

Voice bot platform comparison for 2026: Smallest.ai vs ElevenLabs, Deepgram, OpenAI, Cartesia, and AssemblyAI on latency, quality, and stack coverage.
A voice bot is software that listens to speech, figures out what the speaker wants, and answers back with synthesized audio, fast enough to hold a real conversation. That makes it fundamentally different from a basic IVR tree that just plays prompts and waits for keypad input. Voice bots are increasingly being used in customer support, scheduling, sales, healthcare, and internal operations as organizations look to automate repetitive conversations without sacrificing responsiveness.
Picking a voice bot platform is less about brand names and more about the stack under the hood: speech recognition, language modeling, and text-to-speech. Those choices show up immediately in latency, accuracy, and your monthly bill. This piece lays out what a voice bot actually is, what to evaluate, and which solutions look strongest for 2026, with Smallest.ai at the top of the comparison.
What Makes a Voice Bot Work
A voice bot works by running a tight loop: it turns audio into text (speech-to-text), uses a language model to interpret intent and draft a response, then turns that response into audio (text-to-speech) and streams it back. For the exchange to feel like conversation, the full round trip needs to happen quickly. Lower latency generally leads to more natural and responsive voice interactions. As latency increases, conversations begin to feel less fluid and more interrupt-prone.
If you look closely at voice bot architecture, you see why swapping one layer can change the whole experience. Fast transcription paired with slow synthesis still feels slow. In production, platforms that control the full pipeline, or integrate their components tightly enough to behave like a single system, usually beat stacks stitched together from separate point APIs.
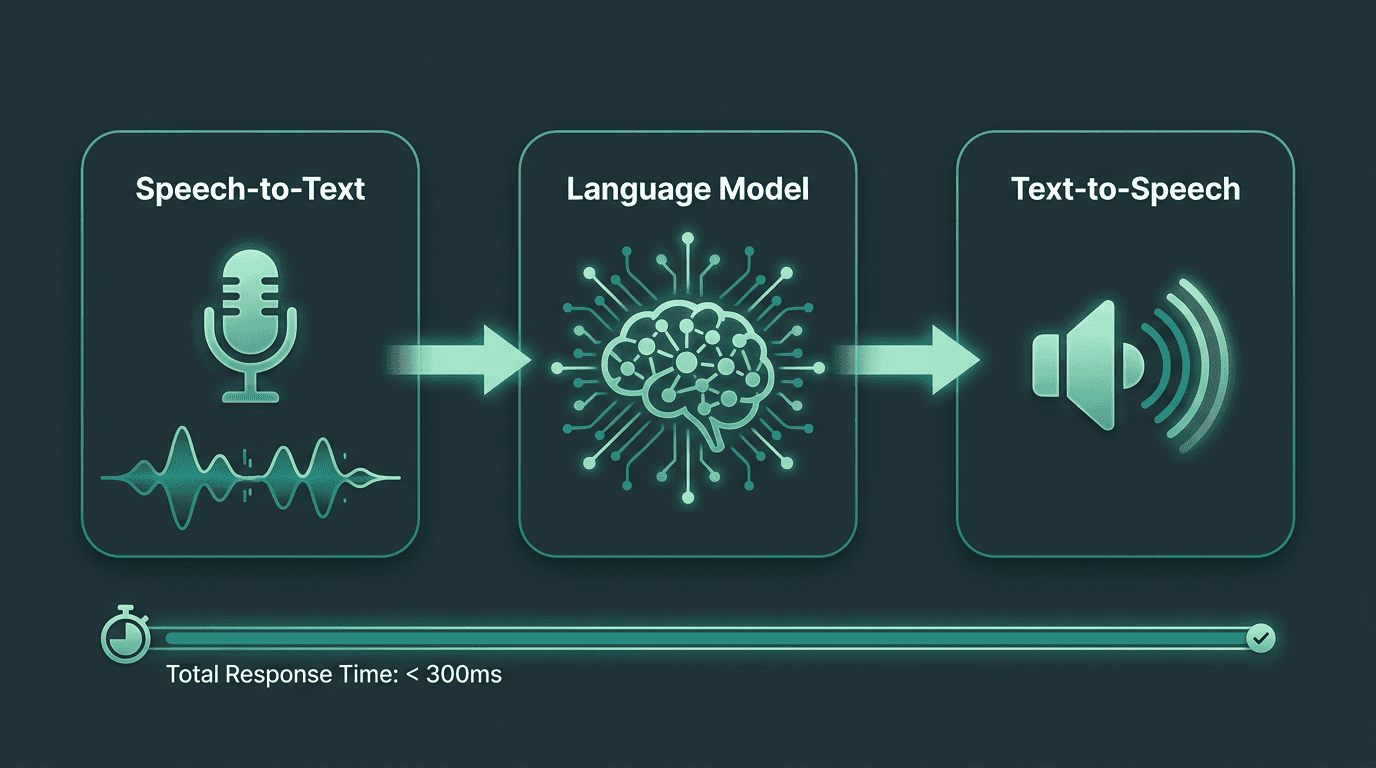
Every millisecond saved across STT, LLM, and TTS layers compounds into a more natural **voice bot** experience.
How to Evaluate a Voice Bot Platform
Comparisons get messy when teams argue past each other: one person is optimizing for voice quality, another for cost, another for time-to-ship. These six criteria mirror the checklist product and engineering teams tend to use when they are about to commit to a platform.
Evaluation criteria used in this comparison:
Latency: End-to-end response time from speech input to audio output, measured in milliseconds.
Voice quality: Naturalness, expressiveness, and multilingual range of synthesized speech.
STT accuracy: Word error rate across accents, noisy environments, and domain-specific vocabulary.
Developer experience: Quality of APIs, SDKs, documentation, and time-to-first-call.
Full-stack vs. point solution: Whether the platform covers the entire voice bot pipeline or just one layer.
Pricing model: Per-character, per-minute, or per-request billing and how costs scale.
Smallest.ai: The Full-Stack Voice Bot Platform
Smallest.ai is built for production voice bots, rather than retrofitting voice onto a general AI platform. The lineup spans the whole pipeline: Lightning for low-latency text-to-speech, Pulse for speech-to-text, Hydra for real-time speech-to-speech translation, Electron as a conversational small language model tuned for voice turns, and Atoms as the agent layer that orchestrates the conversation. All of it is exposed through the Waves API.
Where Smallest.ai tends to win day-to-day is latency, especially on the synthesis side. Lightning is designed to start streaming audio in under 100ms for the first chunk, which is roughly the point where TTS stops feeling like "the system is thinking" and starts feeling like a live rep answering. Atoms also supports no-code voice AI solutions for teams that want to ship without building custom glue code for every integration.
Lightning also includes voice cloning, so teams can keep a consistent branded voice across touchpoints without recording massive datasets. The platform is built around a usage-based model, with more details available for Smallest.ai voice agents.
Where Smallest.ai leads:
Sub-100ms TTS first-chunk latency via Lightning, critical for real-time voice bots.
Unified stack: STT, TTS, STS, LLM, and agent orchestration from one vendor.
Voice cloning with minimal source audio, suitable for brand-consistent deployments.
Atoms SDK supports both code-first and no-code deployment paths.
One real tradeoff: Smallest.ai is a focused voice AI vendor, not a hyperscaler. That usually means fewer prebuilt third-party integrations than you will find in the big cloud ecosystems. If your deployment depends on specific third-party integrations, validate compatibility requirements during evaluation.
ElevenLabs: Premium Voice Quality, Narrower Scope
ElevenLabs is primarily known for text-to-speech and voice cloning. The platform focuses heavily on voice quality, multilingual support, and voice cloning. If you are producing content, audiobooks, or other media where the voice is the product, those capabilities are often important.
Voice bot work is where the boundaries show up. ElevenLabs is, first and foremost, a TTS platform: no STT layer, no native conversational model, and no agent orchestration out of the box. Building a full voice bot around it means choosing and integrating the missing pieces yourself, then paying the latency tax at every handoff. ElevenLabs is commonly evaluated when voice quality is the primary requirement and teams are comfortable assembling the remaining voice bot components separately.
Deepgram: STT Specialist With Growing Voice Capabilities
Deepgram is widely used for real-time speech recognition workloads. Its Nova-3 is often used for telephony audio, accented speech, and domain vocabulary that tends to break general models. Deepgram is often evaluated when speech-recognition performance is a primary consideration.
Deepgram has also pushed into synthesis with Aura, covering two of the three core layers. The missing piece is still the conversation brain and the orchestration around it: there is no native conversational language model or agent layer, so developers have to wire in an LLM and manage state, tools, and routing themselves. Deepgram is often used as the transcription layer in custom voice bot stacks that already have conversational and synthesis infrastructure.
OpenAI: Broad Capability, Voice Bot as a Byproduct
OpenAI provides voice capabilities through its Realtime API. The platform provides integrated speech recognition, language processing, and speech synthesis through a single API surface. This makes speech-to-speech possible via GPT-4o, bundling STT, language understanding, and TTS into a single API surface.
Once you push into sustained volume, the economics and consistency matter more. OpenAI is frequently evaluated for conversational workflows that require broad language understanding and flexible reasoning capabilities. OpenAI builds general-purpose AI infrastructure; voice bots are one workload among many, not the center of the design. Organizations often evaluate purpose-built voice platforms and general-purpose AI platforms differently depending on latency, orchestration, and deployment requirements.
Cartesia: Low-Latency TTS for Developers
Cartesia is aimed squarely at real-time TTS, with streaming latency as the headline metric. Its Sonic model is designed for low-latency speech synthesis. The API is straightforward, which makes it easy to slot into an existing service.
As with ElevenLabs, Cartesia is a point solution focused on synthesis. There is no STT layer, no built-in language model, and no agent orchestration. That is not a flaw so much as a product boundary: you bring the rest of the pipeline. Cartesia makes sense when you already have transcription and LLM infrastructure and you are specifically trying to improve the TTS layer without rewriting everything else.
AssemblyAI: Audio Intelligence Beyond Transcription
AssemblyAI plays a slightly different game. Its strength is audio intelligence: transcription plus speaker diarization, sentiment analysis, topic detection, and summarization. If your "voice bot" work is really about understanding calls after they happen, AssemblyAI has a lot more surface area than a pure STT API.
It does offer real-time streaming transcription, but there is no TTS layer and no agent orchestration. In a voice bot stack, AssemblyAI fits best as the STT and analysis layer when post-call workflows, QA, or compliance matter as much as the live transcript.
Head-to-Head: Voice Bot Platform Comparison
Platform | STT | TTS | Agent Orchestration | Latency Profile | Typical Usage Pattern |
|---|---|---|---|---|---|
Smallest.ai | Yes | Yes | Yes | Low-latency STT and TTS | Full-stack voice bot deployments |
ElevenLabs | Yes | Yes | Yes | TTS-focused | TTS-focused deployments |
Deepgram | Yes | Yes | Yes | STT-focused | STT-focused deployments |
OpenAI | Yes | Yes | Partial (via API) | Varies by component | General-purpose AI workflows |
Cartesia | No | Yes | No | Low-latency TTS | Speech-synthesis deployments |
AssemblyAI | Yes | No | No | Async-focused | Audio analysis workflows |
If you would rather build than spreadsheet, you can make a voice agent in Python with Smallest.ai's Waves API, using an end-to-end example that wires STT, an LLM, and TTS together. For teams stepping back and evaluating the broader category, the conversational AI platform overview explains where voice bots sit inside larger AI product architectures.
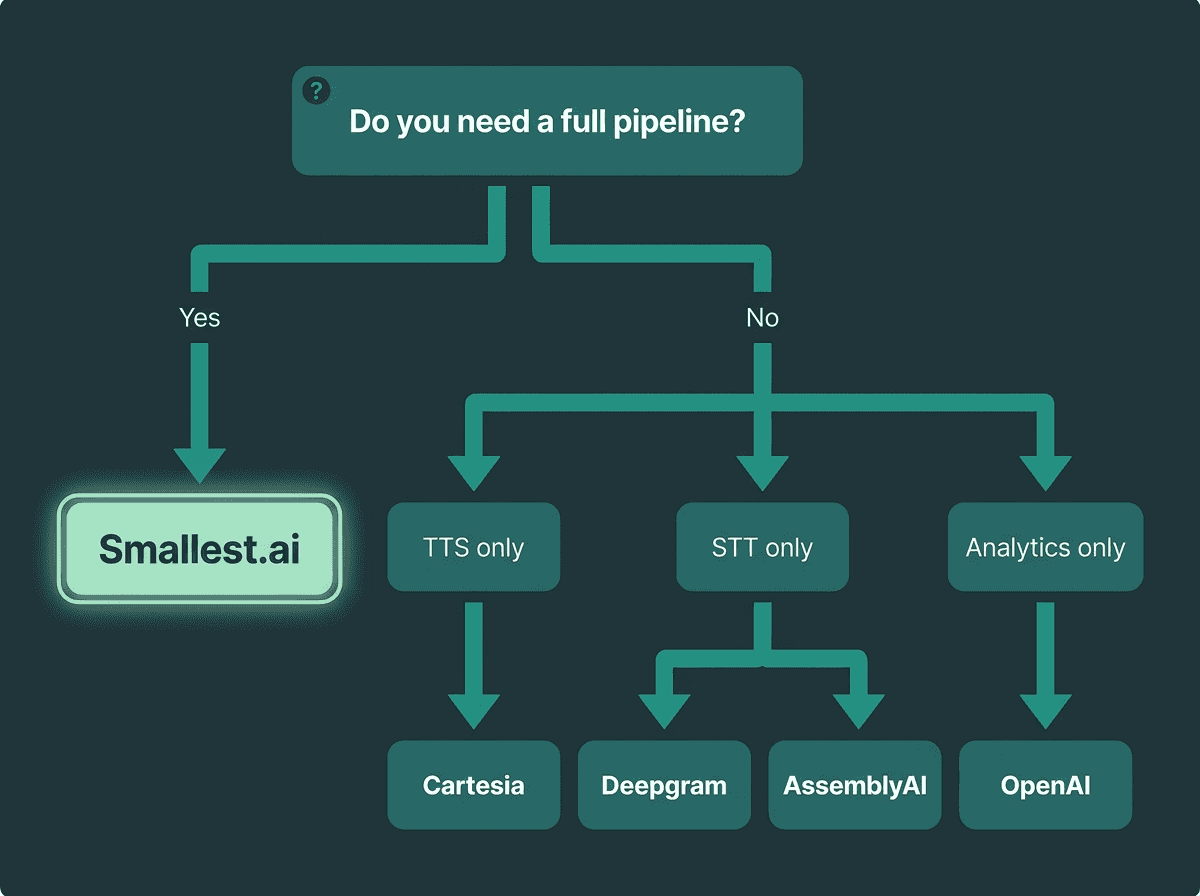
Match your voice bot requirements — full pipeline, TTS, STT, or analytics — to the right platform.
The Problem Most Voice Bot Projects Run Into
Most voice bot projects do not fail because the language model is "bad." They fail because latency piles up across a stack that was never designed to behave like one system. A team picks a strong STT provider, bolts it to an LLM over an API, then adds a TTS service on the output side. Each additional service introduces processing and network overhead that can noticeably increase response times. Add enough hops and you are past a second round-trip, which makes the bot sound hesitant and robotic even when the wording is correct.
That is the gap Smallest.ai's Atoms platform is meant to close. Keeping STT (Pulse), the conversational model (Electron), and TTS (Lightning) inside a unified, co-optimized stack removes the inter-service overhead that drags down assembled pipelines. What you get is a voice bot that answers on human timing, not server timing. If you are moving from evaluation to implementation, the Smallest.ai blog collects architecture patterns, build decisions, and use cases across industries.
Build Voice Bots on a Unified Voice AI Stack
Voice bot performance depends on how well speech recognition, language understanding, and speech synthesis work together. Smallest.ai combines Pulse STT, Lightning TTS, and Atoms orchestration into a platform built for real-time voice interactions, helping teams move from prototype to production without stitching together multiple vendors.
What is a voice bot, and how is it different from a chatbot?
What latency should a good voice bot hit?
Can a voice bot support multiple languages?
Do I need to code to build a voice bot?
How is a voice bot priced, and what are the common cost traps?

