Audio to Text Converter for Call Centers: How to Batch Transcribe Recordings at Scale


Learn to build a scalable audio to text converter pipeline for call centers. Covers batch architecture, preprocessing noisy audio, diarization, and PII redaction.
Every call center is sitting on a backlog of recorded conversations that rarely gets used to its full value. Compliance checks, coaching, sentiment work, and dispute resolution all get easier when you can search and analyze what was said instead of scrubbing through audio. An audio to text converter built for enterprise workloads can process thousands of recordings asynchronously, turning raw calls into structured, searchable transcripts without staffing a transcription team.
The question isn’t whether speech-to-text exists; it’s whether it survives contact-center reality. Getting batch transcription right at scale means picking an architecture that won’t collapse under volume, dealing with the acoustic chaos of real calls, and wiring the output into the systems where it becomes operationally valuable. This piece breaks down the stack end to end: how recognition behaves in contact centers, how to design a pipeline that runs reliably, and what separates a production deployment from a demo that falls apart the first time the queue spikes.
What Makes Call Center Audio Different from Standard Transcription
Most general transcription tools are optimized for clean, single-speaker audio like podcasts, lectures, or dictation. Call center recordings are messier and less forgiving. You’re often working with two speakers on separate channels (or, in the worst case, a single mixed mono track), telephony codec artifacts, and background noise from open-plan floors. Then there’s vocabulary drift by industry: healthcare brings clinical terms, financial services brings product codes and regulatory language, and telecom support has its own shorthand that generic models rarely see often enough to learn properly.
Common failure factors include accents, background noise, and domain-specific terminology. In contact centers, those aren’t occasional problems; they’re the default state of the dataset. Any audio to text converter worth evaluating needs to prove itself on your recordings, not on pristine benchmarks. With models that haven’t been tuned for telephony and contact-center conditions, it’s not uncommon to see real-world word error rates land significantly worse than the numbers shown on clean test sets.
Real call center audio presents four compounding accuracy challenges that generic transcription models are not built to handle.
Batch vs. Real-Time Transcription: Choosing the Right Mode
Real-time transcription streams audio and returns text with low latency, often under 300 milliseconds. That’s the mode you want for live agent assist, where a prompt has to show up while the customer is still mid-sentence. Batch transcription works differently: you hand the system a pile of recorded files, it processes them asynchronously, and you pull the results when they’re ready. Most enterprise batch transcription APIs are designed to process large quantities of audio files in storage and return transcriptions asynchronously.
For most analytics and compliance work, batch is the right default. You’re not trying to steer a live conversation; you’re trying to understand what happened across ten thousand calls last week. Batch pipelines tend to be cheaper at scale, simpler to fan out horizontally, and more forgiving when you want heavier post-processing like diarization, sentiment tagging, or PII redaction. The tradeoff is timing: insights show up hours later, not seconds later. For QA, compliance, and trend analysis, that delay usually doesn’t matter.
How to Batch Transcribe Call Center Recordings: Step-by-Step Workflow
A reliable batch transcription setup starts before the ASR engine receives the audio. The goal is to move recordings from storage to searchable transcripts without losing speaker context, metadata, or compliance controls along the way.
1. Export call recordings from your contact center platform
Start by exporting recordings from your CRM, dialer, CCaaS platform, or call recording system. Each file should carry basic metadata such as call ID, agent ID, customer ID, queue, campaign, language, timestamp, and call duration. This metadata is important because the transcript is only useful if teams can trace it back to the right conversation, agent, customer, or workflow.
2. Normalize the audio format
Call recordings often come in different formats depending on the platform: WAV, MP3, FLAC, OGG, or older telephony formats like G.711. Before transcription, convert everything into a consistent format supported by your ASR provider. Many teams standardize files to 16kHz mono WAV or FLAC to reduce codec-related accuracy issues and make batch processing easier to manage.
3. Split dual-channel recordings when available
If the recording has separate channels for the agent and customer, preserve that separation. Splitting dual-channel audio before transcription usually gives cleaner speaker attribution than trying to separate voices from a single mixed track later. This is especially useful for QA, compliance scoring, sentiment analysis, and dispute resolution, where knowing who said what matters.
4. Submit files to ASR in batches
Once the files are prepared, submit them to the speech-to-text engine in controlled batches. Instead of sending every recording at once, queue jobs based on file size, priority, language, and available API limits. This helps avoid failed jobs, rate-limit issues, and processing delays when call volumes spike.
5. Store transcripts with call IDs and timestamps
The output should not be stored as plain text alone. Each transcript should include the original call ID, timestamps, speaker labels, confidence scores, language metadata, and processing status. This makes it easier to search transcripts, pull exact audio clips, audit transcription quality, and connect the transcript to CRM or QA systems.
6. Run diarization, redaction, and confidence checks
After transcription, apply post-processing. Speaker diarization separates agent and customer turns. PII redaction masks sensitive information such as card numbers, national ID numbers, dates of birth, and account details. Confidence checks help flag low-quality transcript sections for review instead of letting uncertain output flow directly into analytics.
7. Push transcripts into QA, BI, CRM, or compliance workflows
The final step is activation. Send clean transcripts into the systems where teams can use them: QA dashboards, compliance review queues, BI tools, CRM timelines, agent coaching platforms, or conversation intelligence layers. This is where batch transcription becomes more than a back-office process. It turns recorded calls into searchable, analyzable customer data that can support coaching, compliance, trend analysis, and operational decision-making.
Designing a Batch Transcription Pipeline That Holds Up Under Load
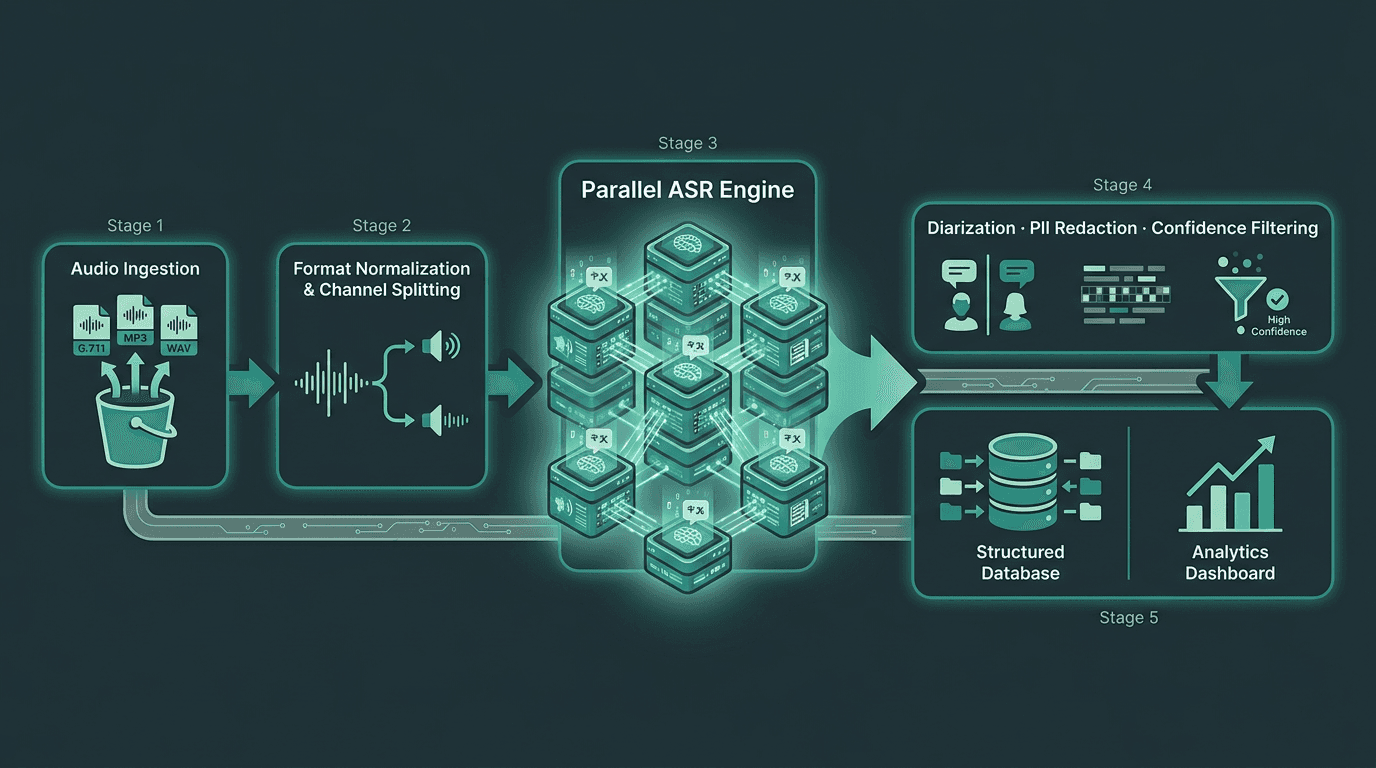
A production batch pipeline separates preprocessing, ASR, and post-processing into distinct, independently scalable stages.
Stage 1: Audio Ingestion and Preprocessing
Accuracy is often decided before the ASR engine even sees the file. Call recordings show up in whatever format your recording stack happens to emit: G.711 mu-law from older PBX setups, MP3 from cloud platforms, stereo WAV where agent and customer sit on separate channels. Pick a house format and normalize everything (16kHz mono WAV or FLAC is broadly supported) before you submit jobs. If you have dual-channel audio, split it up front instead of mixing it down. Transcribing each channel separately and then merging with timestamps typically yields far cleaner diarization than trying to untangle speakers from a single mixed signal afterward.
Stage 2: Parallel ASR Processing
Your ASR layer sets the clock: it determines whether batch runs finish in two hours or drag into the next day. Most enterprise speech-to-text APIs let you submit jobs concurrently and tune parallelism, though the real ceiling depends on the provider and your plan. A practical way to compare throughput is real-time factor (RTF): 0.1 RTF means an hour of audio transcribes in about six minutes. If you’re processing 50,000 calls per month at roughly four minutes each, you need sustained capacity that doesn’t turn into an ever-growing queue. Being fluent in the mechanics of Automatic Speech Recognition (ASR) for call centers helps you pressure-test a vendor’s performance claims before you commit.
Stage 3: Post-Processing and Enrichment
Raw transcripts are only the start. Post-processing is where you turn text into something your QA, analytics, and compliance systems can actually use:
Speaker diarization: Separates turns into agent vs. customer. This is foundational for sentiment and compliance scoring.
PII redaction: Masks credit card numbers, social security numbers, and other sensitive fields before anything lands in your warehouse.
Custom vocabulary application: Fixes the terms base models routinely mangle (product names, internal codes, regulatory language).
Confidence filtering: Routes low-confidence segments to human review instead of polluting downstream analytics with guesses.
Timestamp alignment: Anchors words back to the audio timeline so you can pull clips for coaching or dispute workflows.
Handling the Hard Cases: Accents, Noise, and Code-Switching
Most batch transcription projects don’t fail loudly; they fail in the margins. The “normal” calls look fine, and then accuracy collapses on the long tail, the calls with heavy accents, the mobile recordings with wind noise, the rapid-fire complaints, the bilingual conversations that flip languages mid-thought. If you’re supporting a global customer base, you should assume multilingual audio and code-switching are routine, not rare. The guide on handling multilingual and noisy audio goes deeper on tactics, but the big architectural fork is simple: does your ASR engine reliably detect language on its own, or do you need to specify it per file?
Automatic language ID costs time and, on short utterances or strongly accented speech, it can guess wrong. If your routing or IVR already knows which language queue a call hit, treat that as first-class metadata and pass it into the transcription job. You’ll usually get better accuracy at lower cost than asking the model to infer language from scratch. On the noise side, the most dependable wins come early: apply noise suppression during preprocessing rather than hoping the recognizer will power through. Models trained on cleaner audio degrade quickly on noisy input, and post-processing can’t reconstruct words that were never recognized correctly in the first place.
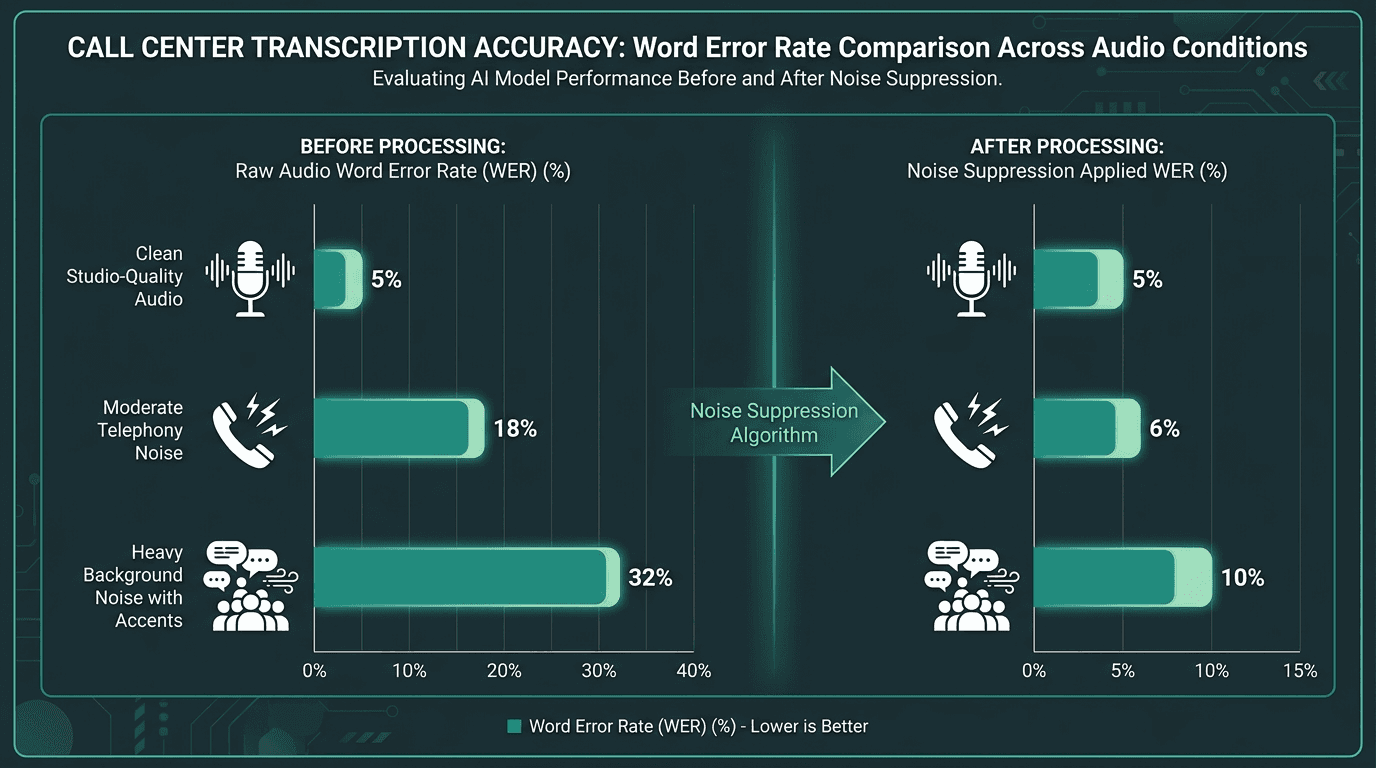
Noise suppression at the preprocessing stage consistently narrows the accuracy gap between clean and degraded call audio.
Connecting Transcripts to Downstream Business Value
A transcript that lives and dies in a storage bucket is just another artifact. Value shows up when transcripts feed an analysis layer that teams actually rely on. The reason is straightforward: recordings contain durable signals about intent, agent performance, product friction, and compliance exposure. Transcription is what makes those signals queryable at scale.
The fastest payoffs tend to come from call center QA and conversation analytics, automated checks for script adherence and compliance, and sentiment trend tracking across large volumes of calls. Once transcripts are dependable, summarization becomes a practical layer on top, which can lead to significant reductions in post-call wrap-up time. Broader AI integration can also reduce average handle time via tools like real-time transcription and automated suggestions. For stakeholders who need the finance story, the ROI of AI in call centers helps put those improvements into a budget frame.
What Most Teams Get Wrong When Evaluating Audio to Text Converters
Mistake one: testing on the wrong calls. A proof-of-concept built on a small set of clean, “representative” recordings almost always looks great. Production doesn’t. The long tail (heavy accents, wind noise on mobile, fast emotional speech) will drag accuracy down and erode trust in whatever analytics you build on top. The fix is boring but effective: evaluate on a stratified sample that intentionally over-indexes on your hardest audio, not your easiest.
Mistake two: treating per-minute pricing as the whole cost story. API rates are easy to compare; total cost of ownership is not. You still pay for preprocessing compute, storage for raw audio and transcripts, engineering time to keep the pipeline healthy, and human review for low-confidence segments. In practice, a provider that charges a bit more per minute but delivers higher accuracy and stronger post-processing can end up cheaper overall than a low-rate option that forces you to build compensating layers. Strong call center quality monitoring depends on transcript quality; once errors enter the system, they cascade into scoring and reporting.
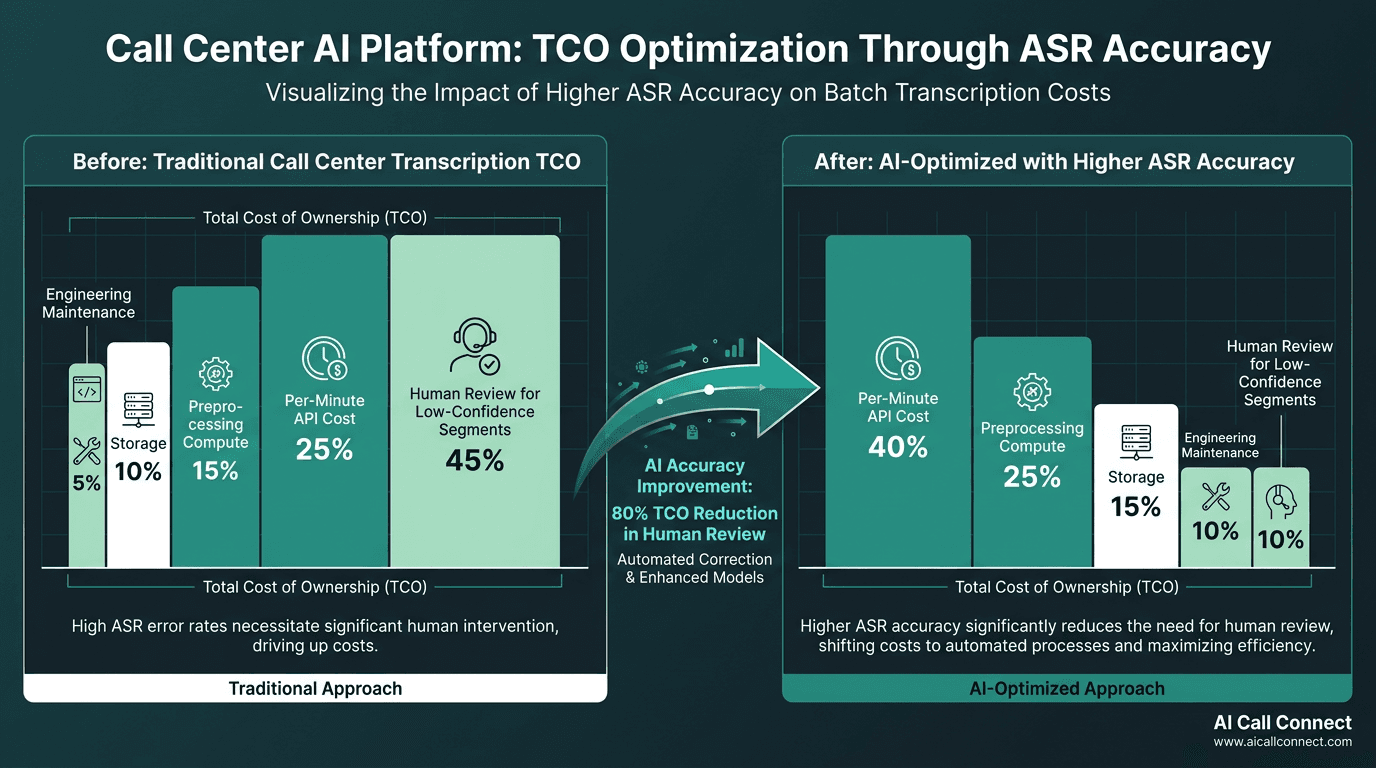
Higher accuracy at the ASR layer reduces the human review burden that often dominates total pipeline cost.
Advanced Considerations for Production Deployments
After the first version is running, a handful of decisions start to dominate outcomes. Language model adaptation is the highest-leverage knob you can turn. Most enterprise ASR providers support vocabulary lists or domain fine-tuning using your own transcribed calls. Even a relatively small adaptation set can significantly cut word error rates on domain terminology versus a base model. That’s where you usually feel it most: product names, internal identifiers, and regulatory terms that are common in your calls and rare in general training data.
Reliability engineering matters just as much as model quality. Batch jobs fail; files arrive corrupted; rate limits happen. A production pipeline should persist job state, retry with exponential backoff, and surface failures loudly instead of quietly skipping calls. Dropping even a small slice of recordings can skew QA metrics and compliance reporting in ways that are hard to spot until an audit forces the issue. Put observability in early, before the system is considered “done.” The broader view in how AI is transforming call center operations is a useful reminder: transcription isn’t a feature you bolt on; it’s infrastructure, and it deserves the same operational discipline as any other data pipeline.
Key Takeaways and Next Steps
The essentials for anyone building or evaluating a batch transcription system for call center audio:
Evaluate accuracy on your hardest audio, not your cleanest. Benchmark word error rate on a stratified sample that includes noisy, accented, and domain-specific calls.
Preprocess before you transcribe. Channel splitting, format normalization, and noise suppression at ingestion improve accuracy more reliably than post-processing corrections.
Build post-processing as a separate stage. Diarization, PII redaction, and confidence filtering belong in their own layer, not mixed into the ASR job.
Measure total cost of ownership, not just per-minute pricing. Engineering time, storage, and human review costs often exceed API costs at scale.
Adapt your language model to your domain. Custom vocabulary and fine-tuning on your own audio are the highest-ROI investments once the base pipeline is stable.
Instrument everything. Job state tracking, retry logic, and accuracy monitoring are not optional in a production system.
Contact center analytics is growing quickly because companies are finally treating recorded conversations as usable data, not just an archive. That shift starts with transcription that’s accurate, scalable, and operationally reliable. Smallest.ai's Pulse is built around that workload: speech-to-text tuned for the acoustic constraints of telephony, with the throughput and post-processing support production deployments demand. If you’re comparing audio to text converters for a contact center, Pulse is a sensible place to start when “works on real calls” matters more than just theoretical benchmark performance.
How accurate is batch transcription on real call center audio?
What audio formats does a batch transcription system typically support?
How does speaker diarization work in a call center context?
What is the difference between batch transcription and real-time transcription for call centers?
How do I handle PII in call center transcripts?

