Voice Recognition vs. Speech Recognition: Which Do You Need for Your Application?


Learn the key differences between voice recognition (who is speaking) and speech recognition (what is said) to choose the right tech for your application.
Voice Recognition vs. Speech Recognition: Which Do You Need for Your Application?
Speech recognition technology converts spoken words into text, focusing on what is being said. In contrast, voice recognition (also known as speaker recognition) identifies or verifies a specific person's voice, focusing on who is speaking. While often used interchangeably, these are distinct technologies with different applications, from transcribing meetings to securing bank accounts.
Understanding the difference is critical for developers, product managers, and business leaders. Choosing the right technology determines whether your application can understand commands, transcribe audio, or authenticate users with biometric precision.
The global market for these technologies reflects their growing importance; one analysis projects the voice recognition market size will grow from USD 6.03 billion in 2025 to USD 19.51 billion by 2033 (SkyQuest Technology, 2025).
What Is Speech Recognition? The 'What'
Speech recognition, also known as Automatic Speech Recognition (ASR), is the technology that converts human speech into written text. Its primary function is to understand what is being said, regardless of who is speaking. It works by analyzing sound waves, identifying phonetic units, and using custom language models to predict the most likely sequence of words.
Speech recognition, formally known as Automatic Speech Recognition (ASR), is a technology that enables a machine to process human speech and convert it into a written, machine-readable format. As defined by IBM (2026), its primary goal is to translate spoken language into text. Virtual assistants like Alexa or Google Assistant use ASR as the first step to understand the words you said before they can figure out your intent. Our Voice AI platform offers high-accuracy ASR models designed for enterprise applications.
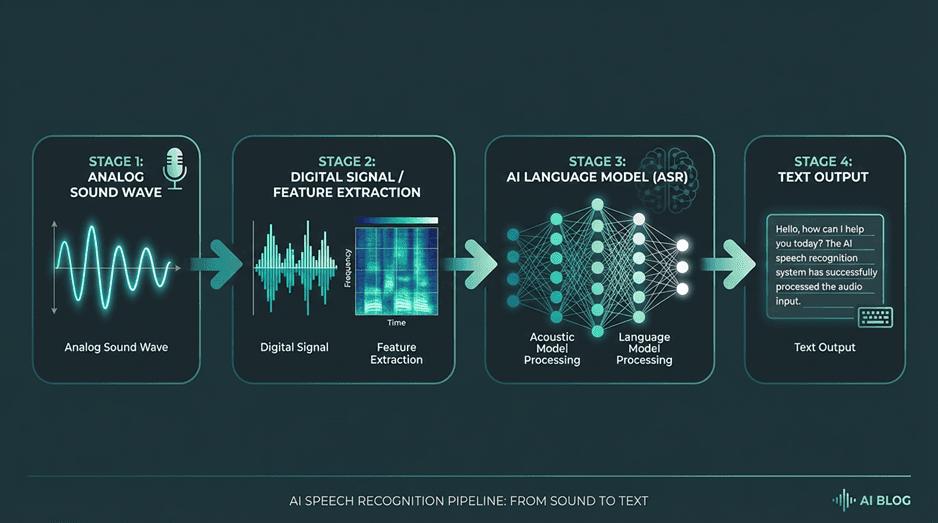
Speech recognition systems convert analog soundwaves into digital data, then use AI models to transcribe it into text.
How Speech Recognition Works
Modern AI speech recognition technology operates through a sophisticated pipeline. The process generally involves several key steps:
Acoustic Analysis: A microphone captures sound waves from the speaker. The system converts these analog waves into a digital signal.
Feature Extraction: The digital signal is cleaned to remove background noise and broken down into small segments. The system analyzes these segments to identify phonemes, the smallest units of sound in a language (like the 'k' sound in 'cat').
Language Modeling: The system uses a language model, trained on vast amounts of text data, to predict the most likely sequence of words based on the identified phonemes. This step helps differentiate between homophones like 'to', 'too', and 'two' by considering the context of the sentence.
Text Output: The most probable sequence of words is assembled and output as text.
Common Applications of Speech Recognition
Because it focuses on content, ASR is the foundation for any application that needs to understand or document spoken language:
Virtual Assistants: Powering Siri, Alexa, and Google Assistant to understand user commands and queries.
Transcription Services: Automatically converting audio and video files into text for meetings, interviews, and media content. This is a core function of real-time speech recognition.
In-Car Systems: Enabling drivers to control navigation, music, and calls with voice commands.
Healthcare: Allowing clinicians to dictate patient notes directly into electronic health records (EHRs), a process known as medical dictation.
Customer Service: Transcribing calls for analysis and powering interactive voice response (IVR) systems. Smallest.ai offers specialized models for contact center intelligence.
What Is Voice Recognition? The 'Who'
Voice recognition, also known as speaker recognition, is a biometric technology that identifies who is speaking. It analyzes unique vocal characteristics like pitch, tone, and accent to create a 'voiceprint'. This technology is used for authentication and personalization, confirming a speaker's identity rather than understanding the words they say.
Voice recognition, or speaker recognition, is a biometric technology used to identify an individual based on their unique vocal characteristics. It does not care about the words being said; instead, it analyzes the underlying voiceprint. According to the National Institute of Standards and Technology (NIST, 2025), speaker recognition technology aims to determine who is speaking from the acoustic properties of their speech.
How Voice Recognition Works
The process of identifying a speaker involves creating and matching a 'voiceprint', a digital model of a person's unique vocal attributes. These attributes are a combination of physiological traits (the shape of the vocal tract) and behavioral patterns (accent, pace, and pronunciation).
There are two primary modes of operation for voice recognition, and you can learn more about how voice recognition works in detail on our blog:
Speaker Identification: This answers the question, “Who is speaking?” The system compares a voice sample against a database of known voiceprints to find a match (a one-to-many comparison). This is used in law enforcement to identify a suspect from a recording.
Speaker Verification (or Authentication): This answers the question, “Is this person who they claim to be?” The system compares a live voice sample to a pre-enrolled voiceprint for a specific user (a one-to-one comparison). This is the method used for security applications.
Common Applications of Voice Recognition
The focus on identity makes voice recognition ideal for security and personalization:
Biometric Authentication: Banks and financial institutions use voice verification for customers to access accounts over the phone, preventing fraud. Smallest.ai provides secure voice biometrics solutions for this purpose.
Device Security: Unlocking smartphones or smart home devices with a specific user's voice.
Personalization: Smart speakers like Google Home can identify different family members by voice to provide personalized calendars, music playlists, and news updates.
Law Enforcement: Identifying suspects from voice recordings in criminal investigations.
Conversational AI: Personalizing chatbot interactions by recognizing a returning customer. This is a key aspect of voice recognition in conversational AI.
Voice Recognition vs. Speech Recognition: A Head-to-Head Comparison
While both technologies analyze the human voice, their goals, methods, and outputs are fundamentally different. The following table breaks down the key distinctions to help you decide which technology fits your needs.
Feature | Speech Recognition (ASR) | Voice Recognition (Speaker Recognition) |
|---|---|---|
Primary Goal | To understand what is being said. | To identify who is speaking. |
Core Function | Transcribes spoken words into text. | Matches a voiceprint to a known identity. |
Output | A string of text. | A user identity or a verification (yes/no) result. |
Key Technology | Acoustic and language models. | Biometric analysis and pattern matching. |
Example Use Case | Dictating a text message. | Unlocking your phone with your voice. |
Dependency | Language-dependent (requires models for each language). | Language-independent (analyzes vocal traits, not words). |
Decision Checklist: ASR vs. Speaker Recognition
Use these questions to determine which technology is the right fit for your application.
Security Level: Is your primary goal to authenticate a user and secure access to sensitive information? If yes, you need voice recognition for its biometric capabilities.
User Enrollment: Can you require users to enroll their voice by providing samples beforehand? Enrollment is necessary for voice recognition but not for general-purpose speech recognition.
Language Support: Does your application need to understand and transcribe words in one or more specific languages? If so, you need speech recognition with appropriate language models.
Operating Environment: Will the application be used in noisy environments? While both technologies are affected by noise, speech recognition systems often have advanced noise cancellation to isolate words, whereas background noise can interfere with creating a clean voiceprint for voice recognition.
When Do You Need Both?
Some of the most powerful voice-enabled applications combine both technologies to create a comprehensive user experience. In these hybrid systems, voice recognition first identifies the user, and then speech recognition processes their commands. This synergy enables both security and functionality.
Consider a smart home system. When a user says, “Hey Google, add milk to my shopping list,” the device performs two actions simultaneously:
Voice Recognition: It identifies the speaker as 'Jane' from her unique voiceprint.
Speech Recognition: It transcribes the command “add milk to my shopping list” into text.
The system then combines these results to add 'milk' to Jane's specific shopping list, not anyone else's in the household. This blend of identification and transcription is what makes modern voice assistants so effective. Developers looking to build such systems often rely on a suite of speech-to-text APIs that can handle these complex tasks. The Smallest.ai platform provides integrated APIs that offer both capabilities.
Choosing the Right Technology for Your Needs
The choice between voice recognition vs. speech recognition boils down to your application's primary goal. Ask yourself one simple question: Is it more important to know who is speaking or what they are saying?
You need Speech Recognition if your application needs to:
Transcribe audio to text.
Act on spoken commands.
Enable voice search functionality.
Provide closed captions for video content.
You need Voice Recognition if your application needs to:
Authenticate users for secure access.
Personalize experiences for different users.
Identify speakers in a recorded conversation.
Prevent unauthorized use of a device or service.
By clearly defining your objective, you can select the right tool and build a more intuitive, effective, and secure product. At Smallest.ai, our Voice AI platform provides developers with powerful speech models and tools needed to integrate these capabilities into any application. Contact our team to discuss your specific use case.
Is voice recognition more secure than a password?
Can speech recognition understand different accents and dialects?
Can I use speech recognition offline?
What are some voice recognition vs. speech recognition examples?
What is the difference between speaker verification vs. identification?
What is the difference between ASR vs. NLP?
What is the difference between voice biometrics vs. speech-to-text?

