Voice Biometrics for AI Agents: Adding Secure Speaker Verification to Voice Workflows


Voice biometrics for AI agents, explained: speaker verification basics, enrollment tradeoffs, anti-spoofing (PAD), compliance needs, and integration patterns.
Voice biometrics has moved well past the "only for three-letter agencies" phase. As AI voice agents start doing work that actually matters, processing loan applications, approving account changes, and authenticating banking transactions, "who is speaking?" stops being a philosophical question and becomes a concrete engineering requirement.
This piece lays out the mechanics of speaker verification, how it fits into modern AI agent architectures, where implementations tend to break, and how to ship workflows that don’t punish users for trying to be secure. The same core patterns show up across financial services, healthcare, and enterprise IT support: you need a clean enrollment strategy, a verification path that doesn’t derail the conversation, defenses against spoofing, and integration patterns that don’t turn into a multi-quarter rewrite.
What Voice Biometrics Actually Does
Ignore the vendor gloss and voice biometrics is straightforward: it builds a mathematical model of a person’s voice (a voiceprint), then compares new audio against that model to decide whether the speaker matches. That voiceprint encodes both physiology (vocal tract shape, nasal passages, mouth geometry) and behavior (speaking rate, pitch contour, rhythm). Put together, those signals are meaningfully harder to fake than a password or PIN, because they encode both physiology and learned behavior rather than a memorized string.
One distinction gets lost in a lot of product conversations, and it matters. Speaker recognition on Wikipedia separates two related tasks: speaker verification is a 1:1 check, does this voice match the identity being claimed? (while speaker identification is a 1:N search) who in this database is speaking? In AI agent workflows, verification is usually the right tool. The user says, "I am Maya Patel," and the system compares Maya’s enrolled voiceprint to the live audio and returns a confidence score. Identification is a very different, surveillance-adjacent category with its own legal and ethical baggage.
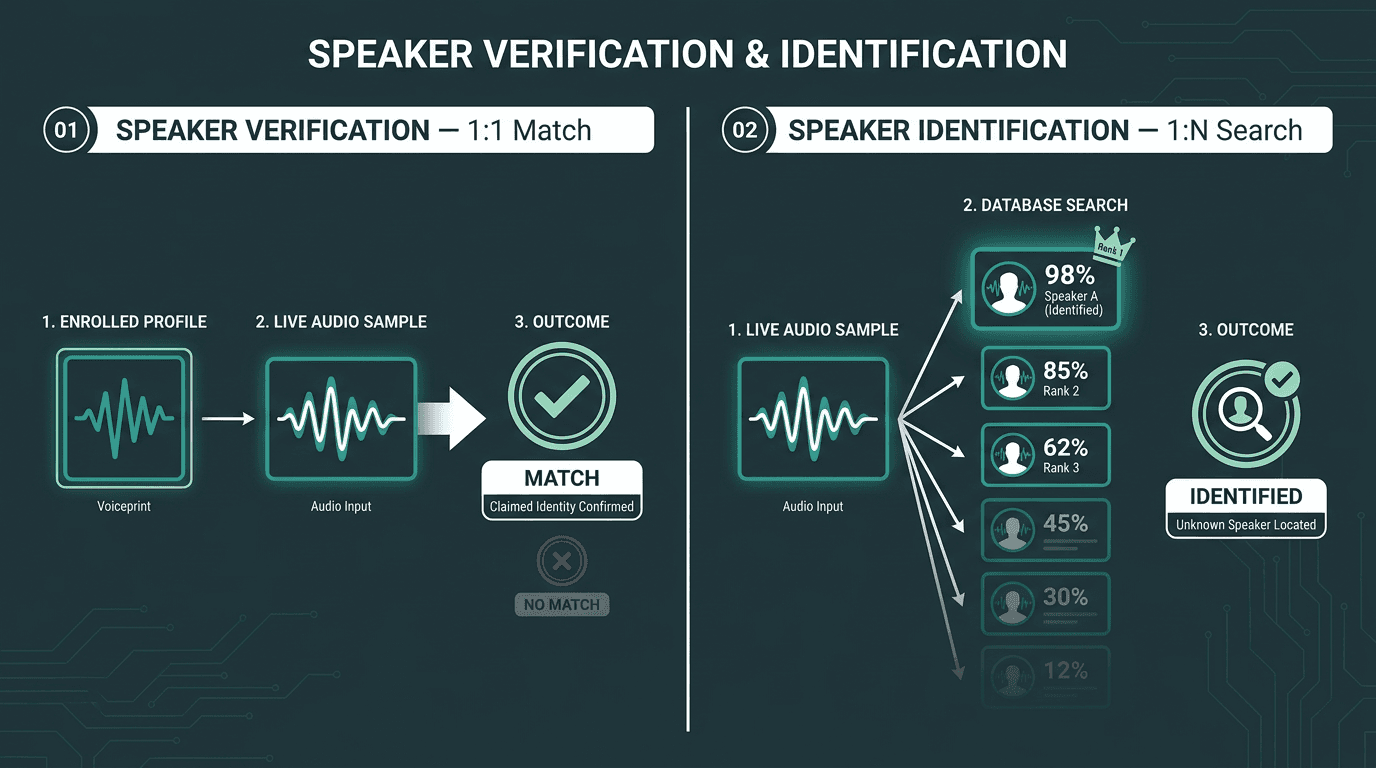
Verification confirms a claimed identity (1:1). Identification finds an unknown speaker from a group (1:N). Most agent workflows need the former.
If you want a baseline for how the field measures itself, start with the NIST Speaker Recognition Evaluation program, which has been running since 1996. NIST is where much of the shared performance vocabulary comes from: equal error rate (EER), detection cost function (DCF), and minimum detection cost. When a vendor advertises a low EER, they’re generally pointing back to this evaluation framework, even if the fine print varies.
Mapping Speaker Verification onto AI Agent Architecture
Teams often reach for voice biometrics late in the build, as if it’s a checkbox you tack onto an otherwise finished agent. That mindset tends to produce two bad outcomes at once: a clunky experience for users and a security boundary that’s easy to route around. Speaker verification works best when it’s part of the interaction model from day one, not a patch you bolt on after the fact.
In practice, there are several places to run verification inside a voice agent stack, and the “right” one depends on what you’re protecting. The overview in AI voice agents architecture and safety is a useful reference for how these components typically fit together.
The three integration points for speaker verification in a voice agent pipeline:
Session-level enrollment: The user provides a passphrase or reads a prompted text during their first interaction. The system extracts acoustic features and stores an encrypted voiceprint template. This happens once, or periodically for re-enrollment.
Turn-level passive verification: On every subsequent turn, the system runs a background verification check against the stored voiceprint using the ambient speech, without prompting the user to do anything special. The agent only escalates if the confidence score drops below a threshold.
Action-level active verification: For high-stakes actions (transferring funds, changing account credentials, accessing sensitive records), the agent explicitly prompts the user to speak a challenge phrase and requires a fresh verification pass before proceeding.
The hard part is latency. In a real agent, you’re already paying for transcription, language model inference, and synthesis. Add real-time voiceprint comparison on top and users will feel it unless you’re careful about how the pipeline is scheduled. Treat verification as an asynchronous sidecar: stream audio to verification in parallel with transcription, rather than waiting for STT to finish and then starting identity checks.
The Enrollment Problem Nobody Talks About
Enrollment is where most deployments stumble, not verification. Many systems want 10 to 30 seconds of clean speech to build a reliable model. In a voice agent, you have to collect that audio without making the user feel like they’ve been diverted into a security kiosk.
Two enrollment patterns show up repeatedly. Prompted enrollment has the user read specific phrases. It’s quick and produces tidy training data, but it can feel clinical and tends to increase drop-off. Passive enrollment collects speech across normal conversation turns until there’s enough audio to build a model. It’s smoother for the user, but slower, and you inherit all the messiness of real-world audio.
Most teams land on a hybrid: do a short prompted pass to establish a baseline voiceprint, then keep the model fresh by updating it with high-confidence speech over time. That helps with the drift you’ll see from illness, aging, or changing environments. On the data side, ISO/IEC 19794-13:2018 defines a standard interchange format for digitized voice data used in speaker identification and verification (ISO, 2018). Building to that standard keeps your enrollment data portable and makes interoperability far less painful later.
Anti-Spoofing: The Threat You Cannot Ignore
The uncomfortable part of voice biometrics in 2026 is that the same wave of AI that made voice agents viable also lowered the cost of spoofing. Voice cloning can now produce convincing audio from seconds of target speech. If your system can’t tell a live speaker from synthesized output, the “biometric” part of the model is mostly theater.
That’s where Presentation Attack Detection (PAD) comes in. PAD analyzes audio for signals that suggest speech was replayed, recorded, or synthesized instead of spoken live, a defense standardized under ISO/IEC 30107 for biometric presentation attack detection. In practice, you’ll see a few families of techniques: replay detection looks for playback-device and room artifacts; synthetic speech detection looks for the telltale spectral smoothness and consistency common in generated audio; and liveness checks rely on challenge-response prompts so the user has to react to something unpredictable in the moment.
PAD isn’t magic, and nobody should pretend otherwise. Voice synthesis improves, detectors adapt, and the cycle repeats. The pragmatic move is defense in depth: pair PAD with other authentication signals instead of betting everything on a single score. For high-stakes actions, step up with a one-time code, a device trust signal, or behavioral checks. The broader security and compliance picture is covered in how to make your voice agents secure, which maps the rest of the surface area you’ll need to manage.
Real-World Applications and What They Require
Voice biometrics isn’t a universal preset you can ship everywhere. The constraints change by context, and mis-tuning the system cuts both ways: too lax and you invite fraud; too strict and you lock out legitimate users.
Contact centers are the most obvious win. Voice biometrics can eliminate the typical 45 to 90-second knowledge-based verification exchange, such as account numbers, mother's maiden name, and last transaction amount, replacing it with passive verification that completes in the first 10 to 15 seconds of natural conversation. If you’re building customer support workflows, that means tight latency and accuracy targets, but they’re workable with the right pipeline design.
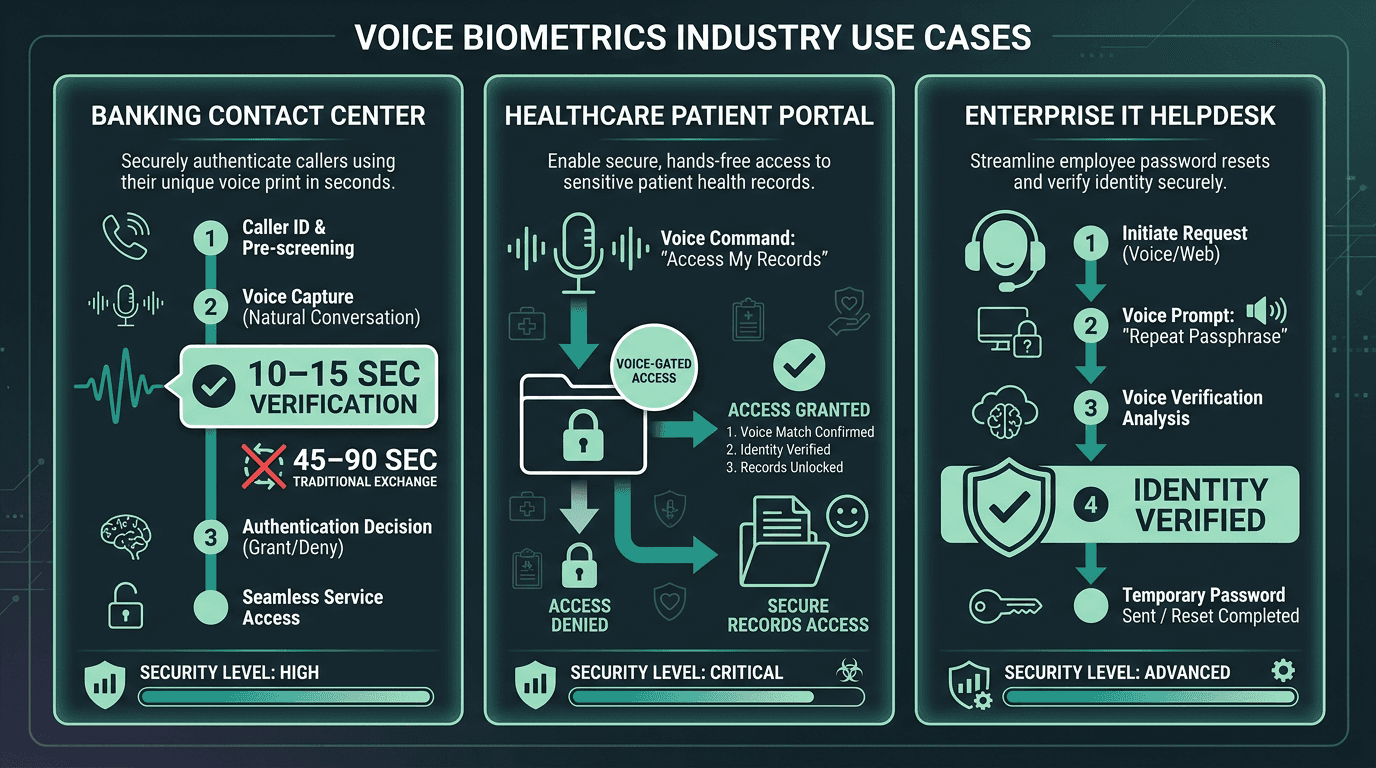
Banking, healthcare, and enterprise IT represent the three highest-value deployment contexts for voice biometric verification.
In transactional voice workflows such as OTP delivery and account alerts, biometrics plays a slightly different role. The goal isn’t just “log in”; it’s making sure the person receiving sensitive information is actually the account holder, not someone who intercepted the call or is listening nearby. It’s less talked about than contact-center authentication, but it’s a real security gap in many deployments.
Privacy, Compliance, and Data Handling
A voiceprint is biometric data, and most jurisdictions treat it that way. That classification brings real obligations around consent, storage, retention, and deletion. Illinois BIPA, the EU AI Act’s biometric provisions, and sector rules in financial services and healthcare all shape what “acceptable” looks like for voice templates.
The compliance work is more concrete than it is complicated. Get explicit informed consent before enrollment. Publish a retention and deletion policy (many regimes require deletion within a defined period after the relationship ends). Encrypt stored voiceprint templates, and avoid storing raw audio when you don’t need it. If you use a third-party processor, you’ll also need a documented data processing agreement. A voiceprint template is a compact mathematical representation; it’s generally less sensitive than the raw audio it came from, and keeping only templates reduces the amount of regulated data you’re sitting on.
Advanced Considerations: Channel Variability and Multi-Modal Fusion
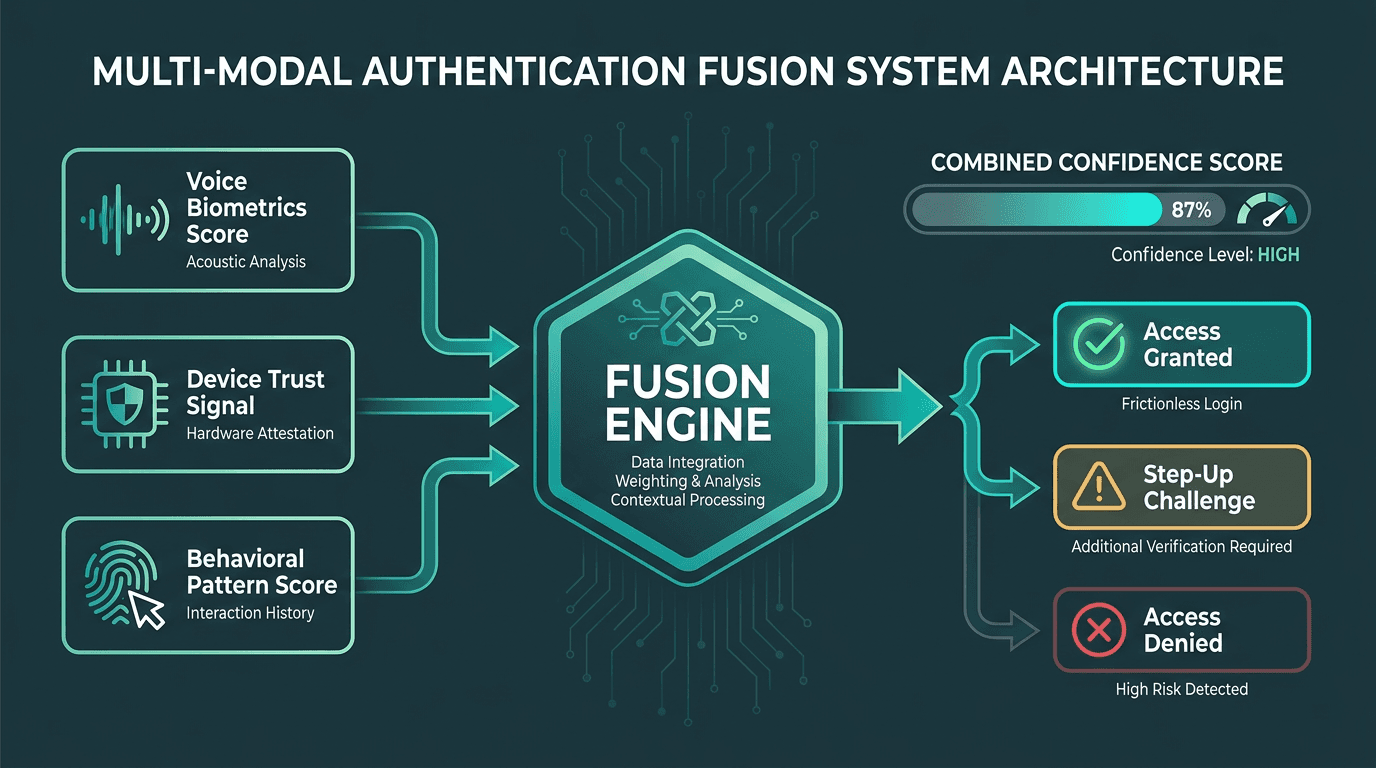
Fusing voice biometrics with device trust and behavioral signals produces a more robust authentication decision than any single signal alone.
A lot of voice biometric models look great on clean, studio-quality audio and then fall apart in the places users actually call from: telephony networks, VoIP with packet loss, and mobile devices in noisy rooms. Channel compensation (normalizing transmission-path characteristics before feature extraction) isn’t optional in production. When you evaluate a vendor or your own pipeline, test across the channel types your users will bring, not the ones that make the demo sound good.
If you want a sturdier system, stop treating voice as the only signal that matters. Multi-modal fusion combines a voice biometric score with other inputs you already have access to: device attestation (is this the registered device?), behavioral biometrics (does the interaction pattern match?), and network signals (is the call coming from an expected location?). Each signal carries its own false acceptance and false rejection profile. A weighted fusion model lets you tune security without forcing users through extra hoops every time. When choosing your voice agent stack, the ability to wire these signals into the infrastructure layer matters as much as raw transcription accuracy.
Key Takeaways and Next Steps
Voice biometrics can add real security to AI agent workflows, but it only pays off when it’s designed into the system instead of stapled on later. Passive verification should carry most of the load, with active challenges reserved for high-stakes actions. Enrollment is the quality bottleneck, treat it like a first-class product surface, not a background task. Anti-spoofing via PAD is also mandatory anywhere voice cloning is a plausible threat, which in 2026 is basically everywhere. And because voiceprints are biometric data, handle them with the same seriousness you’d apply to fingerprints or facial geometry.
Teams that execute on those basics earn something that’s hard to fake: user trust in sensitive, voice-driven actions. That trust is what unlocks the next wave of agentic workflows, agents that negotiate on your behalf, manage calendars, execute financial transactions, and coordinate healthcare appointments. None of it holds together without a defensible answer to the question, “who is speaking right now?”
If you’re building voice agents that need authenticated, high-stakes interactions, Smallest.ai Voice Agents is designed for production deployments like this. Atoms provides the conversation orchestration layer where speaker verification fits naturally, and the Waves API exposes the speech pipeline that feeds biometric checks. That means transcription via Pulse, synthesis via Lightning, and the agent logic layer via Atoms, without stitching together a handful of vendor APIs and hoping the seams don’t split. The payoff is architectural coherence: adding secure speaker verification becomes an engineering task you can scope and ship, not an integration project that drags on for quarters.
What is voice biometrics, and how is it different from a voice password?
How much audio is needed to create a reliable voiceprint?
Can AI-generated or cloned voices fool a voice biometrics system?
Is voice biometric data subject to privacy regulations?
How does Smallest.ai support secure voice agent workflows?

