

Explore top Text to Speech API providers like Google and Amazon for lifelike voices and multilingual support. Discover free options today!
In today’s fast-paced world, businesses are dealing with an overwhelming number of customer calls, and it’s only getting harder to keep up. Long wait times and frustrated customers can lead to lost opportunities, and simply adding more human agents isn’t always the best solution. It's not scalable, and it often leads to more costs.
That's where automation comes in. By integrating Text-to-Speech (TTS) APIs into your systems, you can significantly enhance customer experience without overwhelming your team. TTS technology allows businesses to offer quicker, more efficient responses, improving overall engagement.
In this article, we’ll dive into the top TTS APIs, how they work, and why they’re essential for improving customer interactions. We’ll also explore some of the best paid and free Text-to-Speech options for businesses, helping you make the most of TTS technology without breaking the bank.
What is a Text-to-Speech (TTS) API?
A Text-to-Speech (TTS) API is a cloud-based tool that uses AI to convert written text into natural-sounding speech. These APIs are increasingly popular for creating lifelike audio across different applications, from virtual assistants to accessibility tools. The key capability of TTS APIs is generating clear, high-quality audio files that mimic human speech, with support for various languages and accents.
TTS APIs allow customization, so you can tweak the voice, tone, and pace to suit specific needs. These APIs also support multiple languages, making them versatile for global applications.
TTS technology is used in various fields, from personal assistants and navigation systems to e-learning platforms and accessibility tools for those with visual impairments or reading difficulties. By turning text into lifelike speech, TTS helps businesses and developers improve user interaction and accessibility.
Now that we’ve covered what a TTS API is, let’s dive deeper into how exactly this technology works and how it brings your text to life.
How Does Text-to-Speech Technology Work?
Text-to-Speech (TTS) technology works by converting written text into lifelike speech using advanced algorithms. Here’s how it works:
Send Text Input: The text, often in JSON format, is sent to the TTS API for processing.
Text Formatting with SSML: The text is formatted using Speech Synthesis Markup Language (SSML), which helps enhance the synthesis with features like pauses, tone adjustments, and emphasis.
Generate and Return Audio: The API returns the synthesized speech, which can be further customized in terms of accent, gender, and voice style to suit the user’s needs.
The returned audio can be personalized, allowing users to choose the voice characteristics (accent, gender, style) for a more tailored experience.
Next, let's explore how AI, especially deep learning and large language models, is making these systems smarter and more natural-sounding.
How AI is Advancing TTS APIs
Advancements in AI, particularly deep learning and Large Language Models (LLMs), have greatly enhanced the capabilities of Text-to-Speech (TTS) systems. These technologies allow for more accurate pronunciation, natural inflections, and smoother transitions between words, resulting in speech that sounds far more human-like. Platforms like OpenAI's TTS, ElevenLabs, and Meta's voice synthesis are leading the way by integrating multimodal AI, enabling them to adapt speech to different contexts in real-time, making the output even more expressive and responsive.
Key ways AI is advancing TTS APIs include:
Improved Speech Quality: AI models, trained on vast datasets of human speech, generate voices with better accuracy, inflections, and natural transitions.
Voice Personalization: AI allows customization of voice characteristics like accent, pitch, and tone and even enables the creation of unique synthetic voices from a small sample.
Real-Time Generation: With AI, TTS systems can generate speech instantly, making it ideal for live voice narration or interactive voice assistants.
Multilingual Capabilities: AI-powered TTS APIs support a wide range of languages, ensuring high accuracy for global communication.
Contextual Understanding: AI analyzes the context of the text, adjusting speech delivery to emphasize certain words or phrases and convey meaning more effectively.
With these advancements, TTS systems are becoming more versatile and can now handle a wide range of tasks, from personalized voice assistants to real-time voice narration.
As TTS APIs continue to evolve, their applications are expanding in fascinating ways. Here's a look at how businesses and developers are using TTS to improve accessibility, engagement, and productivity.
Use Cases for Text-to-Speech (TTS) APIs
Text-to-Speech (TTS) APIs are being used in many industries to improve accessibility, user engagement, and overall experience. Let’s explore these in depth.
Accessibility Solutions: TTS technology is crucial for supporting visually impaired individuals. By converting text into speech, it helps users access digital content without relying on sight. It’s also beneficial for those with reading impairments like dyslexia, as TTS can read content aloud, making it easier to understand.
User Engagement: TTS enhances interactivity by powering conversational interfaces like virtual assistants (e.g., Siri, Alexa). These systems make it possible for users to interact with devices using natural speech. Additionally, TTS is used in multimedia content creation, allowing creators to add professional-quality voiceovers to videos, podcasts, and advertisements, improving engagement.
Automotive & Smart Devices: In the automotive industry, TTS enables hands-free navigation, providing real-time spoken directions for safer and more efficient driving. Similarly, in smart home devices, TTS helps devices like thermostats or security systems communicate with users.
E-learning & Education: TTS is revolutionizing education by converting textbooks and educational materials into speech. This auditory approach helps students learn in a more interactive and accessible way.
Content Creation: TTS is also transforming the audiobook industry, where it’s used to convert written content into natural-sounding audio, making books accessible for those who prefer listening.
Customer Support: Finally, TTS enhances chatbot and virtual assistant interactions, providing faster and more accurate responses in customer service scenarios.
TTS technology is transforming how we engage with digital content across industries. If you’re looking to explore more personalized and scalable voice solutions, Smallest.ai offers real-time, AI-driven TTS capabilities that can seamlessly fit into your needs.
Now that we've covered some key use cases for TTS APIs, let’s take a look at some of the popular providers offering these solutions.
Popular Text-to-Speech API Providers: Established Leaders in the Industry
With so many options available, it can be tricky to choose the right Text-to-Speech API for your needs. Let’s explore some of the top providers offering high-quality TTS solutions.
1. Amazon Polly
Amazon Polly is a robust text-to-speech (TTS) API that converts text into lifelike speech. As part of the AWS ecosystem, it offers seamless integration and scalability, making it ideal for developers looking to build speech-enabled applications.
Key Features:
Multi-language support: Translates text into over 20 languages, with variations.
Customizable speech: Adjust pitch, rate, and loudness to suit your needs.
MP3 export: Easily export audio as MP3 files for use across platforms.
SSML support: Allows you to use Speech Synthesis Markup Language to fine-tune speech, including adding pauses and adjusting pronunciation.
Realistic voices: Uses deep learning technology to produce natural-sounding speech.
Pros:
Seamless AWS integration: Works well with other AWS services, making it easier to scale.
Cost-effective pricing: Pay-per-use model with affordable rates.
Extensive language support: Offers a wide range of languages and dialects.
Cons:
Complex setup: Can be challenging for beginners due to its integration and configuration.
Lower voice quality: Some voices may sound less natural compared to competitors.
Learning curve: Requires some familiarity with AWS and APIs to get started.
Pricing:
Standard Voices: $4 per million characters.
Neural Voices: $16 per million characters.
Free Tier: Offers limited access to voice options, perfect for smaller-scale or test projects.
Common Use Cases:
Customer Service: Automate responses for more efficient support.
E-learning: Enhance learning materials with realistic narration.
Media Applications: Create voiceovers for podcasts, videos, or audiobooks.
Amazon Polly is an excellent choice for developers looking for a scalable and flexible TTS solution, particularly if you’re already working within the AWS ecosystem.
2. Google Cloud Text-to-Speech
Google Cloud’s Text-to-Speech API offers a powerful solution for businesses and developers looking to integrate AI-generated speech into their apps and systems. Using Google’s DeepMind AI, it creates near-human quality voices, making it a popular choice among users.
Key Features:
Supports over 40 languages with 380+ voices.
Uses SSML for customizing voice pitch, rate, loudness, and pauses.
Exports to various audio formats, offering flexibility for different use cases.
WaveNet voices (using DeepMind’s neural network) provide high-quality, natural-sounding audio.
Voice customization: You can adjust parameters like pitch, speed, and even create a unique brand voice through custom training.
Pros:
Cutting-edge AI technology for high-quality voice generation.
Extensive range of languages and voices.
Customizable voices with detailed control over speech characteristics.
Cons:
Privacy concerns related to data storage and usage.
Cost implications: Can get expensive depending on usage.
Voice naturalness may fall short in comparison to other specialized providers.
Pricing:
Standard voices: $4 per million characters.
WaveNet voices: $16 per million characters.
Use Cases:
Virtual assistants like Google Assistant.
Accessibility tools for people with visual impairments.
Content creation for podcasts, videos, and e-learning materials.
Google Cloud Text-to-Speech API is a robust, scalable option for developers and businesses, offering rich features and customization options but with some considerations around privacy and cost.
3. Microsoft Azure Text-to-Speech
Microsoft Azure’s Text-to-Speech API is a part of the Azure Cognitive Services suite, designed to offer powerful, scalable speech synthesis.
Key Features:
Over 80 languages and regional accents are supported.
Neural text-to-speech with SSML (Speech Synthesis Markup Language) for fine-tuned control over audio features like speed, pitch, and pauses.
Custom neural voice allows users to create personalized voices using real voice samples.
Integrates seamlessly with other Microsoft services, making it perfect for enterprise-level applications.
Pros:
Extensive language and voice options.
Highly scalable and suitable for large enterprise applications.
Robust integration with Microsoft services like Azure AI and IoT.
Cons:
Complex setup and management can be challenging, especially for beginners.
Some voices can be less natural-sounding compared to other TTS solutions.
Requires familiarity with the Azure ecosystem to make the most of its capabilities.
Pricing:
$15 per 1M characters. The pricing model is competitive, especially for large-scale applications.
Use Cases:
Enterprise applications like customer support and automation.
Accessibility tools to assist users with disabilities.
IoT devices, enabling speech capabilities for connected products.
Microsoft Azure is ideal for businesses looking for a scalable, customizable TTS solution, especially if you're already working within the Azure ecosystem. While the setup can be complex, its capabilities are robust for large-scale enterprise needs.
4. IBM Watson Text-to-Speech
IBM Watson Text-to-Speech (TTS) is a powerful AI-driven service designed for app development and commercial services. It offers end-to-end encryption for secure data processing and is known for delivering high-quality, natural-sounding voices.
Key Features:
Custom Voices: You can create a custom voice from a one-hour recording, allowing for personalized speech options.
Speech Adjustments: Use SSML to modify speech qualities like volume, pitch, speed, and pronunciation.
Multiple Voice Types: Choose between expressive neural voices and enhanced neural voices for natural-sounding speech.
Language Support: Handles over 14 languages and their variations, making it great for global use.
Audio Formats: Supports various formats, including MP3, WAV, FLAC, and OGG.
Pros:
High-quality, lifelike voices with minimal delay.
Flexibility in customizing voices and adjusting speech characteristics.
Robust security features with end-to-end encryption.
Cons:
Premium features like custom voice creation require additional setup and a more significant time investment.
May require technical knowledge to fully utilize features like SSML.
Pricing:
Lite: Free plan with 10,000 characters per month. Ideal to get started at no cost.
Standard: Starting at USD 0.02 per thousand characters. Offers unlimited characters, high-value features, and guaranteed uptime.
Premium: Custom pricing. Designed for large, security-sensitive firms with custom-branded neural voices, 99.9% uptime, and enhanced data protection.
Use Cases:
Ideal for app developers, customer service applications, and any business requiring natural, scalable text-to-speech solutions.
Widely used in industries like healthcare, customer support, and education.
Overall, IBM Watson Text-to-Speech is a reliable and flexible option for businesses and developers looking to integrate high-quality speech synthesis into their applications.
5. ResponsiveVoice
ResponsiveVoice is an HTML5-based Text-to-Speech library that adds voice features to websites and apps, making them more accessible. It’s compatible with smartphones, tablets, and desktops, offering versatility across devices.
Key Features:
51 Languages Supported: Offers text-to-speech in 51 languages with over 190 voices, providing global accessibility.
HTML5-Based: Utilizes HTML5 for client-side text-to-speech with server fallback, ensuring reliable performance.
Developer API: Easy integration with just one line of code, ideal for developers.
WordPress Plugin: Simplifies integration for WordPress sites without complex coding.
Pros:
Wide language and voice support: Covers a broad range of languages and voices.
Cross-platform compatibility: Works on smartphones, tablets, and desktops.
No dependencies: Doesn’t require additional plugins or software.
Ease of use: Simple to integrate across platforms.
Cons:
Limited customization: Lacks advanced features offered by other TTS platforms.
Free version limitations: Some features are restricted for high-traffic sites.
Pricing:
Free: Available with limitations for high-traffic sites.
Pro: $39/month (billed annually) or $49/month (billed monthly).
Enterprise: Custom pricing for large-scale sites.
Use Cases:
Website Accessibility: Helps improve accessibility for users with visual impairments.
Queue Management Systems: Announces ticket numbers in real-time.
E-Learning: Provides audio for educational content.
ResponsiveVoice is ideal for businesses, content creators, and educators aiming to improve user engagement with voice features.
While popular TTS APIs have set the standard, innovative solutions are now emerging with advanced features. Let’s explore these New & Innovative TTS APIs gaining traction.
New And Innovative APIs: The Next Generation of TTS Solutions
As the demand for more advanced and customizable TTS solutions grows, new and innovative APIs are stepping up to offer cutting-edge features and greater flexibility. Let’s explore them.
1. Smallest.ai
Smallest.ai offers two groundbreaking products—Waves and Atoms—that enhance AI-driven voice interactions. Waves is a real-time text-to-speech (TTS) platform, while Atoms powers AI-driven automation for virtual assistants and IVR workflows. Whether you're creating lifelike voiceovers or automating customer interactions, the focus lies on hyper-personalization, low latency, and scalability to meet the needs of businesses and content creators alike.
Key Features:
Hyper-realistic voice synthesis: Produces studio-quality voices that mimic human speech patterns and emotions.
Multi-language and accent support: Offers over 50 languages and diverse accents to suit a global audience.
Real-time processing with low latency: Achieves sub-100ms latency for seamless use in live applications, including IVR and AI-driven customer support.
Real-time conversational AI: Capable of answering inquiries and providing immediate assistance.
Natural language understanding: Accurately interprets and responds to customer queries.
Scalability: Designed to handle high-volume AI voice generation with seamless API integration, making it ideal for enterprises requiring large-scale audio synthesis.
Pros:
High-quality, customizable voices.
Instant voice cloning for personalized experiences.
Quick setup via easy API and Python SDK.
Cons:
The free plan offers limited usage, which may not be enough for high-volume needs.
Pricing Plans:
Free Plan: 30 minutes/month.
Basic Plan ($5/month): 3 hours/month, 1 instant voice clone.
Premium Plan ($29/month): 24 hours/month, 2 voice clones, enhanced API access.
Use Cases:
Media & Content Creation: Ideal for audiobooks, podcasts, and video voiceovers.
Customer Support: Automates FAQs, freeing up agents for complex issues.
Appointment Scheduling: Automates booking and managing appointments.
With competitive pricing and customizable features, Smallest.ai is an excellent choice for businesses looking to innovate and scale efficiently.
2. Speechelo
Speechelo is a user-friendly text-to-speech tool that integrates seamlessly with your video creation software, making it easy to add voiceovers to your projects.
Key Features:
Works with Any Video Creation Software: Speechelo integrates easily with tools like iMovie, Adobe Premiere, Audacity and more.
AI-Powered Text Editor: The built-in editor enhances your text, automatically adding punctuation for natural pauses.
Voice Customization: Adjust speed, pitch, and tone for a personalized voiceover experience.
Multi-Language Support: Choose from 23 languages and 30 voices (Standard), or expand to 60 voices and 40 background music tracks (Pro).
Pros:
No monthly fees; one-time payment.
Supports many languages and different voice styles.
Cons:
Some voices can sound robotic.
Limited customization compared to other TTS tools.
Pricing Plans:
Standard: $97 for 30 voices, 23 languages, and basic voice customization.
Speechelo Pro: Same price as the Standard, but includes 60 voices, 40 background music tracks, and a commercial license.
Speechelo World Wide: $197, offering translation and voiceovers in 20 languages.
Use Cases:
Voiceovers for Video Content
Podcasting
Speechelo offers solid features at a one-time cost, making it a good option for video creators, but it may not be the best choice for those needing highly dynamic voice customization.
3. Play.ht
Play.ht combines voices from top AI databases, including Amazon, Google, IBM, and Microsoft, offering a broad selection of voices across various languages. Its integration of the International Phonetic Alphabet (IPA) allows users to customize pronunciations, making it highly versatile for specialized needs.
Key Features:
Real-time voice generation
Over 142 languages and accents
Custom pronunciation options using IPA
Audio widget integration for websites
Supports both text and SSML for detailed speech adjustments
Pros:
Realistic voice synthesis
Wide selection of voices in 142+ languages and accents
Easy-to-use platform, great for beginners and professionals alike
Cons:
High latency, which may be an issue for real-time applications
Limited advanced features
Lacks scalability for handling larger, real-time use cases
Pricing:
Basic Plan: $19/month with limited voice options
Premium Plan: $99/month for more voices and advanced features
Use Cases:
Social media content and podcasts.
Educational videos
Interactive voice response (IVR) systems
Play.ht offers a solid TTS solution for various needs, with a focus on accessibility and customization. The platform’s broad language support and AI voices make it especially useful for content creators looking to enhance their videos, podcasts, and educational content.
4. NaturalReader
NaturalReader is a user-friendly text-to-speech software designed to enhance accessibility and learning. It’s particularly helpful for people with dyslexia, visual impairments, or anyone who prefers auditory learning. The tool converts written content into natural-sounding speech, making it easier to process information.
Key Features:
Text-to-speech: Converts text into audio in multiple voices and languages.
Multiple languages: Supports a wide variety of languages and accents.
Customizable voices: Adjust speed, pitch, and tone for personalization.
OCR technology: Extracts text from images for conversion.
Browser extension: Converts web content directly to speech.
Integration capabilities: Works with various platforms to improve accessibility.
Pros:
Audio file export: Save spoken text as files for offline listening.
Cloud storage access: Directly pull documents from cloud services.
Real-time conversion: Quick text-to-speech conversion.
Cons:
Limited voices: Free version offers fewer voices.
Internet dependency: Requires a stable connection.
Pricing: Advanced features are locked behind a paywall.
Pricing:
Free: $0/year
PLUS: $20.90/month or $119/year
Use Cases:
Ideal for students, professionals, and anyone looking to improve accessibility and learning.
5. WellSaid Labs
WellSaid Labs is known for its high-quality, human-like voices, making it a popular choice for businesses in need of professional-grade text-to-speech solutions. It’s especially favored for use in e-learning, marketing videos, and podcasting. The platform offers a user-friendly interface, making it accessible for both beginners and experienced users.
Key Features:
120+ Studio-Quality Voices: Offers a wide variety of voices, ensuring a natural, engaging sound.
User-Friendly Interface: Easy to use, even for those with minimal technical expertise.
Easy Integration: Smooth integration with various applications, enhancing usability.
Pros:
High-Quality Voices: Excellent voice quality that’s ideal for professional projects.
User-Friendly: No technical skills needed to get started.
Wide Application: Works well for e-learning, marketing, and podcasts.
Cons:
High Latency: Can experience delays, making it less suitable for real-time applications.
Limited Voice Customization: Fewer options for tweaking voices to match specific needs.
Higher Costs for Extensive Usage: The pricing may be higher for users with large-scale needs.
Use Cases:
E-learning Courses
Marketing and Promotional Videos
Podcast Voiceovers
Pricing:
Starts at $89/month, which is suitable for individuals or small projects but can get expensive with more extensive use.
WellSaid Labs offers a great solution for those needing professional-grade, human-like voices for content creation, though it’s important to weigh the costs and potential limitations for large-scale projects.
Now that we've explored the key players in the text-to-speech API market, let's compare them side-by-side to help you understand how they stack up in terms of features, pricing, and performance.
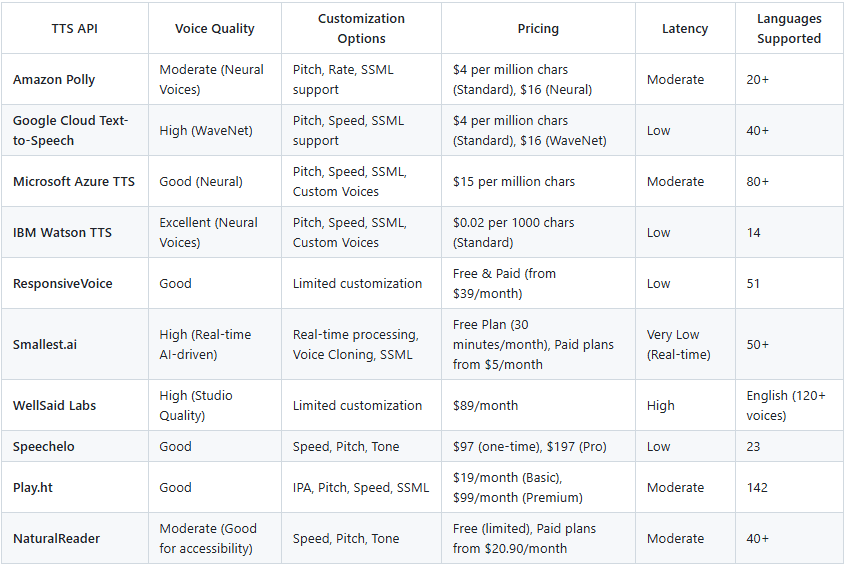
Now that we’ve explored the top Text-to-Speech API players, let’s take a look at the key factors you should consider when selecting the right TTS API for your needs.
Key Factors to Consider When Choosing a TTS API
When choosing a text-to-speech (TTS) API, here are the important factors to consider:
Voice Quality: Prioritize APIs that provide natural, human-like voices. High-quality voice synthesis is crucial for applications like voiceovers, content creation, and media production.
Language Support: Look for APIs that support multiple languages and accents. This helps you reach a diverse audience and cater to different markets.
Integration and Scalability: Make sure the TTS API integrates easily with your existing systems and can scale as your business grows. This is especially important for high-throughput applications or customer-facing solutions.
Cost-Effectiveness: Evaluate the pricing models carefully. Consider the API’s features, your expected usage, and scalability to ensure the cost fits within your budget.
Customer Support: Choose a provider that offers solid customer support and thorough documentation. This ensures smooth setup and quick troubleshooting when issues arise.
Latency: For real-time applications like chatbots, virtual assistants, or live streaming, low latency is essential for quick response times.
Customization Options: Some TTS APIs offer the ability to adjust pitch, speed, and tone. Customization can help tailor the voice to match your brand or specific use case.
Trial Options: Many TTS APIs offer free trials. Take advantage of these to test the performance and features before making a decision.
Conclusion
Text-to-speech (TTS) technology is transforming the way businesses interact with customers, streamline workflows, and improve accessibility. Whether you’re looking for natural-sounding voiceovers for multimedia content, efficient customer service automation, or accessibility tools, there’s a TTS API to suit every need.
Ready to enhance your customer experience with AI-driven voice solutions? Try Smallest.ai today and explore its real-time AI-powered TTS features, including voice cloning and instant speech synthesis. Sign up for free and start transforming your interactions with lifelike, scalable voice solutions.
FAQs
1. What is a Text-to-Speech API?
A Text-to-Speech (TTS) API is a cloud-based service that uses AI to convert text into natural-sounding speech. It's used in various applications such as virtual assistants, accessibility tools, and multimedia content creation.
2. How does Smallest.ai's TTS API stand out from Text-to-Speech APIs?
Smallest.ai offers real-time AI-driven voice synthesis, ensuring low-latency processing with high-quality, customizable voices. It supports over 50 languages and offers instant voice cloning, making it ideal for businesses and content creators who need personalized, scalable solutions.
3. What are the pricing plans for Smallest.ai's TTS API?
Smallest.ai offers a free plan with 30 minutes of TTS per month. Paid plans start at $5/month, offering more features like enhanced voice cloning and access to real-time processing for higher volumes of speech synthesis.
4. How do I select the best TTS API for my business?
When choosing a TTS API, consider factors like voice quality, latency, integration ease, language support, and scalability. You’ll also want to ensure the API fits your budget and use case, whether for customer support, content creation, or accessibility.
5. What are the key use cases for Text-to-Speech technology?
TTS technology is widely used in accessibility solutions (e.g., for visually impaired users), virtual assistants (e.g., Siri, Alexa), voiceovers for multimedia content, real-time customer service automation, and interactive voice response (IVR) systems.

