From Raw Audio to Structured Dialogue: A Guide to Speaker Diarization Pipelines

Learn how speaker diarization identify "who spoke when" in multi-speaker audio. Master DER metrics and technical pipelines for speech AI.
From Raw Audio to Structured Dialogue: A Guide to Speaker Diarization Pipelines
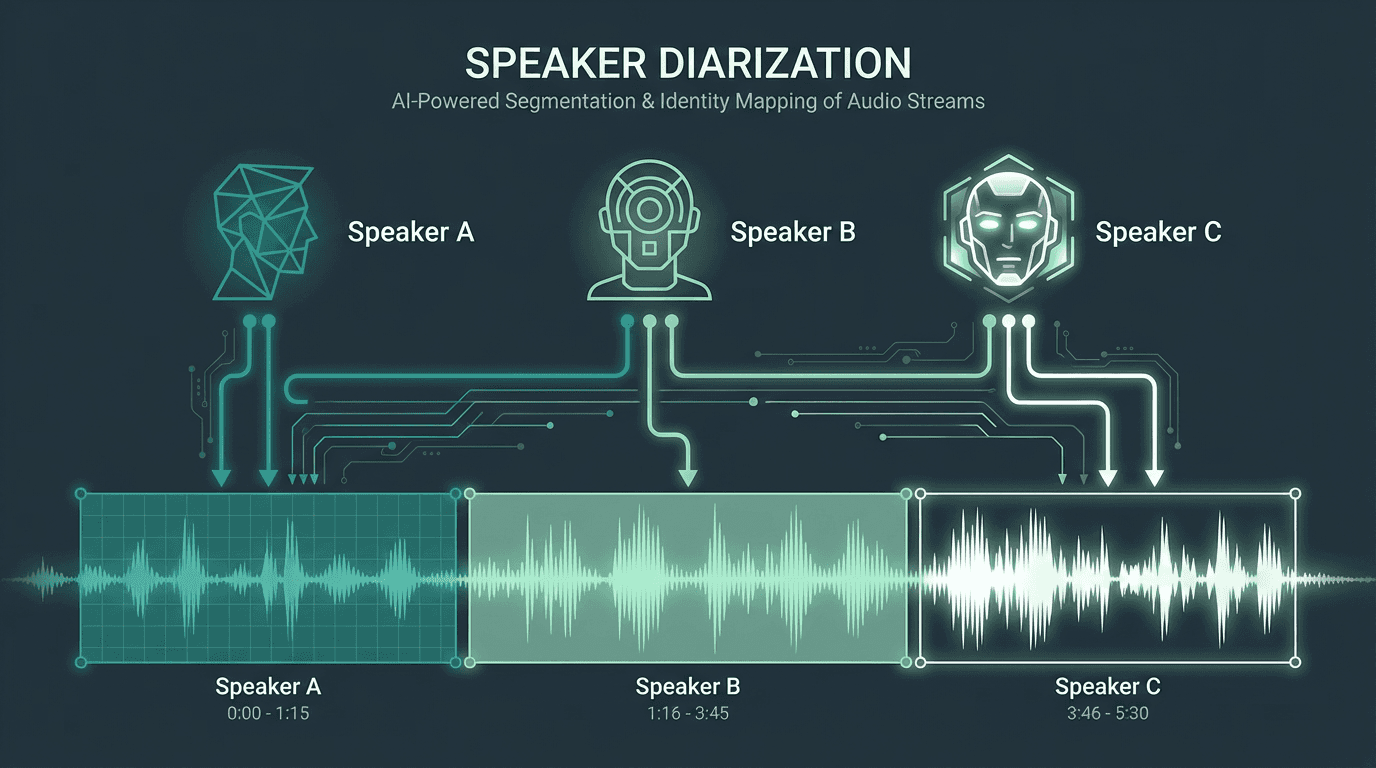
Speaker diarization is the process of partitioning an audio stream into segments based on speaker identity. Its primary goal is to answer the question, ‘who spoke when?’. Unlike speaker identification, which matches a voice to a known person, diarization works without any prior knowledge of the speakers, making it essential for transcribing and analyzing real-world conversations involving multiple, often unknown, participants.
This technology is a cornerstone of modern speech processing, transforming raw, jumbled audio from meetings, call center interactions, and media broadcasts into structured, readable transcripts. By attributing each spoken word to the correct individual, diarization unlocks deeper layers of analysis and comprehension, making audio data significantly more valuable. For developers building applications on top of speech AI, understanding diarization is not just beneficial; it's fundamental to creating sophisticated and user-friendly products.
Speaker diarization partitions an audio stream to identify 'who spoke when', a critical step in analyzing multi-speaker conversations.
Why Diarization is a Critical Component in Speech AI
At first glance, a simple transcript might seem sufficient. However, in any conversation with more than one person, a block of text without speaker labels quickly becomes confusing and loses most of its contextual meaning. Diarization adds this crucial layer of context, fundamentally changing the utility of transcribed audio. It's the difference between a chaotic script and a structured dialogue.
The impact is most evident in business and media applications. Consider a customer service call recording. Without diarization, it's impossible to systematically analyze agent performance versus customer sentiment. A meeting transcript without speaker labels makes it difficult to track action items or attribute key decisions. For media companies, accurate speaker labels are necessary for creating subtitles, closed captions, and searchable archives of interviews and panel discussions. This process is a key enabler for a wide range of speech analytics use cases, turning unstructured audio into a rich source of business intelligence.
The core benefits of integrating diarization into a speech processing pipeline include:
Enhanced Transcript Readability: The most immediate benefit is a transcript that is easy to read and understand. By clearly marking who said what, the flow of conversation becomes apparent.
Enabling Speaker-Specific Analysis: Once speech is attributed to specific speakers, you can perform targeted analysis. This includes calculating speaker talk time, analyzing sentiment per speaker, or tracking keyword mentions by individual participants.
Improving Downstream AI Tasks: Diarization provides vital input for other AI models. For example, a summarization model can create a more accurate summary if it knows which points were made by different people. Similarly, action item detection becomes more reliable.
Powering Automation and Compliance: In contact centers, diarization can automatically verify if an agent read a required compliance script or measure metrics like agent-to-customer talk ratio. This automates quality assurance and monitoring.
Ultimately, diarization bridges the gap between basic transcription and true conversational intelligence. It is a foundational element of any advanced speech-to-text AI functionality, providing the structure necessary for computers to understand not just what was said, but the dynamics of how it was said.
How Speaker Diarization Works: A Technical Breakdown
While the concept of identifying speakers is intuitive, the technical process is a sophisticated multi-stage pipeline. Modern diarization systems, particularly those leveraging deep learning, typically follow a sequence of steps to transform a raw audio file into a speaker-annotated transcript. This process works without needing pre-existing voice samples of the speakers involved.
Step 1: Voice Activity Detection (VAD)
The first task is to distinguish human speech from silence or background noise. A Voice Activity Detection (VAD) model analyzes the audio stream and identifies the precise start and end times of speech segments. This is a critical efficiency step; by filtering out non-speech portions, the system avoids wasting computational resources trying to analyze noise. Early VAD systems relied on energy thresholds, but modern neural network-based VAD models are far more accurate, capable of detecting speech even in noisy environments with music or other ambient sounds.
Step 2: Audio Segmentation
Once the speech regions are identified, they need to be broken down into smaller, manageable chunks. This process, known as segmentation, typically divides the continuous speech into short, fixed-length segments, for instance, 1.5 to 2 seconds long. The goal is to create segments that are long enough to contain unique speaker characteristics but short enough that they are unlikely to contain a change of speaker within the segment itself. This step is crucial for the subsequent feature extraction process.
Step 3: Speaker Embedding Extraction
This is the core of the diarization process where the system creates a unique 'voiceprint' for each audio segment. A specialized deep learning model, known as a speaker embedding model, processes each short segment and converts it into a high-dimensional vector (an embedding). This vector is a compact, numerical representation of the speaker's vocal characteristics, such as pitch, tone, and timbre.
Think of this embedding as a digital fingerprint for a voice. Segments spoken by the same person will produce vectors that are very close to each other in this multi-dimensional space, while segments from different speakers will result in vectors that are far apart. The effectiveness of this model is paramount to the overall accuracy of the diarization system. Models like x-vectors and d-vectors are common architectures used for this task.
Step 4: Clustering and Refinement
With a collection of speaker embeddings generated for all the audio segments, the final step is to group them. A clustering algorithm analyzes the geometric positions of these vectors in the embedding space. Its job is to group together the vectors that are closest to each other. Common algorithms used for this task include k-means, spectral clustering, and agglomerative hierarchical clustering.
The algorithm determines the optimal number of clusters, which corresponds to the number of unique speakers in the audio. Each cluster is then assigned a generic label like 'Speaker 1', 'Speaker 2', and so on. The timestamps from the initial segmentation are then re-associated with these final speaker labels. Some systems may perform an additional re-segmentation step to refine the precise boundaries between speaker turns, further improving accuracy.
Architectural Approaches: Cascaded vs. End-to-End Diarization
The multi-stage pipeline described above is known as a cascaded or modular system. It's the traditional and still most common approach to diarization. However, a newer approach, End-to-End (E2E) diarization, is gaining traction in the research community. Understanding the differences between these two architectures is key to appreciating the current state and future direction of the technology.
Cascaded Diarization Systems
Cascaded systems are built from a series of independent modules, each optimized for a specific task (VAD, embedding, clustering). This modularity is their greatest strength. It allows developers to swap out, fine-tune, or upgrade individual components. For example, you could replace a standard clustering algorithm with a more advanced one without rebuilding the entire system. This flexibility makes them easier to debug and adapt to specific use cases. The majority of production-grade diarization systems today, including those in popular open-source toolkits like pyannote.audio, are based on this architecture.
Advantages:
Modularity and Flexibility: Components can be individually optimized or replaced.
Interpretability: It's easier to diagnose problems by examining the output of each stage.
Maturity: This approach is well-established, with a wealth of research and pre-trained models available.
Disadvantages:
Error Propagation: An error in an early stage, like VAD, will negatively impact all subsequent stages. This is known as compounding error.
Complex Tuning: Each module has its own set of hyperparameters that need to be tuned, and the optimal settings for one may not be optimal for the entire pipeline.
End-to-End (E2E) Diarization Systems
End-to-end diarization systems represent a more recent paradigm, heavily influenced by advances in deep learning. The goal of E2E systems is to replace the multi-stage pipeline with a single, unified neural network. This network takes the raw audio as input and directly outputs the speaker labels and their corresponding timestamps. Models like EEND-SA (End-to-End Neural Diarization with Self-Attention) are trained jointly to perform both speaker representation and attribution simultaneously.
As detailed in the 2021 research survey, "A Review of Speaker Diarization: Recent Advances with Deep Learning," these E2E models can theoretically overcome the error propagation problem of cascaded systems by optimizing for the final diarization objective directly. They are particularly promising for handling complex scenarios with overlapping speech, a major challenge for traditional pipelines. While still largely in the research phase, toolkits like NVIDIA NeMo are making these advanced models more accessible to developers.
Advantages:
Joint Optimization: The entire model is trained to minimize the final diarization error, avoiding compounding errors.
Simpler Pipeline: Eliminates the need for multiple, separately trained models.
Better Overlap Handling: Some E2E architectures are inherently better at detecting and attributing speech when multiple people are talking at once.
Disadvantages:
Data Hungry: These models typically require very large amounts of labeled training data.
Less Interpretable: As a single 'black box', it can be harder to debug why the system made a particular error.
Computational Cost: Training and running these large, unified models can be computationally expensive.
How Diarization Performance is Measured: The DER Metric
To refine any system, you first need a way to quantify its performance. In speaker diarization, the industry-standard benchmark is the Diarization Error Rate (DER). Put simply, DER measures the total percentage of audio duration that is incorrectly attributed by the system. A lower DER, therefore, signifies higher accuracy.

DER is the sum of three distinct error types, providing a comprehensive measure of diarization accuracy.
But what contributes to this error rate? The total DER is the sum of three distinct error types, as defined by the National Institute of Standards and Technology (NIST):
Speaker Confusion Error: The percentage of time a speaker’s voice is assigned to the wrong person. For example, the system attributes a segment to Speaker A when Speaker B was actually talking.
False Alarm Speech: This error occurs when the system identifies speech in a segment that contains only silence or background noise. It’s often a byproduct of an imperfect Voice Activity Detection (VAD) model.
Missed Speech: The inverse of a false alarm, this is the percentage of time that actual speech is completely overlooked by the system and classified as non-speech.
The final DER is calculated by summing these three error percentages over the total audio duration. So, in a 100-second file with 5 seconds of speaker confusion, 2 seconds of false alarms, and 3 seconds of missed speech, the DER is 10%. Crucially, DER calculations typically include a 'forgiveness collar'-usually around 250 milliseconds at the start and end of speech segments-which prevents the system from being penalized for minor inaccuracies in timing boundaries.
Common Misconceptions about Speaker Diarization
As with any complex technology, several misconceptions have emerged around what speaker diarization is and what it can do. Clarifying these points is essential for setting realistic expectations when implementing speech AI solutions.
Misconception 1: Diarization is the same as Speaker Recognition
This is the most common point of confusion. Speaker recognition (or voice recognition) is the task of identifying a specific, known individual from their voice. It answers the question, ‘is this person John Smith?’. This requires a pre-existing voice sample or 'voiceprint' of John Smith to compare against. Diarization, on the other hand, requires no prior knowledge. It answers ‘who spoke when?’ by assigning generic labels like ‘Speaker 1’ and ‘Speaker 2’. While the two technologies can be combined (first diarize, then use recognition to replace generic labels with actual names), they are distinct processes. For a deeper explanation of this, our article on how voice recognition works provides more detail.
Misconception 2: Diarization Perfectly Handles Overlapping Speech
Handling overlapping speech, where two or more people talk at the same time, is one of the biggest challenges in diarization. Traditional cascaded systems that assign only one speaker to each time segment struggle immensely with this. While the audio segment may contain voices from two people, the system is forced to assign it to just one, leading to high Speaker Confusion Error. Modern end-to-end systems are improving at this, but perfect separation and attribution of overlapping speech remains an active area of research. No commercial system today can handle significant, extended periods of overlap flawlessly.
Misconception 3: You Need to Know the Number of Speakers in Advance
A common assumption is that you must tell the system how many speakers to look for. While some older clustering algorithms (like k-means) required this as an input, modern systems do not. Advanced clustering algorithms, such as spectral or agglomerative clustering, can automatically determine the most likely number of speakers directly from the distribution of the speaker embeddings. This makes the technology far more practical for real-world scenarios where the number of participants is unknown beforehand.
Real-World Applications and Use Cases
The practical applications of speaker diarization span numerous industries, transforming how organizations interact with and extract value from audio data. By adding speaker context to conversations, businesses can move from simple transcription to sophisticated conversational intelligence.
Industry | Application | Business Value |
|---|---|---|
Contact Centers | Agent vs. Customer Analysis | Monitors agent talk time, script adherence, and customer sentiment to improve quality assurance and training. |
Media & Entertainment | Content Indexing and Captioning | Automatically generates speaker-labeled subtitles and enables searching for content spoken by a specific person (e.g., an interviewer or guest). |
Healthcare | Clinical Documentation | Distinguishes between the doctor, patient, and family members in a consultation, ensuring accurate medical records and reducing administrative burden. |
Legal | Deposition and Courtroom Transcription | Creates an accurate, speaker-attributed record of legal proceedings, which is crucial for review, analysis, and evidence. |
Enterprise | Meeting Intelligence | Analyzes who spoke about which topics in a meeting, tracks participation, and helps automate the generation of meeting summaries and action items. |
In each of these cases, diarization is not just an add-on; it is the enabling technology. For instance, in real-time speech analytics, diarization allows a system to flag a manager in real-time if a customer's sentiment turns negative during an interaction with a specific agent. In legal settings, an accurate, diarized transcript is a non-negotiable requirement. The technology provides the fundamental structure upon which these advanced applications are built.
The Future of Diarization: Challenges and Opportunities
The field of speaker diarization is evolving rapidly, driven by advancements in deep learning and the increasing demand for conversational AI. While today's systems are remarkably capable, several key challenges remain that define the roadmap for future research and development.
Key areas of active research include:
Robust Overlap Handling: As mentioned, this remains the most significant challenge. Future systems will likely integrate multi-channel audio from microphone arrays or use more sophisticated E2E models to better separate and attribute simultaneous speech.
Online, Low-Latency Diarization: Most high-accuracy systems today operate offline, processing an entire audio file at once. The next frontier is performing highly accurate diarization in real-time with minimal delay, which is essential for live captioning and real-time agent assist applications.
Handling Diverse Acoustic Conditions: Performance can still degrade significantly in 'in-the-wild' scenarios with background noise, reverberation (echo), and far-field microphones. Developing models that are resilient to these variations is a major focus.
Code-Switching and Multilingual Diarization: In global conversations, speakers often switch between languages (code-switching). Diarization systems need to become more robust to these shifts, which can alter a speaker's vocal characteristics and confuse embedding models.
Integration with ASR: Tightly coupling the diarization process with the Automatic Speech Recognition (ASR) model itself is a promising direction. An integrated system could use linguistic cues from the transcript (e.g., a person responding to a question) to help inform speaker turn boundaries, creating a synergistic loop. This is a key part of understanding ASR technology at a deeper level.
As these challenges are addressed, speaker diarization will become an even more invisible but essential part of our digital interactions. It will move from a specialized tool for analysts to a standard feature in everything from video conferencing platforms to in-car voice assistants, making our interactions with technology more natural and context-aware.
Key Takeaways
Speaker diarization is a fundamental technology for making sense of multi-speaker audio. As you build or integrate speech AI, remember these essential points:
Core Function: Diarization answers 'who spoke when?' by segmenting audio and clustering speakers without prior knowledge of their identities.
Enables Analysis: It transforms a simple transcript into a structured dialogue, enabling speaker-specific analytics like talk time, sentiment analysis, and topic attribution.
Technical Pipeline: The process typically involves Voice Activity Detection (VAD), segmentation, speaker embedding extraction, and clustering.
Primary Metric: Performance is measured by Diarization Error Rate (DER), which quantifies the percentage of time with incorrect speaker labels.
Distinct from Recognition: Diarization assigns generic labels (Speaker 1, 2), while speaker recognition identifies specific, known individuals (Alice, Bob).
What is the main difference between diarization and transcription?
Does diarization work for any language?
How many speakers can a diarization system handle?
What is Diarization Error Rate (DER)?
Can diarization identify speakers by their real names?