Speech-to-Text for Multilingual Contact Centers: Handling Accents, Code-Switching, and Noisy Audio


A technical guide to speech to text in multilingual contact centers: handling accents, code-switching, and noisy audio in production ASR pipelines.
Speech to text in a contact center is not the same problem as speech to text in a podcast studio. The audio is messier, the speakers are more diverse, and the stakes are higher. A missed word in a transcription is not just a typo. It can mean a misrouted call, a failed compliance check, or an agent who never got the context they needed to help a customer.
This guide is written for engineers, product managers, and contact center architects who are evaluating or deploying ASR in environments where speakers switch languages mid-sentence, carry regional accents, and call from noisy locations. By the end, you will understand the specific technical failure modes that affect multilingual ASR, what to look for in a speech recognition system, and how to configure your pipeline to handle real-world conditions. The global speech-to-text API market was valued at $4.55 billion in 2025 and is projected to reach $5.36 billion in 2026 (The Business Research Company, 2026), so the infrastructure decisions you make now will matter for a long time.
What makes contact center audio uniquely difficult for ASR
Most ASR benchmarks are measured on clean, single-speaker, single-language audio. Contact centers violate every one of those assumptions. You have telephony compression artifacts from codecs like G.711 narrowing the audio to 300-3400 Hz. You have background noise from open-plan floors, call center hubs in busy cities, or customers calling from cars and kitchens. You have agents and customers who interrupt each other. And you have speakers whose first language is not the language of the product they are supporting.
The research is blunt about the performance gap. A Stanford University study found that major speech recognition systems produced error rates nearly twice as high for Black speakers (35%) compared to white speakers (19%), illustrating how demographic and accent diversity directly affects transcription quality. Studies on noisy environments show that word error rates can double when the signal-to-noise ratio drops below 10 decibels (Ko et al., IEEE, 2025). These are not edge cases in a contact center. They are the baseline.
Understanding how speech-to-text AI works at a technical level helps here. Most modern ASR systems use end-to-end neural architectures trained on large corpora. The problem is that training data skews toward dominant language variants and clean recording conditions. When the acoustic input deviates from what the model saw during training, error rates climb fast.
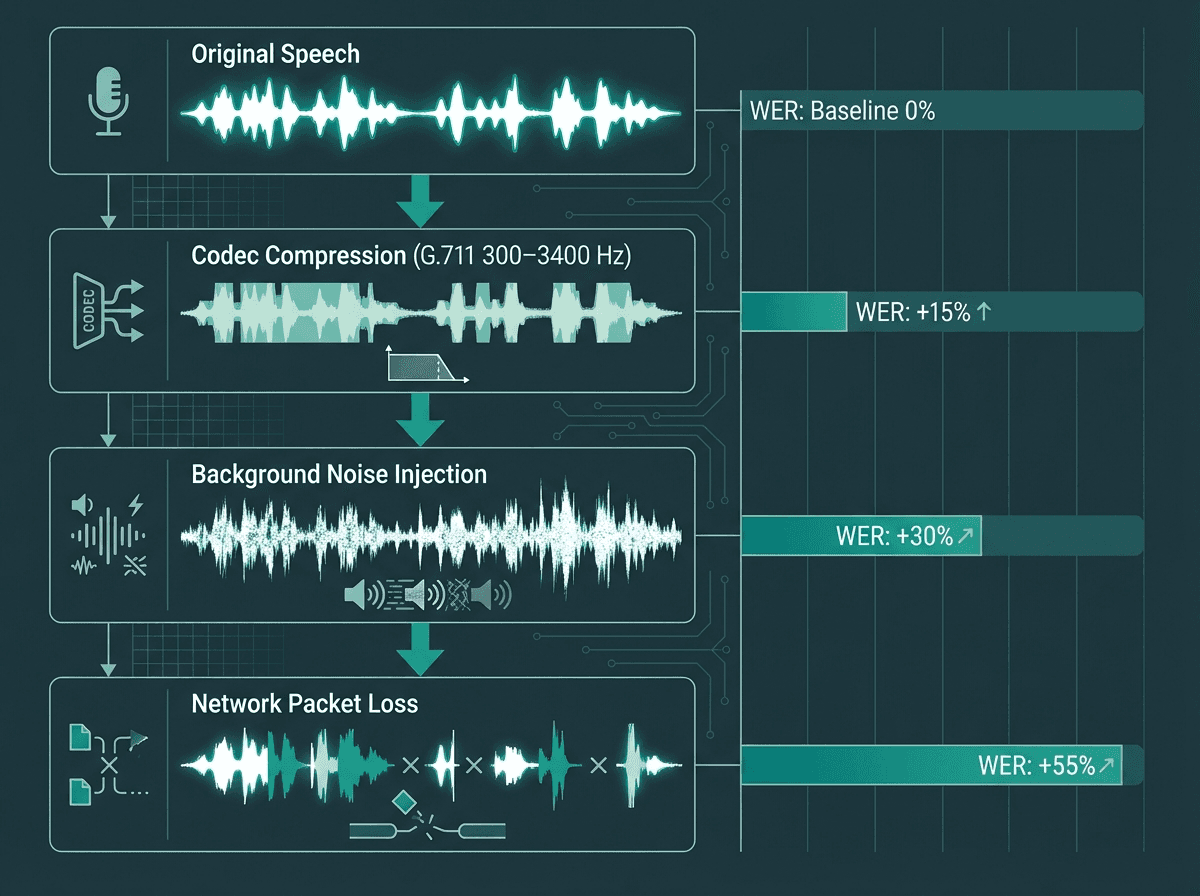
Each layer of telephony processing introduces degradation that compounds ASR error rates.
Accents and dialect variation: the ASR accuracy gap
An accent, as defined in sociolinguistics, is a way of pronouncing a language that is distinctive to a country, area, social class, or individual. It is purely phonetic. A dialect adds vocabulary and grammar variation on top of that. ASR systems struggle with both, but for different reasons.
Phoneme mapping is where accent-related errors originate. When a speaker from Hyderabad pronounces English vowels differently than a speaker from Houston, the acoustic model has to map those sounds to the same underlying words. If the model was not trained on sufficient examples of that accent, it falls back on the closest phoneme it knows, which often produces the wrong word. This is not a solvable problem through post-processing. It requires acoustic model diversity at training time.
What most teams get wrong here is assuming that selecting a 'multilingual' model solves the accent problem. It does not. A model trained on standard American English and standard Mandarin will still struggle with Indian English or Singaporean English, because those are distinct phonetic systems even though the vocabulary is English. When evaluating the best speech-to-text AI for your contact center, always test against audio samples that match your actual caller demographics, not benchmark datasets.
See how Smallest.ai handles accent diversity in real contact center audio
Code-switching: when speakers mix languages mid-sentence

Code-switching mid-utterance is one of the hardest problems in multilingual ASR.
Code-switching is the practice of alternating between two or more languages within a single conversation or even a single sentence. It is not a sign of linguistic confusion. It is a natural feature of multilingual communication, and it is extremely common in markets like India, Southeast Asia, Latin America, and sub-Saharan Africa. A caller might say 'I need to check my account balance, lekin mujhe password yaad nahi hai' without any pause or signal that the language has changed.
For ASR systems, this is a genuinely hard problem. Research published in MDPI (2022) reviewing code-switching in automatic speech recognition found that accuracy declines significantly in these situations due to pronunciation variations and the model's need to switch language models during recognition. Most production ASR systems are configured with a single language at the start of a session. When the speaker switches, the model either transcribes the foreign-language segment as garbled text or silently drops it.
There are a few architectural approaches that actually work. The most effective is a multilingual acoustic model trained on code-switched data, where the training corpus explicitly includes mixed-language utterances. A second approach uses language identification running in parallel with transcription, triggering a model switch when a language boundary is detected. The latency cost of the second approach is real and worth measuring. For real-time speech-to-text applications in contact centers, a language switch detection delay of even 200ms can cause the first word after the switch to be lost.
Handling noisy audio: what actually works in production
Noise in contact center audio falls into a few categories, and they require different solutions. Stationary background noise (HVAC systems, consistent crowd noise) responds well to spectral subtraction and Wiener filtering applied at the audio preprocessing stage. Non-stationary noise (keyboard clicks, sudden background conversations, dogs barking) is harder because the noise profile changes too fast for traditional noise reduction to track it cleanly.
Practical noise handling strategies for contact center ASR pipelines:
Apply voice activity detection (VAD) before sending audio to the ASR model to strip silence and reduce unnecessary processing
Use noise-robust acoustic models trained on augmented data that includes babble noise, telephony artifacts, and codec distortion
Implement acoustic echo cancellation at the telephony layer before audio reaches your ASR pipeline
Consider separate noise reduction preprocessing (RNNoise, DeepFilterNet) for particularly degraded audio streams
Test your pipeline at SNR levels below 10 dB, because that is where word error rates double and most vendors' demos do not go
One thing worth being direct about: noise reduction algorithms can distort the original speech signal. Aggressive noise suppression that removes background noise effectively can also suppress consonants and high-frequency speech content, which actually increases word error rate on the ASR side. The right balance depends on your noise profile. Measure both noise reduction quality and downstream ASR accuracy together, not separately.
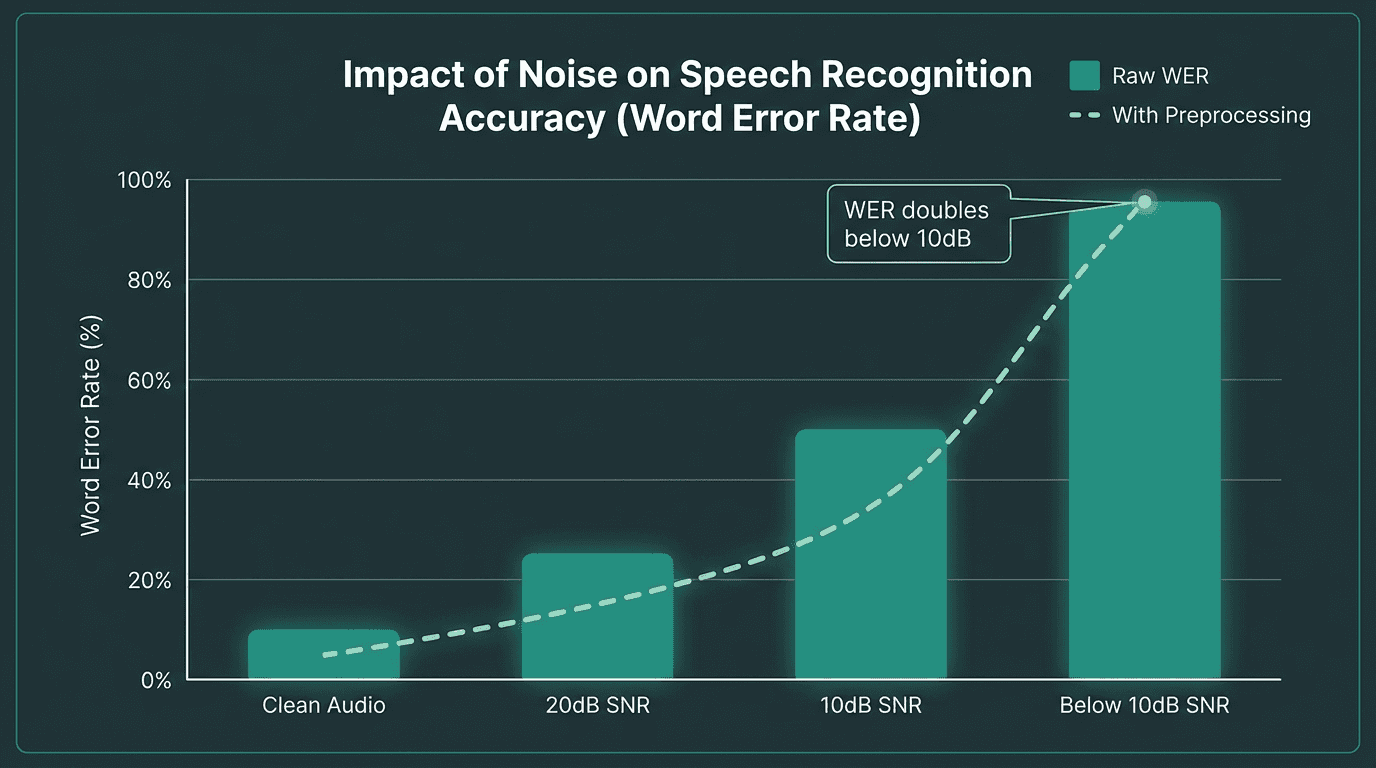
Word error rates climb steeply below 10dB SNR. Preprocessing helps but cannot fully compensate.
Building a multilingual ASR pipeline for contact centers
Architecture decisions made early in a contact center ASR deployment are expensive to reverse. Here is a practical framework for getting them right.
Language identification and routing
If your contact center handles a defined set of languages, pre-routing callers to language-specific ASR models still produces better accuracy than a single multilingual model in most cases. The tradeoff is that it requires callers to self-identify their language, which adds friction. A better approach for markets with predictable code-switching patterns is to configure a primary language per routing queue and use a secondary language model for known switch pairs (English-Spanish, English-Hindi, etc.).
Custom vocabulary and domain adaptation
Contact centers deal in domain-specific vocabulary: product names, account types, internal codes, and industry jargon. Generic ASR models will consistently misrecognize these. Most production-grade ASR APIs support custom vocabulary injection or language model adaptation. Use it. A custom vocabulary list for your top 500 domain-specific terms can reduce error rates on those terms by 40-60% without retraining the acoustic model. For best speech-to-text APIs for voice agents, this feature is a baseline requirement, not a nice-to-have.
Real-time vs. batch transcription tradeoffs
Contact centers increasingly use real-time transcription for agent assist features, sentiment analysis, and compliance flagging. This vertical is projected to account for 28% of real-time speech-to-text solution market revenue by 2026 (Market Research Report, 2026). Real-time transcription introduces latency constraints that force tradeoffs with accuracy. Streaming ASR models produce interim results that get revised as more audio context arrives. For agent assist use cases, interim results are acceptable. For compliance recording and post-call analytics, batch processing with a higher-accuracy model is usually the right choice.
Explore Smallest.ai speech models built for real-world audio conditions
Advanced considerations: speaker diarization, confidence scores, and fallback handling
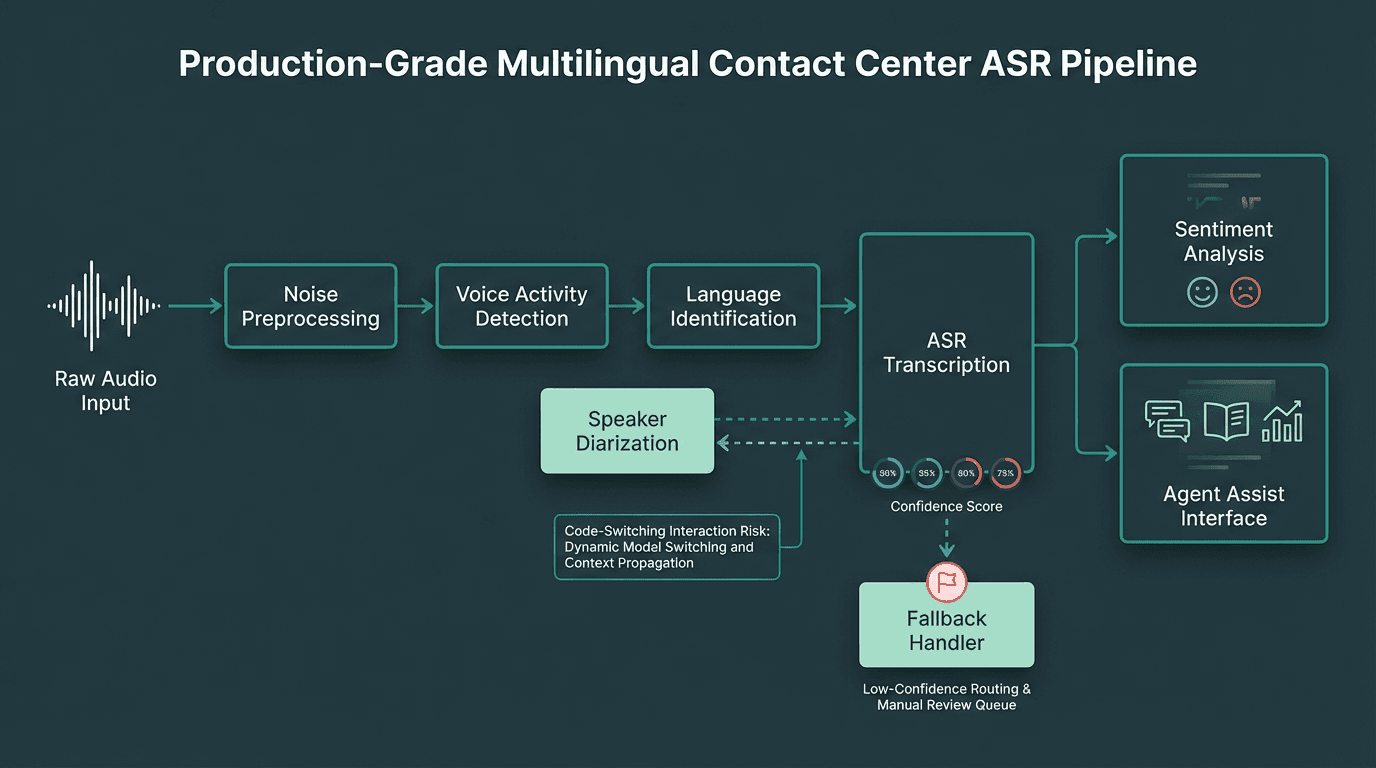
A production-grade multilingual ASR pipeline requires several components working in parallel.
Speaker diarization (separating 'who spoke when') is essential for contact center transcripts but interacts badly with code-switching. When a speaker switches languages, diarization models sometimes interpret the acoustic shift as a new speaker. This produces transcripts where the same person appears as two different speakers. If you are using diarization, test it explicitly on code-switched audio from your target markets.
Confidence scores from ASR models are underused in most contact center deployments. Every word-level transcription comes with a confidence value. Building a fallback handler that flags low-confidence segments for human review (or triggers a clarification prompt in an IVR flow) is one of the highest-ROI improvements you can make to transcription quality without changing the underlying model. Set your confidence threshold based on empirical testing against your audio, not the vendor's default.
For a thorough grounding in the full landscape of transcription technology before deploying in production, a complete guide to speech-to-text AI covers the foundational concepts that apply across all deployment contexts.
Key takeaways and next steps
Multilingual contact center ASR is a solvable problem, but it requires deliberate engineering choices rather than off-the-shelf defaults. The three failure modes that cause the most real-world pain are accent-driven phoneme mismatches, code-switching boundary detection failures, and noise-induced word error rate spikes. Each has a known mitigation strategy, and Pulse STT by Smallest.ai is built specifically for all three: trained on multilingual and accent-diverse audio with support for 30+ languages and automatic language detection; designed to handle code-switching mid-stream without session restarts; and tested at telephony-grade SNR levels where general-purpose models fail. The question is not whether a solution exists — it is whether your chosen vendor is built for these conditions from the ground up.
Concrete next steps for your deployment:
Collect a representative audio sample set from your actual caller population, covering all languages, accents, and noise conditions you expect in production
Benchmark at least three ASR providers against that sample set before committing to an architecture
Implement custom vocabulary for your domain-specific terms as a first-pass accuracy improvement
Build confidence score monitoring into your pipeline from day one so you can measure and improve over time
Test code-switching scenarios explicitly if your caller base is multilingual, and confirm your vendor has a documented approach to handling them
Which languages are hardest for speech-to-text systems to handle accurately?
Can a single ASR model handle both code-switching and noisy audio well?
How does telephony audio quality affect speech-to-text accuracy?
What is the difference between multilingual ASR and language identification?
How should contact centers measure ASR performance in production?

