when), automatic punctuation, and higher accuracy cost more.
Real-time vs. Batch: As discussed, streaming APIs are almost always more expensive than batch APIs due to the higher computational demands for low-latency processing.
On-Premise vs. Cloud: Running ASR models on your own infrastructure (on-premise or in your own cloud VPC) gives you more control over data privacy and can be cheaper at massive scale. However, it comes with a high upfront cost for hardware (e.g. $100,000+ in GPUs) and a significant operational burden for your engineering team. For most companies, a cloud API is the pragmatic choice.
ASR pricing becomes a problem when the headline per-minute rate is not the real rate you end up paying in production. Once streaming, diarization, timestamps, and scale-related usage are added, costs can become much harder to predict.
Smallest.ai has a pricing model that is easier to understand, easier to forecast, and easier to scale with. At about $0.005/minute for Pulse STT and $0.008/minute for Pulse Realtime, we keep our pricing transparent and predictable instead of pushing essential capabilities into add-ons later.
Putting It All Together: A Decision Framework
Choosing an ASR solution is about matching your product's requirements to the right point on the accuracy-latency-cost spectrum. There is no one-size-fits-all answer.
Ask yourself these questions:
What is my ‘good enough’ accuracy? For a voice search feature, a 10% WER might be fine. For medical transcription, you need under 2% WER. Benchmark with your own data to find this number.
What is the cost of a mistake? A wrong food order is an inconvenience. A wrong legal deposition is a lawsuit. The higher the cost of error, the more you should invest in accuracy.
Is my application interactive? If yes, you need a streaming API and must budget for its higher cost. If no, use a batch API and save money.
What is my scale? At 1,000 hours per month, a cloud API is a clear winner. At 1,000,000 hours per month, the economics of an on-premise solution might start to make sense, despite the operational overhead.
What is the difference between speech recognition and voice recognition?
How much data do I need to fine-tune an ASR model?
Can ASR handle multiple languages in the same audio?
What are the privacy implications of using a cloud ASR API?
What is speaker diarization?

