Automatic Speech Recognition (ASR): What It Is and How It Works


A practical guide to automatic speech recognition (ASR): how it works, why modern ASR performs better, and what to evaluate beyond benchmark accuracy.
A customer calls your support line. Within a fraction of a second, their speech is turned into text, split by speaker, passed into a routing system, and used to trigger the next step in the conversation. No human is typing. No one is manually tagging the call. That first layer is Automatic Speech Recognition (ASR).
Automatic speech recognition, or ASR, is the technology that converts spoken language into text. It powers live captions, meeting transcripts, voice agents, call analytics, dictation tools, and searchable audio archives. People use it every day without thinking about it, until they have to build with it. Then it gets real, fast.
Although “speech-to-text” appears straightforward, implementing it in practice is complex.
Demo audio can be misleading. In production, audio typically contains interruptions, narrowband codecs, background noise, diverse accents, and unfamiliar terms. A transcript that performs well in a demo may not succeed in real-world scenarios such as contact centers, multilingual conversations, or voice agents.
Many resources focus only on definitions and basic metrics, overlooking these challenges. If you are evaluating ASR as a developer, product manager, founder, or buyer, a deeper understanding is essential:
What ASR actually does under the hood
Why modern systems work better than older ones
Which metrics matter and which are misleading on their own
How your use case changes what “good” looks like
This guide is intended to provide that clarity.
What is ASR?
ASR is the underlying technology that turns speech into text.
When people say speech-to-text, they are usually talking about the product capability. When they say ASR, they are referring to the technology underneath it. In most practical conversations, the terms get used interchangeably, but there is a useful distinction:
ASR = the recognition engine
Speech-to-text = the feature or product experience powered by that engine
Voice recognition = identifying who is speaking
NLP = understanding what the text means after ASR has produced it
This distinction matters because teams often focus on the wrong layer. Rather than only requesting speech-to-text, it is critical to assess whether the ASR layer meets requirements for speed, accuracy, and robustness. For more information on the underlying mechanics, see our guide on how voice recognition works.
Why ASR Matters More Now Than It Did a Few Years Ago?
ASR has existed for decades. While its fundamental goal remains the same, what changed is the quality and adaptability to diverse environments.
Older systems worked best in controlled settings: clean speech, limited vocabulary, predictable phrasing. Whereas Modern ASR can handle:
Spontaneous speech instead of carefully read speech
Accents and code-switching
Overlapping speakers
Noisy environments
Telephony audio
Real-time streaming
This evolution has transformed ASR from a niche feature into core infrastructure. It supports automation, AI voice agents, compliance review, accessibility, search, summarization, and analytics.
For products that process spoken language at scale, ASR is essential and a strategic system choice.
How Automatic Speech Recognition Works?
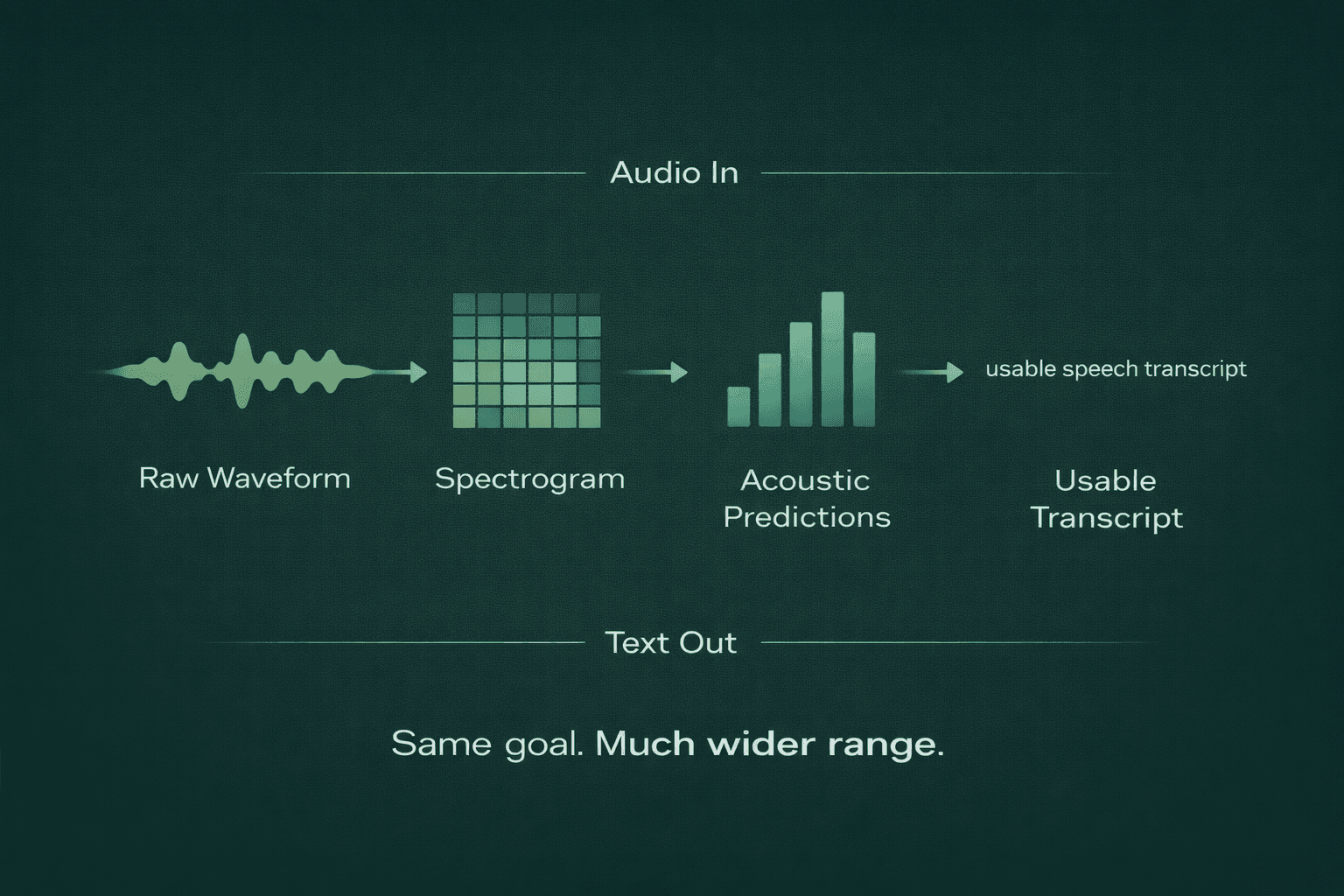
At a high level, ASR processes an audio signal to estimate the sequence of spoken words. Each step in this process is complex.
1. The System Starts with the Raw Waveform
Audio arrives as a waveform: a changing signal over time. Machines can process raw waveforms directly, but many ASR systems first transform them into a representation that makes speech patterns easier to detect.
A common representation is a spectrogram, often a mel spectrogram.
Think of it as a map of how energy is distributed across frequencies over time. Instead of seeing only amplitude, the model gets a view of how speech sounds evolve. Vowels, fricatives, plosives, pauses, and breath sounds all leave different signatures.
This distinction is important because speech is a time-varying acoustic event, not merely a sequence of letters. The model must identify patterns in sound to accurately recover words.
2. The Model Predicts Smaller Speech Units
Once the audio has been represented in a usable form, the model starts predicting likely linguistic units over time.
Depending on the system, those units may be:
Phonemes: basic sound units like /p/, /b/, /aa/
Characters: individual letters or symbols
Subwords: chunks smaller than full words but larger than letters
Word pieces or tokens: common pieces used in modern neural systems
Phonemes are distinct from letters; they represent sounds. For example, the words “cat” and “kite” begin with different letters after the first, but both start with the same /k/ sound, which the model learns to recognize.
This stage is often called acoustic modeling, because the system is mapping acoustic patterns to probable speech units.
3. Decoding Turns Raw Predictions into Actual Text
Many simplified explanations do not address this stage in detail.
The model does not hear a sentence and instantly “know” the final transcript. It produces probabilities over time. Decoding turns those probabilities into the most likely text sequence.
Decoding is necessary because raw audio evidence is often ambiguous and complex.
A short sound might map to multiple words. Background noise might distort a syllable. Fast speech might blur boundaries between words. The decoder chooses the sequence that best fits both the sound and the language patterns the system has learned.
This is also where language modeling matters.
When acoustic evidence is ambiguous between phrases, the system relies on context to determine the most plausible option. For example, “recognize speech” and “wreck a nice beach” can sound similar, but context helps the system choose the correct phrase.
4. The Transcript Is Refined for Actual Use
A raw transcript is not always useful by itself. Many production systems add layers to make the output usable:
Punctuation
Capitalization
Timestamps
Speaker labels
Segment boundaries
Confidence signals
Language identification
These enhancements are often considered optional, but they are essential for practical use.
A transcript without timestamps is harder to audit. A call transcript without speaker labels is weaker for QA and coaching. A transcript without segmentation is difficult for summarization or search.
Both recognition accuracy and transcript usability are important.
The Older ASR Stack vs. the Modern One
Many articles mention this topic but do not explain it in detail.

Traditional ASR: A Pipeline of Specialized Components
Older ASR systems were usually hybrid systems. They stitched together multiple separate pieces:
A feature extraction stage
An acoustic model
A pronunciation lexicon
A language model
A decoder
A common combination was HMM-GMM:
Hidden Markov Models (HMMs) modeled the sequence of speech states over time
Gaussian Mixture Models (GMMs) modeled how the acoustic features were distributed for those states
While understanding the mathematics is not required, it is important to note that these systems were modular and tunable, but also fragile. They relied on handcrafted components and assumptions about pronunciation, timing, and language structure.
This approach made the systems useful and interpretable, but also brittle.
They struggled more when speech got messy:
Strong accents
Spontaneous conversation
Noisy audio
Overlapping speakers
Domain-specific vocabulary
Multilingual switching
Modern ASR: Neural Systems Trained on Large Real-World Data
Modern ASR moved toward deep neural models and, increasingly, end-to-end or near-end-to-end architectures.
Instead of hand-optimizing multiple discrete components, newer systems learn more of the mapping from audio to text directly from data. Depending on the architecture, they may use:
CTC-based models
Attention-based encoder-decoder systems
RNN-T style streaming models
Transformer-based architectures
Hybrid neural systems with separate decoding layers
The key is understanding the practical changes in ASR systems, rather than memorizing acronyms.
Modern ASR got better because:
Models learned from much larger and more varied audio corpora
Neural representations handled variability better than older handcrafted assumptions
Systems were trained closer to real-world conditions
Architectures improved for streaming and low-latency inference
As a result, modern systems handle real customer calls, voice agents, live meetings, and multilingual speech more effectively than previous generations.
While not perfect, they represent a significant improvement.
A Simple Comparison
Traditional hybrid ASR | Separate acoustic, lexicon, language, and decoding components | Interpretable, configurable, easier to reason about in parts | More manual tuning, less robust to messy real-world audio |
Modern neural ASR | Learns audio-to-text mappings from large datasets using neural models | Better generalization, stronger real-world accuracy, better streaming options | Data-hungry, deployment-sensitive, can be harder to debug |
What “Good ASR” Actually Means
Many teams assume ASR quality is determined by accuracy, but this is not the case.
The key question is not which model has the lowest WER on a benchmark, but which system performs best for your audio, latency requirements, and workflow.
This is a more challenging but ultimately more valuable question.
Accuracy Matters, but in Context
The most common accuracy metric is Word Error Rate, or WER.
WER counts how many edits are needed to turn a predicted transcript into the reference transcript:
Substitutions
Deletions
Insertions
Then it divides that by the total number of reference words.
Lower WER is better. But WER has limits.
For call summarization, minor punctuation differences may be acceptable. In medical dictation, a single incorrect term can be critical. For live agent turn-taking, a slightly less accurate but faster stream may provide a better user experience than a slower, more accurate transcript.
WER is a useful but incomplete metric.
CER Matters in Some Languages and Edge Cases
Character Error Rate, or CER, measures error at the character level rather than the word level.
It becomes helpful when:
Word boundaries are less reliable
You care about spelling precision
You are evaluating languages where word segmentation behaves differently
Names, IDs, or codes matter a lot
WER remains the standard in many evaluations, but CER can identify issues WER may overlook.
Latency Matters More Than Many Teams Expect
If your transcript appears after the user has moved on, the model can be “accurate” and still fail the product.
For real-time transcription, pay attention to:
Time to first token or first result
Streaming stability
P95 latency, not just average latency
Turn-taking quality in conversational systems
This is critical for voice agents and live captioning, where users notice delays immediately. Even a delay of a few hundred milliseconds can make conversations feel unnatural or interfaces less effective.
Diarization and Metadata Can Matter More Than Marginal Accuracy Gains
In many business workflows, the transcript is not the end product. It is the input to another system.
That means these may matter as much as raw recognition:
Speaker diarization
Timestamps
Confidence signals
Segmentation quality
Language detection
Stable streaming behavior
A model with slightly higher WER but reliable speaker labels may be more useful for call center QA than a model that wins narrowly on clean-text benchmarks.
For this reason, evaluating ASR on headline accuracy is often insufficient.
Real-World Examples That Change What You Optimize
This is where theoretical considerations often differ from practical deployment.
1. Customer Support Calls with Overlap and Noise
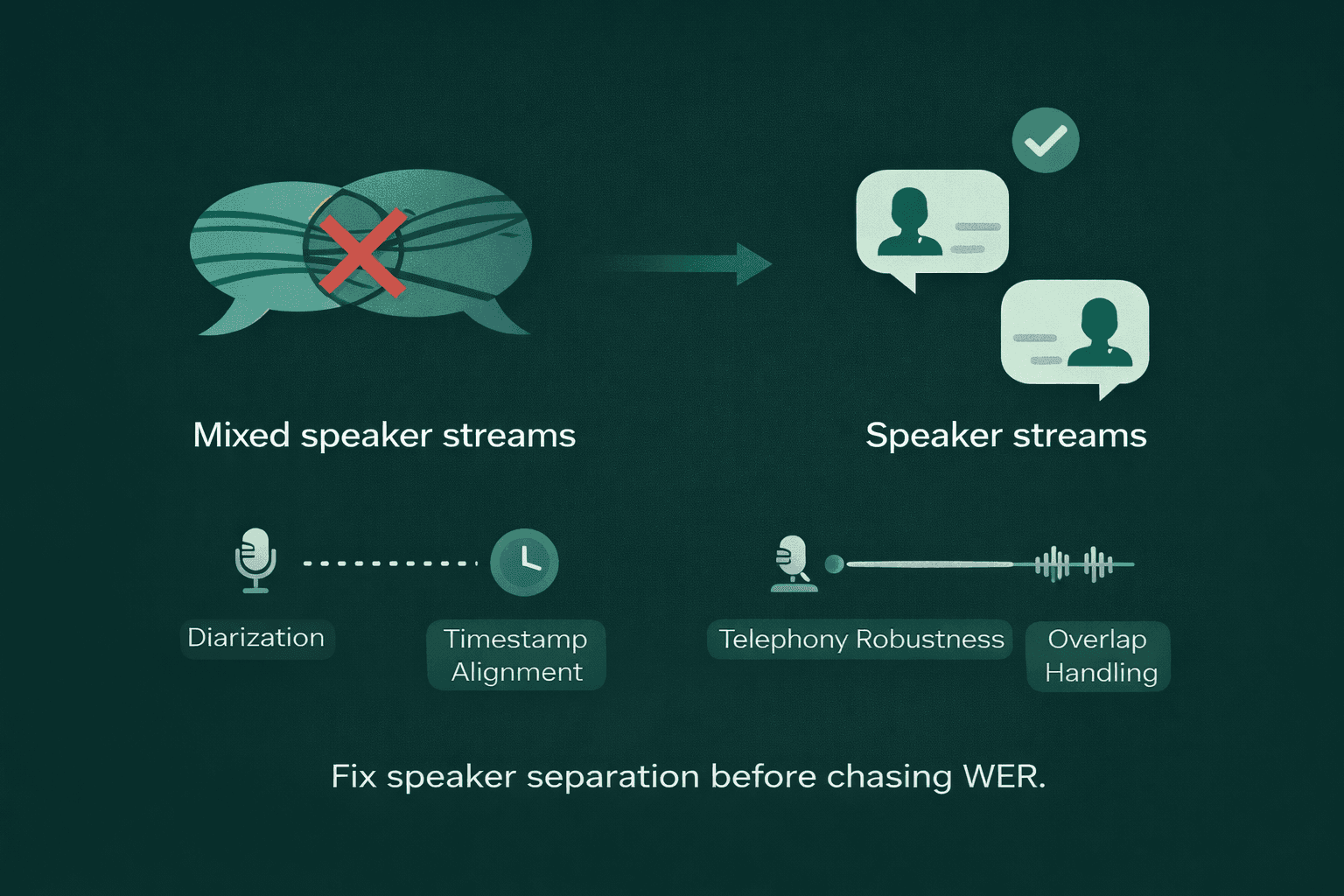
In support calls, two people talk over each other. Lines crackle. Someone is on speaker. Someone else is in a room with background chatter. The real business question is often not just “what words were spoken?” It is “what did the customer say, and what did the agent say?”
In that environment, speaker diarization can matter more than shaving a tiny amount off WER.
If your transcript is slightly cleaner but mixes both speakers into one stream, your QA team, compliance tools, and coaching workflows all get weaker. The transcript becomes harder to use.
What to optimize for:
Diarization quality
Timestamp alignment
Telephony robustness
Performance on overlapped speech
These factors are often more important than raw text accuracy.
2. Voice Agents Live or Die on Response Speed

If you are building a voice agent, the user is not grading your transcript. They are feeling the interaction.
What breaks the experience first is often not recognition accuracy. It is delay.
A voice agent needs to know when a user has started speaking, what they are likely saying, whether they have finished, and when the system should respond. That means the recognition layer must stream quickly and consistently.
In this setup, a key metric is not just final transcript quality. It is the speed at which the first usable partial result appears, and how stable those streaming updates are.
What to optimize for:
Time to first result
P95 latency under load
Interruption handling
Smooth interim transcripts
A highly accurate transcript delivered with significant delay still results in a poor conversational experience.
3. Telephony Audio Is Not “Bad Audio.” It Is Different Audio

Many teams benchmark on clean WAV files and then deploy on phone calls. That is one of the fastest ways to fool yourself.
Telephony audio is often:
Narrowband, like 8 kHz
Compressed
μ-law encoded
Lossy in ways that change what the model hears
This does not make telephony audio unusable; it simply differs from studio-quality audio.
Testing on pristine audio but deploying on telephony audio results in benchmarks that do not reflect real-world performance.
What to optimize for:
Codec-matched evaluation
Phone-call audio samples in the test set
Robustness to compression artifacts
Domain vocabulary on real call data
This is one of the most common evaluation mistakes teams make.
Common ASR Use Cases
ASR is now embedded across a wide range of workflows, but the optimization target changes by use case.
Meeting transcription: The priority is usually readable text, punctuation, timestamps, speaker labels, and strong accuracy on multi-speaker conversations.
Contact center analytics: You need reliable performance on telephony audio, good diarization, domain terms, and usable transcripts for QA, compliance, summaries, and routing.
Voice agents: Streaming latency becomes critical. The model has to support natural turn-taking, not just good offline transcripts.
Media transcription and subtitles: Accuracy, punctuation, multilingual handling, timestamps, and batch efficiency matter more than ultra-fast streaming.
Searchable audio archives: You need transcripts structured well enough to support indexing, search, tagging, and retrieval.
Accessibility and live captions: The balance shifts toward real-time responsiveness and stable incremental output, with accuracy still important but not alone.
How to Evaluate ASR Properly
This is the part that separates a clean vendor demo from a serious evaluation. For a deeper look at this process, see our guide on evaluating streaming speech recognition models.
1. Build a Representative Test Set
Do not evaluate on whatever audio is easiest to gather.
Use audio that reflects reality:
Accents your users actually have
Background noise you actually expect
Codecs you actually deploy
Domain vocabulary you actually care about
Speech styles your users actually produce
An unrealistic dataset can create a false sense of confidence.
2. Normalize Transcripts Consistently
If one transcript includes punctuation and another does not, or one expands contractions and another keeps them, you can distort the evaluation.
Before computing WER or CER, decide:
Casing rules
Punctuation rules
Number formatting
Filler-word handling
Abbreviation handling
Inconsistent normalization leads to unreliable comparisons.
3. Slice Results, Do Not Just Average Them
A single average WER can hide a lot:
Maybe English works well, Hindi-English code-switching does not
Maybe clean audio works well, telephony does not
Maybe short utterances work well, long calls degrade
Break results down by:
Language
Accent
Audio source
Noise level
Use case
Conversation length
Detailed analysis at this level provides the most actionable insights.
4. Measure Latency Like a Production Team, Not Like a Marketer
Do not rely on best-case or average latency alone.
Track:
P50 latency
P95 latency
Time to first result
Streaming stability over longer sessions
Performance under concurrency
Outliers are important because users experience their effects directly.
5. Evaluate Downstream Usefulness, Not Just Transcript Quality
Ask:
Can your summarizer use the transcript well?
Are timestamps accurate enough for review workflows?
Do speaker labels hold up?
Does the transcript preserve names, product terms, and numbers?
Does the system reduce manual cleanup or just shift the work downstream?
The optimal ASR system is not always the one with the highest benchmark score, but rather the one that best fits your workflow.
What to Look for in ASR Software
When making a choice, use a practical checklist.
Accuracy on your real audio: Not generic claims. Not leaderboard screenshots. Your audio.
Streaming support if you need live interactions: If your product is interactive, real-time support is required.
Low-latency performance under load: Not just “fast in ideal conditions.” Fast when multiple sessions are active.
Features that reduce downstream work: Look for speaker diarization, timestamps, segmentation, language detection, and confidence metadata. These features often matter more than teams expect.
Deployment and security fit: Especially for enterprise or regulated data, ask about private deployment options, retention controls, encryption, auditability, and access controls.
Robustness, not just benchmark quality: The system must perform reliably with real-world audio, not just in controlled environments.
Where Smallest AI Fits
Smallest AI’s primary advantage is not just offering speech-to-text, but providing a product designed for real-time, production-grade voice workflows.
That matters most when the buyer cares about:
Low latency
Live conversations
AI voice agents
Operational use, not just offline transcription
Production deployment quality
That is the angle worth leaning into. Not generic ASR claims. Focus on practical voice infrastructure value. Test our speech-to-text API to see the difference.
ASR vs. Speech-to-Text vs. Voice Recognition
ASR | The technology that converts spoken audio into text | Transcribing a customer call |
Speech-to-text | The product feature built on top of ASR | Live captions or meeting notes |
Voice recognition | Identifying who the speaker is | Verifying a user’s identity by voice |
NLP | Understanding and acting on the transcribed text | Summarization, routing, intent detection |
Much of the confusion arises from conflating these terms. ASR provides the transcribed words, while other systems determine subsequent actions.
Final Thought
ASR is often described inaccurately or oversimplified.
It is more than just “AI that turns speech into text.” While accurate, this definition lacks sufficient detail for practical understanding.
A useful understanding of ASR starts with the pipeline, then moves to the real questions: what kind of audio you are dealing with, what latency your product can tolerate, what downstream tasks depend on the transcript, and how much mess from the real world your system can absorb before it breaks.
Teams should approach ASR as a critical system component, rather than a novelty feature, a checklist item, or solely a benchmark competition.
For a thorough ASR evaluation, test the system with your own audio, assess multiple metrics, and optimize for your specific workflow requirements.
What is ASR in simple terms?
Is ASR the same as speech to text?
Can ASR work in real time?
What is Word Error Rate?
Why is low latency important in ASR?
What is diarization?
Can ASR handle noisy environments?
How should I evaluate ASR for my product?

