Audio to Text API: How to Convert Recorded Audio Into Accurate Transcripts Programmatically


Audio to text API basics, from batch vs streaming to diarization and post-processing, plus what to benchmark so transcripts hold up in production.
Recorded audio shows up in everything from customer support calls and podcasts to medical dictation, earnings calls, and field interviews. The catch is that audio is basically invisible to most software. You can’t reliably search it, index it, summarize it, or route it into downstream systems until it’s been turned into text. That’s the job of an audio to text API: convert speech into usable transcripts fast enough to keep up with real production volume.
Below is a practical walkthrough of what’s happening behind the API call, what separates "works in a demo" from "holds up in production," and how to implement transcription without stepping on the usual rakes. If you’re building a voice-first product, automating meeting notes, or chewing through a backlog of recorded calls, the same fundamentals keep showing up.
What Is an Audio to Text API and How Does It Work?
An API is a contract between two software systems: one system exposes a capability, and the other uses it without caring how it’s implemented. An audio to text API exposes a very specific capability: provide an audio file (or stream), get back a transcript. All the messy work (acoustic modeling, language modeling, and signal processing) stays on the other side of the boundary.
Underneath, you’re relying on Automatic Speech Recognition (ASR). ASR is the AI-driven machinery that turns spoken language into readable text, powering voice dictation, captions, and meeting transcripts. Modern ASR has shifted toward end-to-end deep learning models that roll what used to be a multi-stage pipeline into a single neural network, typically improving accuracy and simplifying system design compared to older hybrid approaches. The practical implication is subtle but important: your integration code can stay the same while the transcription quality improves over time as the vendor updates models behind the API.
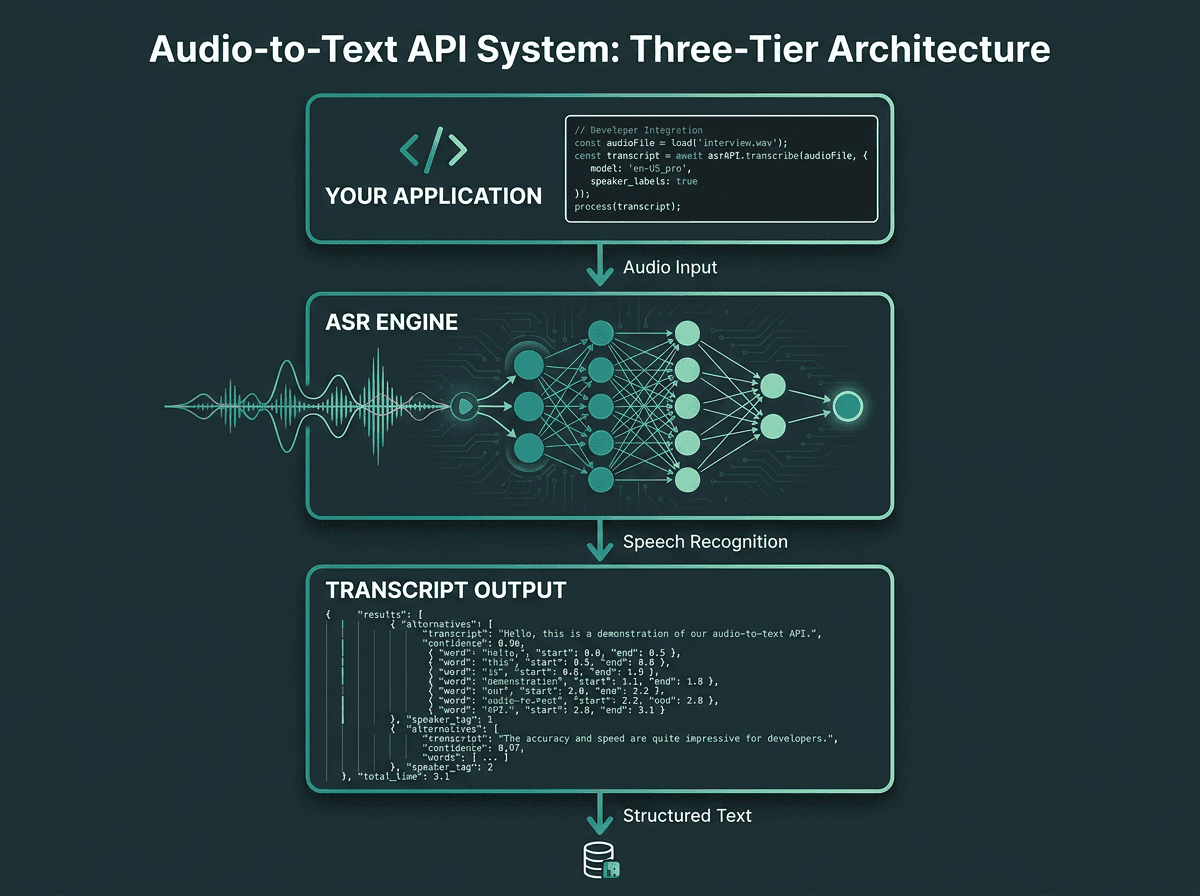
How an audio-to-text API abstracts the ASR engine from your application layer.
Batch vs. Real-Time: Choosing the Right Mode Before You Write a Line of Code
Most teams postpone this decision and then pay for it later. Batch transcription and real-time (streaming) transcription have different constraints, different infrastructure patterns, and different failure modes. Pick the wrong one and you’ll end up with avoidable latency, avoidable spend, or both. Understanding the difference between a batch and a streaming architecture is critical.
Batch transcription is the right choice when:
You are processing pre-recorded files (interviews, calls, podcasts) where the audio already exists in full.
Turnaround time of seconds to minutes is acceptable rather than milliseconds.
You want the highest possible accuracy, since the model can see the entire audio before producing output.
Cost efficiency matters more than immediacy.
Real-time streaming transcription is the right choice when:
You are building a live application: a voice agent, live captioning, or a real-time call analytics dashboard.
The user needs to see words appear as they speak.
You are feeding transcripts into a downstream model that needs to respond before the speaker finishes.
If you’re working with recorded audio, batch should be your starting point. It’s easier to ship, easier to scale, and typically produces better transcripts. Streaming earns its keep when the experience depends on immediacy, when waiting for the full file breaks the product. The architectural patterns for a streaming voice agent are fundamentally different.
How to Convert Recorded Audio to Text Programmatically
Converting recorded audio to text with an API is usually a simple pipeline: send an audio file, pass the transcription options your workflow needs, receive structured JSON, then clean and store the output for downstream use.
Here’s the basic flow:
1. Upload or host the audio file
Start with a recorded file such as a support call, meeting recording, podcast episode, interview, or voice note. You can either upload the file directly to the API or host it at a secure URL, depending on the API’s supported input method.
2. Send the file or audio URL to the transcription API
Your application sends the recorded audio to the speech-to-text endpoint. For Smallest.ai Pulse, the pre-recorded transcription endpoint is:
https://docs.smallest.ai/waves/documentation/speech-to-text-pulse/overview
3. Pass language, diarization, timestamps, and formatting options
Configure the request based on your use case. For example, pass a known language code when available, enable diarization if multiple speakers are present, request word-level timestamps for editing or search, and use formatting options when you need cleaner transcript output. Smallest.ai’s Pulse documentation lists support for pre-recorded and real-time transcription, speaker diarization, word timestamps, language detection, punctuation formatting, and related speech-to-text features. (Smallest AI Docs)
4. Receive structured JSON
Instead of getting only a plain text transcript, a production API should return structured fields your application can use, such as transcript text, timestamps, detected language, speaker labels, and confidence-related metadata.
5. Store transcript data with useful metadata
Save the transcript alongside the original call ID, file ID, customer ID, timestamp, speaker labels, and any confidence or quality markers. This makes the transcript easier to search, audit, analyze, and connect to downstream systems.
6. Run post-processing before sending data forward
Clean the transcript before pushing it into CRM, QA tools, BI dashboards, compliance workflows, or search indexes. Common post-processing steps include punctuation cleanup, paragraph segmentation, filler-word removal, entity correction, redaction, summarization, and topic tagging.
cURL request
Python request
Once the JSON response comes back, your application can store the transcript text, attach speaker labels, preserve word-level timestamps, and route the cleaned output into support QA, CRM notes, compliance review, analytics, or internal search.
The Anatomy of an API Request: What You Actually Send and Receive
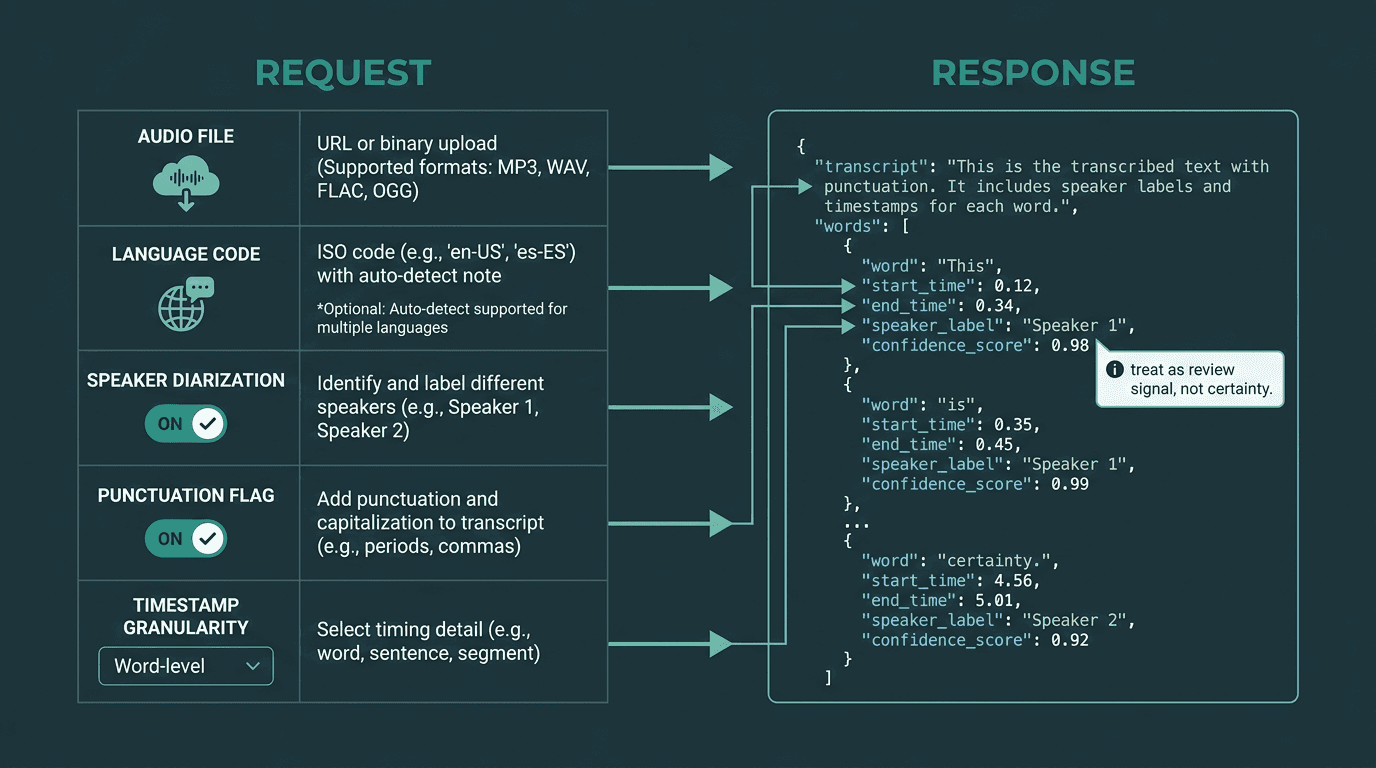
Anatomy of a typical audio-to-text API call: what goes in and what comes back.
A solid audio-to-text request is pleasantly boring. You provide an audio source (upload a file or pass a URL to one you host), specify the language (or allow auto-detection) and toggle a few optional features. What you get back is structured JSON you can actually build on.
In the response, the most useful fields are the transcript text, word-level timestamps (critical for editing tools and highlight extraction), and confidence scores at the word or segment level. If you’re dealing with more than one speaker, diarization is the difference between "we have text" and "we have something a human can use." Diarization assigns segments of speech to individual speakers, which is table stakes for calls and interviews. You can find implementation details in the Pulse diarization documentation.
A quick warning on confidence scores: teams routinely over-interpret them. A 0.85 score doesn’t mean the model is "85% sure" in a human sense; it’s a number derived from the model’s internal probability distribution. Treat low-confidence spans as candidates for review, not as a promise that those words are wrong.
Audio Quality Is the Variable Most Teams Underestimate
Even the most sophisticated ASR model can’t reconstruct speech that never made it into the recording. Background noise, compression artifacts, overlapping speakers, and low-bitrate audio all damage the signal before the model gets a shot. The system is doing inference from imperfect input, useful, but not magical.
A few pre-processing steps reliably move the needle: resample to 16kHz mono before sending (many ASR models are trained on that format), apply a noise gate or a spectral subtraction pass when the environment is messy, and split very long recordings (over 60 minutes) to avoid timeouts and enable parallelization. If you’re dealing with accented speech, code-switching, or call center audio, the hard parts extend well beyond basic cleanup. The handling accents, code-switching, and noisy audio considerations in multilingual environments are worth treating as first-class requirements, not edge cases.
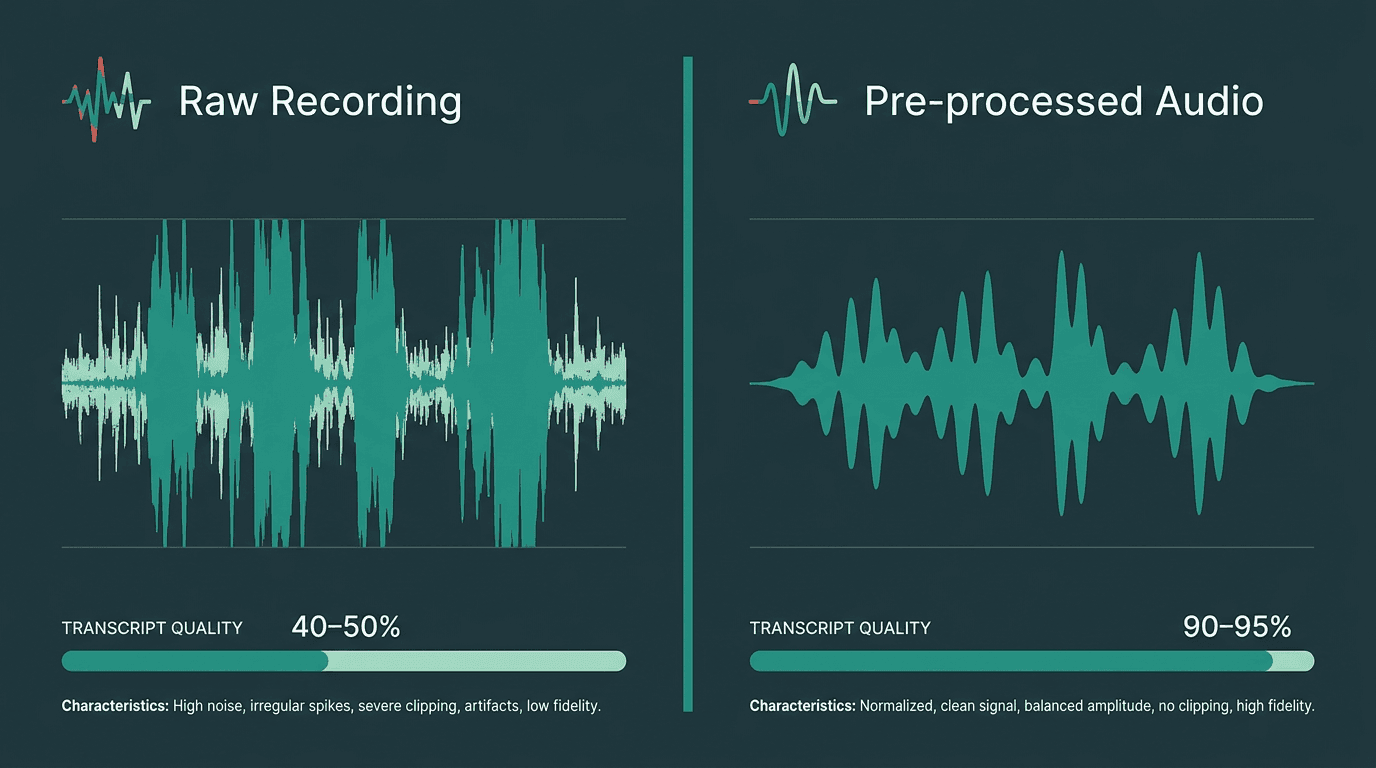
Pre-processing audio before sending it to an API has a measurable impact on transcript accuracy.
Language Detection and Multilingual Transcription
Automatic language identification has gotten materially better. The 2022 NIST Language Recognition Evaluation reported meaningful progress on recognizing languages in conversational telephone speech, including a newer emphasis on African languages that were underrepresented in earlier benchmarks. For production systems that handle global audio, this isn’t academic: if the model falls apart on Swahili or on Hindi-accented English, it’s not actually global.
When you’re building a multilingual pipeline, pass an explicit language code whenever you know it. Auto-detection costs latency and can miss on short clips or heavily accented speech. If the language is genuinely unknown, run a lightweight identification step first, then route the audio to the right transcription configuration. In practice, that two-step flow is more dependable than asking one model to guess the language and transcribe it in a single shot.
Post-Processing: Turning a Raw Transcript Into Something Useful
A raw transcript is usually just the starting point. Teams don’t want "text" so much as text they can search, route, audit, and act on. Closing that gap (between raw output and operationally useful output) is where most of the real engineering time goes.
Common post-processing steps worth building into your pipeline:
Punctuation and capitalization normalization: Some APIs return this automatically; others return a flat string. Confirm which you are getting.
Custom vocabulary and entity correction: Industry-specific terms, product names, and proper nouns are where generic models make the most errors. Most APIs accept a custom vocabulary list that boosts recognition probability for those terms.
Filler word removal: 'Um', 'uh', and 'like' can be stripped programmatically before the transcript reaches end users.
Paragraph segmentation: Long monologue transcripts are unreadable without paragraph breaks. Use silence gaps or topic-shift signals to segment.
Downstream enrichment: Sentiment analysis, topic tagging, and summarization can all be applied to the cleaned transcript as a second pass.
What to Look for When Evaluating an Audio to Text API
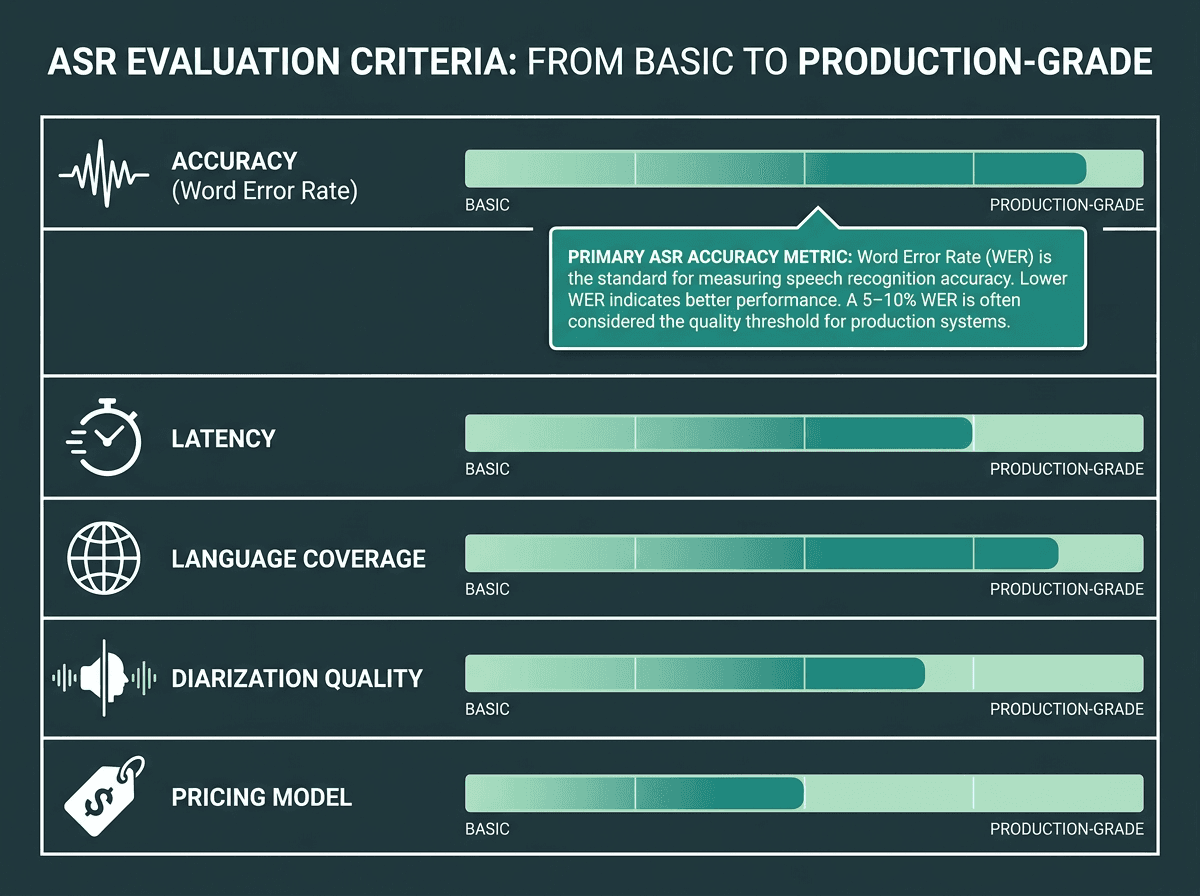
Five dimensions that separate a production-ready transcription API from a demo-grade one.
Word Error Rate (WER) remains the default metric for ASR accuracy, as defined by organizations like NIST. It reports the percentage of words that differ from a ground-truth transcript. While there is no universal threshold, a WER of 5-10% is often considered good quality for many use cases. For noisy or accented audio, a WER under 20% can be acceptable. The non-negotiable: measure performance on your own recordings, not a vendor’s headline benchmarks, which are frequently taken on clean studio audio that doesn’t resemble real workloads.
Accuracy isn’t the only thing that bites teams in production. You also need to care about latency (how long does a 10-minute file take to come back?), language coverage (does it match your user base?), diarization quality (does it separate two speakers reliably?), and the pricing structure (per-minute, per-character, or subscription). The model matters, but the pricing model can matter more, because it determines how cost behaves when volume ramps.
Smallest.ai Pulse: Built for Production Transcription Workloads
Smallest.ai’s speech-to-text product, Pulse, is aimed at teams that need transcription to behave predictably in production, not just look good in a quick test. It supports batch files and streaming input, includes speaker diarization, and integrates through a clean API so you can plug it into an existing pipeline without reworking your infrastructure.
Pulse’s practical emphasis is on low-latency output without trading away accuracy on real-world audio. That matters in products that rely on fast, accurate transcription, where users expect spoken notes to show up as clean text in seconds.
If you’re building voice agents, it’s worth mapping transcription into the full real-time pipeline before you lock in an implementation. The AI voice agents architecture resource breaks down how voice models, use cases, and safety guardrails interact once you’re operating in production. For automated note-taking, the orchestration of voice and text agents is a distinct challenge Smallest.ai's Atoms is designed to solve.
Pricing is published on the pricing page. To validate fit on your own audio before committing, you can book a demo and bring representative sample files.
Summary and Next Steps
Programmatic audio-to-text isn’t a commodity where every API behaves the same. Results swing based on audio quality, language and accent mix, speaker overlap, and how closely the model’s training data matches your domain. Your implementation choices matter too: batch versus streaming, the shape of your post-processing layer, and how transcription plugs into the rest of your data pipeline.
The practical checklist before going to production:
Pre-process your audio: resample to 16kHz mono, reduce background noise where possible.
Benchmark on your own audio, not vendor-published WER numbers.
Decide batch vs. streaming before writing integration code.
Build a post-processing layer: punctuation, custom vocabulary, segmentation.
Test diarization on multi-speaker recordings specific to your use case.
Confirm pricing scales acceptably at your expected monthly volume.
The core problem is turning raw audio into structured, actionable data. The operational constraint is doing so with the accuracy and speed that production workflows require. Smallest.ai’s Pulse is built for this reality, providing a transcription API that fits cleanly into a broader voice AI stack. More resources are on our blog, and you can book a demo to run it on your own audio.
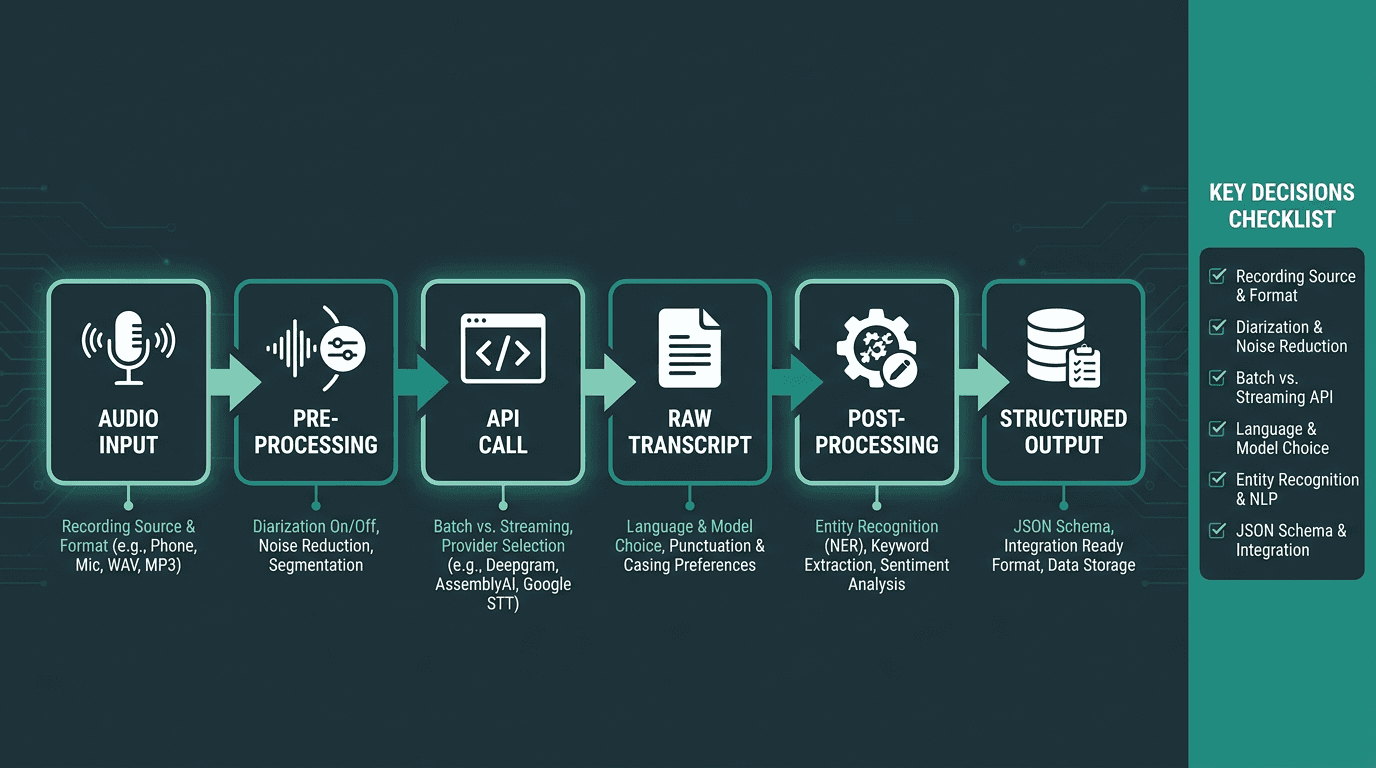
A six-step implementation checklist for taking audio-to-text from prototype to production.
Which audio formats do speech-to-text APIs usually accept?
How accurate is audio to text conversion on phone call recordings?
Can an audio to text API transcribe multiple speakers in the same recording?
What’s the difference between batch transcription and real-time transcription?
How can I improve transcription accuracy for domain-specific terminology?