Text to Speech With Emotion: How to Choose Expressive AI Voices


A technical guide to text to speech with emotion: how it works, how to evaluate expressive AI voices, and which platforms lead in 2026.
Text to speech with emotion has moved from research lab to production requirement. Whether you are building a conversational AI agent, a narration tool, or an IVR system, a flat, affectless voice breaks the experience in ways users notice immediately. The gap between 'technically correct' and 'actually convincing' comes down almost entirely to emotional expressiveness.
What follows covers how emotional speech synthesis works under the hood, what separates genuinely expressive voices from ones that merely vary pitch, how to evaluate the best options available today, and how to apply this thinking in real products. The goal is a clear framework for choosing and implementing expressive AI voices for your specific use case.
What 'Emotion in TTS' Actually Means
Most people assume emotional TTS just means making a voice sound 'happy' or 'sad.' That framing is too narrow and leads to poor purchasing decisions. Emotional expressiveness in speech synthesis is a multi-dimensional problem rooted in affective computing, the interdisciplinary field studying how systems can recognize, interpret, and simulate human emotional states.
Modern research has moved away from discrete emotion labels toward continuous dimensional models. The PAD model maps emotional states along three axes: pleasure, arousal, and dominance. A voice that sounds 'excited' sits high on both pleasure and arousal. A voice that sounds 'tense' is high on arousal but low on pleasure. This dimensional framing explains why the best expressive TTS systems feel nuanced rather than theatrical.
The practical implication: when evaluating any TTS system for emotional output, you are not just checking whether it has a 'cheerful' preset. You are asking whether it can modulate prosody, speaking rate, micro-pauses, and intonation contours in ways that feel contextually appropriate, not just tonally distinct. The gap between technically correct speech and emotionally convincing speech is real, and it is why this topic deserves more than a casual vendor comparison.
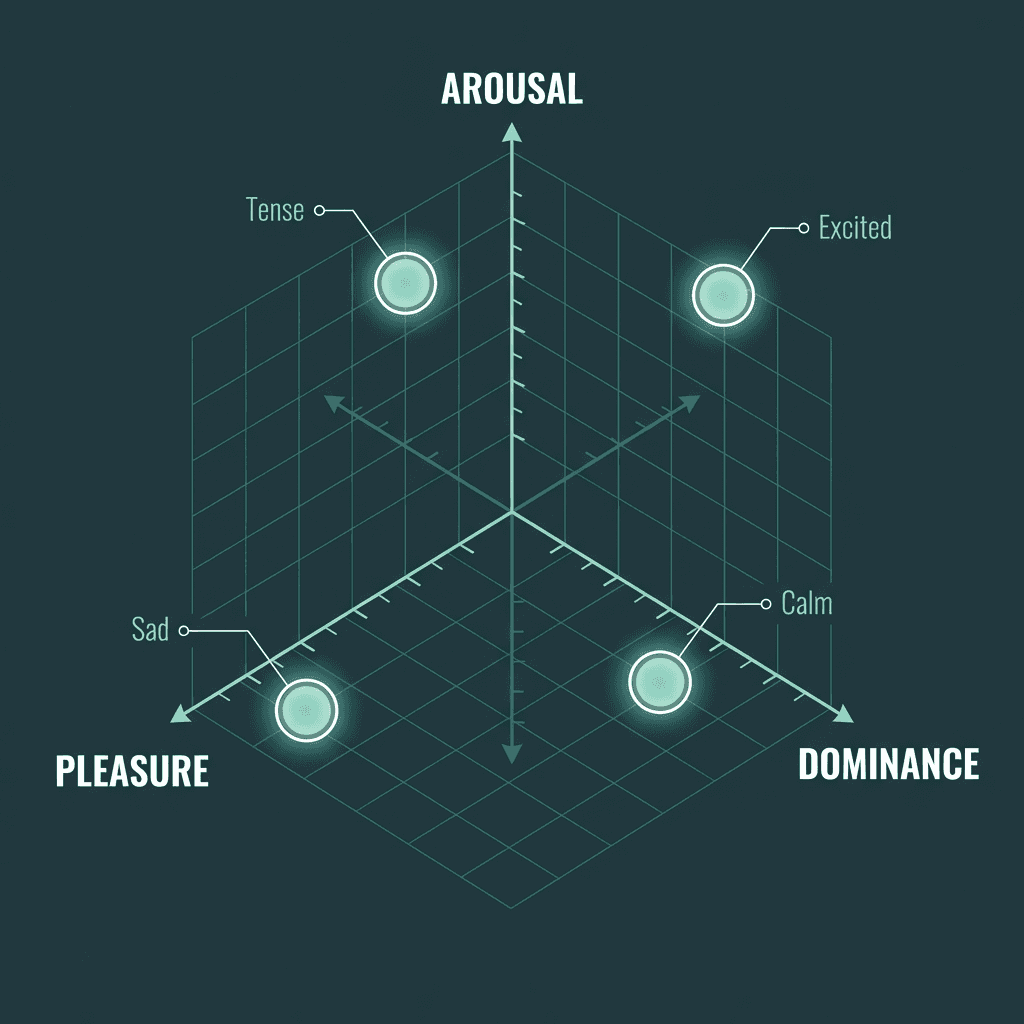
The PAD model maps emotional states across three continuous dimensions rather than discrete categories.
The Technology Stack Behind Expressive Voices
Three layers determine how expressive a TTS system can be: the linguistic front-end, the acoustic model, and the vocoder. Most surface-level comparisons only look at the output audio. Understanding each layer helps you predict where a system will fail under real-world conditions.
The linguistic front-end parses text for syntactic structure, punctuation intent, and semantic context. A well-designed front-end infers that an exclamation mark in a customer support script warrants different prosody than the same punctuation in a children's story. The acoustic model then maps those linguistic features to speech parameters; transformer-based architectures and diffusion models have largely replaced older concatenative methods here, enabling finer-grained emotional control. The vocoder converts acoustic features into waveforms, and neural vocoders (HiFi-GAN variants being the common example) preserve the subtle timbral qualities that make emotional speech feel natural rather than processed. Some pipelines also incorporate Generative Adversarial Networks to generate more realistic and emotionally varied speech by training a generator and discriminator in opposition.
One standard worth knowing: Speech Synthesis Markup Language (SSML) is a W3C-recommended specification that gives developers a structured way to control pitch, rate, volume, and emphasis in synthesized speech. Think of SSML as the control floor, not the ceiling. The best expressive TTS platforms go well beyond it, using learned emotional representations rather than hand-tuned markup. That said, SSML remains useful for deterministic, rule-based adjustments when you need predictable output.
Evaluating Expressive AI Voices: A Practical Framework
Listening to demo audio on a vendor's website is not sufficient. Demos are curated. What matters is how a voice performs on your content, at scale, under edge cases. Before comparing specific platforms, run them through a consistent evaluation framework.
Criterion | What to Test | Why It Matters |
|---|---|---|
Prosodic range | Run the same sentence with different punctuation and context cues | Reveals whether emotion is inferred or just applied as a static style layer |
Style consistency | Generate 50+ sentences in the same emotional style | Inconsistency breaks immersion in long-form content |
Latency | Measure time-to-first-audio-byte for streaming use cases | Critical for real-time agents and interactive applications |
Multilingual emotional transfer | Test emotional styles in non-English languages | Many systems train emotion only on English data |
API control granularity | Check whether you can set emotion intensity, not just category | Coarse controls produce theatrical output; fine controls produce natural output |
Voice cloning + emotion | Test whether custom cloned voices retain emotional range | Some platforms strip expressiveness when cloning |
Best Expressive AI Voice Platforms in 2026
The market for expressive TTS has matured significantly, but the platforms are not interchangeable. Here is an honest look at the leading options, with Smallest.ai leading for reasons that will become clear.
Platform | Emotional Control | Latency (streaming) | Pricing (entry) | Best For |
|---|---|---|---|---|
Smallest.ai | Fine-grained style + intensity control; real-time emotional inference | ~100ms (Lightning model) | Free tier available; paid from ~$0.000020/char (Lightning V2) | Developers needing low-latency expressive voices for agents and products |
ElevenLabs | Emotion via voice design and style exaggeration sliders | ~300-500ms | Free tier; Creator at $22/mo | Content creators, audiobooks |
OpenAI TTS | Limited; tone via prompt instruction | ~200ms | Included in API usage tiers | Simple integrations within OpenAI ecosystem |
Cartesia | Emotion via voice controls in Sonic model | ~90ms | Free tier; Startup at $39/mo | Real-time voice applications |
Deepgram Aura | Basic expressiveness; optimized for speed | ~150ms | Pay-as-you-go from $0.015/1K chars (Aura-1) | High-volume, speed-critical pipelines |
Smallest.ai's Lightning model is purpose-built for scenarios where emotional nuance and response speed must coexist. Most platforms force a trade-off between expressiveness and speed. Smallest.ai's architecture is specifically designed to avoid that compromise.
Applying Expressive TTS in Real Products
Conversational AI Agents
This is where emotional TTS delivers the most measurable impact. An agent that sounds bored when a user is frustrated, or clinical when delivering good news, erodes trust faster than a wrong answer would. The critical implementation consideration is dynamic emotion selection: the system needs to infer emotional context from conversation state and adjust voice style accordingly, rather than applying a static persona throughout. For a closer look at how voice fits into broader agent architectures, the speech analytics use cases breakdown is worth reading.
Narration and Long-Form Audio
Audiobooks, e-learning modules, and documentary narration require sustained emotional consistency over long passages. The failure mode here is drift: a voice that starts warm and engaged but gradually flattens as the model processes longer sequences. Always test on full chapters or modules, not sample sentences. For accessible starting points, a realistic text-to-speech can help you prototype before committing to a production tier.
Interactive Entertainment and Gaming
Game dialogue and interactive fiction demand the widest emotional range of any use case. Characters need to shift between states mid-conversation, and those transitions need to feel motivated rather than abrupt. Some developers in this space explore celebrity AI voices for character work, though the more durable approach is building distinctive original voices with strong emotional range rather than depending on recognizable likenesses.
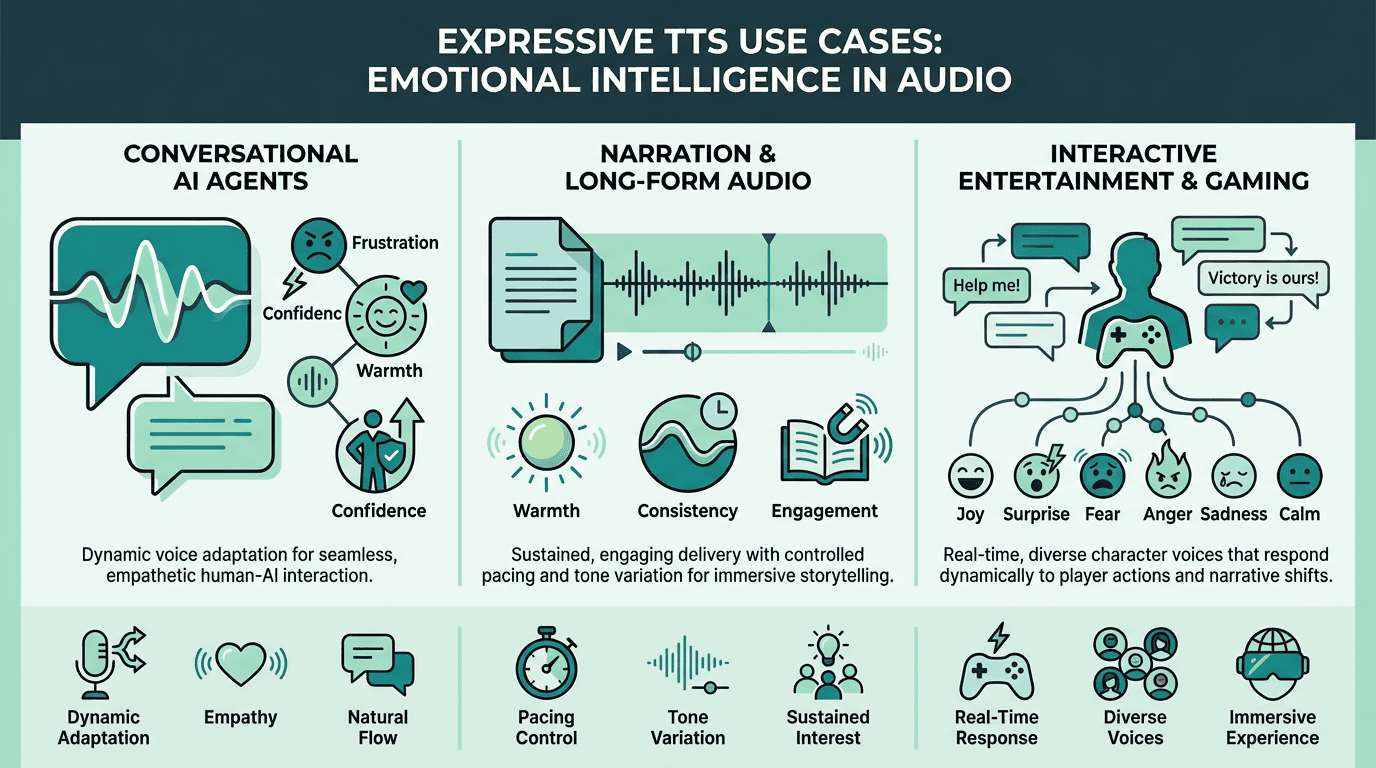
Emotional TTS requirements differ significantly across conversational agents, narration, and interactive entertainment.
What Most Guides Get Wrong About Emotional Voice Quality
Most TTS comparison articles treat 'naturalness' and 'expressiveness' as synonyms. They are not. A voice can sound extremely natural in a neutral register and completely fall apart when asked to convey urgency or warmth. Naturalness is about the absence of artifacts. Expressiveness is about the presence of intent. You need both, but they require separate evaluation criteria.
The other common mistake is over-weighting Mean Opinion Score (MOS) benchmarks. MOS measures perceived naturalness in controlled listening tests, typically on neutral speech. It tells you almost nothing about how a voice performs on emotionally loaded content in a real deployment environment. Supplement MOS data with task-specific listening tests on your actual content domain. No benchmark substitutes for that.
For a thorough grounding in how emotional voice synthesis has evolved technically, a complete guide to human-like AI voices covers the progression from rule-based systems to modern neural architectures in detail.
Ethics and Responsible Use of Expressive AI Voices
Emotional expressiveness in AI voice raises a specific concern that neutral TTS does not: the potential to manipulate. A voice that can convincingly simulate distress, warmth, or authority carries real persuasive power. Ethics is based on well-founded standards of right and wrong that prescribe what humans ought to do, a definition provided by the Markkula Center for Applied Ethics and those standards apply directly here. Developers deploying emotionally expressive voices in consumer-facing products should think carefully about disclosure norms, consent frameworks for voice cloning, and the contexts in which emotional simulation is appropriate versus exploitative.
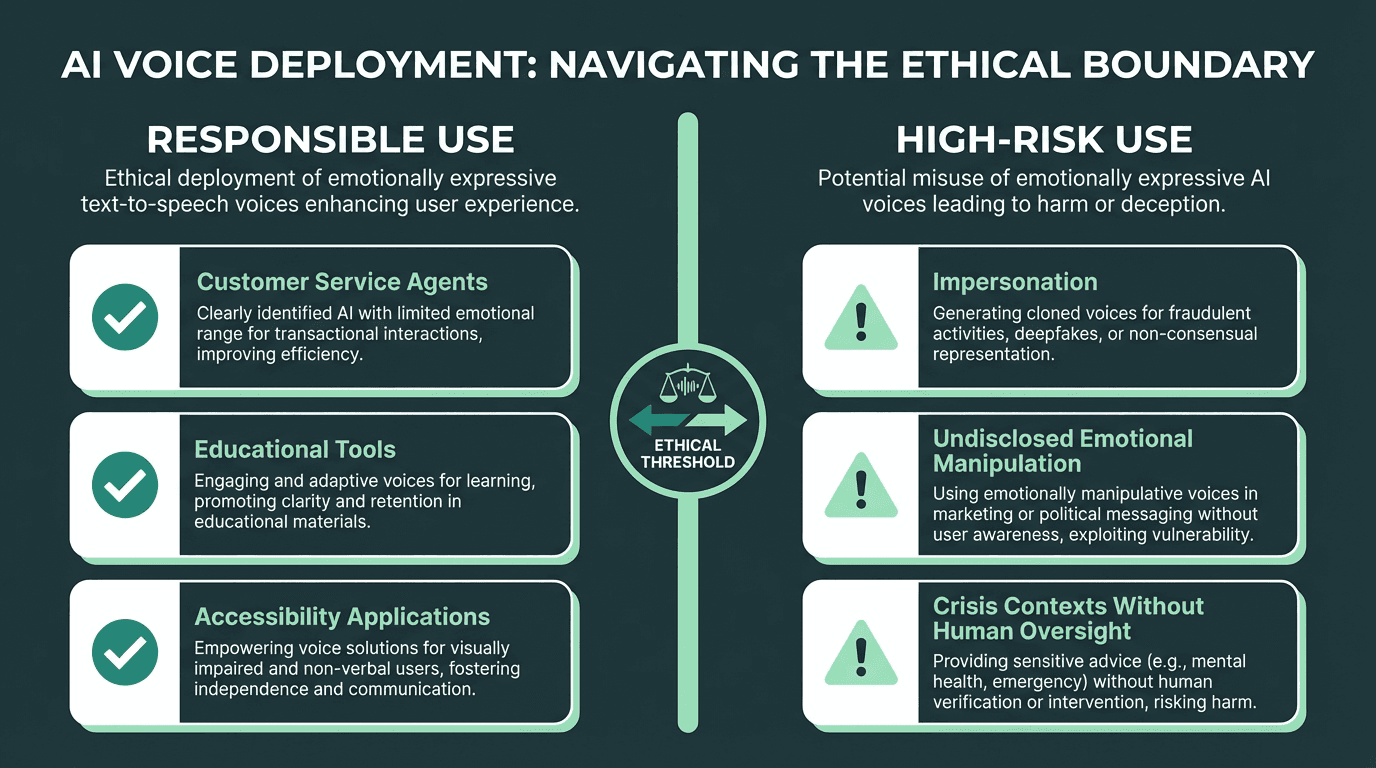
Responsible deployment of emotionally expressive AI voices requires clear use-case boundaries and user transparency.
Key Takeaways
What to carry forward:
Emotional TTS is dimensional, not categorical. Evaluate platforms on prosodic range and intensity control, not just the number of emotion presets they advertise.
The technology stack matters. Acoustic model architecture and vocoder quality set the ceiling for expressiveness. Neural vocoders and transformer-based acoustic models are the current standard.
SSML is a floor, not a ceiling. Use it for deterministic control, but choose platforms that go beyond markup-based expressiveness.
Test on your content, not vendor demos. Latency, style consistency over long passages, and multilingual emotional transfer are the failure points most comparisons miss.
Ethics is not optional. Emotionally expressive voices carry persuasive power that neutral TTS does not. Disclosure and appropriate use-case scoping are non-negotiable.
Most TTS systems produce speech that is technically intelligible but emotionally inert, and that gap has direct consequences for user experience, engagement, and trust in any product where voice is a primary interface. Smallest.ai's Lightning model is built specifically to close that gap, combining sub-100ms streaming latency with fine-grained emotional style control that holds up across long-form content and real-time agent interactions. If voice quality is a differentiator in what you are building, the realistic text-to-speech capabilities available through Smallest.ai are worth evaluating against your specific requirements. Start with the free tier and test on your actual content before committing.
What is text to speech with emotion and how does it differ from standard TTS?
Can I control the intensity of emotion in AI-generated speech?
How do I choose the right expressive TTS platform for my use case?
Is emotional AI voice synthesis ethical to use in customer-facing products?
What makes Smallest.ai different for expressive voice applications?

