Human-Like Text-to-Speech: Quality, Latency, and Provider Selection in 2026


Discover what makes human voice text to speech truly realistic in 2026. Compare neural TTS quality, latency, and emotion control to find the best AI voice.
Human-like text-to-speech has reached a point where synthetic voices can be difficult for listeners to separate from real human speech, with one 2025 study finding that AI voice clones fooled listeners at rates close to real human voices. The latest AI voiceover systems now capture subtle nuances like laughter, sighs, and natural pauses, making synthesized speech nearly indistinguishable from a real human recording.
The global text-to-speech market has seen sustained growth driven by the rapid expansion of voice agents, accessibility tools, and AI-powered content creation.
This article is aimed at developers, product teams, and voice AI practitioners who want to understand what separates truly realistic AI voices from the robotic-sounding systems of the past. By the end, you will know what technical factors drive naturalness, how to evaluate voice quality objectively, and where Smallest.ai fits into this landscape.
What Makes a Voice Sound Human
Most people assume that a realistic AI voice is just a matter of 'better audio quality.' That is the wrong frame. Audio fidelity is table stakes. The real differentiators are prosody, emotional range, and contextual adaptability.
Prosody refers to the rhythm, stress, and intonation patterns that carry meaning beyond the words themselves. A sentence like 'Really?' can express disbelief, curiosity, or sarcasm depending entirely on prosodic shaping. Early concatenative TTS systems, which stitched together pre-recorded phoneme segments, could never handle this well because they lacked any model of communicative intent. Modern neural TTS systems, by contrast, are trained on thousands of hours of human speech and learn to model these patterns statistically. The result is output that carries natural stress, appropriate pauses, and even speaker-specific quirks.
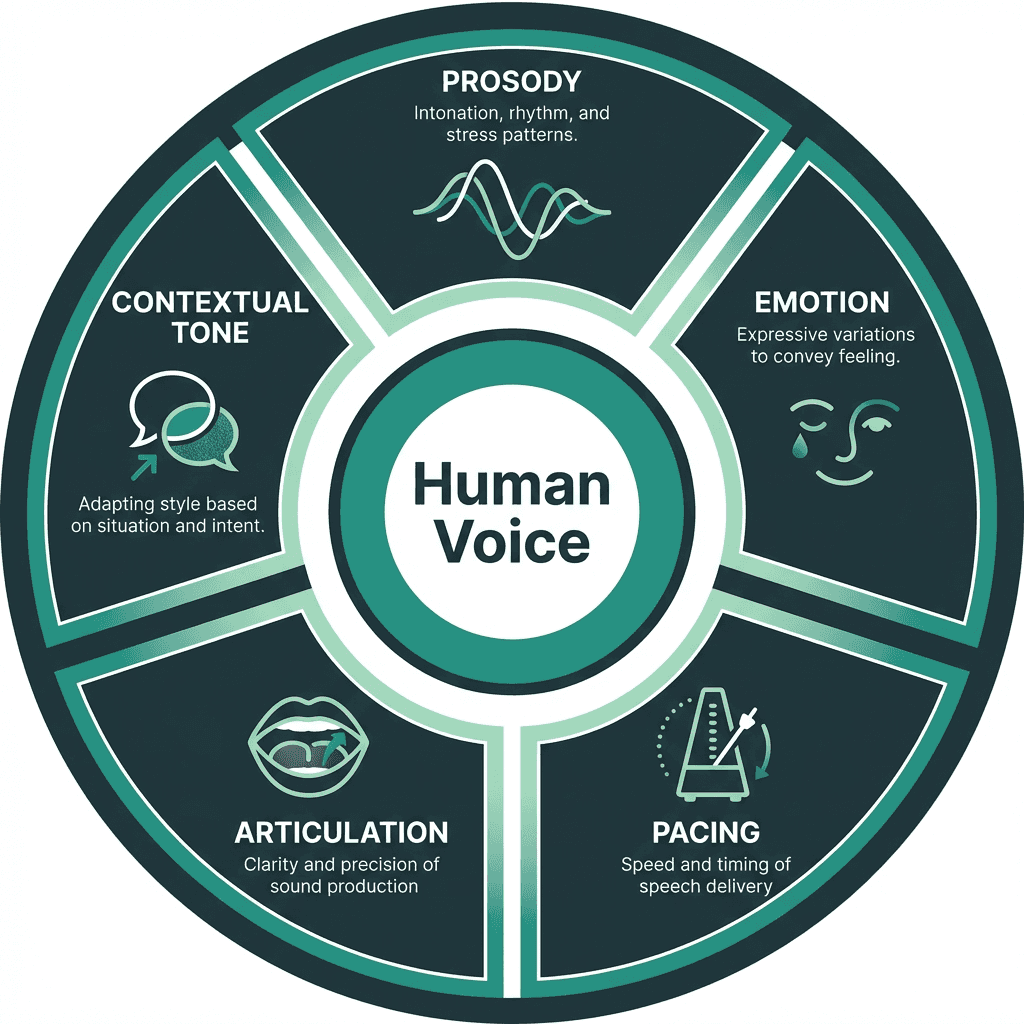
Five dimensions that separate realistic AI voices from robotic-sounding synthesis
The Technology Stack Behind Realistic Voice Synthesis
Neural TTS architectures have evolved through several generations, and the progression matters because each generation addressed a specific failure mode of its predecessor.
Generation | Architecture Type | Key Strength | Key Limitation |
|---|---|---|---|
1st Gen | Concatenative / Rule-based | Predictable output | Robotic, no prosody control |
2nd Gen | HMM-based Statistical | Smoother transitions | Flat affect, limited expressiveness |
3rd Gen | Neural (Tacotron, FastSpeech) | Natural prosody, speaker cloning | High compute, latency issues |
4th Gen | Diffusion / Flow-based Neural | Ultra-low latency, emotional range | Still maturing for edge deployment |
Current state-of-the-art systems combine a text encoder, a prosody predictor, and a neural vocoder. The vocoder is where much of the perceptual quality is won or lost. WaveNet-style vocoders produce exceptional audio but are computationally expensive. More recent flow-based and diffusion vocoders achieve comparable quality at a fraction of the inference cost, which is critical for real-time applications like voice agents. If you are building voice-enabled products, understanding human-like AI voices and the emotional modeling layer is as important as understanding the vocoder itself.
Evaluating Voice Quality: What the Numbers Actually Tell You
The standard benchmark for synthesized speech is MOS (Mean Opinion Score), which rates output on a 1-5 scale based on human listener judgments. A score above 4.0 is generally considered 'natural-sounding,' and top neural TTS systems now regularly achieve MOS scores of 4.2 to 4.5 on standard test sets. But MOS has a known weakness: it measures average perception across a panel, not performance on edge cases. A system might score 4.3 on clean, declarative sentences and fall to 3.1 on technical jargon, questions, or emotionally charged text. Treat MOS as a starting point, not a verdict.
What most evaluations miss is latency under load. For a voice agent handling thousands of concurrent sessions, a model that produces beautiful audio in 800ms per sentence can become impractical for real-time applications. Real-time factor (RTF) measures how fast a system generates audio relative to the duration of that audio. An RTF below 1.0 means the system generates speech faster than it plays, which is the minimum bar for interactive applications.
Use Cases Where Realism Is Non-Negotiable
Not every application needs the highest possible voice quality. A simple IVR system reading back a confirmation number can get away with decent but unremarkable synthesis. There is, however, a growing category of applications where voice realism is directly tied to product success. Voice AI has moved from experimental to production-critical, with developer adoption accelerating across customer support, accessibility, and content workflows.
Applications where human-level voice quality drives measurable outcomes:
Conversational voice agents for customer support: Users abandon calls when the voice feels robotic. Naturalness directly reduces churn in automated support flows.
AI companions and mental wellness apps: Emotional authenticity is the product. A flat, affectless voice undermines the entire value proposition.
E-learning and audiobook narration: Listener fatigue sets in faster with synthetic-sounding audio, reducing completion rates.
Real-time language dubbing: Prosody must match the emotional register of the source content, not just the words.
Accessibility tools for users with reading difficulties: Naturalness improves comprehension and engagement for users who rely on TTS daily.
For teams building these systems, the architectural decisions around TTS are covered in detail in the guide on AI voice agents architecture, voice models, use cases, and safety guardrails.
How to Choose a Human Voice TTS Provider

A five-step framework for evaluating and selecting a realistic TTS provider
Selection criteria depend heavily on your deployment context. A developer building a Python-based narration pipeline has different requirements than a product team deploying a real-time voice agent at scale. The framework below applies across both scenarios, though the weights you assign to each criterion will differ significantly.
Criterion | Why It Matters | What to Test |
|---|---|---|
Voice Naturalness | Directly affects user trust and engagement | MOS score, blind listening tests on your content type |
Latency (RTF) | Critical for real-time and interactive applications | Time-to-first-audio-byte under concurrent load |
Emotional Range | Required for agents, companions, and narrative content | Test with questions, exclamations, and emotional prompts |
Language and Accent Coverage | Global products need multi-language fidelity | Native speaker evaluation, not just automated metrics |
API Design and SDK Quality | Affects developer velocity and integration cost | Documentation quality, SDK availability, error handling |
Pricing Model | Determines scalability economics | Per-character vs per-second vs flat rate; volume tiers |
One criterion that rarely appears in comparison guides but matters enormously in practice: how does the system handle domain-specific vocabulary? Medical, legal, and technical content is full of terms that general-purpose TTS models mispronounce. Some providers allow custom pronunciation dictionaries or phoneme-level overrides. If your use case involves specialized terminology, test this explicitly before selecting a provider. Developers looking for implementation guidance can start with building realistic text-to-speech in Python to understand how API choices translate into production code.
Advanced Considerations: Voice Cloning, Emotion Control, and Multilingual Fidelity
Voice cloning has matured significantly. Where early systems required hours of reference audio to produce a passable clone, current approaches can generate a consistent speaker identity from as little as a few seconds of audio. The quality ceiling, however, is still determined by the reference recording. A noisy, compressed reference will produce a noisy, compressed clone regardless of how sophisticated the underlying model is.
Emotion control is where the most interesting work is happening right now. Some systems expose explicit emotion tags (happy, sad, angry) that modify prosody at inference time. More sophisticated approaches allow continuous control over emotional intensity, so you can dial in 'mildly enthusiastic' rather than toggling between neutral and 'very excited.' This matters for e-learning in particular, where a narrator should sound engaged but not performative. The guide on human-like AI voices covers the technical mechanisms behind emotion-aware synthesis in depth.
Multilingual fidelity is frequently overstated in marketing materials. A system that supports 30 languages does not necessarily produce equally natural output across all of them. English and Mandarin might score 4.3 MOS while a less-resourced language scores 3.4. For global deployments, always run native speaker evaluations on your specific target languages rather than relying on headline language counts. Competitive pressure to improve multilingual quality will intensify as AI voice generation becomes a core infrastructure layer across industries.
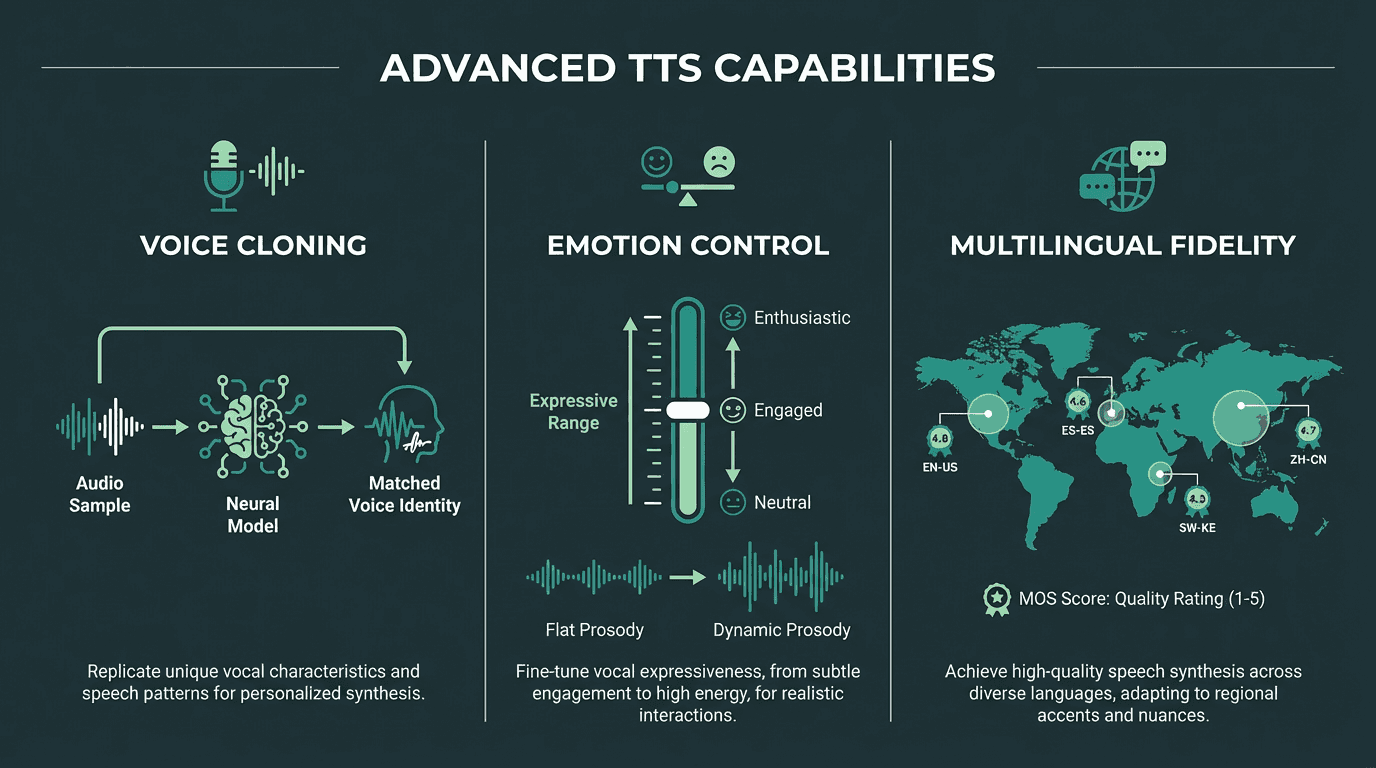
Three advanced dimensions of modern human voice TTS: cloning, emotion control, and multilingual fidelity
Smallest.ai: Built for Production-Grade Voice Realism
Smallest.ai was built around a specific conviction: the gap between 'impressive demo' and 'production-ready voice AI' is primarily a latency and consistency problem, not a quality problem. While several platforms now offer high-quality neural TTS, performance under real-time constraints and consistency at scale remain key differentiators. Most systems can produce beautiful audio in a controlled environment. Far fewer can do it reliably at scale, in real time, across diverse content types.
The Lightning speech model from Smallest.ai is designed to deliver ultra-low latency synthesis without sacrificing the prosodic richness that makes voices sound human. For teams building voice agents, the combination of low RTF and high naturalness reduces the typical trade-off between responsiveness and quality. Teams evaluating cost at scale can review Smallest.ai pricing to understand how the model fits different usage volumes, and those who want to experiment before committing will find the free AI voice generator resource a practical starting point.
The platform is built for developers who need both the quality bar and the operational reliability to ship production voice products, focusing on the core challenges of latency, naturalness, and pricing scalability.
The core challenge for most teams building voice AI products is finding a system that delivers both the perceptual quality users expect and the operational performance production demands. Demo-quality audio that falls apart under load, or fast synthesis that sounds robotic, are both failure modes that erode user trust. Smallest.ai's Lightning model was built to close that gap, combining neural voice quality with the low-latency architecture that real-time voice applications require. If you are building a voice agent, a narration pipeline, or any product where human voice text to speech quality is central to the user experience, Smallest.ai is the logical place to start.
Key Takeaways
What separates production-ready TTS from everything else:
Realism in TTS is driven by prosody, emotional range, and contextual adaptability, not audio fidelity alone.
Neural architectures have largely solved the quality problem. Latency and consistency under load are now the production differentiators.
MOS scores are useful but incomplete. Always test on your specific content type and measure RTF under realistic concurrent load.
Voice cloning quality is bounded by reference audio quality. Emotion control and multilingual fidelity require explicit testing, not vendor claims.
Provider selection should be driven by use case requirements. Real-time voice agents have fundamentally different constraints than narration pipelines.
Smallest.ai's Lightning model addresses the latency-quality trade-off that most production voice AI teams encounter.
What is human voice text to speech and how is it different from older TTS systems?
How do I evaluate whether a TTS system is truly realistic?
Can AI voice generators replicate any voice or accent accurately?
What is the difference between text-to-speech and a voice agent?
Is realistic AI voice synthesis expensive to run at scale?

