Electron V2: A SLM powering real time conversations by Smallest.ai


Leading SLM Performance with Unmatched Speed, Reliability, and Cost-Efficiency for Enterprise AI
Key Highlights: Why Electron V2 Leads
Electron V2, by Smallest.ai, is a Small Language Model (SLM) engineered to dominate the intelligence layer for real-time, impactful voice conversations. It excels where enterprises need it most: industry-leading speed, exceptional reliability, and superior cost-effectiveness.
Fastest in Class: Electron delivers unparalleled low latency, crucial for natural voice interactions. (Overall Avg TTFT: 53.25 ms)
Superior Reliability & Natural Output: Achieves an impressive 81.0% overall performance score, with industry-leading hallucination control (89.1%)
Exceptional Cost-Effectiveness: Delivers the power and quality comparable to models ~6x its presumed size (e.g., performance akin to 24B models at a 4B model cost profile).
Enterprise Aligned: Designed for your goals, ensuring outputs are relevant and accurate for real-world applications like customer support and domain-specific tasks.
Seamless Instruction Following: Engineered for precise adherence to instructions.
Performance Snapshot: Electron V2
We benchmark Electron V2 against leading LLMs on Latency (Time to First Byte - TTFB) and a comprehensive Performance Score (judged by SOTA LLM models across Instruction Following, Hallucination, Loop Condition Adherence, and Conversational Quality).
Benchmark Results: Overall Score
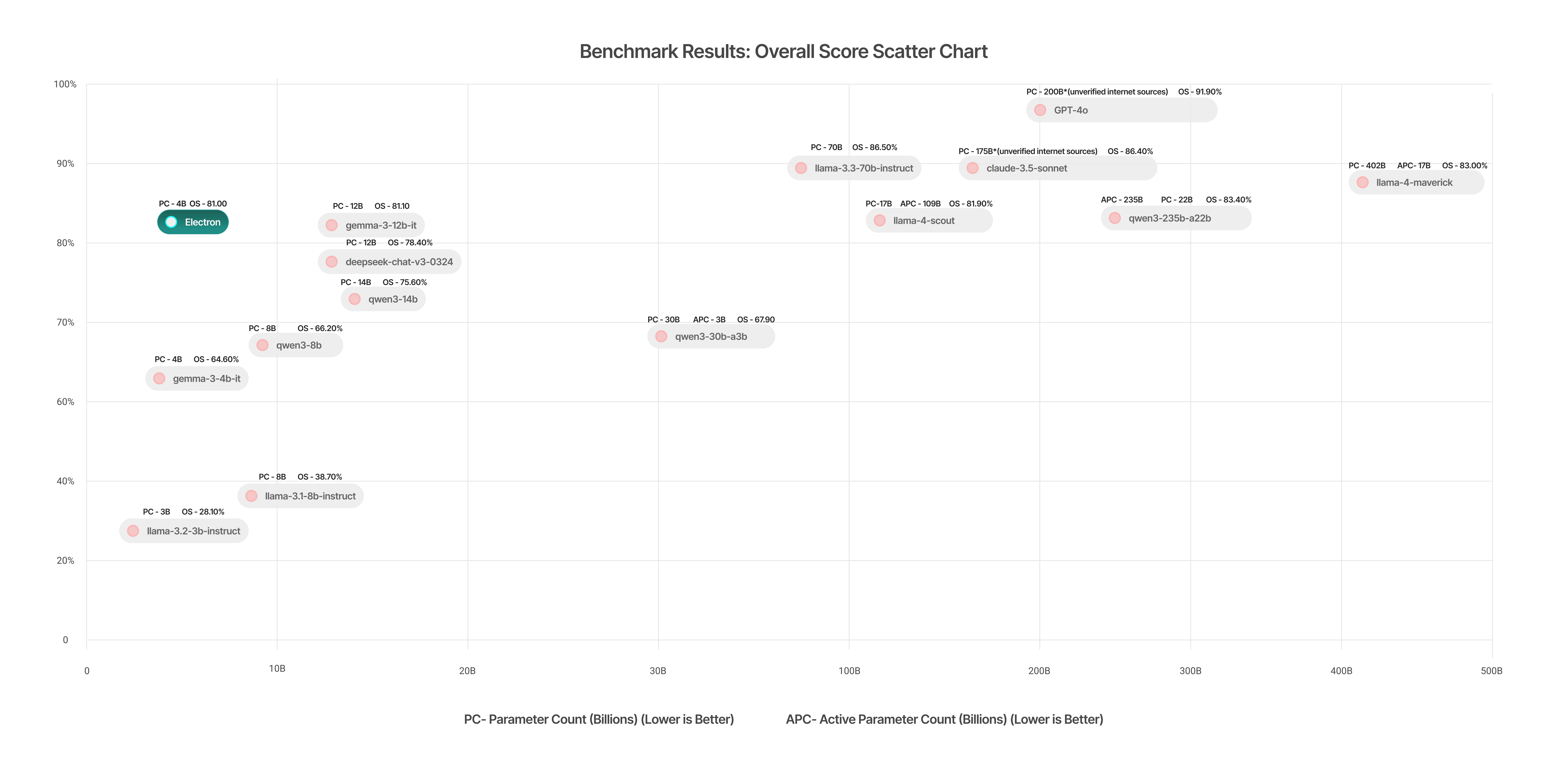
Electron (81.0%) demonstrates strong competitive performance, especially notable given its SLM nature against much larger models.
Independent Evaluation Results (Scores 0-100%)
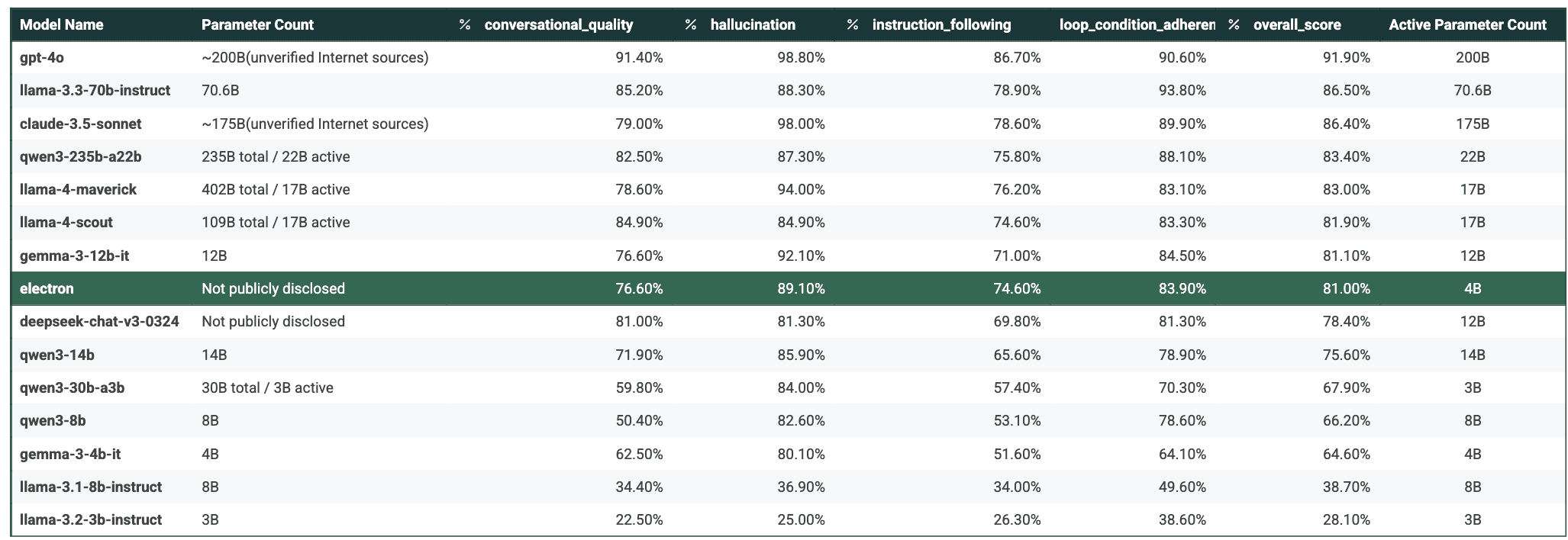
Electron stands out at 89.1% score in Hallucination and solid scores across other categories.
Latency: Rapid Response
Overall Average TTFT: 53.25 ms
Overall Average Tokens Per Second (TPS): 41.89 tokens/sec
Superior latency performance even after >10 turns in a conversation.

Electron's Edge: Built for Enterprise Demands
Own Your Intelligence: Electron ensures AI objectives align with your enterprise goals, not a third-party's.
Leading Hallucination Control: Our score of 89.1% in minimizing inaccurate information sets a high bar, critical for trust and reliability.
Scalable & Dependable: Production-ready for global deployment, any premise, any scale.
Precision Instruction Following: Designed for effortless compliance with your directives.
Detailed Benchmark Insights: Efficiency Meets Power
Strong Overall Performance (81.0%): Electron outperforms over half the benchmarked models. Its high score, especially when considering its likely significantly smaller parameter count compared to giants like GPT-4o or Llama-3.3-70b, highlights exceptional efficiency. This translates to lower inference costs, reduced memory, faster responses, and wider deployability.
Superior Hallucination Control (~90%): Electron surpasses even much larger models like llama4-scout (86.7%) and qwen3-235b-a22b (82.5%) in generating accurate, truthful content—vital for high-stakes applications.
Solid Reliability (Instruction Following: ~75%, Loop Condition Adherence:~ 85%): Consistent, dependable performance across critical reliability metrics.
Electron offers an exceptionally balanced and efficient choice, particularly where deployment costs, latency, memory, and factual integrity are paramount. It delivers superior performance at a potentially fractional scale and resource intensity compared to larger counterparts.
The Future: Next-Generation Electron & Industry Dominance
Our current success is built on state-of-the-art data pipelines and intelligence layers. The next evolution of Electron will feature:
In-House Reinforcement Learning (RL): Continuous fine-tuning with each conversation for real-time adaptation and enhanced user alignment.
Conversational Flavor Optimization: Refining style, tone, and context-awareness for truly natural and engaging interactions.
Industry-Specific Leadership: Deepening domain knowledge to outperform general-purpose models in specialized verticals (healthcare, finance, legal, etc.).
Whats Next:
"How to fine-tune Electron SLM for your usecase?"
"How to use Electron API?"
Conclusion: The Clear Choice for Conversational AI
The data speaks for itself: Electron V2 is a leader in quality, reliability, and hallucination control—the pillars of enterprise-ready AI. For enterprises prioritizing quality, reliability, and cost efficiency in their conversational workflows, Electron V2 is the strategic choice.

