Lightning V3 TTS: Next-Gen Conversational AI Voice Model

Explore Smallest.ai's Lightning V3, a breakthrough text-to-speech model for highly natural and responsive voice agents. Read the full announcement.
Lightning V3.1 is our most natural-sounding TTS model to date, based on neutral third-party and customer evaluation. It supports 15 languages: English, Spanish, French, Italian, Dutch, Swedish, Portuguese, German, Hindi, Tamil, Kannada, Telugu, Malayalam, Marathi, and Gujarati, with automatic language detection and mid-sentence language switching.
Lightning V3.2 extends the V3 architecture with instruction-following capability. The model accepts explicit directives for emotional register, pitch variation, and volume control, including low-energy output states like whispering that are difficult to achieve through prosody modeling alone.
Lightning V3 is available today on our pay-as-you-go plan. You can also get started for free today.
Speech Fidelity Is Not the Same as Conversational Naturalness
The TTS field has spent years solving a specific and well-defined problem: converting text into intelligible audio. By that measure, it has largely succeeded. Leading models have converged on pronunciation accuracy, low word error rates, and high audio fidelity. Intelligibility is now table stakes.
The problem is that optimizing for how well a voice reads text is the wrong objective if the application is a voice agent.
In conversational generation, the model does not receive the full utterance before synthesis begins. It produces audio in real-time chunks as responses stream in, with incomplete context at every step. Naturalness degrades in ways that end-to-end evaluation does not surface. And more fundamentally, a voice that reads beautifully can still be genuinely unpleasant to hold a conversation with.
A conversational voice has to do four things simultaneously:
To sound like it is thinking. Natural speech contains micro-variations in rhythm, pacing, and emphasis that signal active cognition. A metronomically consistent voice does not sound calm; it sounds scripted. Speech cadence is not arbitrary. It reflects the cognitive load of producing a thought in real time. Complex ideas generate longer pauses, irregular pacing, and more varied emphasis. Cadence is not a stylistic feature. It is a cognitive signal. [1]
To sound like it is listening. Intonation in conversation is reactive. A clarification carries a different prosodic profile than an opening statement. A response to a frustrated customer sounds different from a first-turn greeting. Prosody is how speech signals intent, and in conversation, intent changes with every turn.
To handle the way people actually speak. In real multilingual conversations, language does not switch at clean paragraph boundaries. It switches mid-sentence, at the word level, the way thought actually moves. A voice agent serving Hinglish or Spanglish speakers encounters this constantly. It is not an edge case.
To keep the user engaged. This is the most important, least quantifiable, and hardest problem to solve. A robotic voice does not just sound unpleasant; it creates friction. The evidence here is not just anecdotal. Research consistently documents the cost of getting this wrong. Vonage found that 51% of U.S. consumers had abandoned a business altogether after reaching an IVR menu. The voice is not a UX detail layered on top of the product experience. In many deployment contexts, it is the core experience. [2]
Lightning V3 Sets a New SOTA for Conversational TTS
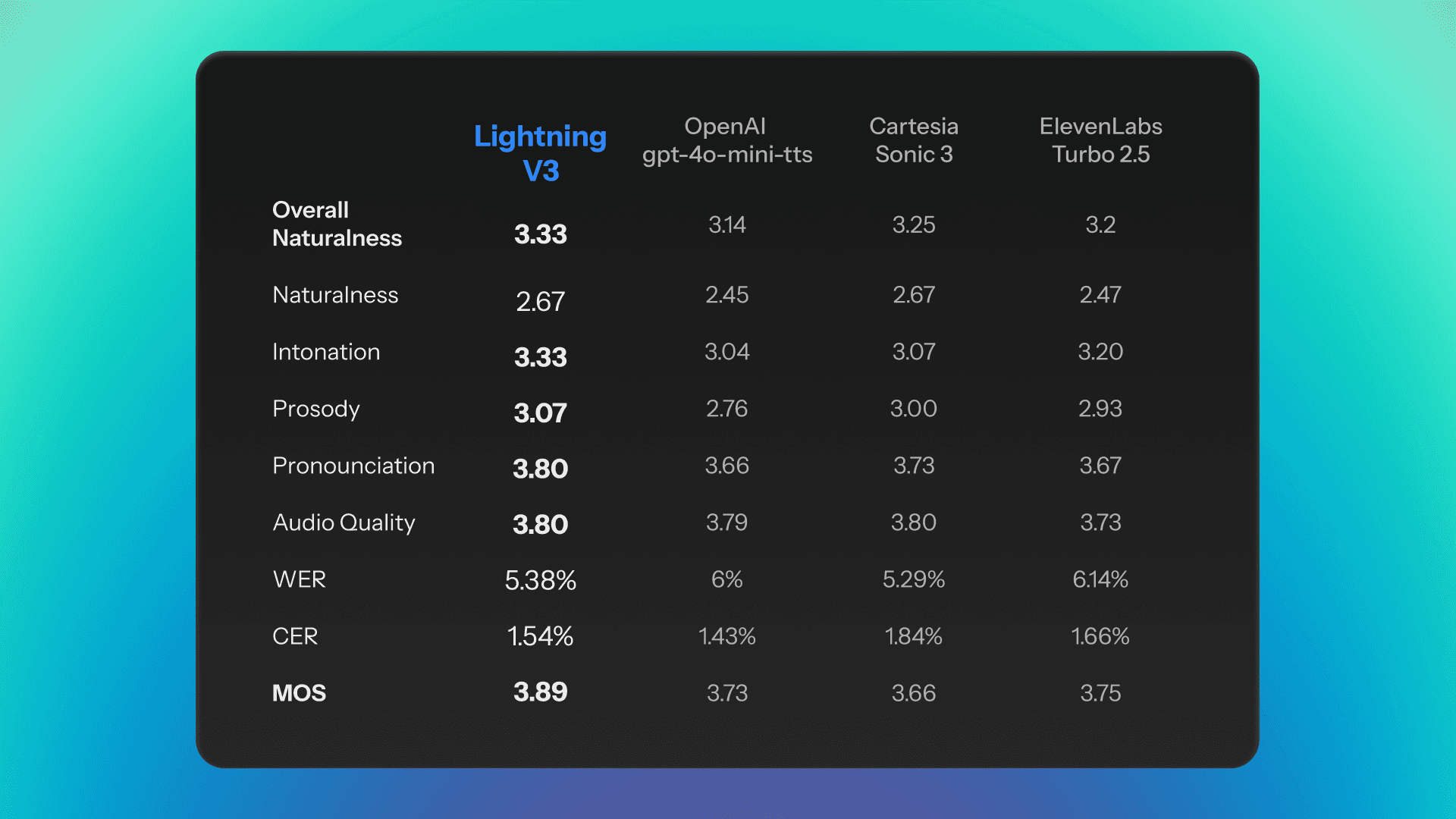
Evaluation conducted in end-to-end utterance synthesis systematically overstates real-world performance for streaming applications. Our evaluation was conducted specifically in the conversational generation setting. The test set comprised samples from the Seed-TTS evaluation corpus, scored using an LLM-as-judge framework.
The evaluation code used for this benchmark is available at this link for replication.
Lightning V3 leads on MOS at 3.89, and leads on intonation and prosody across all competitors. Those are not incidental wins. They are the specific dimensions the model was designed for.
Word Error Rate is the foundational measure of transcription fidelity. Lightning V3 achieves a WER of 5.38%, outperforming almost every competitor. For domain-specific terminology where out-of-distribution vocabulary degrades model confidence (proper nouns, medical nomenclature, brand identifiers), pronunciation dictionaries provide an override layer. Rather than relying on the model to infer correct pronunciation, these dictionaries hardcode the expected output, ensuring consistent accuracy on the vocabulary that matters most.
Against OpenAI gpt-4o-mini-tts, Lightning V3 achieves a comparative win rate of approximately 76% on overall naturalness. That number is real. It is also worth interrogating.
Set the scorecards aside and listen to the same audio clip from both models side by side.
In a neutral listening session, the speech quality is nearly impossible to tell apart. Change the listening context, the playback device, the evaluator's frame of reference, what they have been primed to notice, and the rankings shift. Change it again, and they shift again.
This is not noise in the data. It is the data. Naturalness is not a fixed property of the audio. It is a relationship between the audio and the person hearing it, shaped by context that no standardized evaluation can fully account for.
Which raises the question: if preference rankings move this much with context, what are TTS benchmarks actually measuring?
TTS Evals Are Dead, and We Need to Admit It
The scores above are structurally incomplete, not because the methodology is flawed, but because the metrics themselves have a ceiling the field has been slow to acknowledge.
MOS collapses an enormous range of perceptual experience into a single averaged number. The "opinion" in Mean Opinion Score is doing a lot of work. The score depends entirely on listener composition, question framing, and what "quality" means to a given rater. LLM-as-judge reduces some of the variance and operational cost of human panel evaluation, while still preserving sensitivity to prosodic and acoustic differences. However, the prompt given to the judge model is itself a form of question framing. Change the evaluation criteria, the reference description, or the scoring rubric, and the outputs shift. The variance moves from the rater pool to the prompt, not away from subjectivity entirely.
As you can see all 3 audios are almost entirely the same, save for the voice. Yet, Natalie has a score of 3.9 on MOS, Olivia 3.18 and Mia 2.94.
For years, TTS evaluation has organized itself around a familiar set of benchmarks: MOS for overall perceived quality, WER and CER for intelligibility, and dimensions like pronunciation, prosody, intonation, and audio quality for signal-level correctness. These metrics were built for a period when the dominant failures were obvious, when speech still sounded detectably synthetic.
The field has largely solved that problem. Intelligibility is no longer the frontier. And this is precisely where the evaluation framework breaks down. As systems cross the threshold from intelligible to natural-sounding, the benchmarks become less diagnostic. They can still confirm that a system is not failing. What they cannot do is tell you how far it has succeeded. What remains is a different and harder problem: not whether a voice sounds good under controlled evaluation conditions, but whether it sounds believable.
Expressiveness Is Not the Same as Naturalness
A quiet assumption in modern TTS is that increased expressiveness should make a voice feel more human. If a model widens its pitch range, adds stronger emotional contours, varies its pace, and delivers lines with more energy, that tends to be treated as progress. Up to a point, it is. But performing an emotion is not the same as having it.
Beyond that point, the relationship starts to break. A voice can become more expressive and less believable at the same time.
The new failure points are subtler than the old ones. A voice can be clear, polished, and highly animated, and still register as less natural than a quieter alternative. The problem is uniformity: these voices are too consistently expressive and too performative across turns. In isolation, that reads as impressive. Sustained across a conversation, it starts to feel rehearsed, far from the uneven, effortful texture of real human speech.
Rendering the surface cues of emotion is not the same as carrying a believable human state through speech. Human conversation is shaped by attention, memory, planning, breath, fatigue, and social context. The result is irregularity that is not random.
Spontaneous speech is not perfectly fluent. Typical speakers produce disfluencies at a rate of roughly 5 to 6 per 100 words, including filled pauses, silent pauses, prolongations, repetitions, and self-repairs. And below the level of overt disfluency, human listeners remain sensitive to much finer structure: where pauses fall, how timing stretches under planning load, and the small irregularities in phonation that natural voices carry but overly smoothed synthesis often suppresses.
This divergence showed up clearly in informal listening evaluations. "Natalie" scores higher on structured evaluation dimensions compared to competitors. "Olivia" scores lower. Listeners prefer Olivia.
The Most Natural Voice Is Often Your Own
Even the best pre-built voice has a ceiling. In our evaluations, a cloned voice consistently outperforms it.
When you clone a voice (currently available on Lightning V3.1), you are capturing the specific irregularity that makes a voice feel like a person. What cloning preserves is not just timbre, but irregularity: the timing, emphasis, and small imperfections that make a voice feel like a person rather than a performance.
Lightning V3.1 generate a production-grade replica from 5 to 15 seconds of audio.
No recording session, no fine-tuning pipeline. One short clip produces a voice that synthesizes speech across any of the 15 supported languages.
For teams building at scale, this is not a convenience feature. It is a fundamentally different way to think about voice as a product asset, because the clone preserves the natural irregularity of the source.
Conversation Is the Hardest Test, and It Unlocks Everything Else
If a voice holds up in conversation, it holds up everywhere. The naturalness that makes our TTS effective in a support call makes it equally effective for podcast, audiobook, and dubbing applications. Conversational generation is the most demanding acoustic context a TTS model can face: real-time synthesis, emotionally varied dialogue, unpredictable prosodic context, and incomplete information at every chunk boundary. A model designed for this setting has addressed the hardest version of every other use case.
Lightning V3 generates audio natively at 44,100 Hz, exceeding the Nyquist limit for the full audible speech frequency range. For bandwidth-constrained or telephony deployments, it downsamples cleanly to 8, 16, or 24 kHz.
Setting | Options |
Sample Rates | 8,000 / 16,000 / 24,000 / 44,100 Hz |
Output Formats | PCM, MP3, WAV, mulaw |
Speed Control | 0.5x to 2.0x |
Language Detection | Explicit (ISO 639-1) or auto-detect |
Deployment Modes | HTTP, SSE Streaming, WebSocket |
The model does not change based on deployment context. The output configuration does. A telephony IVR running on 8 kHz mulaw and a podcast tool rendering 44.1 kHz WAV are calling the same model.
Persona-Specific Evals Are the Need of the Hour
The challenge we are addressing is what we call communicative adequacy: not whether a voice sounds human, but whether it sounds like the right human for a specific role.
Voice AI now has to be evaluated against the persona it is designed to inhabit. A calm healthcare agent, a high-energy sales rep, and a measured financial advisor should not be judged against the same prosodic ideal. They are not trying to do the same job. Their acceptable pitch range, pause density, speech rate, boundary strength, breathiness, and disfluency profile differ because the communicative goal differs. A reassuring voice may need softness, restraint, and careful pause placement. An authoritative voice may need steadier pacing and lower pitch volatility. A persuasive voice may need more lift and energy, but only to the point where it still sounds human rather than overperformed.
A benchmark that rewards proximity to a population-average naturalness score will systematically penalize the deviations that make a voice appropriate for its context.
Context changes the score.
The field already has evidence that evaluation changes when context is introduced. The 2025 replicability paper argues directly that modern synthetic speech cannot be evaluated in a one-size-fits-all setup. The Blizzard Challenge 2025 report separately measured naturalness and appropriateness, and found significant differences between them for some systems.
That distinction matters. If the same sample receives materially different judgments when listeners are asked "how natural is this?" versus "how appropriate is this here?", then the benchmark is not measuring a stable property of the audio alone. It is measuring audio plus task fit. That is the doorway to persona-conditioned evaluation. [3][4]
In short, a model can be benchmarked generically, but a voice cannot. Models should still be evaluated for fidelity, robustness, controllability, and pronunciation. Voices should be designed and judged in context: for whether they fit the persona they are meant to inhabit, carry the right social signal, and feel believable in the moment they were built for.
Lightning V3.1 is now available on a pay-as-you-go model. You only pay for what you use. No upfront commitments, no seat licenses, no minimums. Whether you are prototyping a new voice agent, running millions of calls a month, or generating multilingual content for your channels, the pricing scales with you. Credits do not expire every month.
Go to app.smallest.ai to get started now or try our API at this link.
References
[1] https://pmc.ncbi.nlm.nih.gov/articles/PMC2131696/ (Prosodic Planning: Effects of Phrasal Length and Complexity on Pause Duration)
[2] https://www.vonage.com/about-us/newsroom/press-releases/Vonage-research-reveals-IVR-horror-costs-businesses-262-per-customer-each-year-09-26-2019/444cff58-7541-43bd-b08b-41d47951117d/ (Vonage research reveals IVR horror costs businesses $262 per customer each year)
[3] https://www.isca-archive.org/interspeech_2025/lemaguer25_interspeech.pdf (Enabling the replicability of speech synthesis perceptual evaluations)
[4] https://www.isca-archive.org/blizzard_2025/do25_blizzard.pdf (The Blizzard Challenge 2025)

