

AI transcription turns speech into text using ASR and NLP. Get accuracy realities, top use cases, and a checklist for picking the right transcription tool.
AI transcription turns spoken audio or video into text automatically, using machine learning models, most commonly Automatic Speech Recognition (ASR) plus Natural Language Processing (NLP). Compared with manual transcription, it can return results in seconds, scale to large volumes without hiring more typists, and get better as models are retrained on broader, messier data.
The growth in AI transcription tracks how routine audio has become inside modern operations, from customer calls and medical consultations to legal depositions and recurring team meetings. If you want to understand what AI transcription is and how it works from a technical standpoint, it helps to look at the pipeline step by step.
How AI Transcription Actually Works
Everything begins when audio hits the system. Raw audio is a continuous waveform, so an ASR engine first slices it into short frames, usually 20 to 25 milliseconds each. For every frame, the model extracts acoustic features: numerical signals that capture patterns like frequency and energy over time.
A deep learning model, often transformer-based, then connects those features to phonemes (basic sound units), assembles phonemes into words, and predicts word sequences that fit the language. NLP components typically come after that pass, using context to clean up punctuation, normalize text, and reduce obvious grammatical artifacts. This ASR-plus-NLP stack is what moved transcription beyond older, rule-heavy systems that routinely fell apart on natural speech.
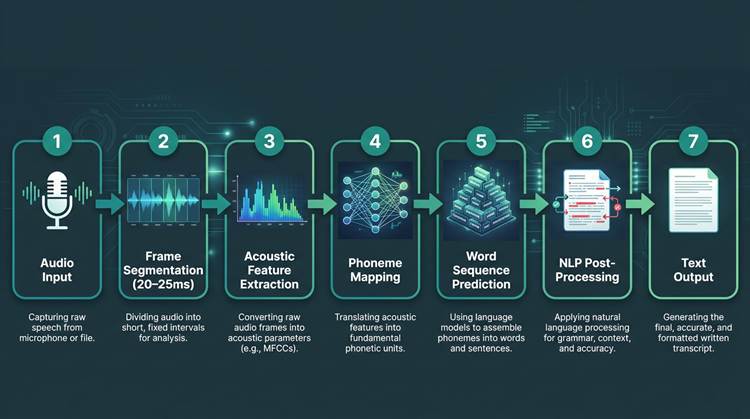
The AI transcription pipeline: from raw audio frames to clean, punctuated text.
A practical split is batch versus real-time transcription. Batch systems ingest a complete audio file, run it through the model, and return a finished transcript. Real-time systems stream audio and emit text with very low latency. The core model families can look similar, but live transcription needs extra work around buffering, partial hypotheses, and correcting earlier words as more context arrives.
Types of AI Transcription
Transcription isn’t one problem; it’s a cluster of related ones. Most products you’ll evaluate fall into four categories.
The four primary types of AI transcription:
● Automated Speech Recognition (ASR): The base layer. Converts audio into raw text, usually without speaker labels or deeper structure. It’s fast and inexpensive, but the output often needs cleanup.
● Speaker diarization: Figures out who spoke when in a multi-speaker recording. It’s what makes meeting notes, interviews, and call analytics readable instead of a wall of text.
● Domain-specific transcription: Models tuned for specialized vocabulary, such as medical transcription for clinical notes or legal transcription for court proceedings. On jargon-heavy audio, these models typically land far closer to usable accuracy than general-purpose systems.
● Real-time / live transcription: Produces text as someone is speaking. This is the layer behind live captions, voice agents, and real-time support tooling.
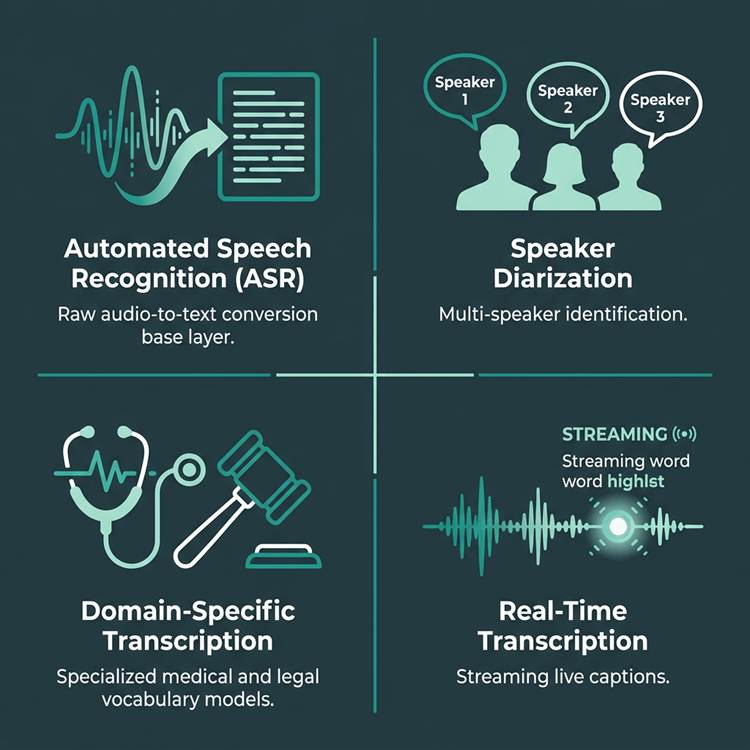
The four main categories of AI transcription, each suited to different use cases.
Where AI Transcription Is Being Used Right Now
Healthcare is a major adopter of AI transcription. Clinicians use transcription to turn patient conversations into structured notes and reduce the documentation burden that competes with care time. Because the tolerance for mistakes is low, domain-trained clinical models have become the default rather than a nice-to-have.
Meeting transcription is a fast-growing slice of the market. The appeal is straightforward: a call stops being an audio file that disappears into a folder and becomes a searchable artifact you can summarize, quote, and audit later.
Customer support is also high-volume by nature. AI transcription tools for customer support are used for real-time monitoring, turning voice interactions into tickets automatically, and scaling QA without staffing an army of reviewers to listen to every call. For legal and compliance teams, transcription becomes the backbone of an audit trail for verbal agreements, depositions, and regulatory interviews, where both accuracy and security are table stakes.
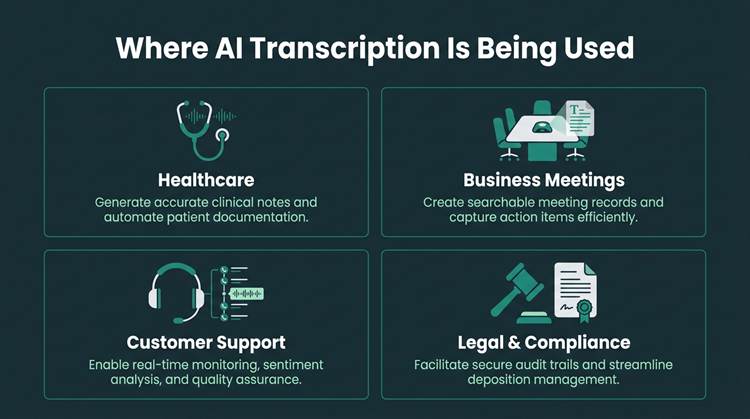
AI transcription is embedded across healthcare, enterprise, support, and legal workflows.
Accuracy: What the Numbers Actually Mean
On clean, studio-quality audio, some transcription engines can achieve high accuracy. The number sounds reassuring until you do the math: a 2% error rate across a 10,000-word transcript is about 200 wrong words. In a medical record or a legal deposition, that’s not a rounding error; it’s risk.
Real-world audio is where systems get exposed. Background noise, strong accents, crosstalk, and specialized vocabulary can drag general-purpose models down in accuracy by word error rate. That’s why “which engine” matters as much as “which technique.” A model trained on call-center audio will routinely beat a general ASR model on customer support calls, even if the general model advertises a better benchmark score.

Accuracy varies widely depending on audio quality, accent diversity, and speaker overlap.
Common Misconceptions About AI Transcription
Misconception 1: Higher accuracy percentage always means better output. Word Error Rate (WER) is usually reported on benchmark datasets, and those datasets are often far cleaner than the audio you deal with day to day. A tool claiming 98% on controlled speech can still stumble on your meetings, your customers, or your recording setup. Before you commit, run a test on a representative slice of your own audio.
Misconception 2: AI transcription replaces human review entirely. For high-stakes material like medical records, legal filings, or financial disclosures, automation speeds up the first pass but doesn’t erase the need for verification. Let the model do the bulk conversion; rely on humans for the edge cases and the consequences.
Misconception 3: All transcription APIs work the same way. The API surface is part of the product. Some platforms support streaming for real-time use cases; others only accept uploads. Some return plain text; others return structured JSON with timestamps, confidence scores, and speaker labels. If you map your workflow needs first, you’ll save yourself a lot of integration churn later.
Best AI Transcription Tools: What to Look For
The market for AI audio and video transcription tools has grown quickly, and the real differences tend to show up after the demo. Use the checklist below to pressure-test platforms against the conditions you actually operate in.
What separates a good transcription tool from the right one for your use case:
● Latency: For voice agents and live captions, low-latency streaming is as important as aggregate accuracy. Interactions that feel natural require fast responses.
● Language and accent support: If your users aren’t all “standard” US/UK English speakers, you need models trained on diverse accents and speaking styles.
● Domain vocabulary: Medical, legal, and technical terms are where general models tend to fray. Look for fine-tuning paths or domain-specific variants.
● API flexibility: Can you use both batch and streaming? Will it return structured output (timestamps, speaker labels, confidence)? Understanding what an API offers is a good primer for developers.
● Pricing model: Per-minute, per-hour, or subscription pricing changes the economics fast at scale. Model total cost around your expected volume, not the lowest advertised tier.
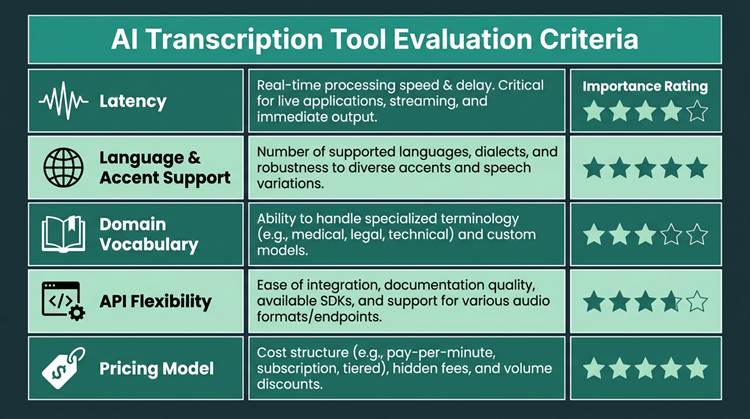
Evaluate transcription tools on these five dimensions before committing to a platform.
Why AI Transcription Matters
What you need to know about AI transcription:
● AI transcription relies on ASR to convert audio into text, with NLP used to improve readability through punctuation, grammar, and context-aware corrections.
● Accuracy can be high on clean audio, but it can dip with noise, accents, or overlapping speakers.
● The market is growing fast, with some reports projecting significant expansion in the coming years.
● Healthcare is a major user of transcription technology, while meeting transcription is a fast-growing segment.
● Batch and real-time transcription target different workflows and come with different infrastructure requirements.
● Domain-specific models consistently beat general-purpose models when vocabulary gets specialized.
● Benchmark scores are a starting point; the real test is how a tool performs on your own audio.
The Right Transcription Tool Starts With the Right Speech Engine
Most transcription rollouts don’t fail because transcription is a bad idea; they fail in the gap between benchmark numbers and real production audio. Teams pick a tool that shines on clean samples, then watch performance slide on accented speech, technical terminology, or noisy call recordings. By the time that mismatch shows up in production, switching vendors is expensive and disruptive.
Smallest.ai’s Pulse is a speech-to-text engine built for that messy reality. It targets low-latency, high-accuracy transcription across varied audio conditions, with developer-friendly APIs that support both streaming and batch workflows in production. If you’re building a voice agent, automating meeting notes, or processing customer calls at scale, Pulse is designed to stay reliable when the input audio isn’t pristine. Explore Smallest.ai pricing to map it to your volume, or review the AI voice agents architecture overview to see where Pulse sits in a broader voice AI stack.
What separates AI transcription from traditional transcription?
How accurate is AI transcription outside of studio audio?
Can AI transcription label multiple speakers in a recording?
Which industries get the most value from AI transcription?
How should I evaluate an AI transcription tool?

