Audio To Text Converter : Fast AI Transcription For Files, Calls, And Recordings


Audio to text converter basics: how ASR works, why accuracy drops in real audio, and what to measure for files, live calls, and call recordings.
Audio to Text Converter: Fast AI Transcription for Files, Calls, and Recordings.
An audio to text converter is software that runs automatic speech recognition (ASR) to turn spoken audio into written text, whether that audio comes from uploaded files, live calls, or a backlog of recordings. Under the hood, it blends signal processing with acoustic and language modeling to decode speech reliably across the messy range of real-world audio.
The use of AI transcription is growing as companies treat transcripts not just as admin work, but as a data layer that powers compliance, search, analytics, and accessibility. If you build voice-enabled products or run high-volume audio workflows, it helps to understand what an audio to text converter is actually doing, and where it predictably breaks.
What Happens Inside an Audio to Text Converter
"Speech recognition" sounds straightforward until you look at what has to happen to get usable text out of a waveform. As IBM's overview of speech-to-text technology lays out, even the baseline pipeline has three distinct layers: audio preprocessing, feature extraction, and decoding with a language model. Each stage comes with its own ways to fail, which is why accuracy swings so much between platforms and across audio conditions.
Preprocessing is the cleanup pass: filtering noise, normalizing levels, and chopping out silence so the model spends its time on speech. Feature extraction then turns the waveform into a compact representation, often mel-frequency cepstral coefficients (MFCCs) or learned embeddings from a neural encoder. From there, the decoder combines an acoustic model (what sounds map to what phonemes) with a language model (what word sequences make sense in context) to resolve ambiguity and produce the final transcript.
Most modern systems have moved past the classic hidden Markov model pipeline in favor of end-to-end deep learning, especially transformer-based architectures that learn acoustic and linguistic patterns together. That transition has improved performance on many clean, controlled benchmarks, but production audio still needs separate testing. Production audio is still the stress test: overlapping speakers, telephone compression, accents, and domain vocabulary are where systems start to wobble. If you want a closer look at how fast AI speech recognition deals with those constraints in real time, the architecture matters at least as much as the headline accuracy number.
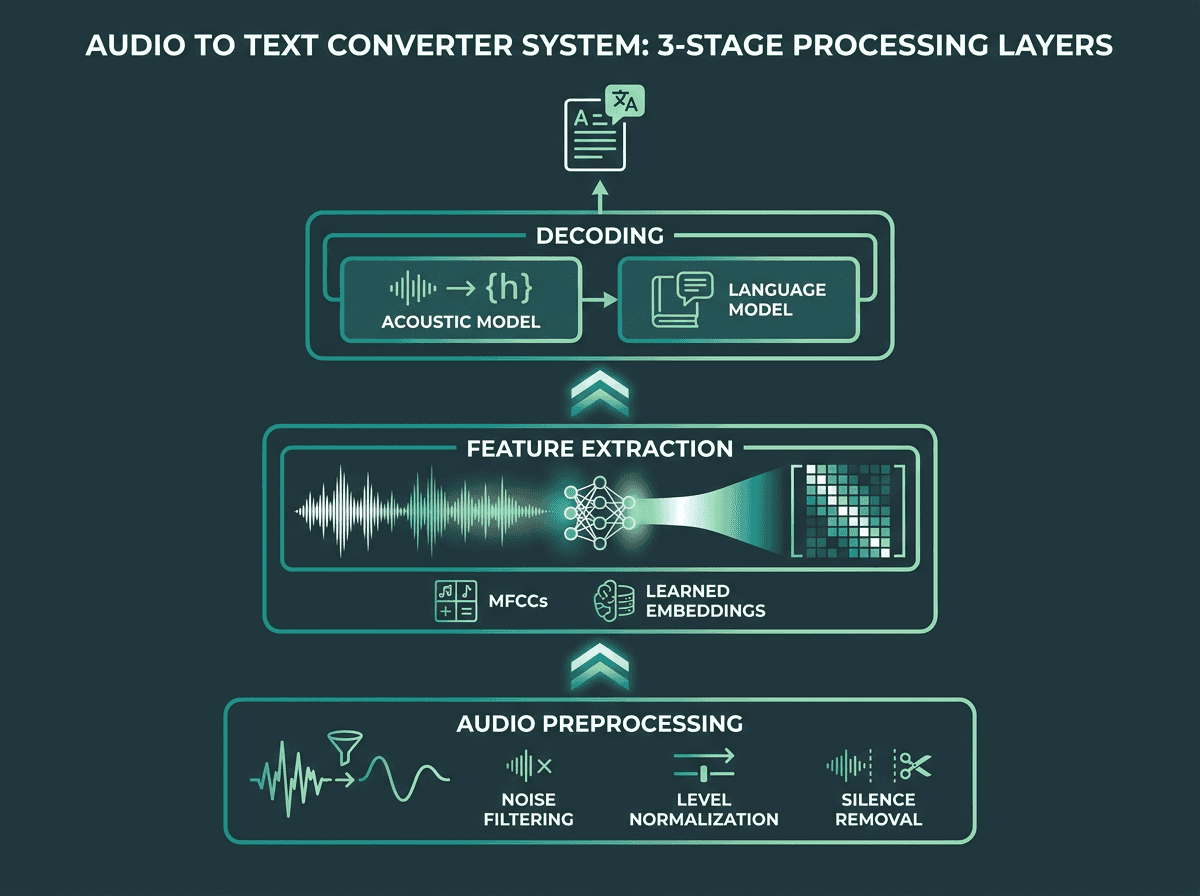
The three core processing layers inside any modern audio to text converter.
Three Modes of Transcription: Files, Calls, and Recordings
Not all audio inputs behave the same, and transcription systems feel those differences immediately. The source drives latency expectations, accuracy trade-offs, and even which model and API style makes sense.
Input Type | Processing Mode | Latency Requirement | Primary Use Case |
|---|---|---|---|
Uploaded audio files (MP3, WAV, M4A) | Asynchronous batch | Minutes to hours acceptable | Podcast transcription, media archiving, research |
Live phone calls / VoIP streams | Real-time streaming | Sub-second (under 300ms ideal) | Contact center agents, live captioning, IVR |
Pre-recorded call recordings | Asynchronous or batch | Near-real-time to minutes | Compliance review, QA, CRM enrichment |
Contact centers are the most punishing environment of the three: lots of audio, often heavily compressed, and usually tied to downstream workflows that expect structure. Teams that need to transcribe call recordings at scale end up making very different engineering calls than a solo podcaster uploading a single episode. At volume, speaker diarization, channel separation, and domain-adapted language models stop being "nice to have" and become table stakes.
Accuracy in the Real World: What the Numbers Actually Mean
Benchmark scores and production performance routinely drift apart. Modern transcription systems can achieve very high accuracy on clean, single-speaker recordings. Performance varies significantly once noise, accents, and multiple speakers are introduced. The gap between ideal and real-world conditions is not academic. It is the difference between text you can route into analytics or compliance systems and text that forces someone back into the loop to fix it.
Word Error Rate (WER) is the standard yardstick: the share of words that differ from a reference transcript. A WER of 5% sounds small until you apply it to a 1,000-word call, where roughly 50 words are wrong, including the ones you care about most: names, product codes, and complaint details. In compliance-heavy industries like healthcare and finance, even small WER differences can create review burden or risk when errors affect names, codes, consent language, or complaint details. That is why medical transcription typically leans on domain-specific language models trained on clinical vocabulary rather than general-purpose ASR.
Common Misconceptions About Audio to Text Conversion
Misconception 1: Higher accuracy claims mean consistent accuracy. Vendors love to cite WER from clean, single-speaker benchmarks like LibriSpeech. Your audio will not look like that. Accents, code-switching, and background noise all drag performance down in ways those benchmark numbers do not predict. Before you commit, run the system on your own recordings, not the vendor's curated samples. If you operate in multilingual environments, handling accents and noisy audio usually means configuring models for the reality of your data, not the ideal case.
Misconception 2: Transcription and speech recognition are the same thing. ASR is the engine that maps audio to a text sequence. Transcription is the workflow around it: speaker labeling, punctuation restoration, timestamp alignment, and post-processing so the output reads like something a human wrote. A model can post a strong WER and still produce a transcript that is awkward or unusable without those extra layers.
Misconception 3: Batch and streaming APIs are interchangeable. They are built for different constraints. Streaming transcription works chunk-by-chunk as audio arrives, prioritizing low latency and often giving up some context. Batch transcription runs over the full file, which gives the model more context and typically better accuracy, but you wait for the result. Pick the wrong mode, like forcing a batch API into a live call assistant, and you create UX problems that post-processing cannot paper over.
Key Use Cases Driving Adoption
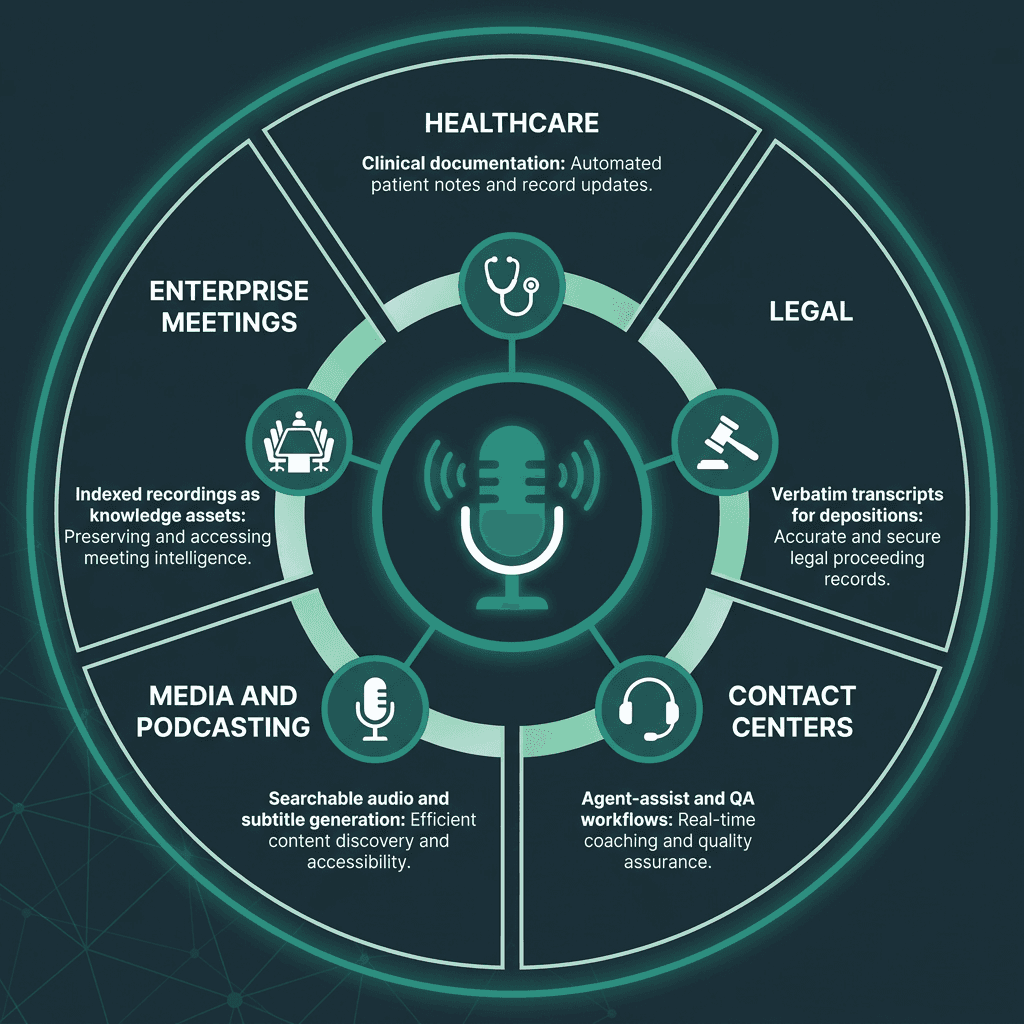
Five industries where audio to text conversion has moved from optional to operationally critical.
Healthcare is a major adoption area because clinical documentation is high-volume and high-stakes. Outside healthcare, adoption clusters around a few repeatable patterns:
Contact centers: Real-time transcription powers agent-assist tools, sentiment analysis, and post-call QA without requiring humans to listen to every recording.
Legal and compliance: Depositions, court proceedings, and regulated calls often demand verbatim transcripts with speaker attribution and timestamps for evidentiary use.
Media and podcasting: Transcripts make audio searchable, speed up subtitle generation, and support repurposing across formats without manual transcription.
Enterprise meetings: Once meetings are transcribed and indexed, recordings turn into searchable knowledge assets instead of dead weight in a shared drive.
Accessibility: ASR-driven captions help make audio content usable for people with hearing impairments, aligning with digital inclusion frameworks.
How Developers Integrate Audio to Text Conversion
For engineering teams, the real question is rarely "who is best" in the abstract. It is which audio to text API drops into your stack cleanly and keeps behaving once it is in production. Most speech-to-text APIs look familiar: authenticate with an API key, send audio as an upload or a streaming byte stream, and get back JSON with the transcript, confidence scores, word-level timestamps, and sometimes speaker labels.
The sharp edges show up in the details. Streaming chunk sizes, partial transcript handling, and retry logic for failed requests can quietly make or break reliability. A practical walkthrough of how to transcribe audio to text in Python gets into request structure, error handling, and response parsing that API docs often treat as an afterthought.
Evaluating an Audio to Text Converter: What to Actually Measure
If you are choosing a transcription platform, ignore the glossy accuracy claim until you have numbers that match your environment. These are the dimensions worth testing:
Dimension | What to Test | Why It Matters |
|---|---|---|
WER on your audio | Run 10-20 representative samples through the API | Benchmark WER rarely matches production conditions |
Latency (streaming) | Measure time-to-first-word and end-to-end delay | Critical for live calls and real-time captioning |
Speaker diarization accuracy | Test multi-speaker recordings with known ground truth | Bad speaker attribution poisons downstream analytics |
Language and accent coverage | Test the specific languages and dialects in your data | Performance varies widely across language variants |
Deployment fit | Match batch, streaming, and workflow requirements | Different architectures behave differently in production |
If you are still surveying the market, a review of top speech-to-text transcription software lays out a structured comparison across these criteria. The point is not to chase the highest benchmark score, but to pick the system that stays accurate on the audio your application will actually see.
Key Takeaways
What you need to know about audio to text converters:
An audio to text converter uses ASR to turn speech into text via preprocessing, feature extraction, acoustic modeling, and language modeling.
Processing mode matters: streaming APIs prioritize latency for live calls, while batch APIs prioritize context and accuracy for file transcription. They are not drop-in substitutes.
Real-world accuracy is often far below benchmark accuracy. Test on your own audio before you choose a platform.
Healthcare, legal, and contact center applications are major drivers of AI transcription adoption.
Speaker diarization, domain-tuned language models, and noise robustness are the features that separate production-grade systems from general-purpose tools.
Integration details such as streaming chunking, retries, and response schemas drive production reliability as much as model accuracy.
From Audio Chaos to Structured Data: Where Smallest.ai Fits
Most audio-to-text stacks do not fail because there are no transcription engines available. They fail because the output from a general-purpose ASR model is not what production systems need: low-latency streaming for live calls, diarization that holds up in multi-speaker audio, domain adaptation for specialized vocabulary, and an API that integrates cleanly without brittle workarounds.
Smallest.ai's Pulse is built to narrow that gap. Pulse supports real-time streaming and batch transcription through a developer-first API, with speaker diarization and the low-latency performance that contact center and voice agent applications expect. It is part of a broader platform that includes Lightning for text-to-speech, Hydra for speech-to-speech, and Atoms for full voice and text agent deployment, so transcription is positioned as one layer in a complete voice AI stack rather than a standalone feature.
If you are working with high-volume call recordings, real-time agent assist, or building a voice-enabled product end to end, start by getting specific about your audio and the error rate your workflow can tolerate. Explore the Smallest.ai Speech-to-Text API for production-ready transcription, or see how transcription fits into a complete conversational AI workflow with Smallest.ai Voice Agents.
What is the difference between an audio to text converter and a speech recognition system?
How accurate are AI transcription tools on real-world audio?
Can an audio to text converter handle multiple speakers on a call?
What audio file formats does a typical speech-to-text API accept?
How do I get started with integrating an audio to text API into my application?