

Dive deep into Neural Text-to-Speech technology. Understand its architecture, voice cloning, and real-world impact. Get the full technical guide.
Neural TTS, short for neural text-to-speech, is the engine behind every voice assistant, audiobook narrator, and conversational AI that actually sounds human. Not the flat, robotic monotone of early synthesizers. Something fundamentally different: speech generated from scratch by deep neural networks that have learned the rhythm, tone, and texture of real human voices.
This article is written for developers, product builders, and anyone who wants to understand how voice AI works under the hood. You will come away knowing the mechanics of neural TTS, how it diverges from older approaches, what separates a good system from a great one, and where the technology is heading. If you are newer to the space, it helps to first understand what text-to-speech is and how it works before going deeper here.
What Neural TTS Actually Is
Speech synthesis has existed in some form since the 1950s, but for most of that history it was built on rules and recordings. Early systems stitched together pre-recorded audio fragments, a method called concatenative synthesis. The results were intelligible but unmistakably mechanical. You could always tell. According to Wikipedia's overview of speech synthesis, the field passed through several generations of parametric and formant-based methods before deep learning fundamentally changed what was possible.
Rather than assembling speech from clips, neural TTS trains deep neural networks on thousands of hours of recorded human speech, building an internal model of how language sounds, including prosody, emphasis, and natural pausing. The output is voice that is far more expressive than anything concatenative methods could produce. Neural and AI-powered voices now account for the majority of TTS market revenue, reflecting how completely the industry has shifted away from rule-based synthesis.
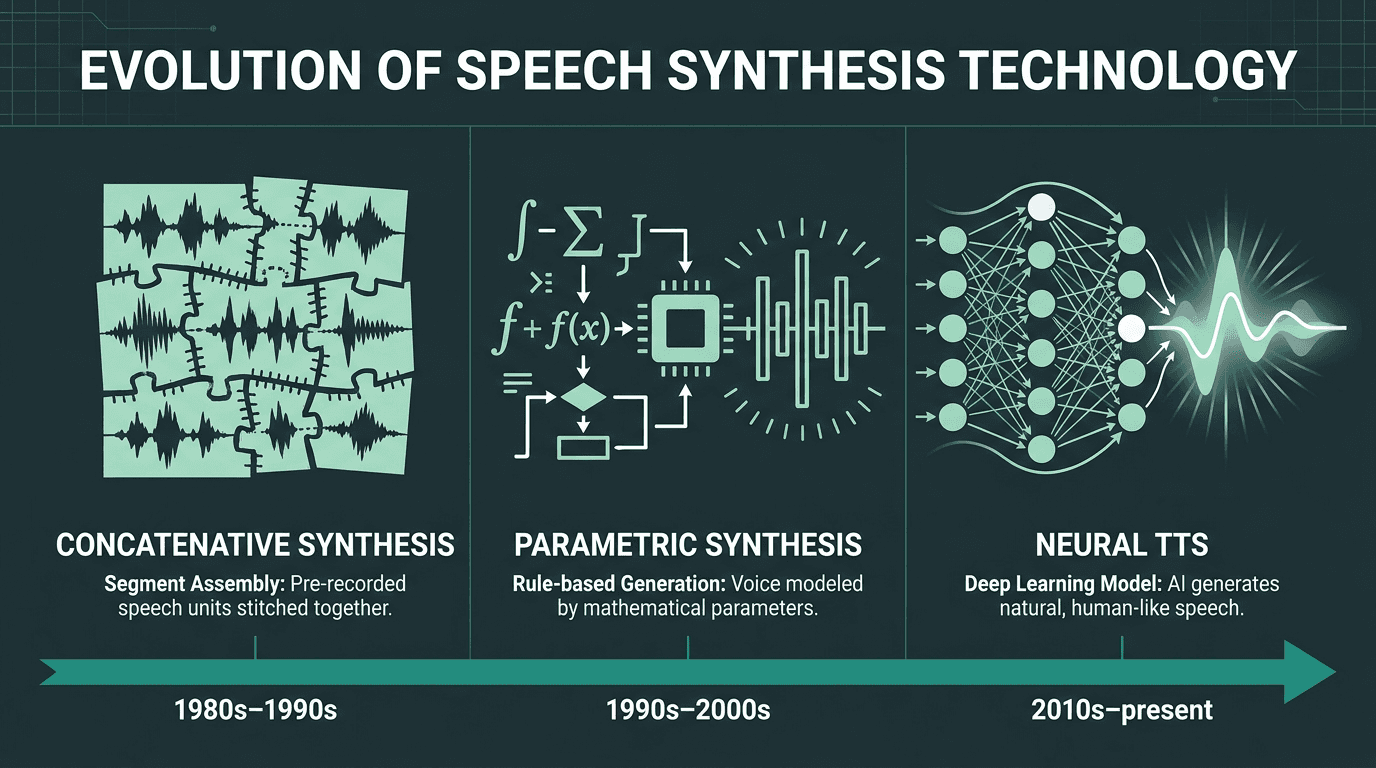
Three generations of speech synthesis technology, from rule-based concatenation to neural generation.
How a Neural TTS System Works: The Three-Stage Pipeline
Most people assume neural TTS is a single model that takes text in and spits audio out. In practice it is a pipeline with three distinct stages, each solving a different problem. Understanding this architecture matters because it explains why some systems are faster, more expressive, or more customizable than others.
Stage 1: Text Analysis. Before any audio is generated, the system has to understand what it is reading. Natural language processing handles abbreviations, numbers, punctuation, and context. "Dr." means "doctor" in one sentence and "drive" in another. The text analysis stage resolves these ambiguities and converts the input into a phoneme sequence, essentially a pronunciation map of the text.
Stage 2: Acoustic Modeling. The phoneme sequence feeds into an acoustic model, which predicts a spectrogram: a representation of how pitch, tone, and energy should vary over time. This is where prosody lives, and it is largely responsible for whether speech sounds natural or stilted. Models like Tacotron 2 and FastSpeech 2 operate at this stage, controlling the rhythm and melody of the output.
Stage 3: The Vocoder. A spectrogram is not audio. A vocoder converts it into an actual waveform. WaveNet, introduced in 2016, was the first model to generate raw audio waveforms directly using neural networks, producing speech realism that was unprecedented at the time. Modern vocoders like HiFi-GAN and WaveGlow have since made this process fast enough for real-time applications.
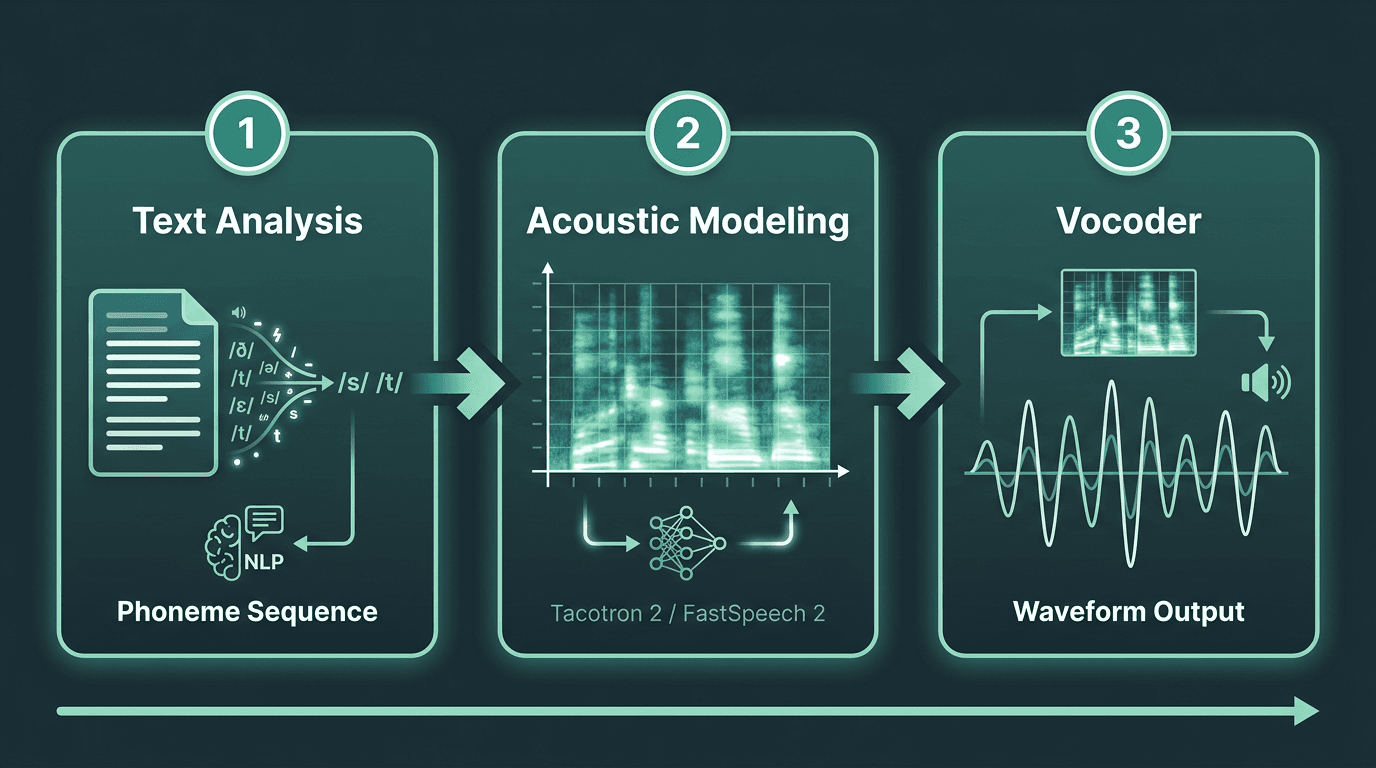
The three-stage neural TTS pipeline: text analysis, acoustic modeling, and waveform synthesis.
What Most People Get Wrong About Neural TTS Quality
"Neural TTS" is not a single quality tier. The gap between a well-trained, low-latency model and a poorly optimized one is enormous, and it surfaces in ways that directly affect real products.
Latency is the most underappreciated quality dimension. A system that produces beautiful audio in 800 milliseconds is unusable for a live phone call. For real-time voice applications, a target time-to-first-audio under 200 milliseconds is a common requirement, which demands architectural choices that go well beyond training a better acoustic model. Streaming synthesis, where audio is generated and played in chunks before the full sentence is processed, is now a core engineering requirement.
Expressiveness is the other separator. A neural TTS model trained on a narrow dataset will sound natural in neutral declarative sentences but fall apart on questions, exclamations, or emotional dialogue. The breadth and diversity of training data, combined with how the model is conditioned on speaking style, determines whether a voice can carry a conversation or just read a paragraph. These two dimensions, latency and expressiveness, are where production-grade systems earn their keep.
For a broader view of how these quality dimensions fit into the wider field, the speech technology landscape provides useful context on where neural TTS sits relative to other voice AI components.
Key Architectures That Shaped Modern Neural TTS
The academic survey "A Survey on Neural Speech Synthesis" (arXiv, 2021) is a comprehensive technical reference on how these architectures evolved. Even if you are not a researcher, a few landmarks are worth knowing.
Architectures that defined the modern era:
WaveNet (2016): An autoregressive model that generated audio sample by sample using dilated causal convolutions. Groundbreaking quality, but too slow for real-time use without significant engineering work.
Tacotron 2 (2017): A sequence-to-sequence model that combined a recurrent acoustic model with a WaveNet-style vocoder, setting the standard for end-to-end neural TTS pipelines.
FastSpeech 2: A non-autoregressive model that generates spectrograms in parallel rather than sequentially, dramatically improving inference speed while maintaining quality.
VITS (Variational Inference with adversarial learning for end-to-end TTS): Skips the spectrogram stage entirely, generating waveforms directly from text with strong naturalness scores.
Diffusion-based models: The newest generation, using iterative denoising to generate audio. Exceptional quality, but hitting real-time latency targets requires careful optimization.
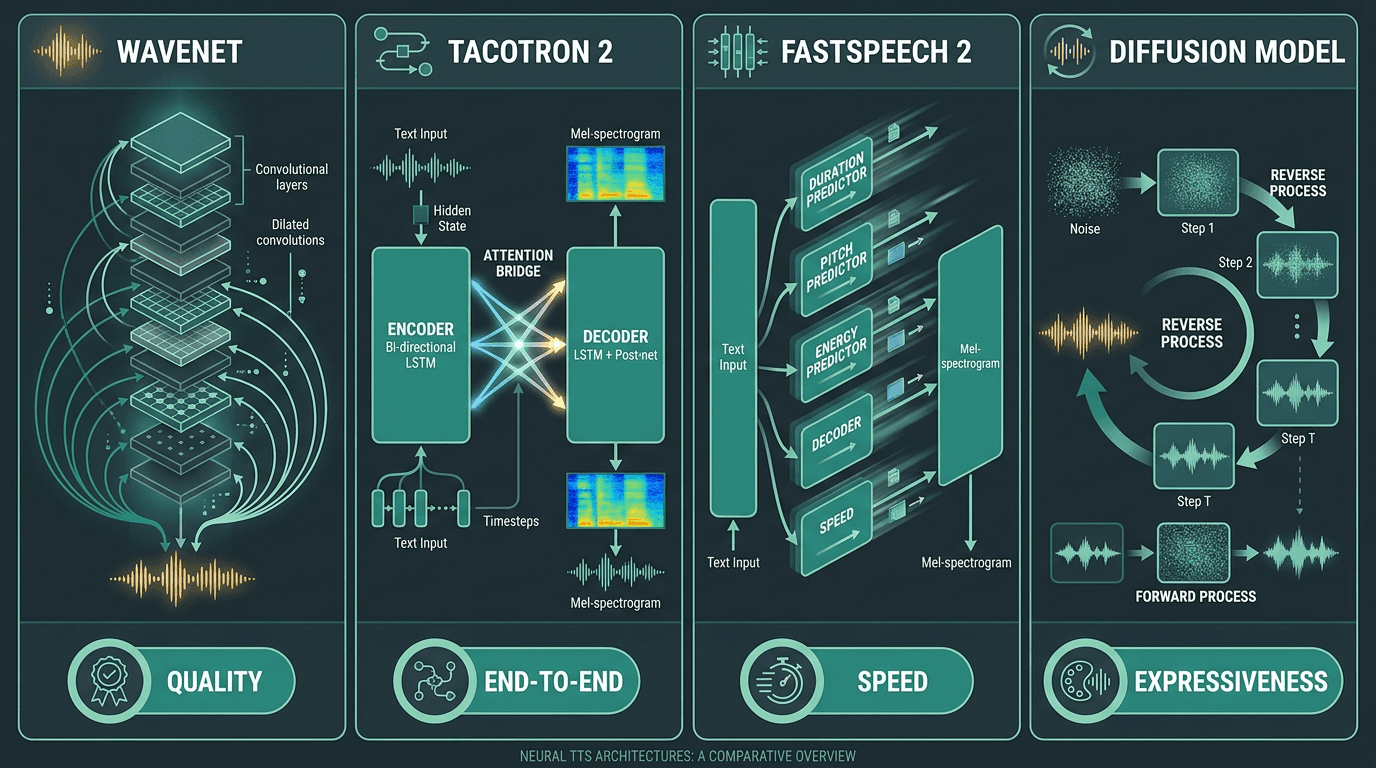
Key neural TTS architectures and the trade-offs each one optimizes for.
Where Neural TTS Is Actually Being Used
Accessibility is one of the oldest use cases: screen readers and tools for the visually impaired have relied on TTS for decades, but neural voices have made these tools genuinely pleasant rather than merely functional. Audiobook production has moved from experimental to mainstream, with publishers generating narration at a fraction of traditional studio costs. E-learning platforms now dynamically narrate course content. Navigation and in-car systems demand low-latency voice output. Brand voice programs let companies build a distinctive synthetic voice into their identity.
The highest-growth application right now is conversational AI. AI voice agents for customer service, sales, and support depend entirely on neural TTS to sound credible in real-time dialogue. A voice agent that sounds robotic loses user trust immediately, regardless of how capable the underlying language model is. The TTS layer is not a detail; it is the user's primary interface.
Major cloud providers have built neural TTS directly into their platforms as part of broader speech API offerings, which reflects how thoroughly the technology has moved from research into infrastructure.
Voice Cloning and Custom Voices: The Advanced Frontier
Standard neural TTS gives you a library of pre-built voices. Voice cloning takes this further. Given a short audio sample of a target speaker, a cloning system generates new speech in that person's voice by training or fine-tuning a speaker encoder on the sample, then conditioning the acoustic model on that speaker's embedding.
Zero-shot voice cloning, where a model clones a voice from just a few seconds of audio without fine-tuning, is now a practical capability rather than a research demo. A platform can offer users a voice that sounds like themselves. A brand can deploy a consistent voice across every customer touchpoint without recording thousands of hours of audio. The personalization implications are significant.
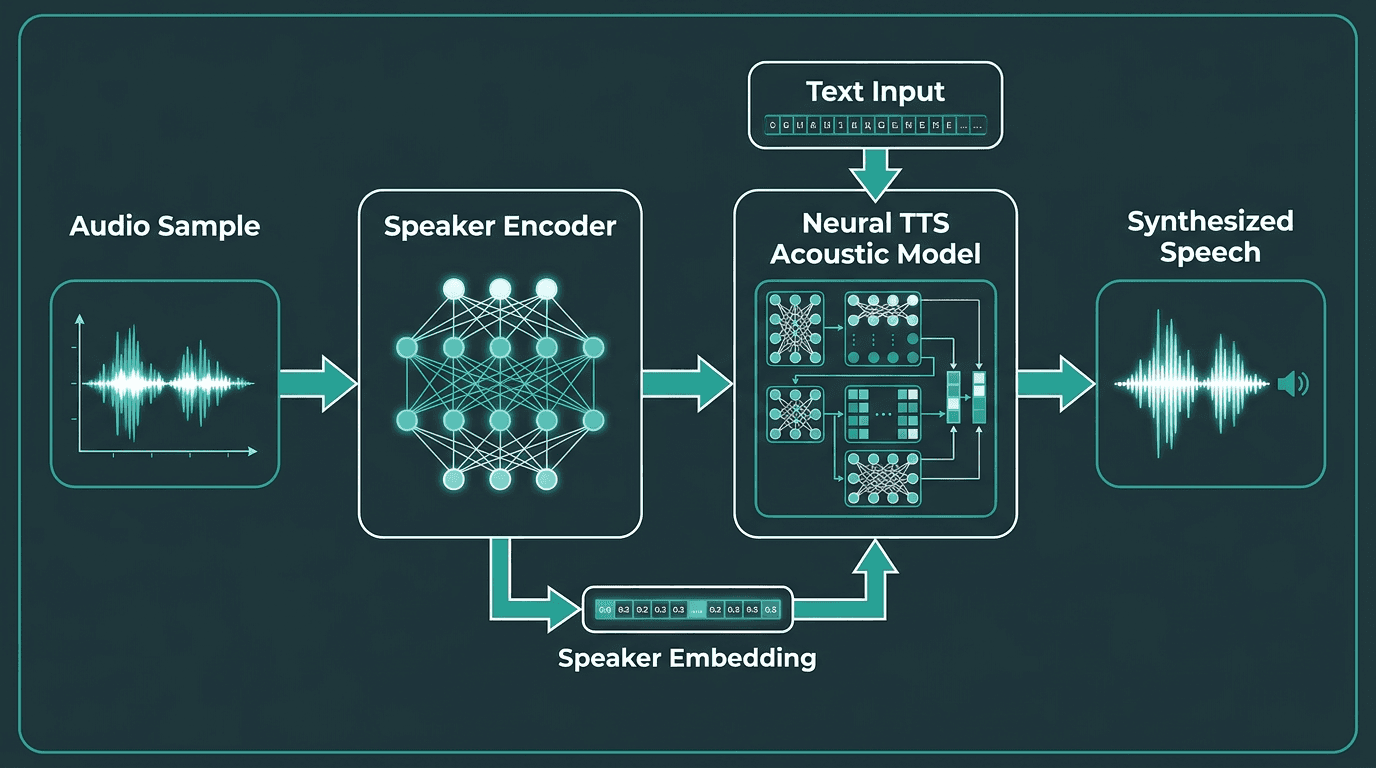
How voice cloning works: a speaker encoder extracts voice characteristics that condition the TTS model.
Evaluating Neural TTS: What the Metrics Actually Mean
Mean Opinion Score (MOS) is the most cited evaluation metric: human listeners rate speech naturalness on a 1-5 scale, and scores above 4.0 are generally considered to represent high naturalness, often approaching the quality of human speech in controlled conditions. The problem is that MOS is expensive to run, hard to reproduce, and does not reliably predict how a voice performs in specific contexts like phone audio or noisy environments.
Word Error Rate (WER) of downstream ASR systems is a useful proxy for intelligibility. If a speech recognizer struggles to transcribe synthetic audio, real users probably will too. Understanding Automatic Speech Recognition (ASR) is useful context here, since TTS and ASR are often evaluated in tandem in voice pipeline design. For latency-sensitive applications, time-to-first-audio and real-time factor (the ratio of generation time to audio duration) are the metrics that actually determine whether a system ships.
One metric that rarely appears in benchmarks but matters enormously in practice: consistency across edge cases. Proper nouns, technical jargon, mixed-language input, unusual punctuation. A model that scores 4.2 MOS on clean English sentences but mispronounces half your product names is not production-ready for your use case, regardless of what the benchmark says.
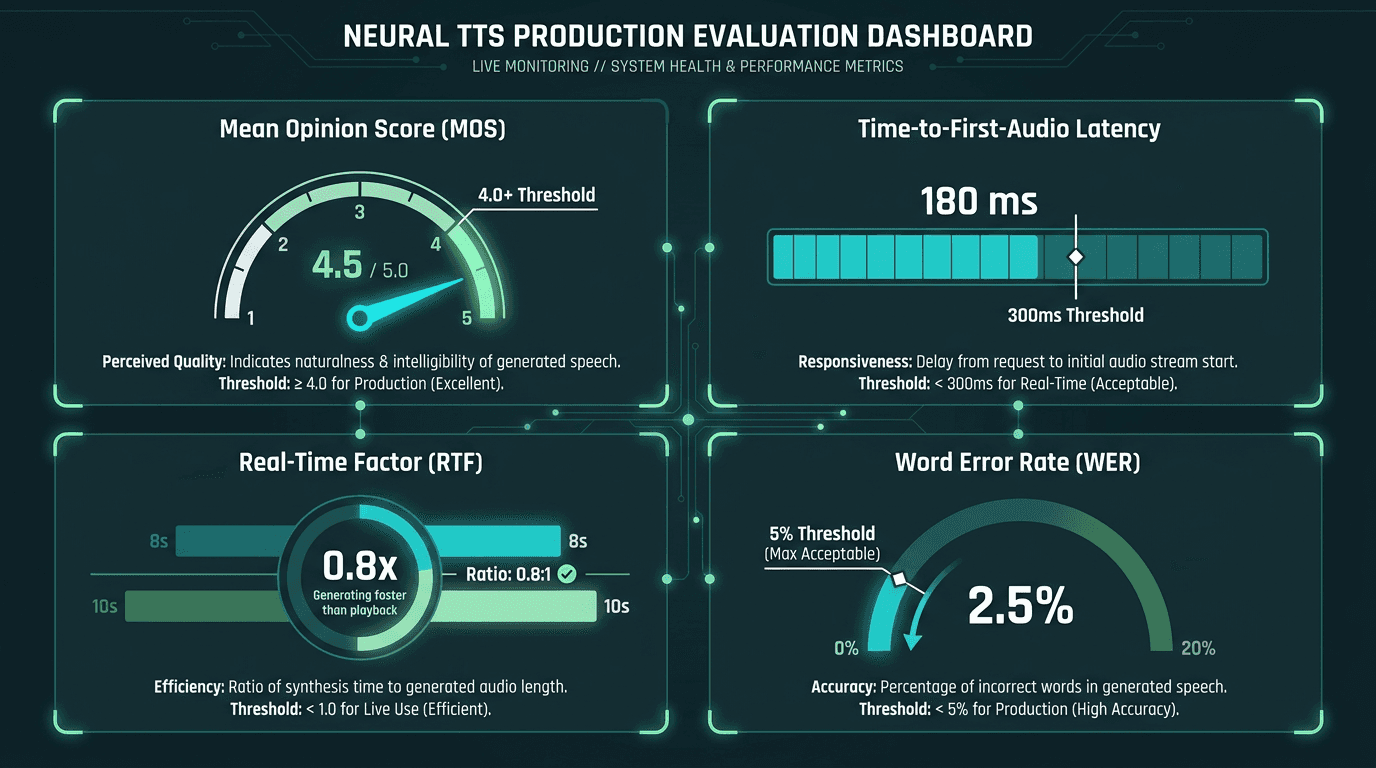
Key metrics for evaluating neural TTS systems in production: quality, speed, and intelligibility.
The Problem Neural TTS Solves, and What Comes Next
The fundamental problem neural TTS solves is the uncanny valley of synthetic speech. For decades, voice interfaces were tolerated rather than trusted because the voices felt wrong in ways that were hard to articulate but impossible to ignore. Neural TTS closed that gap by learning from human speech rather than approximating it through rules, producing voice output that people engage with rather than endure.
What comes next is tighter integration between the language model and the voice layer. Today, most voice AI systems generate text first and then synthesize it, which introduces latency and discards prosodic information the language model had but never passed along. The next generation of systems will encode emotion and intent from the start rather than approximating them at the synthesis stage. Voice recognition and TTS are also converging in full-duplex systems where a single model handles both understanding and speaking.
For developers building voice products today, the practical question is not whether to use neural TTS but which system fits your latency, quality, and customization requirements. For real-time conversational applications requiring sub-200ms latency with high expressiveness, Smallest.ai's Lightning TTS API is built specifically for that constraint. It is optimized for streaming synthesis in voice agent pipelines and pairs with Smallest.ai's broader voice stack, including Pulse for speech-to-text and Electron for conversational AI, giving you a complete infrastructure layer rather than a collection of disconnected APIs.
Key Takeaway: The Problem Neural TTS Solves, and What Comes Next
Neural TTS solved the biggest problem synthetic speech had for decades: it made machine-generated voices sound natural enough for people to actually trust and engage with them. Instead of stitching together fragments or following rigid pronunciation rules, modern neural TTS systems learn rhythm, tone, pauses, and emphasis from real human speech.
For developers building voice products today, the challenge is no longer just generating realistic speech. It is generating speech fast enough for real-time conversations, expressive enough for natural dialogue, and reliable enough for production use. That is especially important for AI voice agents, contact centers, sales calls, support workflows, and any product where voice is the main user interface.
This is where Smallest.ai’s Lightning TTS API fits in. Lightning is built for low-latency, streaming text-to-speech, helping teams create voice agents that respond quickly and sound natural in live conversations. It also works alongside Smallest.ai’s broader voice stack, including Pulse for speech-to-text, giving developers a more complete infrastructure layer for building real-time voice AI.
If you are building a voice product where latency, expressiveness, and reliability matter, try Smallest.ai and start testing Lightning TTS in your own workflow.
What is the difference between neural TTS and standard TTS?
How fast does a neural TTS system need to be for real-time use?
Can neural TTS support multiple languages?
What is voice cloning and how is it different from standard neural TTS?
How do I choose the right neural TTS API for my application?

