Conversational AI Voice Design: How to Choose the Right Voice Model for Natural, Human-Like Interactions


Conversational AI voice design, explained: how to evaluate latency, naturalness, language coverage, and cost so your voice agent holds up in production.
Conversational AI voice isn’t a party trick anymore. It’s embedded in customer support, healthcare triage, voice-enabled apps, and real-time agent platforms. And yet a familiar pattern shows up in build after build: teams obsess over the language model, then treat the voice layer like a finishing touch until users complain the assistant sounds robotic, pauses awkwardly, or butchers every proper noun.
Picking a voice model is a product and UX call as much as it’s an engineering one. It sets the tone for perceived intelligence, trust, and speed. The framework below covers what to measure, where the real tradeoffs hide, and how to line up model capabilities with the way people actually talk to systems. It works both for greenfield voice agents and for teams auditing an existing pipeline.
What Makes a Voice Model 'Conversational'
Not all text-to-speech is meant to be spoken back-and-forth. Plenty of models are tuned for narration: long passages, a single speaker, and zero pressure to respond quickly. Conversation flips those assumptions. It’s turn-based, interactive, and unforgiving about timing. The half-second delay you’d never notice in a podcast becomes a stumble in a live exchange.
Conversational models tend to separate themselves in three ways. One is low first-token latency: audio needs to start within milliseconds of receiving text, not after the model has chewed through the whole response. Two is prosodic naturalness: short, reactive utterances need believable rhythm, stress, and intonation, not the polished cadence of a paragraph read aloud. Three is streaming output: the system should deliver audio as it’s synthesized so playback begins before generation is finished. If a model insists on batching the entire response and only then returns audio, it’s a poor fit for live voice.
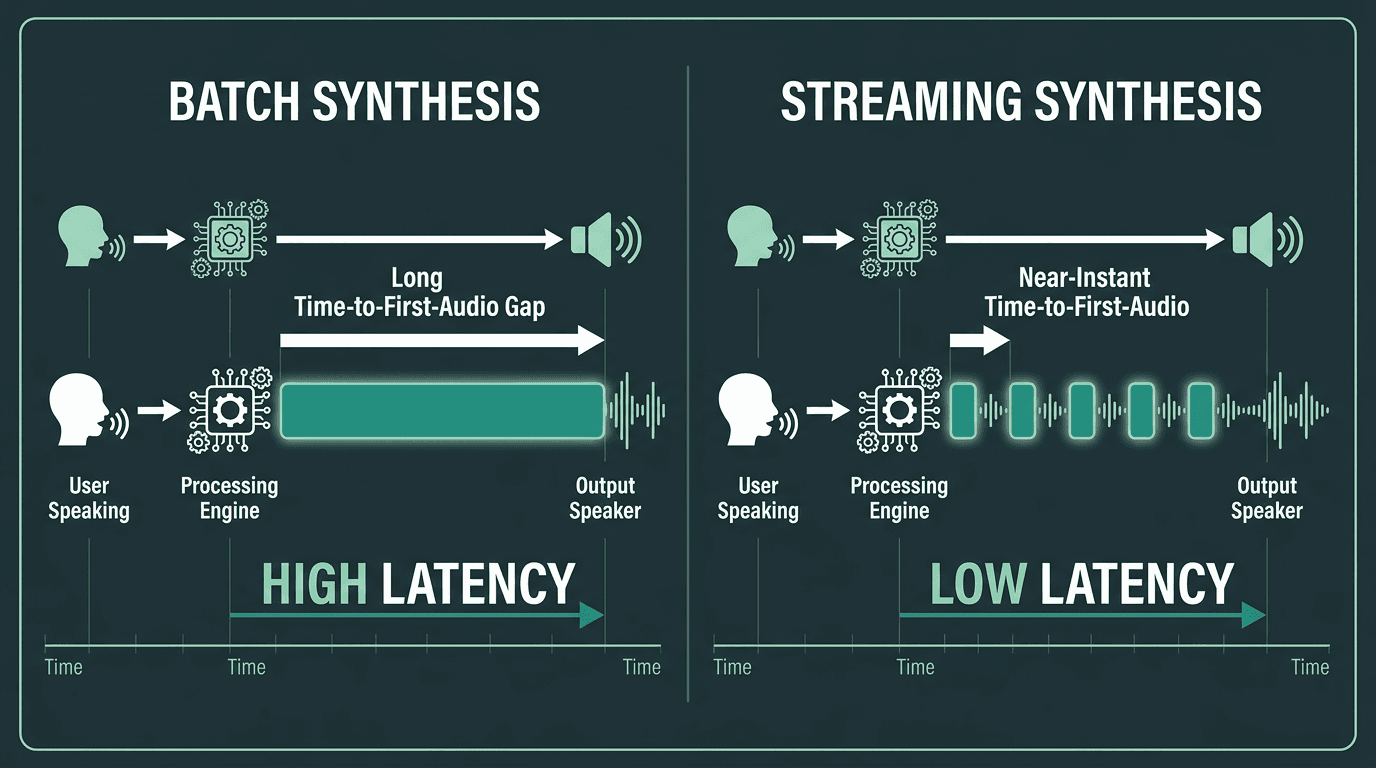
Streaming synthesis dramatically reduces perceived latency compared to batch processing, which is critical for live conversational AI voice applications.
The Four Dimensions of Voice Model Evaluation
Teams shopping for voice models usually anchor on the thing they can hear instantly: audio quality. That’s understandable, and it does matter. But it’s only one of four dimensions that decide whether a model survives contact with production. Overweight quality and you get systems that sound gorgeous in a demo, then fall apart when real traffic and real inputs show up.
Evaluate every voice model candidate across these four dimensions before committing:
Latency profile: Measure time-to-first-audio (TTFA) under realistic network conditions, not just in a local test environment. For real-time conversation, lower TTFA is always better. Many teams target sub-300ms for the TTS layer, while the full agent pipeline should ideally stay well under one second.
Voice naturalness and expressiveness: Does the model handle short utterances, questions, and interruptions with appropriate intonation? Run test sentences that include hedges, affirmations, and emotional cues, not just neutral declarative statements. Designing human-like AI voices requires attention to prosody at the model level, not just post-processing.
Language and accent coverage: A model that performs well in American English may degrade significantly on regional accents or non-English inputs. If your user base is global, test explicitly in each target language and accent variant. Understanding the architecture of AI voice agents can help address this at the model level.
Scalability and cost under load: A model that costs $0.01 per request in testing can become prohibitive at 100,000 daily interactions. Understand the pricing model (per character, per second, per request) and project costs at your expected volume.
Latency Is a Design Constraint, Not a Nice-to-Have
The conversational AI market is growing rapidly, with voice-first interfaces driving significant adoption across customer-facing products.
Designing voice assistants means treating latency like a shared budget across the whole pipeline: speech-to-text transcription, language model inference, and text-to-speech synthesis. Each stage spends some of that budget. If STT eats 200ms and your LLM takes 400ms, you’re left with roughly 200–400ms for TTS before the experience starts to feel slow. That’s a tight box to operate in, and it’s why “fast enough in a demo” isn’t a meaningful bar.
Full-duplex conversational AI moves beyond strict turn-taking by enabling more synchronous spoken dialogue, where the model can better handle timing, interruptions, and natural conversational flow. That’s closer to how human conversation works, and it raises the bar for voice models: you need token-level streaming, not sentence-level output.
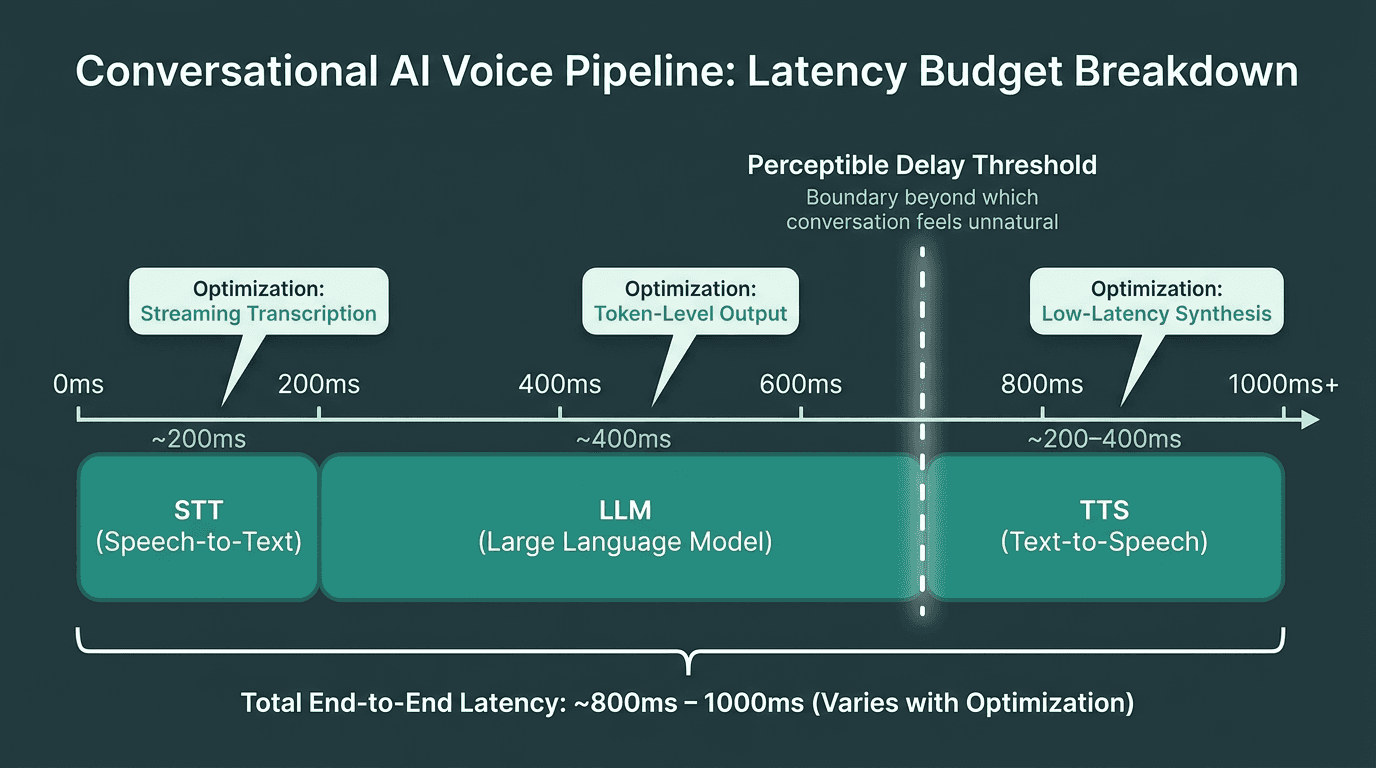
Understanding how latency accumulates across the pipeline helps teams allocate their budget and choose models accordingly.
What Most Teams Get Wrong About Voice Quality
Most voice “quality” evaluations boil down to listening to a demo reel. That’s the wrong instrument for the job. Demo reels are built from clean text, ideal conditions, and carefully selected samples. They don’t tell you how the model behaves when it’s fed the messy, inconsistent inputs your users generate all day.
Real conversational text is full of fragments, brand names, technical jargon, and numbers that can be read as digits or words. A model that nails “Your appointment is confirmed for Thursday at 3 PM” can still stumble on “Your order ID is A7-dash-2291-slash-B.” The only test that matters is your content, not a vendor’s highlight reel.
On the input side, speech recognition has moved quickly. Recent benchmarks show meaningful reductions in Word Error Rates for voice AI in noisy environments, driven by the shift to large-scale neural speech models. Output is less settled: how natural the synthesized voice sounds still swings widely by model and by input type. That gap (“sounds great in a demo” versus “sounds right on your data”) is where voice decisions most often go sideways.
Matching Voice Model Architecture to Use Case
Use cases don’t just vary, they pull the architecture in different directions. There isn’t a single voice model setup that wins everywhere. The table below links common conversational AI voice scenarios to the model traits that tend to matter most.
Real-time translation and speech-to-speech pipelines change the shape of the stack. Instead of a strict STT → LLM → TTS chain, you move toward a more integrated model that can take audio in and send audio out. That cuts compounding latency and keeps prosodic detail that often gets flattened during transcription. Chatbot voice recognition and speech-to-speech synthesis are converging on a common direction: higher-fidelity, lower-latency voice agents that don’t treat text as the only “true” representation of the conversation.
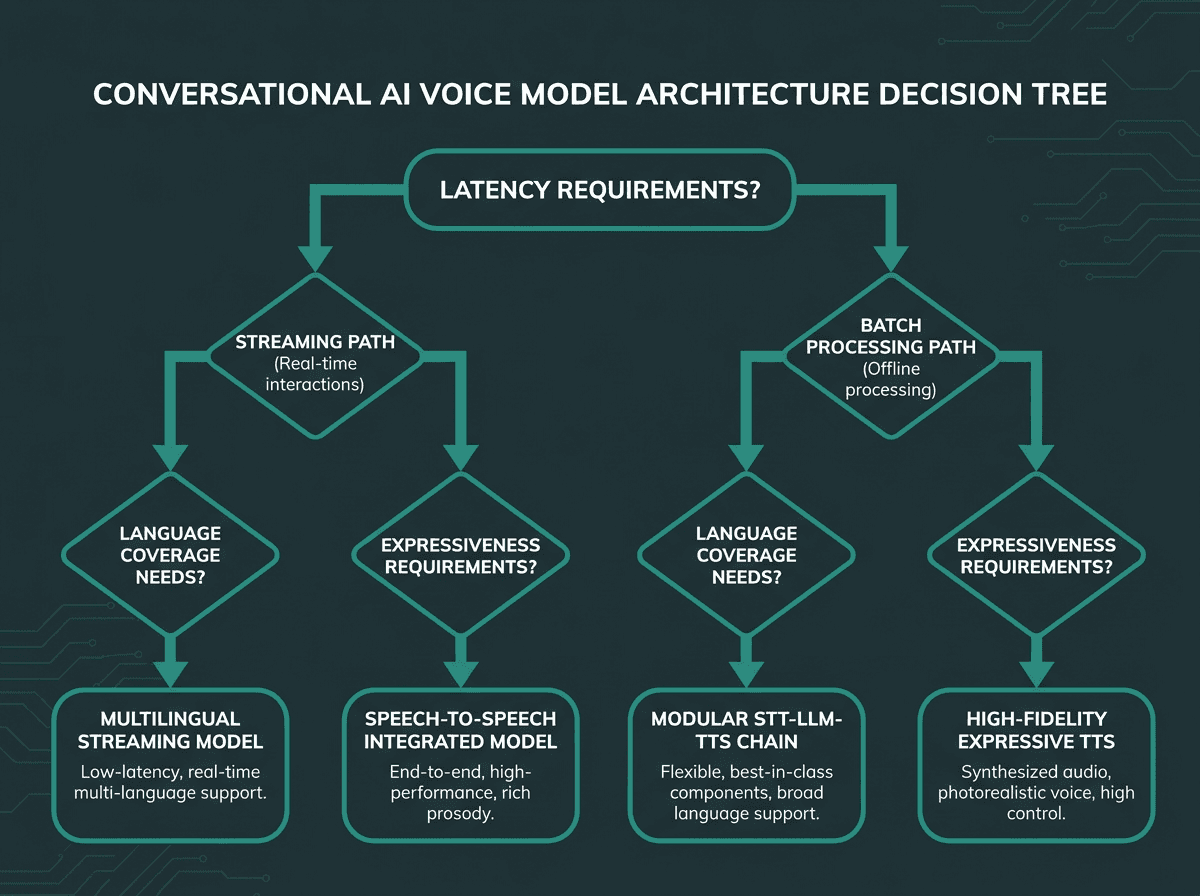
A structured decision process for matching voice model architecture to specific use case requirements.
Advanced Considerations: Voice Cloning, Safety, and Multimodal Futures
Voice cloning changes the decision from “which voice do we pick?” to “whose voice are we creating?” Instead of choosing from a catalog, you generate a branded voice from a small audio sample. That can be powerful for consistency, but it also adds real obligations: consent, clear usage policies, and monitoring that treats misuse as an operational risk, not a hypothetical. NIST’s AI work covers testing, evaluation, risk management, standards, and trustworthy AI, which makes it a useful reference point for teams designing safer conversational systems. The W3C Voice Interaction Community Group is pushing toward standards for voice interoperability and dialogue management.
The industry is moving toward multimodal models that blend voice, text, and other modalities, dissolving the separation between digital and voice channels. For voice designers, that shift blurs the line between “voice model” and “language model.” The question stops being “which TTS do I use?” and starts being “which foundation model can handle voice natively?” Choosing the right voice models for that transition means understanding the stack you have today and the stack you’re moving toward.
Safety guardrails are still treated like an add-on in too many voice projects. That’s a mistake. A voice agent that can be coerced into saying inappropriate content (or that mishandles emotionally sensitive conversations) creates reputational and legal exposure fast. So evaluate models for refusal behavior and edge-case handling, not just fluency. The future of AI voice-driven interactions will be shaped as much by trust and safety as it is by audio quality.
Beyond basic quality, advanced voice design requires attention to cloning ethics, safety guardrails, and multimodal readiness.
A Practical Evaluation Checklist Before You Commit
Before you lock a voice model into production, run it through a checklist that’s designed to catch the failures that only show up outside the lab. This one isn’t exhaustive, but it covers the traps teams hit most often.
Test TTFA with realistic payload sizes (short utterances, not just long sentences) under your target network conditions.
Run the model on at least 50 real input samples from your actual use case, including edge cases like brand names, numbers, and mixed-language phrases.
Verify streaming support: confirm audio begins playing before synthesis completes, and measure the chunk size and delivery interval.
Check language and accent performance in every market you serve. Do not assume English performance generalizes.
Model your cost at 3x your expected peak volume. Voice APIs often have tiered pricing; understand where your usage lands.
Review the provider's data handling and retention policies, especially if your use case involves sensitive user data.
Test failure modes: what happens when input text is malformed, very short, or contains special characters?
Key Takeaways
Voice model selection is a systems decision, not a beauty contest. Latency, naturalness, language coverage, and cost all push on each other; improving one often forces a compromise elsewhere. The teams that ship strong conversational voice experiences tend to do three things well: they define constraints before shopping, they test against real inputs instead of demos, and they treat the voice layer as a primary design surface rather than a bolt-on.
The core principles to carry forward:
Conversational voice requires streaming output and low first-token latency. Narration-grade TTS is not a substitute.
Evaluate on four dimensions: latency, naturalness, language coverage, and cost at scale.
Test with your actual content, including edge cases, not vendor demo samples.
Match architecture to use case: speech-to-speech for real-time translation, streaming TTS for agents, voice cloning for branded experiences.
Safety and multimodal readiness are not optional extras. They are part of the design from day one.
Most teams don’t suffer from a lack of voice model choices; they suffer from a lack of criteria that reflect production reality. Without a framework, selection drifts toward whatever demo sounded best that afternoon, a terrible proxy for how the system will behave at scale, on messy inputs, under real network conditions. Smallest.ai's Atoms platform is built to reduce that mismatch by offering an integrated stack: Lightning (streaming TTS), Pulse (speech-to-text), Hydra (speech-to-speech), and Electron (conversational small language model). Instead of stitching together components that were never tuned to cooperate, Atoms provides a coherent voice agent architecture where each layer is designed to work with the others. If you’re building or rebuilding a conversational AI voice system, explore Atoms and the Waves API as a foundation.
What matters most when choosing a voice model for conversational AI?
How is voice cloning different from picking a voice from a library?
Can one voice model really cover multiple languages well?
What’s the difference between speech-to-speech and a standard TTS pipeline?
How should I estimate voice model cost at scale?