

Text to audio converter basics: the neural TTS pipeline, what drives voice quality, and how to ship low-latency, production-ready audio output.
A text to audio converter does exactly what you want it to do: take written content and turn it into spoken audio. The catch is that "TTS" can mean wildly different things depending on the generation of the tech. The systems many of us remember from the mid-2010s were serviceable, but flat and robotic. Modern neural voice synthesis, by contrast, can carry prosody, subtle emotion, and speaker identity well enough that in the right conditions it can pass for a human recording.
This piece is for developers, content teams, and product builders who need the mechanics, not the hype: how text to audio conversion works end-to-end, where quality actually breaks down in production, and how to pick an approach that fits the job. The goal is a clear mental model of the tech, a practical workflow you can implement, and a checklist of what really drives output quality.
What Is a Text to Audio Converter?
A text to audio converter is a system that takes text as input and returns audio as a file or a stream. Depending on where that audio is headed, you might request MP3, WAV, OGG, or a real-time PCM stream. Under the hood, though, the way we get from characters to speech has changed dramatically over the last few generations.
Older concatenative TTS literally stitched together pre-recorded phoneme segments. It was understandable, but it never stopped sounding like a machine. Parametric synthesis smoothed some of that out, while adding its own "buzzy" signature. Modern neural text-to-speech systems have improved dramatically in naturalness, with many producing speech that sounds substantially more human-like than earlier generations of synthetic voice technology. Neural text-to-speech is where the step-change happened: models built around transformer-style architectures and diffusion-based vocoders pushed speech quality into a different tier.
In practice, if you're shipping voice output in 2026, you're almost certainly using neural synthesis. The decisions that separate a smooth experience from a brittle one tend to be about latency, voice quality, language coverage, and how the system behaves on the messy edge cases your content will inevitably contain.
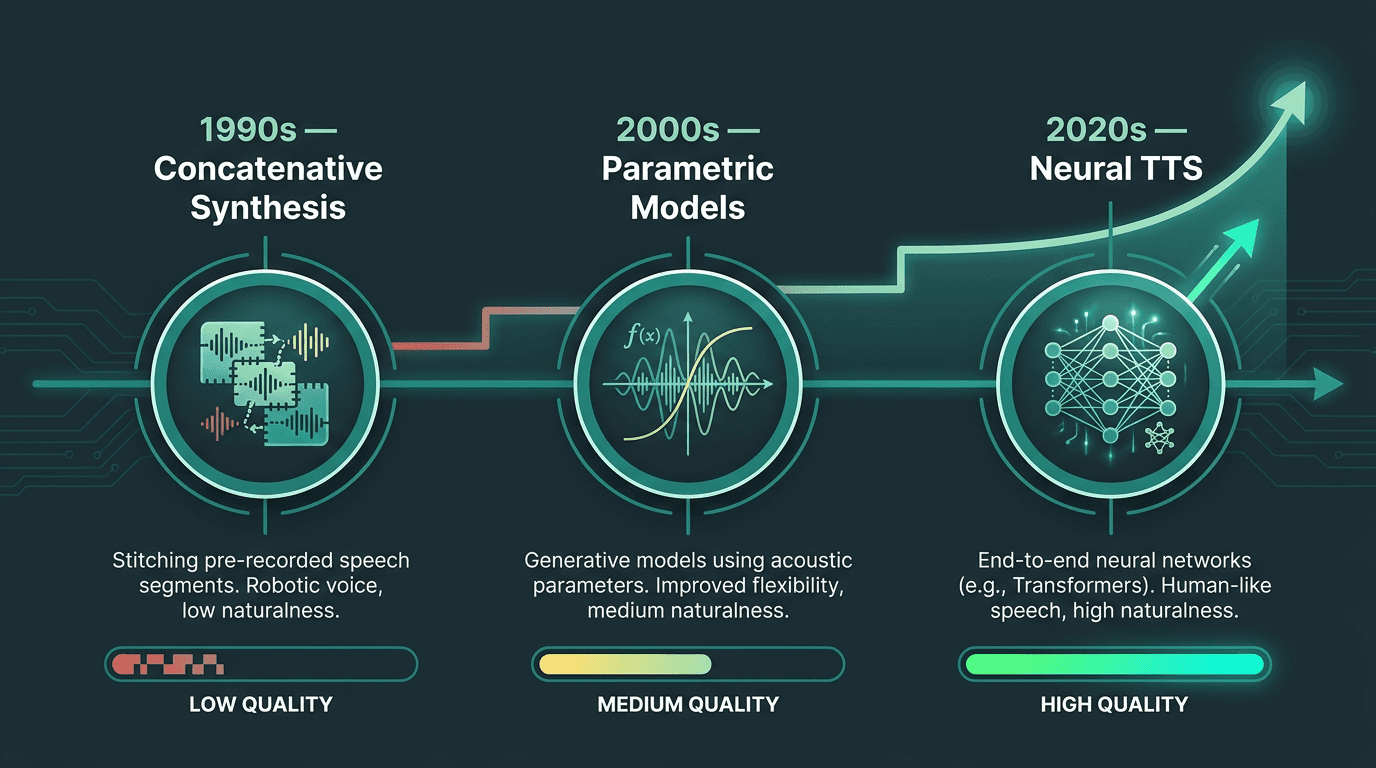
TTS technology has advanced from robotic phoneme stitching to near-human neural synthesis over three decades.
How the Conversion Process Actually Works
If you understand the pipeline, you can usually explain the failure. Modern neural TTS is a sequence of transformations, and each stage introduces its own class of bugs and quality regressions.
The core stages of a neural text to audio pipeline:
Text normalization: Raw input gets cleaned and standardized. Numbers, abbreviations, currency symbols, and dates are expanded into spoken forms. "$1.5M" becomes "one point five million dollars." This stage looks trivial until it isn't, and it is a frequent source of production issues.
Linguistic analysis: The normalized text is converted into phonemes, syllable boundaries, and syntactic structure. That information drives stress, rhythm, and where pauses should land.
Acoustic model inference: A neural model (often a variant of Tacotron, FastSpeech, or a diffusion-based architecture) maps the linguistic representation into a mel-spectrogram or a latent audio representation.
Vocoder synthesis: A neural vocoder (HiFi-GAN, WaveGrad, or similar) turns that intermediate representation into a raw waveform.
Post-processing: The waveform is encoded into the format you asked for, and may include loudness normalization.
Latency mostly shows up during acoustic inference and vocoder synthesis. Streaming TTS works by generating audio in chunks so playback can start before the full utterance is finished. For conversational products, first-chunk latency (time from request to the first audio byte) is the number that makes or breaks the experience. For batch jobs like audiobook generation, throughput matters more than real-time response. Those are different engineering constraints, and vendors tend to optimize for one or the other.
What Most People Get Wrong About Voice Quality
A lot of teams judge a text to audio converter the way you'd judge a demo reel: one impressive clip and a thumbs-up. That test is almost designed to miss the problems that show up once you run real content through the system at scale.
The first failure mode is prosody over long-form audio. A voice can sound great for 10 seconds and still wear listeners down over 10 minutes. Long narration needs variation in pitch, pace, and emphasis across paragraphs and sections, not just within a single sentence.
Second is technical vocabulary. General-purpose models are trained on broad datasets, so they routinely stumble on domain terms, product names, and acronyms. If a medical narration reads "mRNA" as a word instead of spelling it out, that is not a minor quirk; it is a production defect. The usual fix is better normalization plus pronunciation dictionaries, but not every platform gives you enough control to do that cleanly.
Third is emotional range. Neutral delivery works for documentation and a lot of accessibility use cases. But voice agents, e-learning, and marketing scripts often need the voice to shift tone between informational and warm, or calm and urgent, without sounding like it is acting. In those cases, voice design is as consequential as the model family behind the API.

Evaluating a text to audio converter across three dimensions reveals quality gaps a single demo clip never will.
Choosing the Right Text to Audio Converter for Your Use Case
"Best" is the wrong question. The right choice depends on what you're shipping, what your users will tolerate, and what your infrastructure can support. The easiest way to make the decision is to compare the dimensions that actually drive trade-offs.
Use Case | Latency Priority | Voice Variety Needed | Key Feature |
|---|---|---|---|
Conversational voice agent | Very high (sub-300ms first chunk) | Low to medium | Streaming TTS, low latency API |
Audiobook / long-form narration | Low | High | Consistent prosody, chapter-level control |
E-learning content | Medium | Medium | Pronunciation dictionaries, SSML support |
Accessibility (screen reader) | Medium | Low | Broad language support, reliability |
Video dubbing / localization | Low | High | Multilingual voices, timing control |
IVR / phone system | High | Low | Telephony codec support (8kHz, mulaw) |
If you're building a real-time voice product, latency is not a nice-to-have; it is the product. The Lightning TTS from Smallest.ai is oriented around low-latency streaming synthesis, with first-chunk performance tuned for conversational scenarios. If you're a publisher or a content team producing long-form audio, the priorities flip: you care less about sub-second responsiveness and more about consistency across chapters, plus batch throughput that won't turn a catalog into a weeks-long rendering job.
Practical Implementation: From Text Input to Audio Output
Step 1: Prepare and Normalize Your Text
Before you send text to any synthesis API, make it speakable. Strip or replace anything that doesn't map cleanly to audio: HTML tags, markdown artifacts, weird punctuation, and the kind of whitespace that turns into awkward pauses. Expand abbreviations the model is likely to guess wrong. And be deliberate with numbers. "Call 1-800-555-0100" should be read as digits; "The population is 1800" should not. If you don't decide up front, the model will decide for you.
Step 2: Select Voice and Parameters
Most TTS APIs let you pick a voice and adjust speaking rate and pitch. Some also support SSML (Speech Synthesis Markup Language), which is where you get real control: pauses, emphasis, and pronunciation tweaks that the default prosody won't always infer correctly. If pacing affects comprehension, SSML is not optional. A well-placed pause before a key point in an e-learning module is part of the instruction, not decoration. The W3C Speech Synthesis Markup Language specification remains the canonical reference for SSML, defining a standard way to control pronunciation, pitch, volume, rate, pauses, and other speech-output behavior across synthesis systems.
Step 3: Handle Output Format for Your Delivery Context
Choose your output format based on where the audio will live. MP3 at 128kbps is fine for most web, podcast, and app delivery. If you're doing post-production work like mixing, noise reduction, or level normalization, ask for WAV or FLAC so you're not compounding compression artifacts. Telephony is its own world: 8kHz or 16kHz PCM or G.711 mulaw is typical. If you're streaming, you want chunked transfer or WebSocket delivery rather than waiting on a file download. Make the format decision early; back-end conversions add quality loss and make pipelines harder to reason about.

A clean implementation workflow reduces errors and ensures audio quality at every stage of delivery.
Voice Cloning and Custom Voices
Voice cloning is no longer a lab demo; it's a feature you can buy from many commercial TTS platforms. The premise is straightforward: you provide reference audio of a target speaker, and the system synthesizes new speech that matches that voice. The catch is that "voice cloning" covers a wide range of quality levels and data requirements.
Zero-shot cloning works from just a few seconds of reference audio and tends to produce a usable approximation. Fine-tuned cloning uses longer recordings (typically 30 minutes to several hours) to get closer to the target voice, with better prosody and more stable speaker characteristics. If you're building a brand voice that needs to sound consistent across thousands of outputs, fine-tuning is the safer bet. If you're prototyping or producing one-off content, zero-shot can be the pragmatic choice.
This is also where the ethical and legal stakes get real. Cloning a voice without consent is a genuine harm. Regulation around synthetic media and voice cloning continues to evolve, making consent, disclosure, and auditability increasingly important for production deployments. If you deploy voice cloning in production, build explicit consent, disclosure, and audit trails into the workflow rather than treating them as policy docs nobody reads.
Smallest.ai's Lightning TTS supports voice cloning via API, which lets teams build consistent brand voices or personalized audio experiences. If you're scaling narration, the AI audiobook generation workflow is a useful reference for how cloned voices hold up in long-form production.
Multilingual Support and What It Actually Means
"Supports 30 languages" sounds decisive, but it's mostly empty unless you ask better questions. How close is each language to the model's primary training language in quality? Can it handle code-switching (two languages in one utterance) without falling apart? Do the voices sound like native speakers, or like an English model doing an impression?
If you're deploying globally, test the languages you actually care about using the content your users will hear. It is common for quality to vary significantly between high-resource and lower-resource language pairs, so each target language needs its own QA pass. Accent authenticity affects trust, especially in consumer-facing products. A customer service voice agent that technically speaks the right words but carries a heavy foreign accent still creates friction.
If you're localizing video, the bar gets higher because timing matters. The multilingual voice dubbing workflow shows what changes once you add synchronization constraints on top of basic TTS.
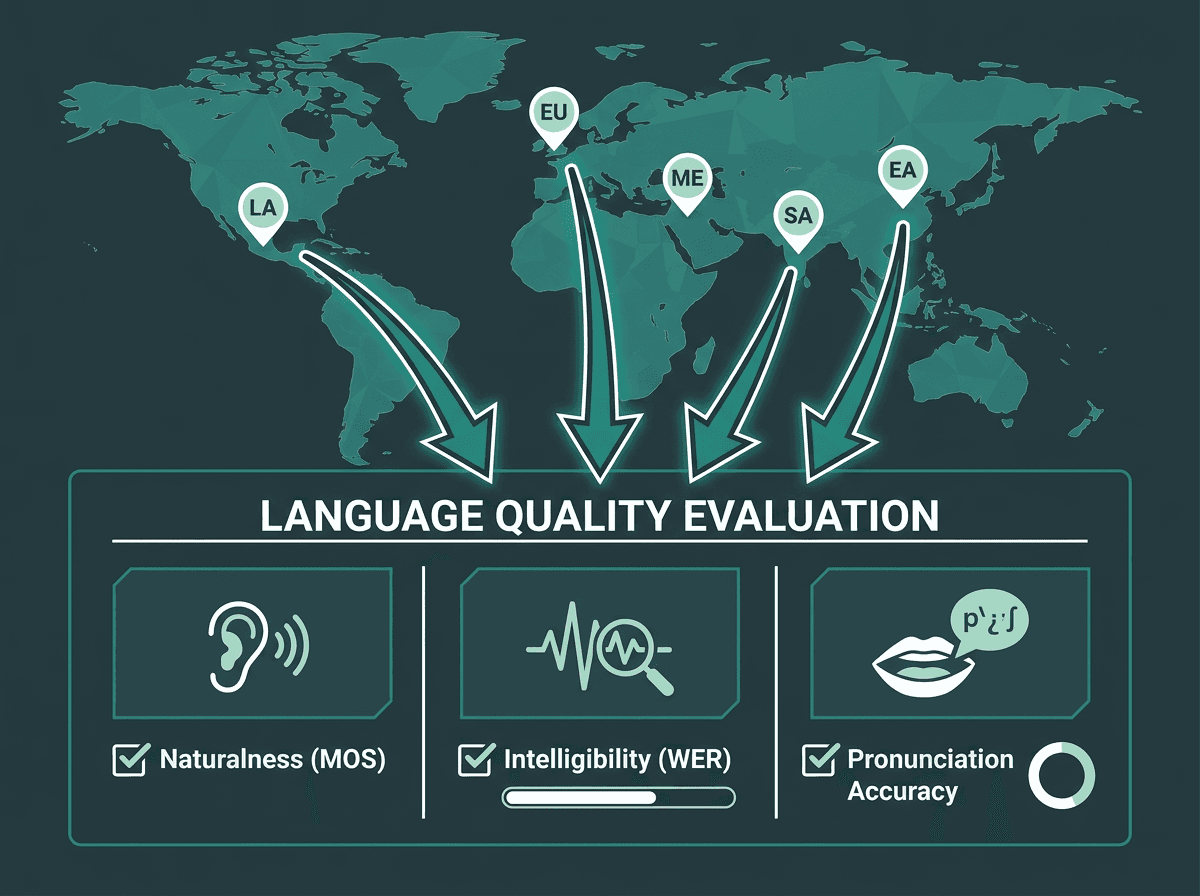
Testing each language individually reveals where a text to audio converter truly performs — and where it falls short.
Advanced Considerations for Production Deployments
A few details that often get a footnote in product docs, but show up immediately once you're in production:
Caching strategy. If your product repeats the same audio (navigation prompts, common responses, static content), caching synthesized files removes both latency and per-request cost. In many applications, a solid caching layer can significantly reduce repeated API requests and improve response times for frequently used audio. The cost is storage, plus the operational headache of cache invalidation when content or voices change.
Fallback handling. TTS APIs fail in boring, predictable ways: timeouts, rate limits, transient model errors. Your app needs a plan for that moment: a pre-synthesized default response, a backup provider, or a clear user-facing error state. Silent failures are the worst outcome because they look like your product is broken, not like a dependency hiccuped.
Audio quality monitoring. Audio can degrade without any obvious signal in an HTTP response code. Build periodic checks into your ops cadence: listen to production samples, watch for odd silence lengths, and track user feedback. Provider-side model updates can shift voice characteristics, which matters if you're trying to keep a brand voice consistent.
Cost modeling. Most TTS APIs charge by character count. A 1,000-word article is roughly 6,000 characters, and at scale that math gets expensive fast. Model expected usage before you lock into a tier, and account for re-synthesis when content changes. If you're building high-volume applications, the Waves API documentation is a good place to understand throughput and pricing structure.
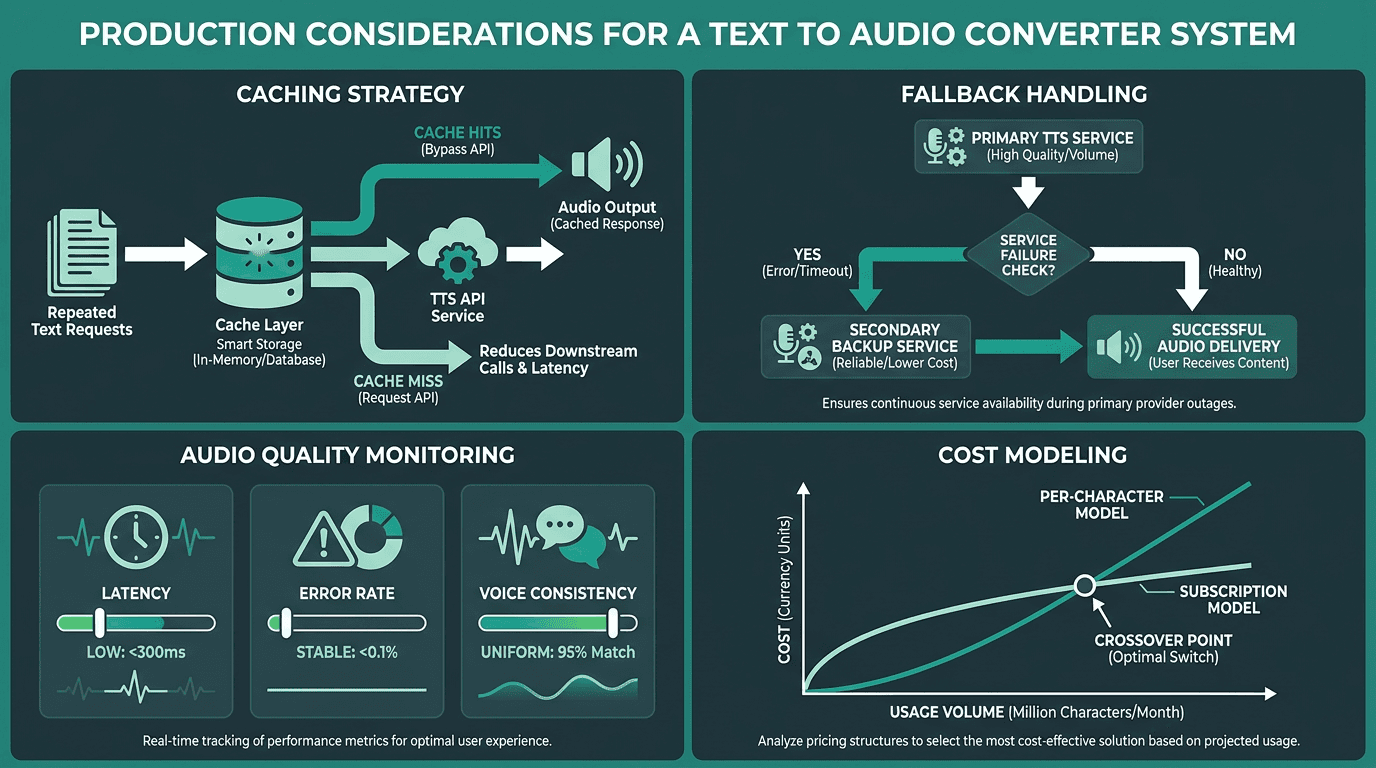
Production-grade TTS deployments require caching, fallback logic, quality monitoring, and careful cost modeling.
Key Takeaways
What to carry forward from this guide:
Neural TTS has reached near-human quality in controlled tests; what separates platforms now is latency, language quality, and production reliability.
Text normalization is easy to underestimate. A large share of production quality issues come from messy input, not the synthesis model.
Pick tools by use case. Conversational agents need low-latency streaming; long-form narration needs stable prosody. Optimizing for one does not automatically optimize for the other.
Voice cloning is ready for production, but it brings ethical and legal obligations with it. Build consent and audit mechanisms from day one.
Treat multilingual claims as hypotheses. Test your target languages with your real content before you commit.
Production deployments need caching, fallback logic, and quality monitoring, not just an API that returns audio.
Most teams don't struggle to find a TTS vendor; they struggle to find one that stays natural across real content, hits the latency their product needs, and doesn't force a pile of brittle workarounds. Smallest.ai's Lightning TTS is positioned for that production reality: a low-latency, high-quality neural voice synthesis engine delivered through the Lightning TTS, with streaming delivery, multilingual support, and voice cloning built in. If you're building a voice agent, scaling narration, or shipping accessibility features, explore the Smallest.ai Text-to-Speech API and evaluate Lightning on your own content, not a polished demo script.
What is the difference between a text to audio converter and a text-to-speech API?
How do I get the most natural-sounding output from a TTS system?
Can I use a text to audio converter to create audiobooks at scale?
What audio formats should I request from a TTS API?
Is voice cloning through a text to audio API legal and ethical to use?
![This blog will be featured on the top of the /blog page. Only one blog can be featured at a time. If multiple blogs are featured, only the first featured blog will appear in the list Transcribe audio to text in Python with clean preprocessing, API calls, diarization, chunking, and production retry/cost patterns you can ship confidently. Meta data of Page Empty How to Transcribe Audio to Text in Python: A Step-by-Step API Guide for Developers Transcribe audio to text in Python with clean preprocessing, API calls, diarization, chunking, and production retry/cost patterns you can ship confidently. how-to-transcribe-audio-to-text-in-python-a-step-by-step-api-guide-for-developers smallest.ai/blog/how-to-transcribe-audio-to-text-in-python-a-step-by-step-api-guide-for-developers Empty Empty Prithvi Bharadwaj Empty Transcribing audio to text sounds like a solved problem right up until you try to ship it. Different file types, odd sample rates, background noise, accents, and multi-speaker chatter have a way of turning a “quick script” into a real engineering effort. What follows is the practical path from “it works on my machine” to Python code that can handle real-world audio without reliability issues. If you’re building meeting notes, a voice-driven support bot, or an audio indexing pipeline, the same fundamentals show up again and again. You’ll end up with working Python code, a clearer sense of which knobs actually move accuracy, and a realistic map from prototype to production. The sections build in order, so you can treat this as a sequence rather than a menu. How Python Audio Transcription Works: Basic Workflow Before you start writing code, it helps to understand the full transcription flow. A speech-to-text pipeline is not just “upload audio and get text back.” In a real application, you need to prepare the audio, send the right request, receive structured output, and make that output usable for your product or workflow. Here is the basic workflow most Python audio transcription systems follow: Prepare or host the audio file Start with the audio source you want to transcribe. This could be a local file from a user upload, a call recording from your CRM, a meeting recording, a podcast episode, or a hosted file URL. If the file is already hosted securely, you can send the URL directly to the transcription API. If it is stored locally, you can upload the raw audio file from Python. Normalize audio format when needed Audio files often arrive in different formats, bitrates, sample rates, and channel layouts. Before sending them to the API, normalize the file if needed. A common safe format is mono, 16 kHz, 16-bit WAV, especially when you want predictable transcription quality across different recordings. This step helps reduce issues caused by unsupported formats, stereo channel confusion, or noisy conversions. Send the file or URL to the transcription API Once the audio is ready, your Python script sends it to the speech-to-text API. For a local file, this usually means reading the audio bytes and sending them in a POST request. For hosted audio, you send the public or signed URL in a JSON payload. In both cases, your request should include authentication, usually through an API key stored in an environment variable. Pass language, diarization, timestamp, and formatting options Most transcription APIs let you control how the output should be generated. For example, you can pass a language code such as en, enable speaker diarization for multi-speaker conversations, request word-level timestamps, or allow automatic language detection. These options are important because they affect how useful the final transcript will be for search, captions, analytics, QA, or downstream automation. Receive structured JSON A good speech-to-text API does not only return plain text. It usually returns structured JSON containing the full transcript, word-level timing, detected language, confidence scores, and speaker information when diarization is enabled. This structure is what turns a transcript from a simple text blob into data your application can work with. Extract transcript, word timestamps, speaker labels, and confidence metadata After receiving the response, parse the JSON in Python. Extract the full transcript for display, word timestamps for syncing text with audio or video, speaker labels for conversations, and confidence scores for quality checks. For example, low-confidence words can be flagged for human review before the transcript is pushed into a customer-facing or compliance-sensitive workflow. Store or post-process the transcript Finally, store the transcript and metadata in your database, object storage, CRM, QA platform, BI tool, or search index. You may also run post-processing steps such as punctuation cleanup, redaction, summarization, keyword extraction, speaker formatting, or topic tagging. This is where transcription becomes useful beyond raw text: it can power searchable call archives, meeting summaries, support QA, captions, compliance review, or voice analytics. A simple Python transcription workflow usually looks like this: 1. Prepare or host audio audio_path = "preprocessed_audio.wav" 2. Send audio to transcription API response = transcribe_audio(audio_path) 3. Extract structured fields transcript = response.get("transcription", "") words = response.get("words", []) utterances = response.get("utterances", []) language = response.get("language", "unknown") 4. Store or post-process results print("Transcript:", transcript) print("Detected language:", language) print("Word count:", len(words)) print("Speaker turns:", len(utterances)) This workflow gives you a clean mental model before you move into the actual implementation. What 'Transcribe Audio to Text' Actually Means at the API Level Before you write Python, it helps to be specific about what a speech-to-text API is doing when you hit “transcribe.” You’re not mailing a file to a black box and getting a paragraph back. The service typically runs audio through an acoustic model (sound to phonemes), a language model (phonemes to likely words in context), and then a post-processing layer that cleans things up with punctuation, capitalization, and sometimes speaker labels. Those layers are also where quality gaps show up fast. A model that looks great on clean, studio English often falls apart on call-center audio, heavy background noise, or conversations that switch languages mid-thought. That’s why API choice matters as much as your Python wrapper. If you want more of the underlying mechanics, the speech recognition Python guide breaks down how modern recognition systems behave in practice. The internal pipeline of a modern speech-to-text API, from raw audio to structured transcript Setting Up Your Python Environment Use a fresh virtual environment. Audio tooling is notorious for dependency clashes, and isolating packages saves you from debugging your machine instead of your pipeline. Run these commands to get your environment ready: python -m venv stt-env # macOS / Linux source stt-env/bin/activate # Windows stt-env\Scripts\activate pip install requests python-dotenv pydub Keep your API key in a `.env` file instead of baking it into code. That’s basic hygiene, and it also makes key rotation painless when you move from local testing to production. Add `SMALLEST_API_KEY=your_api_key_here` to `.env`, then load it with the snippet below. SMALLEST_API_KEY=your_api_key_here from dotenv import load_dotenv load_dotenv() Audio Preprocessing: The Step Most Tutorials Skip A lot of transcription walkthroughs start with a pristine WAV and pretend that’s normal. It isn’t. Phone recordings often arrive at 8 kHz, which is a bad match for models expecting 16 kHz. Video shows up as MP4 or MKV with audio tucked inside a container. Zoom exports can include separate mono tracks per speaker, which changes how you should feed the audio into a model. `pydub` covers most of the annoying format work without much fuss. Here’s a small preprocessing function that converts audio into the shape most APIs prefer: from pydub import AudioSegment def preprocess_audio(input_path: str, output_path: str) -> str: """ Convert an audio file to mono, 16 kHz, 16-bit PCM WAV. This format is commonly preferred for speech-to-text pipelines. """ audio = AudioSegment.from_file(input_path) audio = audio.set_channels(1) audio = audio.set_frame_rate(16000) audio = audio.set_sample_width(2) audio.export(output_path, format="wav") return output_path if __name__ == "__main__": preprocess_audio("input_audio.mp3", "preprocessed_audio.wav") In practice, run everything through this before you call the API. Resampling alone can move the needle a lot, especially when the original recording is telephony-grade. As Mozilla's Common Voice documentation notes, 16 kHz mono WAV is the standard input format across many open-source and commercial speech models. Preprocessing audio before sending it to a transcription API significantly improves accuracy Making Your First Transcription API Call in Python Once you’ve got a clean audio file, the API call is straightforward. The example below uses Smallest.ai's Pulse, a speech-to-text API aimed at low-latency, high-accuracy transcription, with streaming support for real-time scenarios. import os import requests from dotenv import load_dotenv load_dotenv() def transcribe_audio(file_path: str) -> dict: """ Send a local audio file to Smallest.ai Pulse STT and return the transcription response as JSON. """ api_key = os.getenv("SMALLEST_API_KEY") if not api_key: raise ValueError("Missing SMALLEST_API_KEY in environment variables.") url = "https://api.smallest.ai/waves/v1/pulse/get_text" params = { "language": "en", "word_timestamps": "true", "diarize": "false", } headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "audio/wav", } with open(file_path, "rb") as audio_file: response = requests.post( url, headers=headers, params=params, data=audio_file, Two details here matter more than they look. `raise_for_status` turns HTTP failures into exceptions, so you deal with errors explicitly instead of quietly printing an empty string and calling it “done.” And word_timestamps=true gives you word-level timing, which you’ll want the moment you need to sync text to video, highlight search hits, or build any kind of usable audio index. If you’re building a richer pipeline, the speech-to-text developer guide goes further on streaming and real-time patterns. Transcribing a Hosted Audio URL import os import requests from dotenv import load_dotenv load_dotenv() def transcribe_audio_url(audio_url: str) -> dict: """ Send a hosted audio URL to Smallest.ai Pulse STT and return the transcription response as JSON. """ api_key = os.getenv("SMALLEST_API_KEY") if not api_key: raise ValueError("Missing SMALLEST_API_KEY in environment variables.") url = "https://api.smallest.ai/waves/v1/pulse/get_text" params = { "language": "en", "word_timestamps": "true", "diarize": "true", } headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "application/json", } payload = { "url": audio_url, } response = requests.post( url, Handling the API Response and Extracting Structured Data A transcription response is usually more than a single transcript field. Good APIs return structure: word timings, confidence scores, detected language, and sometimes speaker metadata. Here’s a typical response shape and a simple way to pull the useful parts out: def parse_transcript(response: dict) -> None: """ Print the transcript, word-level timestamps, confidence scores, and detected language. """ full_text = response.get("transcription", "") print(f"Transcript: {full_text}") words = response.get("words", []) for word in words: text = word.get("word", "") start = word.get("start") end = word.get("end") confidence = word.get("confidence") start_text = f"{start:.2f}s" if isinstance(start, (int, float)) else "?" end_text = f"{end:.2f}s" if isinstance(end, (int, float)) else "?" confidence_text = ( f"{confidence:.2f}" if isinstance(confidence, (int, float)) else "?" ) print(f"[{start_text} - {end_text}] {text} (confidence: {confidence_text})") language = response.get("language", "unknown") print(f"Detected language: {language}") Treat confidence scores as a routing signal, not trivia. When a word drops below ~0.7, the model is telling you it’s guessing, often because of noise, an unfamiliar proper noun, or overlapping speech. In production, low-confidence spans are a good place to trigger human review instead of letting uncertainty leak into downstream systems. Anatomy of a transcription API response: transcript, word-level timestamps, and confidence scores Speaker Diarization: Knowing Who Said What Single-speaker audio is the easy mode. Meetings, podcasts, and support calls are where things get interesting, because “what was said” isn’t enough, you need “who said it.” That’s diarization, and you typically switch it on with `diarize: True` in your request parameters. When diarization is enabled, Pulse adds speaker labels to word-level and utterance-level output, so you can rebuild the transcript as a conversation. def format_diarized_transcript(response: dict) -> str: """ Format diarized utterances into a readable speaker-by-speaker transcript. """ utterances = response.get("utterances", []) lines = [] for utterance in utterances: speaker = utterance.get("speaker", "unknown_speaker") text = utterance.get("text", "").strip() start = utterance.get("start", 0) if not text: continue lines.append(f"[{start:.1f}s] {speaker}: {text}") return "\n".join(lines) There’s a catch: diarization gets worse when people talk over each other. In call-center audio, interruptions are common, and the cleanest fix is often upstream (separate channels when you have them, then transcribe) rather than expecting the model to untangle cross-talk perfectly. The speaker diarization pipelines guide goes deeper on multi-speaker strategies. Handling Long Audio Files and Chunking Strategies Transcription APIs usually impose limits on file size or duration. Even if yours doesn’t, pushing a 90-minute recording through a single request is asking for trouble: one timeout and you’re back at zero. Chunking long audio into smaller pieces is the standard way to keep the pipeline resilient. A robust chunking strategy for long audio files: Split audio into segments of 30-60 seconds using `pydub`'s `make_chunks` method Add a 1-2 second overlap between chunks to avoid cutting words at boundaries Transcribe each chunk independently and collect results in order Merge transcripts by removing duplicate words in the overlap region using a simple string alignment check Preserve global timestamps by offsetting each chunk's word timestamps by its start position in the original file from pydub import AudioSegment def split_audio_with_overlap( input_path: str, output_dir: str, chunk_length_ms: int = 60_000, overlap_ms: int = 2_000, ) -> list[str]: """ Split long audio into overlapping chunks. Default: 60-second chunks with 2-second overlap. """ audio = AudioSegment.from_file(input_path) chunk_paths = [] start = 0 chunk_index = 0 while start < len(audio): end = min(start + chunk_length_ms, len(audio)) chunk = audio[start:end] chunk_path = f"{output_dir}/chunk_{chunk_index:04d}.wav" chunk.export(chunk_path, format="wav") chunk_paths.append(chunk_path) if end == len(audio): break start = end - overlap_ms chunk_index += 1 return chunk_paths That overlap is the difference between “mostly works” and a system that behaves predictably at boundaries. Without it, words that land on the boundary get clipped and either vanish or come back mangled. A one-second overlap barely changes processing cost, but it wipes out an entire category of edge cases. If you’re dealing with accents, code-switching, or multilingual audio, the speech-to-text for multilingual audio guide lays out the extra pitfalls. Chunking long audio with overlapping segments prevents word-boundary errors at split points Production Considerations: Error Handling, Retries, and Cost Control A laptop script is a demo; production is where the messy stuff shows up. Rate limits kick in, networks flake out, and users upload audio in formats you didn’t plan for (or recordings that are far longer than they should be). If you plan for those three upfront, the rest is mostly engineering. For rate limits and transient failures, use exponential backoff. `tenacity` keeps it tidy: `@retry(wait=wait_exponential(multiplier=1, min=2, max=30), stop=stop_after_attempt(5))`. Put that decorator on your API call and you’ll ride out most short-lived issues without writing your own retry state machine. pip install tenacity import os import requests from dotenv import load_dotenv from tenacity import retry, stop_after_attempt, wait_exponential load_dotenv() @retry( wait=wait_exponential(multiplier=1, min=2, max=30), stop=stop_after_attempt(5), ) def transcribe_with_retries(file_path: str) -> dict: """ Transcribe audio with retries for transient API or network failures. """ api_key = os.getenv("SMALLEST_API_KEY") if not api_key: raise ValueError("Missing SMALLEST_API_KEY in environment variables.") url = "https://api.smallest.ai/waves/v1/pulse/get_text" params = { "language": "en", "word_timestamps": "true", "diarize": "false", } headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "audio/wav", } with open(file_path, "rb") as audio_file: Cost is the other production surprise. Most transcription APIs bill per minute, which means “just run it” can get expensive fast. Two habits keep spend predictable: check duration before you upload (and reject anything over your cap at the app layer), and cache results so the same file doesn’t get transcribed twice. A content hash of the audio makes a practical cache key. If you’re building at volume, the speech-to-text guide gets into higher-throughput architectures, async workers, queues, and the patterns that keep long-running pipelines stable. What Most Developers Get Wrong About Transcription Accuracy A 5% WER sounds tiny until you translate it: roughly 1 in every 20 words is wrong. In a 500-word meeting summary, that's about 25 errors. Even state-of-the-art models show meaningfully higher word error rates on noisy, spontaneous conversational speech compared to clean benchmark conditions (sometimes exceeding 20%) which is why testing on your own audio is non-negotiable. So benchmark like you mean it. Test your API on audio that matches your product, not on clean demo clips. Capture 10–15 minutes from the real environment, measure accuracy, and only then commit. Domain vocabulary is where general models stumble most, medical terms, product names, internal acronyms. If your provider offers custom vocabulary or domain adaptation, use it when specialized terminology is part of the job. Summary and Next Steps A dependable audio-to-text pipeline in Python usually comes down to four disciplines: normalize audio before the API sees it, treat the response as structured data (not a single string), chunk long recordings with overlap, and build retries and error handling as first-class features. The snippets here stay intentionally small so you can drop them into your own stack without a rewrite. As usage grows, you’ll likely add async processing, a job queue, and durable storage for results, but the core flow doesn’t change. If you’re comparing speech-to-text providers, Smallest.ai's Pulse is built for developers who care about latency, transcription quality, and an API that integrates cleanly. It supports streaming transcription, speaker diarization, word-level timestamps, and multilingual audio out of the box, which lines up with the production patterns covered above. Explore Pulse and the Waves API to start transcribing audio in Python today. The four pillars of a production-ready transcription pipeline in Python Gushwork Team: Ignore this Build Audio Transcription in Python Start testing speech-to-text workflows today Start Building https://app.smallest.ai/ FAQ row will only show if FAQ Answer is set. Please make sure both Question and Answers are set. The visibility of the FAQ Section is tied to FAQ Question 1 being set.](https://framerusercontent.com/images/5h0IzsaRLohS5uAxf7C2xhgJnOI.png?width=1456&height=816)
