

Learn how to build speech-to-text pipelines for call center QA and conversation analytics at scale. Covers accuracy, real-time vs batch, cost, and compliance.
Speech to text has become the operational foundation of how contact centers understand what actually happens on their calls. Not summaries, not agent notes, not sampled recordings reviewed by a QA team of five people covering ten thousand calls a week. The actual words, in sequence, at scale, available for analysis within seconds of a call ending or even while it is still in progress.
This guide is written for QA leads, contact center technology architects, and product teams building conversation intelligence platforms. By the end, you will understand how transcription pipelines are structured for call center environments, what separates production-grade speech recognition from demo-grade, how to instrument conversation analytics on top of transcripts, and what to watch out for when you move from pilot to full deployment. For a broader foundation, a complete guide to speech-to-text AI is a useful starting point before going further here.
Why call centers are the highest-stakes environment for speech recognition
Despite the rise of chat, email, and self-service portals, 76% of consumers still prefer using the phone to contact customer support. That preference creates a data problem. Voice is the richest channel and the hardest to analyze at scale. A contact center handling 50,000 calls per day generates more unstructured data than most analytics teams can process manually.
Traditional QA approaches sample somewhere between 1% and 5% of calls. A supervisor listens, scores a rubric, and the rest of the calls disappear into storage. This means 95% or more of customer interactions never get reviewed. Compliance risks go undetected. Coaching opportunities are missed. Trends in customer sentiment are invisible until they show up in churn data weeks later.
Gartner predicts that by 2026, conversational AI will reduce agent labor costs in contact centers by $80 billion. That number is not driven by replacing agents. It is driven by making every agent interaction measurable, coachable, and improvable. Speech transcription is the first step in that chain. Without accurate, structured text output from voice calls, none of the downstream analytics, scoring, or automation is possible.
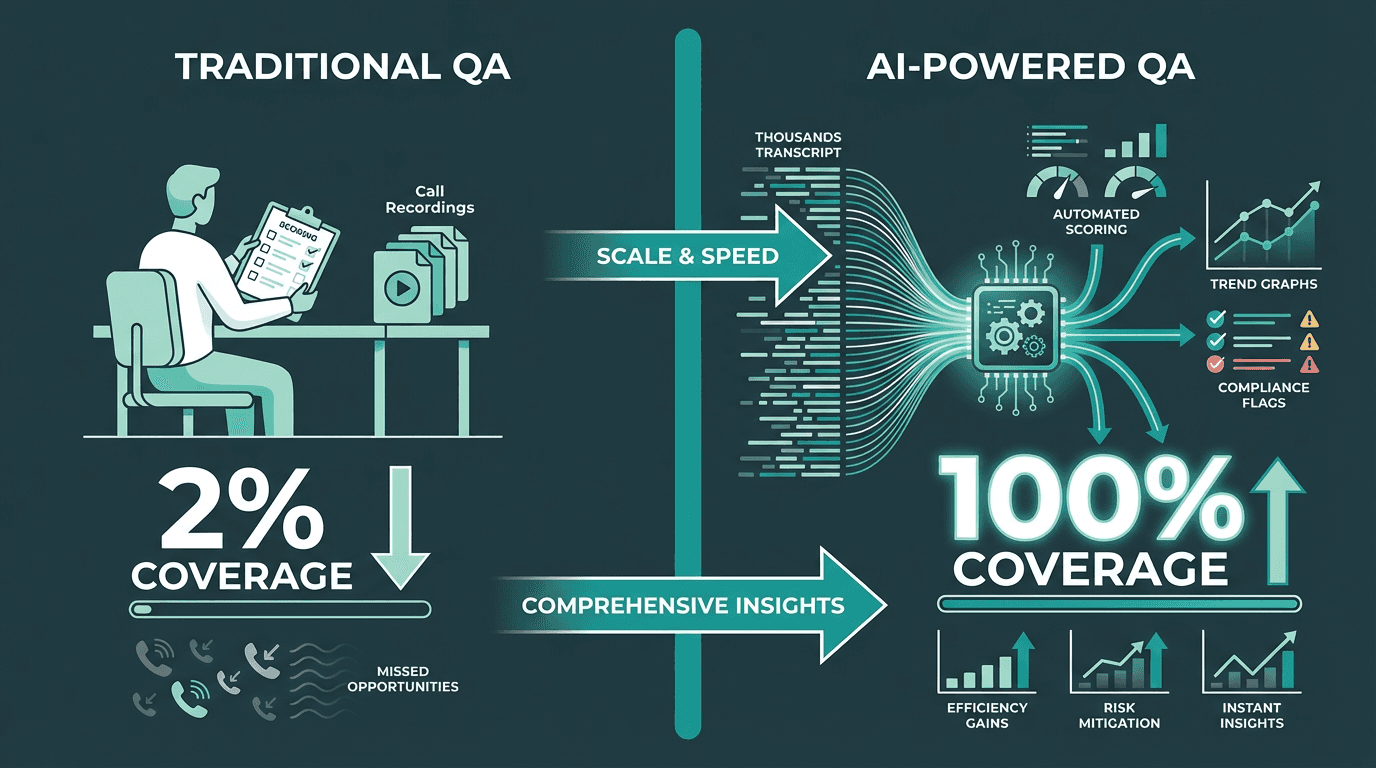
Manual QA covers a fraction of calls. Automated transcription-based QA covers every interaction.
How speech to text pipelines are structured for call center environments
A call center transcription pipeline is not a single API call. It is a sequence of processing stages, each of which introduces latency, error, or cost if not handled correctly. Understanding how speech-to-text AI works at the model level helps when you need to diagnose why a pipeline is producing poor output in specific conditions.
Audio ingestion and channel separation
Most telephony systems deliver audio in one of two formats: dual-channel stereo (agent on one channel, customer on the other) or mixed mono (both speakers on a single track). Dual-channel is strongly preferable. When agent and customer audio are separated at the source, speaker diarization becomes trivial and accuracy improves because the model is not trying to separate overlapping speech. If your telephony stack delivers mono, you will need a diarization step that uses acoustic features to assign speaker labels, which adds latency and introduces errors on cross-talk segments.
Batch versus real-time transcription
Post-call QA workflows can use batch transcription, where audio is processed after the call ends. This allows higher accuracy models to run without latency constraints. Real-time use cases, such as agent assist, live compliance monitoring, or supervisor alerts, require streaming transcription with sub-second word latency. The two modes have different infrastructure requirements and different accuracy profiles. Real-time speech-to-text is worth understanding separately before committing to a real-time architecture, because the engineering complexity is significantly higher.
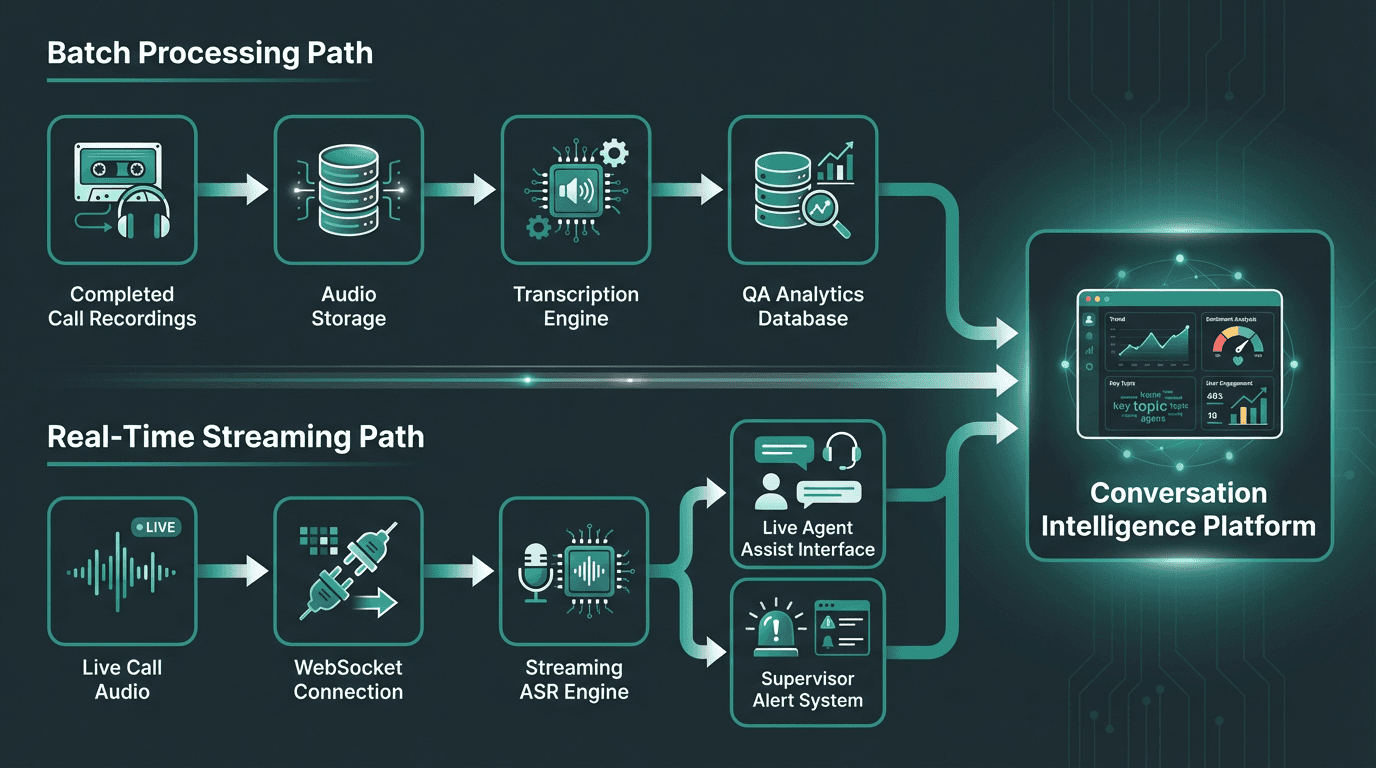
Batch and real-time pipelines serve different QA use cases and require different infrastructure trade-offs.
What actually determines speech to text accuracy in contact center audio
Word error rate (WER) is the standard benchmark for speech recognition accuracy, but it is a misleading metric for call center applications if taken at face value. A model with 8% WER on a clean podcast corpus might land at 18% WER on telephony audio compressed at 8kHz, with background noise, strong accents, and domain-specific vocabulary layered on top. That gap between benchmark performance and production performance is where most contact center deployments actually run into trouble, and it tends to surface only after go-live.
The factors that matter most in practice are acoustic conditions (codec quality, background noise, headset type), speaker diversity (accents, speaking rates, emotional states), and domain vocabulary (product names, internal jargon, regulatory terminology). A general-purpose model trained on clean speech will systematically misrecognize your product names and compliance phrases. Those are precisely the terms your QA process cares about most, which means errors concentrate exactly where they do the most damage. Custom vocabulary injection or domain-adapted models are not optional for serious deployments. For a structured evaluation of how leading models perform on these dimensions, evaluating the best speech-to-text AI covers accuracy and latency benchmarks in detail.
Building conversation analytics on top of transcripts
A transcript is raw material. Conversation analytics is what you build on top of it. The global speech-to-text API market was valued at $4.55 billion in 2025 and is projected to reach $5.36 billion in 2026, with contact centers expected to account for 28% of real-time solution revenue. That investment is not going into transcription alone. It is going into the analytics layer.
Core analytics capabilities built on call transcripts:
Automated QA scoring: structured rubrics (greeting compliance, empathy language, resolution confirmation) evaluated against every transcript rather than a sampled subset
Topic and intent classification: categorizing calls by reason for contact, product area, or escalation trigger using NLP classifiers trained on your transcript history
Sentiment analysis: tracking emotional trajectory through a call, identifying moments where customer sentiment shifts negative
Compliance monitoring: flagging required disclosures, prohibited phrases, or regulatory language against a defined checklist
Talk ratio and silence detection: measuring agent-to-customer speaking balance, identifying long silences that indicate confusion or hold time
Keyword and phrase spotting: alerting supervisors in real time when specific terms appear, such as competitor names, cancellation intent, or escalation language
McKinsey research found that organizations using predictive analytics in contact centers can see up to a 30% improvement in workforce efficiency. Getting there requires structured transcript data you can actually trust. When transcription accuracy is low, the classifiers and scoring models built on top start producing unreliable outputs, and once reviewers lose confidence in the system, adoption stalls.
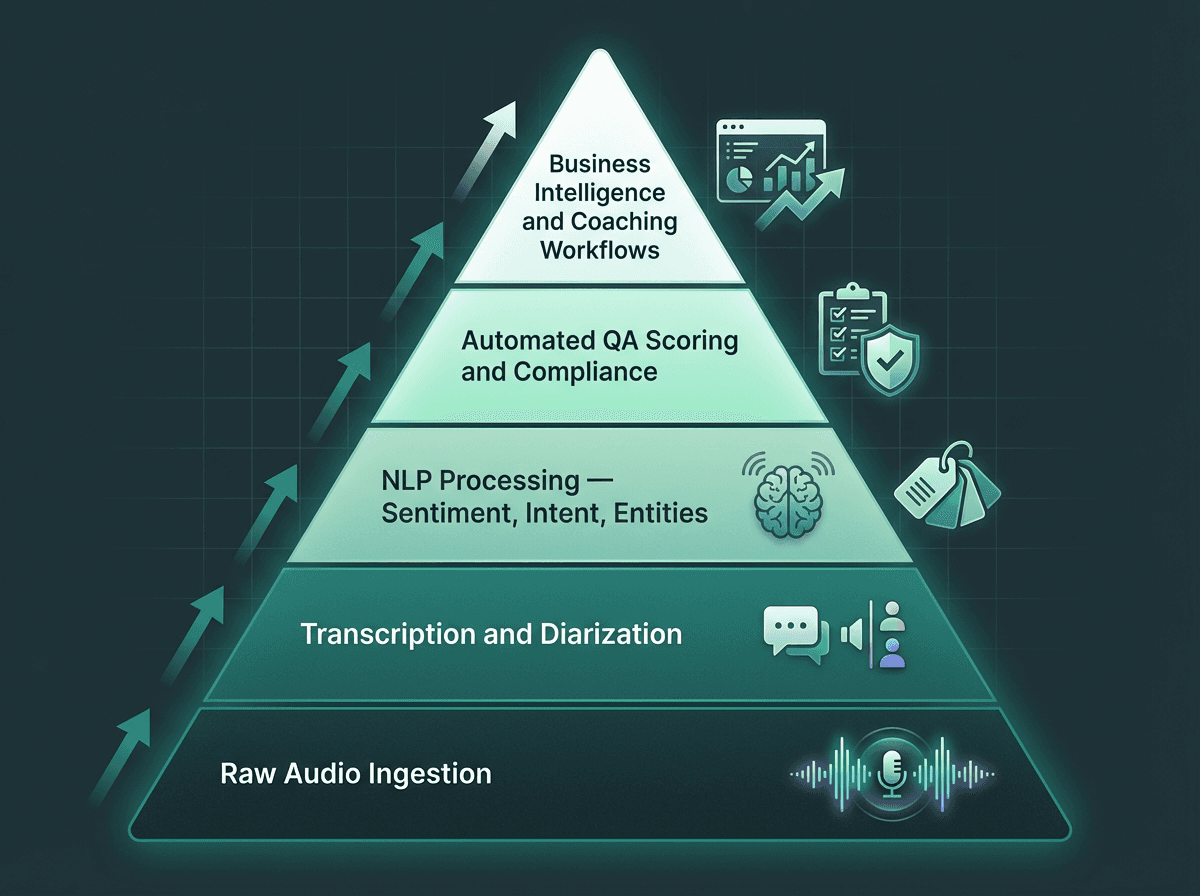
Conversation intelligence is built in layers. Transcription quality at the base determines the reliability of every layer above it.
Scaling from pilot to production: what most teams underestimate
A pilot running on 500 calls per day feels nothing like a system processing 50,000 calls per day. The failure modes are different, the cost structure changes, and the edge cases that were rare in the pilot become daily occurrences at scale. This is not a hypothetical. It comes up in nearly every production deployment of any real size.
Concurrency and throughput planning
Batch transcription workloads are often bursty. If your contact center peaks between 9am and 1pm, your transcription queue will spike at call end times. Providers that charge per minute of audio processed may throttle concurrent requests, creating backlogs that delay QA workflows. Understand your provider's concurrency limits before signing a contract. For teams evaluating API options, best speech-to-text APIs for voice agents includes concurrency and throughput considerations alongside accuracy metrics.
Cost modeling at scale
At 50,000 calls per day averaging four minutes each, you are processing 200,000 minutes of audio daily. Pricing differences of even $0.002 per minute compound to significant monthly costs. Most providers offer per-minute, per-hour, or volume-tiered pricing. Some offer flat-rate enterprise agreements. Different pricing structures and what to negotiate for at volume vary significantly between providers. Model your costs before committing to any agreement. For a breakdown of per-minute, volume-tiered, and enterprise flat-rate pricing structures, see our speech-to-text API pricing guide.
Data residency and compliance
Call recordings contain personally identifiable information, financial data, and in many jurisdictions, protected health information. Your transcription provider's data handling practices, storage policies, and regional processing locations are compliance requirements, not preferences. Confirm whether audio is retained after transcription, whether transcripts are used for model training, and whether processing can be restricted to specific geographic regions.
One area teams often overlook until late in the procurement process: whether the provider's data processing agreements are compatible with your existing regulatory obligations, particularly if you operate across multiple jurisdictions with different retention rules. Getting legal review involved early saves significant rework later.
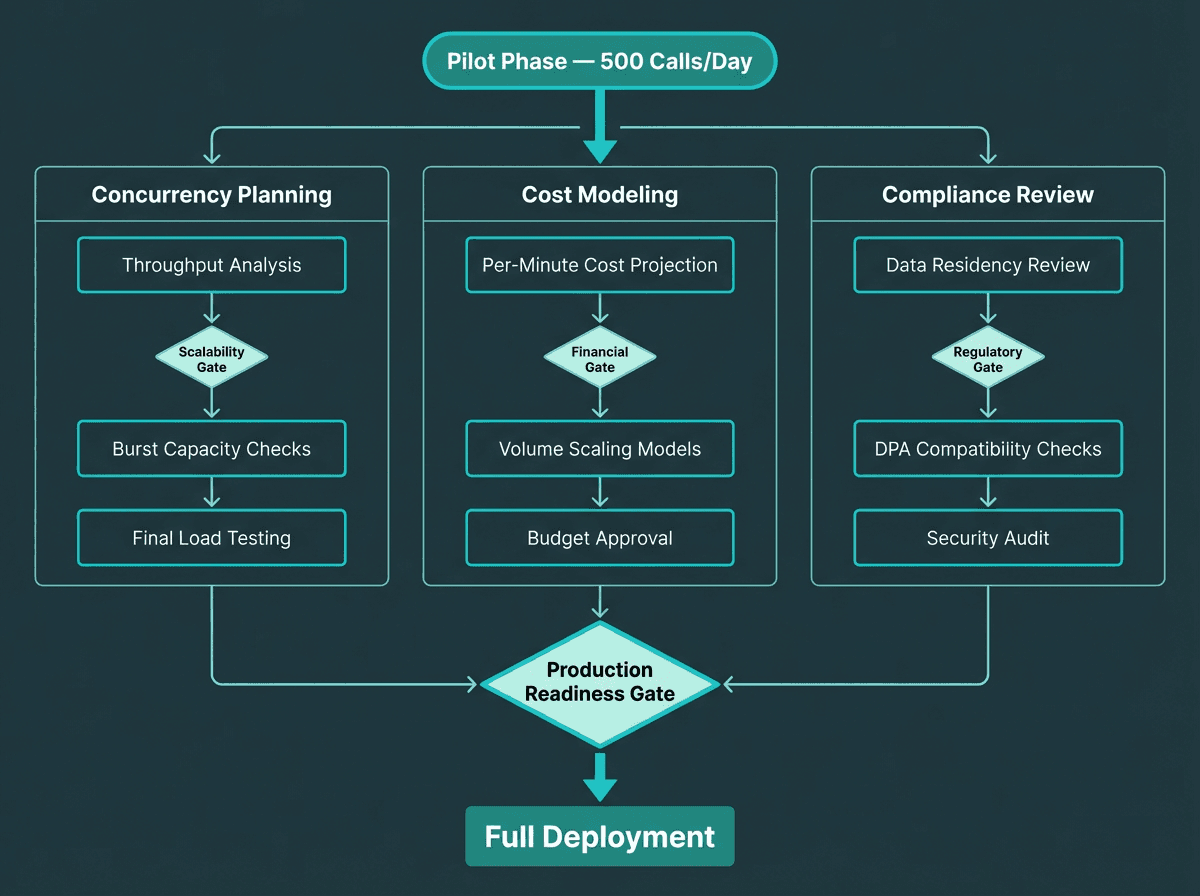
Production deployments surface failure modes that pilots never encounter. Plan for scale before you need it.
Advanced considerations: multilingual support, custom models, and feedback loops
Global contact centers handle calls in dozens of languages and regional dialects. Most off-the-shelf speech recognition models perform well in US English and drop significantly in accuracy for accented English, Spanish, French, or less-resourced languages. If your agent population or customer base spans multiple languages, test your chosen model against real audio samples from each language variant before committing to a vendor. Benchmark word error rate separately per language, not as an aggregate. Aggregate WER numbers can mask a model that performs well in English but poorly in every other language your customers actually speak.
Custom acoustic models trained on your specific audio conditions and domain vocabulary represent a meaningful accuracy improvement for high-volume deployments. The Stanford NLP Group's research on speech recognition illustrates how acoustic modeling, pronunciation dictionaries, and language model adaptation interact to produce domain-specific accuracy gains. For most contact centers, custom vocabulary injection (adding product names, agent names, and regulatory phrases to the recognition vocabulary) delivers 60-70% of the benefit of full custom model training at a fraction of the cost and time. It is usually the right place to start.
The feedback loop is the most underused capability in mature deployments. When QA reviewers correct transcript errors or override automated scores, that correction data is valuable training signal that most teams simply discard. Build a process to capture reviewer corrections, route them back to your model provider or fine-tuning pipeline, and measure accuracy improvement over time. Deployments that treat transcription as a static vendor service tend to plateau. The ones that treat it as a system that improves with use compound their accuracy advantage over time, which matters more the longer you run at scale.
Treating transcription as a learning system rather than a static service is what separates average deployments from excellent ones.
Key takeaways and next steps
Speech to text is not a commodity in call center environments. The difference between a model that performs at 92% accuracy on your audio and one that performs at 82% is the difference between a QA system your team trusts and one they work around. Accuracy on your specific audio conditions, domain vocabulary support, concurrency at scale, and data compliance are the four dimensions that determine whether a deployment succeeds. Most teams that struggle in production underinvested in evaluating at least one of them.
Actionable next steps for teams evaluating or scaling a deployment:
Collect 200-500 representative call recordings across your language variants, audio conditions, and call types before evaluating any vendor
Run head-to-head WER benchmarks on your own audio, not published benchmarks on standard test sets
Model your cost at full production volume before signing any agreement, including burst concurrency scenarios
Confirm data residency and audio retention policies in writing as part of vendor due diligence
Start with custom vocabulary injection before investing in full model fine-tuning; measure the accuracy delta first
Build a reviewer correction capture workflow from day one so you have training data when you need it
Revisit your accuracy benchmarks every quarter, especially after call volume grows or your product vocabulary changes
The contact centers that will see the $80 billion in labor cost reduction Gartner projects are not the ones that simply deployed transcription and moved on. They are the ones that built analytics, coaching, and automation on top of accurate, reliable speech-to-text at scale, and kept improving it. The technology is available to any team willing to implement it properly. Pulse STT by Smallest AI is built specifically for this intersection: sub-70ms streaming latency, speaker diarization, and accuracy across 30+ languages that holds up on telephony audio — the conditions that break general-purpose models in production call center environments. Teams that get all four dimensions right from the start spend their engineering effort on analytics and coaching, not chasing transcription errors.
What word error rate should I target for call center QA applications?
Is real-time transcription necessary for call center QA, or is post-call batch processing sufficient?
How do I handle calls in multiple languages across a global contact center?
What is speaker diarization and why does it matter for conversation analytics?
How should I think about the cost of speech-to-text at contact center scale?

