Accent-Adaptive Speech AI for Global Contact Centers: Improving Clarity Across Regions


Accent-adaptive speech AI cuts WER gaps across regions. Get a practical plan for evaluation, fine-tuning, monitoring, and ROI in contact centers.
Accent-adaptive speech AI has moved from “nice to have” to table stakes for enterprise contact centers. It’s often the difference between a caller who feels understood and one who bails out of pure frustration. As contact centers scale across regions, the range of accents on inbound calls expands right along with them. Someone calling from Lagos, Chennai, or Sao Paulo may be speaking the same language your system prompts for, but the phonetics can differ enough to break models trained on a narrow slice of English or Spanish.
This is for contact center architects, CX technology leads, and AI engineers making speech AI decisions at scale. The goal is practical clarity: why standard ASR falls apart under accent diversity, what the research says actually improves robustness, how to pressure-test a vendor’s claims, and how to roll out a deployment that keeps working as you add regions.
Why Standard ASR Models Struggle With Accented Speech
An accent, in the sociolinguistic sense, is a distinctive way of pronouncing a language shaped by geography, ethnicity, first-language interference, and socioeconomic background. ASR runs into trouble because most large training corpora overweight a small set of “default” accent profiles: typically General American English, Received Pronunciation British English, and a few other prestige varieties. Everything outside that distribution shows up less often in training, and you see it immediately in lower confidence scores and higher error rates.
That gap isn’t subtle. A Stanford-led study of top ASR services found error rates nearly doubled for African American speakers compared to white speakers, with word error rates of 35% versus 19% respectively (Stanford News, 2020). That’s not a rounding error; it’s the point where transcripts stop being reliable inputs for intent detection, compliance logging, or QA scoring. At contact center volumes, the operational fallout is predictable: misrouted tickets, self-service flows that collapse, and escalations that didn’t need to happen.
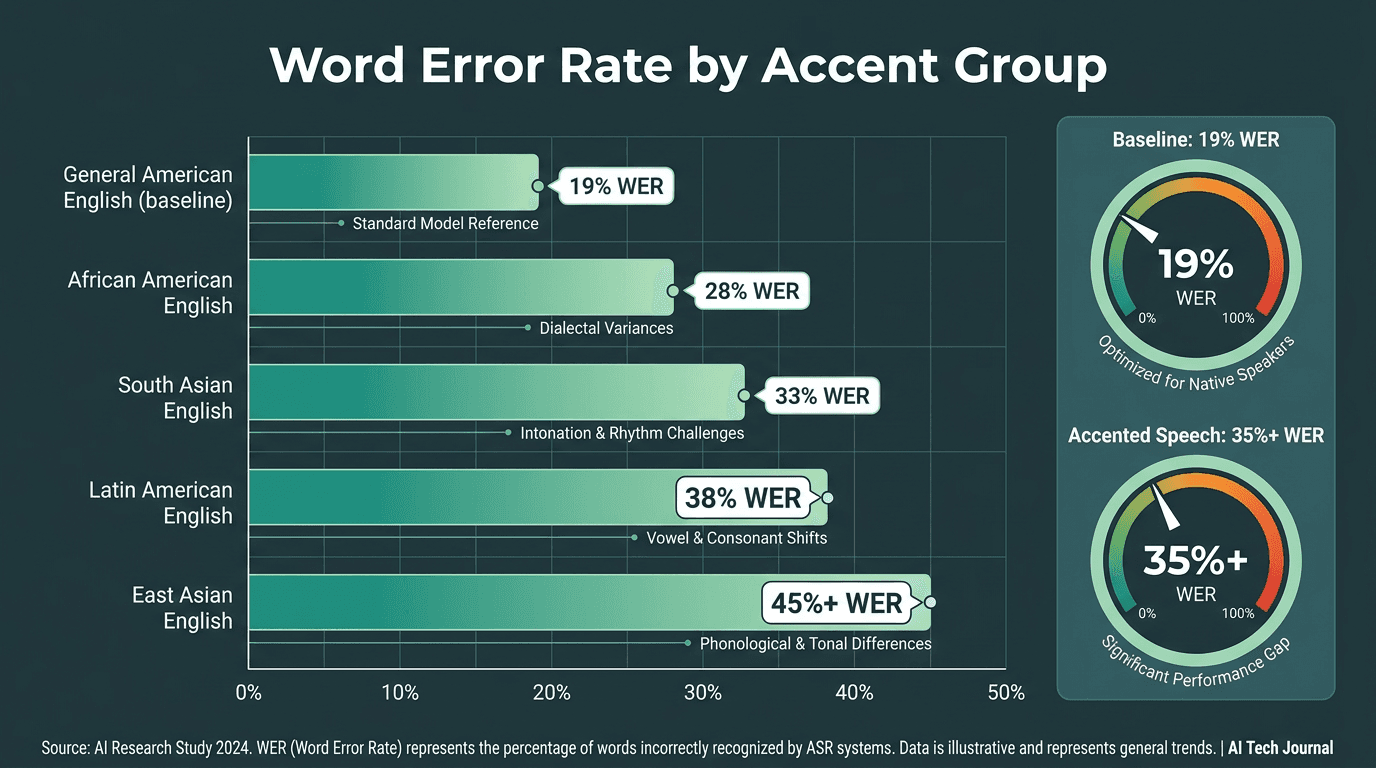
WER disparities across accent groups reveal the cost of training on narrow speech corpora.
The underlying issue isn’t that accent-diverse speech is inherently “hard.” The models just haven’t been exposed to enough of it. Work on Automatic Speech Recognition (ASR) for call centers makes the same point: architecture rarely sets the ceiling here. Training data distribution and a sane fine-tuning strategy do.
The Business Cost of Getting Accent Recognition Wrong
A 2020 study from CSA Research found that 75% of consumers are more likely to purchase from the same brand again if customer care is offered in their language. That number usually gets pulled into multilingual support decks, but the same dynamic shows up with accents. When an IVR or transcription system repeatedly mishears someone, the message isn’t “our model struggled”, it’s “this system wasn’t built for you.” That’s a retention problem wearing a technical mask.
The downstream costs of poor accent recognition compound across the contact center stack:
Higher handle times: Agents burn time untangling misrouted calls and re-asking questions the IVR should have captured cleanly.
Failed self-service: Voice bots that can’t reliably parse accented input shove callers to live agents, wiping out automation ROI.
Compliance gaps: In regulated industries, bad transcripts turn into audit risk when recordings are reviewed.
Agent attrition: Accent bias in AI systems and from callers contributes to high contact center agent turnover rates, as agents who feel their accent is a persistent barrier are more likely to leave.
Analytics blind spots: Call center QA and conversation analytics only work if transcripts are trustworthy. Systematic errors for specific accent groups skew the data and the decisions built on top of it.
How Accent Adaptation Actually Works: The Technical Picture
There isn’t one magic switch for accent robustness. Production systems usually combine a few techniques, and each comes with trade-offs. Knowing the menu makes vendor conversations sharper, and helps you spot hand-wavy promises.
Accent-specific codebooks are a strong recent direction. A 2023 paper on arXiv proposed trainable codebooks that capture accent-specific phonetic information, letting the model adapt internal representations per accent group without retraining the entire network. The authors reported meaningful gains on both seen and unseen English accents.
Activation steering targets the activation space of speech foundation models. Instead of reshaping training data or fine-tuning weights, it applies lightweight interventions at inference time to reduce accent-driven recognition errors. A 2024 arXiv pre-print showed this can improve fairness in deployment without major compute overhead (Activation Steering for Accent Adaptation in Speech Foundation Models, arXiv, 2024).
Fine-tuning on accented data is still the workhorse approach for most production teams. Research from Google shows that fine-tuning an ASR model on a small amount of accented speech, sometimes as little as 15 minutes, can deliver a substantial portion of the total possible accuracy improvement for that accent. That’s an unusually high return on a small data budget, and it’s why contact centers sitting on region-specific call recordings are also sitting on a fine-tuning asset.
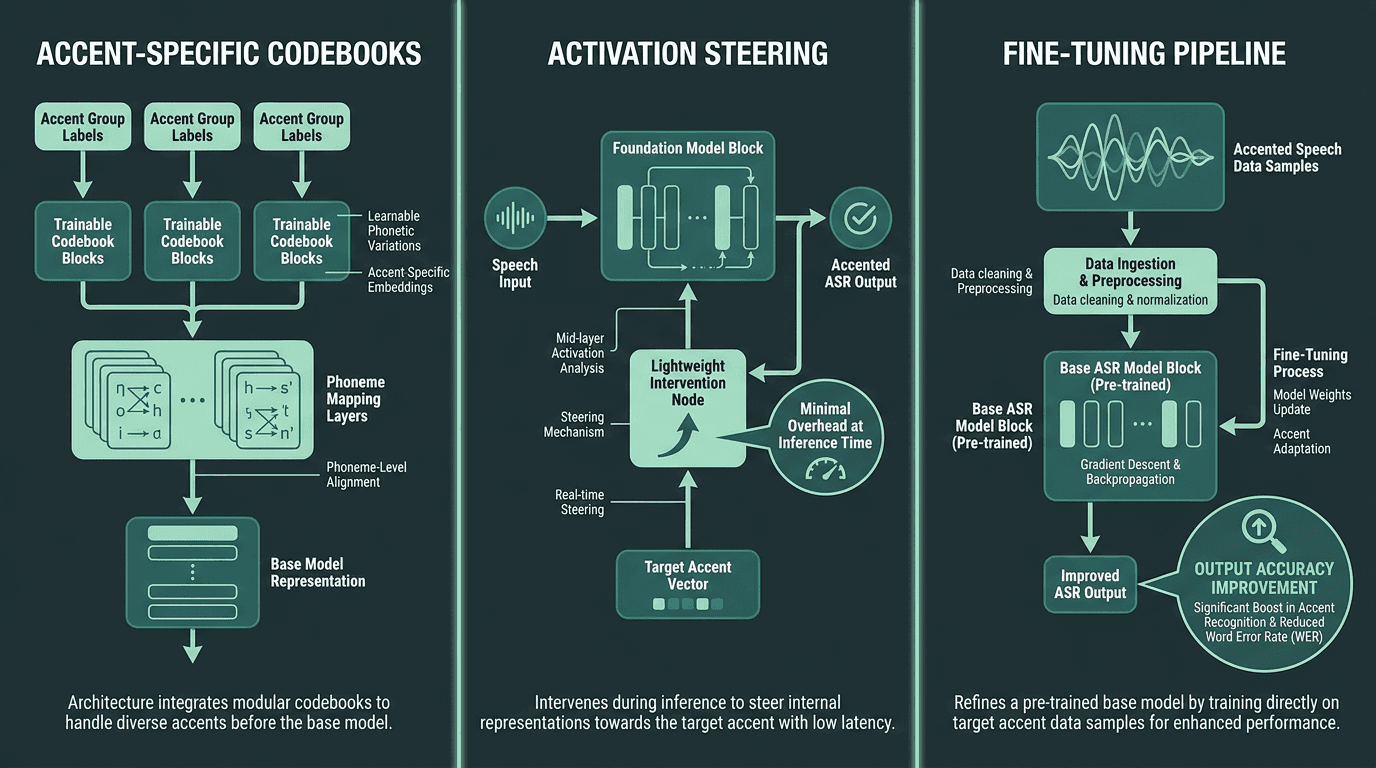
Three technical approaches to accent adaptation, each with different trade-offs in cost, latency, and coverage.
What Most Evaluations Get Wrong About Accent Robustness
Most ASR evaluations stop at a clean benchmark dataset and a single accuracy number. That’s convenient, and misleading. Benchmarks like LibriSpeech or CommonVoice are useful, but they don’t resemble contact center audio: background noise, telephony compression, overlapping speech, and a caller mix that rarely matches the benchmark’s accent distribution.
A model that posts 95% accuracy on LibriSpeech can slide to 78% on your real call recordings if your customers lean toward accents that benchmark barely represents. If you want a number you can trust, test on your own data, or at least on a held-out set that mirrors your caller demographics as closely as you can make it.
When you run that evaluation, break the test set out by accent group and report WER per segment, not just a blended average. Aggregate accuracy is great at hiding the exact disparity you need to fix. A system that’s 92% overall but 74% for your largest non-native speaker segment isn’t “92% accurate” in any operational sense. The post on handling accents, code-switching, and noisy audio lays out this evaluation pattern in practical terms.
Building an Accent-Aware Deployment Strategy
Rolling out accent-adaptive speech AI isn’t a one-and-done settings change. Treat it like a lifecycle, and it breaks into three phases.
Phase 1: Audit your caller base. Before you pick a model or start fine-tuning, map the accent distribution of inbound calls. Pull a stratified sample across regions, time zones, and customer segments. The audit tells you which accents dominate volume, where your current system fails, and what data you already have available for fine-tuning.
Phase 2: Fine-tune or select a model with demonstrated accent coverage. If your vendor supports custom fine-tuning, use your call recordings. If they don’t, evaluate out-of-the-box performance against your own accent mix rather than trusting published benchmarks. Favor models explicitly trained or validated on diverse English varieties. Indian English, Nigerian English, Latin American Spanish, Mandarin-accented English, based on where you operate.
Phase 3: Monitor and iterate. Start production with per-accent WER monitoring on day one. Set alert thresholds for degradation inside specific segments. As your caller base shifts (or you launch in a new region) monitoring tells you when you’ve crossed the line from “acceptable drift” to “time to fine-tune again.” Speech AI that excels across languages and accents is usually the result of iteration, not a single heroic training run.
The ROI Case for Investing in Accent-Adaptive Speech AI
Industry analyses show that AI-powered speech systems can significantly reduce average call handling times, in some cases by up to 40%. That number only holds if recognition is good enough for the rest of the automation stack to do its job. If accent-driven errors push intents into the wrong buckets, automation either fails quietly or punts to an agent, and the time savings evaporate.
The ROI math for accent adaptation is refreshingly direct. Start with your current self-service containment rate, then estimate how much of the failure rate is caused by recognition errors concentrated in specific accent groups. Even a conservative assumption (say 15% of failed self-service interactions are accent-related) can translate into a meaningful drop in agent-handled volume once fixed. Multiply that by cost per live interaction and the payback window tends to be short. For a broader view of how conversational AI boosts ROI across the stack, the same logic repeats across use cases.
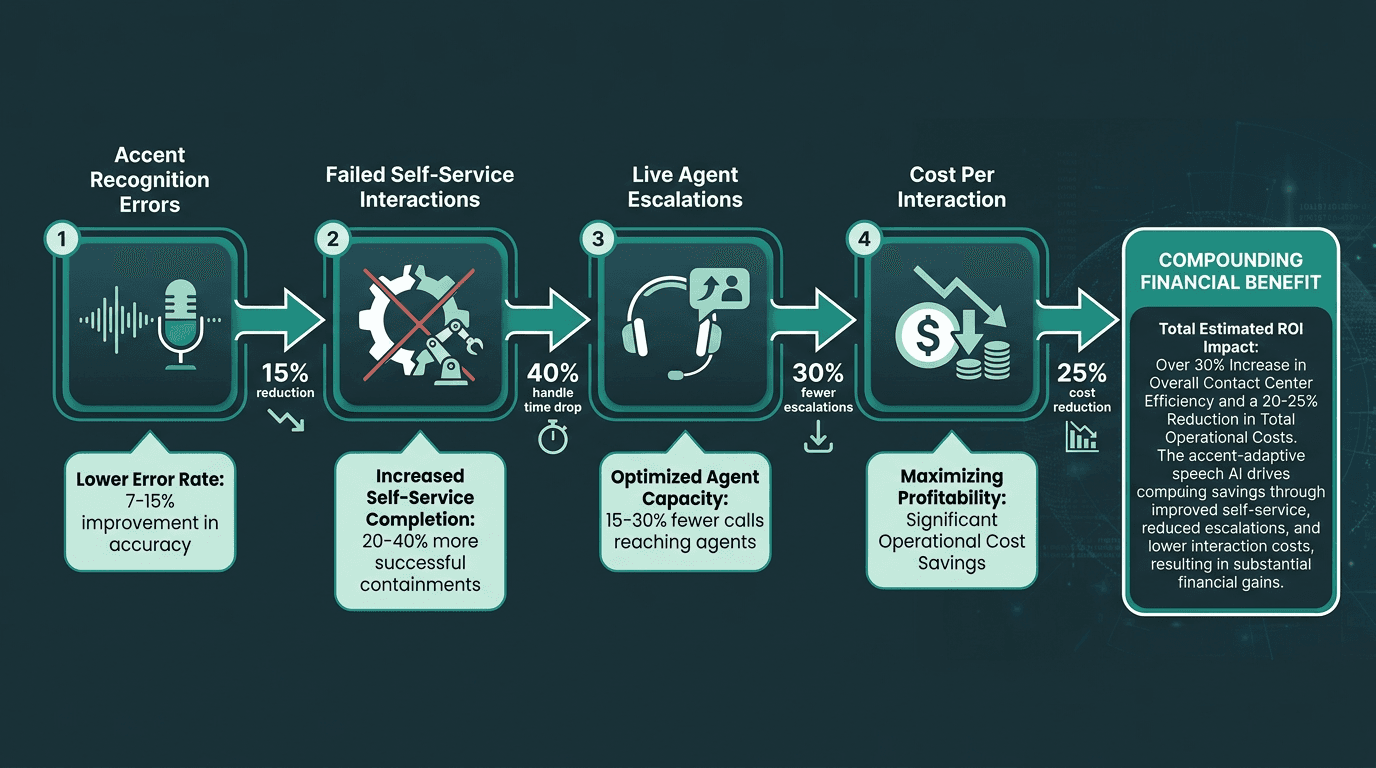
Fixing accent recognition errors at the input layer compounds into measurable cost savings across the entire call flow.
Advanced Considerations: Code-Switching, Telephony Noise, and Real-Time Constraints
Global contact centers also deal with a messier reality than “one caller, one accent.” Plenty of people code-switch mid-sentence, blending languages or dialects in ways many models still handle badly. A caller in Mumbai might speak English but drop in Hindi vocabulary. A caller in Miami might flip between English and Spanish inside the same sentence. Models trained on monolingual corpora don’t have a clean way to represent that, and word error rates can spike on the switched segments.
Telephony compression makes things worse. Most contact center audio arrives through narrow-band or wide-band codecs that shave off high-frequency detail. Accented speech can carry distinctive cues in exactly the ranges that get flattened or discarded, which means an already fragile recognition path becomes even more brittle. Models fine-tuned on telephony-grade audio (not studio recordings) tend to hold up better once you hit production.
Latency is the other constraint you can’t hand-wave away. Batch transcription can trade time for accuracy; a live voice bot can’t. If a model only gets robust by leaning on heavy ensembles or slow inference pipelines, it won’t survive real-time IVR or agent-assist requirements. That’s why speech AI built for contact centers is a different engineering problem than general transcription: you’re balancing accuracy and speed under ugly audio conditions.
Putting It Together: From Accent Problem to Solved Deployment
Accent-related failure in contact center speech AI isn’t mysterious, and it’s not inevitable. The research points to workable techniques, and the business incentives are clear. Teams that actually solve it tend to do three things consistently: choose models that can support accent diversity, evaluate with discipline instead of benchmarks-as-theater, and run deployment as a continuous coverage program, not a one-time checkbox.
If you’re building or re-evaluating a speech AI stack, AI for the modern contact center starts with infrastructure designed for acoustic diversity from the start. Smallest.ai’s Pulse speech-to-text model is built to handle accent variability, telephony noise, and the low-latency requirements global contact centers live with. Paired with the company's voice agents, it’s a foundation for accent-aware automation that holds up across regions without constant manual triage. Explore Smallest.ai pricing for a view of how that stack maps to your scale.
Key Takeaways
The core principles for building accent-adaptive speech AI in global contact centers:
Standard ASR models show large, documented accuracy gaps for non-dominant accent groups. A Stanford study found WER nearly double for African American speakers versus white speakers (Stanford News, 2020).
The business impact is immediate: failed self-service, longer handle times, compliance risk, and agent attrition can all trace back to accent recognition breakdowns.
Fine-tuning on even small amounts of accented speech (as little as 15 minutes in some studies) can deliver a majority of the maximum possible accuracy improvement for that accent group.
Evaluate vendors on your own caller data, segmented by accent group, rather than leaning on published benchmarks that may not match your demographics.
Ship with per-accent WER monitoring from day one, and treat coverage as a continuous improvement loop, not a one-time setup task.
Real-time contact center use cases demand both accent robustness and low latency, which is a different target than general-purpose transcription.
What is accent-adaptive speech AI, and how does it differ from standard ASR?
How much accented speech data is needed to meaningfully improve recognition accuracy?
Can one speech AI model handle multiple accents at once, or do you need a separate model per accent?
How should contact centers measure accent recognition performance in production?
Does improving accent recognition require replacing the entire speech AI stack?

