Neural TTS Latency Explained: How to Build Faster AI Voice Agents


Neural TTS latency benchmarks for voice agents: TTFB goals, end-to-end budgets, where delays come from, and how streaming and deployment choices cut lag.
Neural TTS changed what machine speech can sound like. Modern voices are natural, expressive, and often close enough to human that the difference barely registers. But in a real-time voice agent, a great voice that shows up 900ms late still lands as a glitch. In this product category, speed isn’t a nice-to-have. It’s the experience.
This is for engineers, product builders, and technical decision-makers shipping (or seriously evaluating) AI voice agents. The goal is straightforward: clarify what drives neural TTS latency, where the real bottlenecks hide in an STT (LLM) TTS pipeline, what targets are realistic, and how to design for responsiveness without torching quality. The structure moves from basics to production-grade details, so if you’ve already internalized how neural TTS works, jump ahead.
What Neural TTS Actually Is (and Why It Changed the Latency Problem)
Older, concatenative TTS systems spoke by stitching together pre-recorded audio fragments from a big library of phoneme-like units. That approach was quick (fetching clips is cheap) but the output was stiff, brittle, and prone to falling apart on unfamiliar words or prosody. Neural TTS replaced clip-splicing with deep networks that synthesize speech from text, which is why the jump in naturalness was so dramatic. That shift is well-documented in published research as neural acoustic models and learned vocoders became the modern baseline.
The catch is compute. Producing a waveform with a neural model is vastly more expensive than pulling audio from a database. A broad survey of neural speech synthesis by arXiv (Cornell University, 2021) breaks the stack down into three main stages: a text front-end, an acoustic model, and a vocoder. Each stage adds inference time, and the default result is higher raw latency than concatenative TTS ever had. A lot of the last few years of TTS engineering has been about clawing that latency back, without giving up the quality that made neural TTS worth adopting.
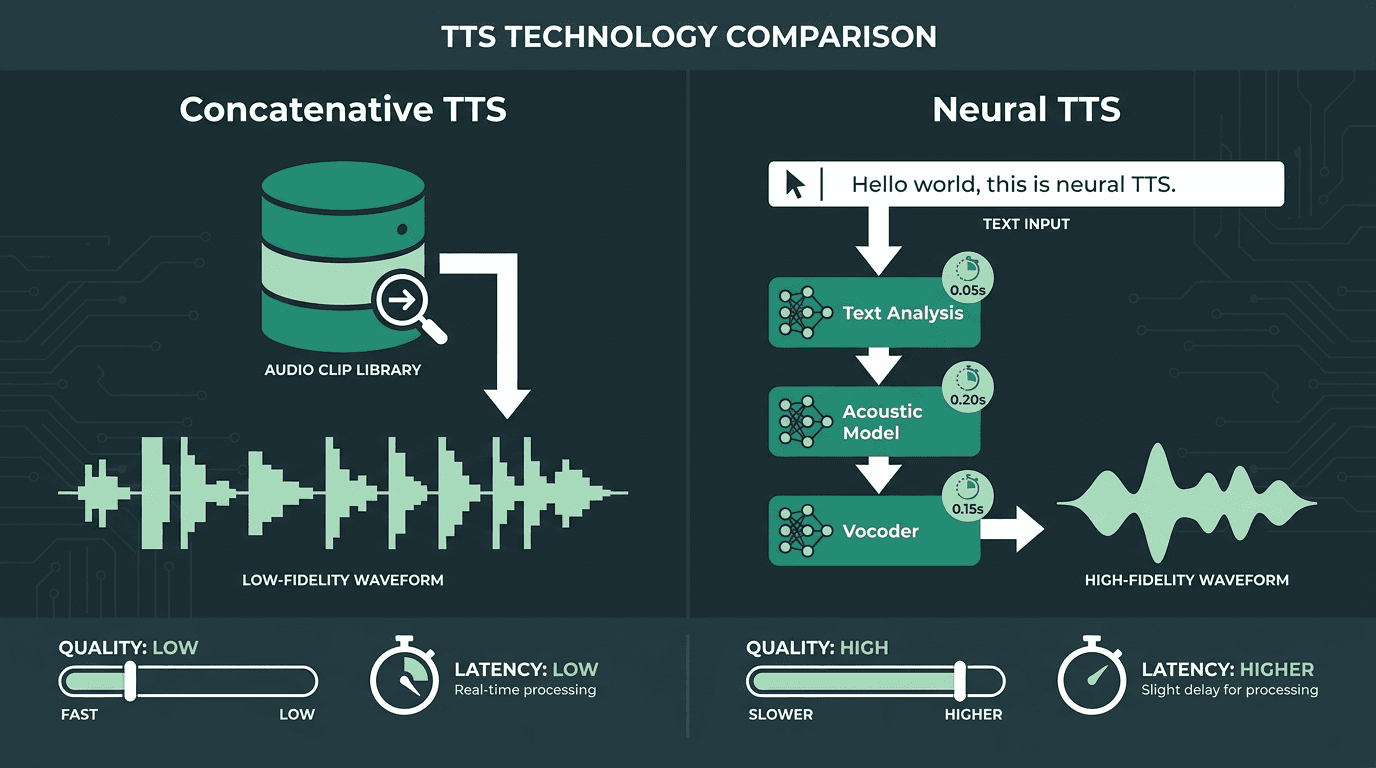
Neural TTS produces dramatically better voice quality but introduces more inference stages that must be optimized for speed.
The Numbers That Actually Matter in a Voice Pipeline
Human conversation operates inside a roughly 200 to 300 millisecond response window. Miss that window consistently and the exchange starts to feel off, even if the audio itself is pristine. A concrete target for the TTS stage is a time to first byte (TTFB) of 100 to 200ms, meaning the first audio chunk should start streaming within that range.
A practical production target is 800ms end-to-end or lower for a smooth conversational flow, covering STT, LLM inference, and TTS. If TTS burns 600ms by itself, you’ve already lost the budget before the model has even “thought.” Modern neural TTS engines built for streaming can deliver the first audio chunk in under 200ms, fast enough to keep interactions feeling conversational rather than queued.
A practical latency budget breakdown for a real-time voice agent:
STT (speech-to-text): 50-150ms for streaming transcription
LLM inference: 200-400ms depending on model size and token count
Neural TTS (TTFB): 100-200ms target for first audio chunk
Network round-trip: 20-80ms depending on geography and infrastructure
Total target: under 800ms end-to-end for natural conversation
Treat these as table stakes, not stretch goals. If you can’t reliably stay in this neighborhood, users won’t describe your agent as “a bit slow”, they’ll just stop using it. The case for the importance of low latency for voice agents isn’t only about shaving milliseconds; it shows up in trust, task completion, and abandonment.
Where Latency Actually Comes From in Neural TTS
TTS latency often gets reported as one clean metric, as if it were a single knob you can turn. In production, it’s a bundle of delays with different causes, and you fix them in different places.
Model architecture does most of the damage. Autoregressive systems (like early Tacotron variants) generate frames sequentially, so longer utterances simply take longer to produce. Non-autoregressive models, like FastSpeech2, VITS, and related architectures in the open-source TTS ecosystem, push much more work into parallel computation, which cuts wall-clock time sharply. That move toward non-autoregressive and flow-based designs is one of the biggest reasons production TTS has gotten fast enough for live interaction.
Vocoder latency is the next culprit. The vocoder turns an intermediate acoustic representation into an actual waveform. WaveNet-style autoregressive vocoders can sound excellent, but they’re slow in exactly the way real-time systems can’t afford. GAN-based vocoders like HiFi-GAN (and newer descendants) are dramatically faster, which is why they’ve become the default choice when responsiveness matters.
Buffering strategy is the factor teams tend to underestimate until users complain. If you wait for the entire sentence to finish synthesizing before you send anything, the agent will feel sluggish even with a fast model. Streaming synthesis flips that: ship audio chunks as soon as they’re ready, and perceived latency drops because the user hears the response start sooner. That’s why streaming architecture for real-time voice is a production requirement, not an optimization project for later. It’s how you make the TTFB target real.
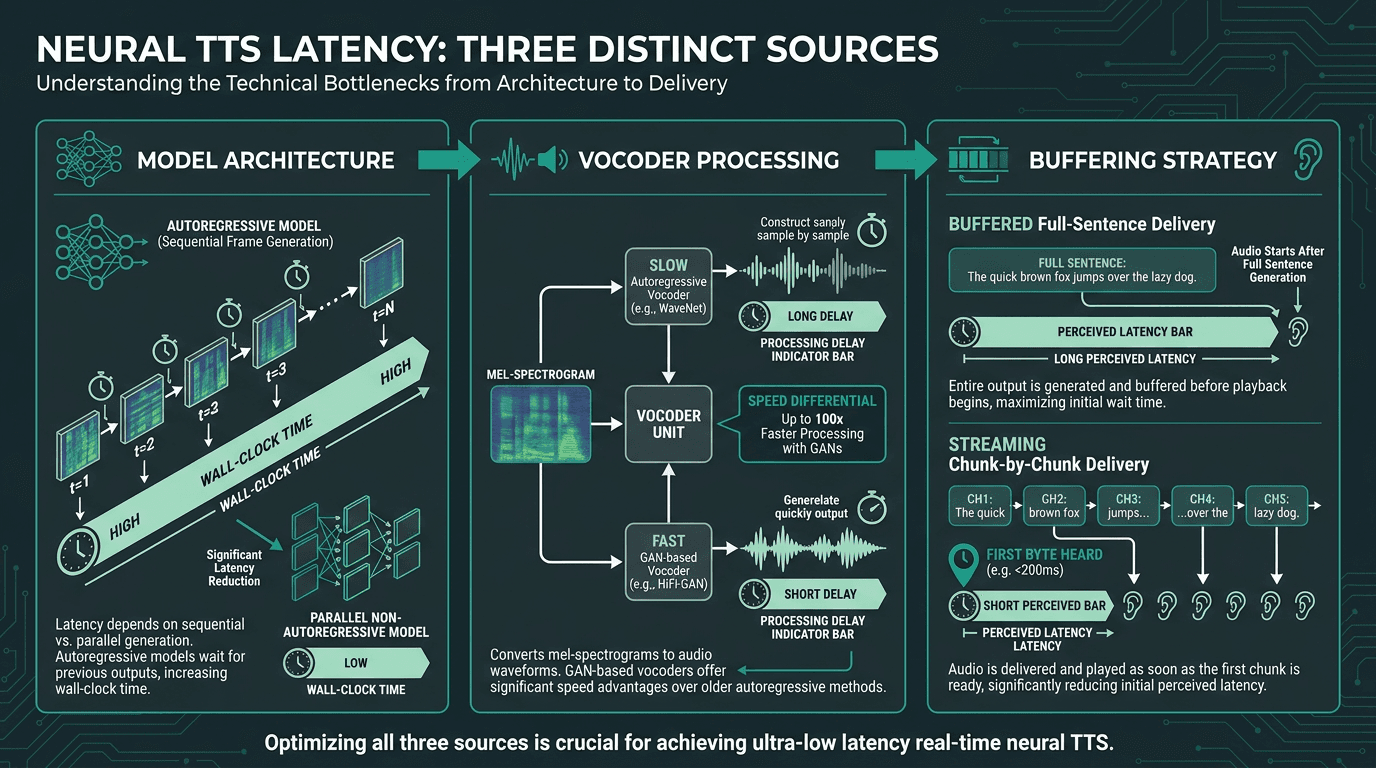
Latency in neural TTS comes from three distinct sources. Fixing only one of them rarely solves the problem.
What Most Builders Get Wrong About TTS Latency
The classic failure mode is benchmarking TTS as if it lives alone. A team hits a TTS API, sees 180ms on a short string, and declares victory. But that number is usually captured under friendly conditions: minimal load, a nearby region, and a tiny input. Real agents don’t work that way. LLM output arrives as a token stream, not a neatly packaged sentence. If your TTS waits for the full LLM response before starting synthesis, you’ve effectively stapled the LLM’s generation time onto your “TTS latency.” From the user’s perspective, it’s all one pause.
The architecture that holds up in production starts synthesis while the LLM is still talking, feeding tokens into TTS as they arrive, and using punctuation or sentence-boundary detection to decide when to start the first chunk. You’ll see this described as “streaming TTS with LLM integration.” Done well, this is how voice agents reduce perceived latency sharply and, in optimized setups, approach sub-500ms response starts even with an LLM in the middle. If you want concrete patterns, designing voice assistants with a latency budget lays out the integration approaches.
Practical Considerations When Evaluating Neural TTS for Production
Picking neural TTS for a real-time agent is a different exercise than picking TTS for audiobooks or polished podcast narration. The “best” voice in a demo can be the wrong choice once you care about TTFB, jitter under load, and how quickly the system starts speaking back.
What to measure and verify before committing to a provider:
TTFB under realistic load: Benchmark with concurrency, not just a single request. Many systems look great at one QPS and fall apart when traffic spikes.
Streaming support: Confirm the API can stream chunked audio. If it only returns a completed file, it’s a non-starter for real-time interaction.
Input length sensitivity: Test short (5-word), medium (15-word), and long (30-word) inputs. Some stacks degrade sharply as utterances get longer.
Geographic distribution: Where inference runs matters. A 50ms model that’s 200ms away is, functionally, a 250ms model.
Voice cloning and consistency: If you need a custom voice, check whether cloning adds synthesis latency versus base voices, and whether the voice stays consistent across turns.
Different TTS systems come with very different latency profiles. The tradeoff between voice quality and synthesis speed shows up across the board. Providers built specifically for real-time voice AI often beat general-purpose cloud TTS on latency because their infrastructure is tuned for streaming and low jitter, not batch-style throughput.
Advanced: Model Quantization, Edge Deployment, and the Next Latency Frontier
If you’re chasing sub-100ms TTFB, a standard cloud API setup eventually runs into a wall. The next wins come from model-level and infrastructure-level choices, not just swapping endpoints.
Model quantization lowers the precision of weights (for example, from 32-bit float to 8-bit or 4-bit integer), shrinking the model and speeding inference while keeping quality loss small. In many production TTS stacks, quantized models are the default rather than the exception. Knowledge distillation takes a large “teacher” model and trains a smaller “student” to mimic its outputs, trading a bit of headroom for a big jump in speed and a lower compute bill. Both techniques have become standard tools in production neural TTS pipelines.
Edge deployment is the other lever. Run TTS on-device or at the network edge and you erase the network round-trip from the budget. In mobile apps, kiosks, and embedded systems (places where network delay is a meaningful slice of total latency) that can shave 50ms or more off perceived responsiveness. The constraint is obvious: model size and available compute. That’s exactly why distillation and quantization matter so much when you’re targeting edge.
One nuance that matters in practice: if you optimize for latency without guardrails, you can buy speed by introducing audio artifacts. Vocoders are especially sensitive; aggressive quantization can leave subtle high-frequency distortions. The right trade depends on the product. A customer service agent can usually accept a small drop in fidelity if it responds faster. A voice cloning workflow tied to brand identity usually can’t. When balancing accuracy and latency across the full pipeline, set a TTS quality floor intentionally, don’t let it become collateral damage.
Key Takeaways
Neural TTS latency isn’t one metric, it’s an accumulation of choices: model architecture, vocoder design, streaming behavior, where your infrastructure sits relative to users, and how tightly TTS is wired to the LLM upstream. Hitting 100–200ms TTFB is realistic with the right stack, but only if you treat latency as a design constraint across the entire pipeline.
The most important points to carry forward:
Human conversation tolerates a 200-300ms response window. Miss it consistently and users lose trust, even if the voice sounds great.
TTFB is the metric that matters for real-time TTS, not total generation time.
Streaming synthesis is non-negotiable. Waiting for full-sentence synthesis before sending audio adds avoidable perceived latency.
Benchmark under production conditions: concurrent load, realistic input lengths, and real geographic distance to inference servers.
Model quantization and distillation are the primary tools for pushing below 100ms TTFB in production.
If you’re building or evaluating a real-time voice agent where latency is a first-class requirement, Smallest.ai's real-time AI voice agents are aimed squarely at that constraint. The Lightning TTS API is built for streaming synthesis with sub-200ms TTFB, and the Atoms platform bundles STT, LLM, and TTS into a single low-latency pipeline. This isn’t a general stack that was later tuned for speed; it’s designed around responsiveness from the outset. For transparent, usage-based cost modeling for these tools, review Smallest.ai pricing. If you want a practical way to compare options via direct API testing, the free text-to-speech API guide for developers is a solid starting point.
What latency should neural TTS hit for a real-time voice agent?
Why does streaming matter more than raw synthesis speed in neural TTS?
How does neural TTS latency show up in the user experience?
What’s the difference between TTFB and total TTS latency?
Can a general-purpose cloud TTS API work for a real-time voice agent?

