

Speech to text vs voice to text: they run on the same ASR tech. See where the terms diverge, how transcription works, and what to evaluate in tools.
Speech to text is the technology that turns spoken audio into a written transcript, using machine learning and computational linguistics. The process starts with audio captured by a microphone, which is digitized through an analog-to-digital converter. From there, software models map the resulting sound data to phonemes, words, and sentence structures.
So where does "voice to text" land in all of this? If you have caught yourself wondering whether the two phrases point to different tech stacks or just different ways of saying the same thing, you are in good company. The gap between them is small, highly situational, and easy to overthink. Here is the practical breakdown: what each term tends to signal, when the distinction is useful, and when it is just noise.
The Honest Answer: They Describe the Same Core Technology
Most of the time, "speech to text" and "voice to text" are two labels for the same workflow: software listens to spoken audio and outputs a text transcript. IBM defines speech-to-text as converting spoken words into text and even calls out that it is "sometimes referred to as voice-to-text." In everyday usage, the terms are largely interchangeable.
Both terms are used across the same category of transcription and speech-recognition products, even though different teams often prefer different terminology.
Where the Terminology Actually Diverges

Same engine, different contexts: how each term tends to be used in practice.
The tech is the same, but the language has drifted toward different audiences. In developer and research contexts, "speech to text" is the default. It shows up in API docs, SDKs, research papers, and enterprise procurement checklists. When engineers talk about speech-to-text APIs, they usually mean programmatic interfaces that ingest files or streams and return transcripts reliably at scale.
"Voice to text" tends to be the product-facing phrasing. It is the microphone button on a mobile keyboard, the dictation toggle in a word processor, the setting tucked into accessibility menus. Functionally, it is still ASR producing text. The difference is framing: one reads like a building block in a system design doc, the other reads like a feature a user can turn on.
Dimension | Speech to Text | Voice to Text |
|---|---|---|
Primary audience | Developers, enterprises, researchers | Consumers, end users |
Common placement | API docs, SDKs, technical specs | Mobile keyboards, dictation apps, accessibility settings |
Typical use case | Transcription pipelines, voice agents, call analytics | Hands-free typing, accessibility, quick notes |
Underlying technology | ASR / ML models | ASR / ML models (identical) |
Industry standard term? | Yes, widely adopted | Informal, product-layer label |
How the Technology Actually Works
No matter what a product calls it, the mechanics are consistent. A microphone captures analog sound. An analog-to-digital converter samples that signal thousands of times per second, translating a continuous waveform into a stream of numbers. After that handoff, machine learning does the heavy lifting.
Modern ASR systems are trained on large and diverse audio datasets to improve robustness across accents, speaking styles, and noisy environments. They learn to map audio patterns to phonemes (the smallest units of sound) and then to words and sentences. In engineering terms, this end-to-end path from raw audio to structured text is automatic speech recognition (ASR): capture, processing, inference, and a transcript you can actually use.
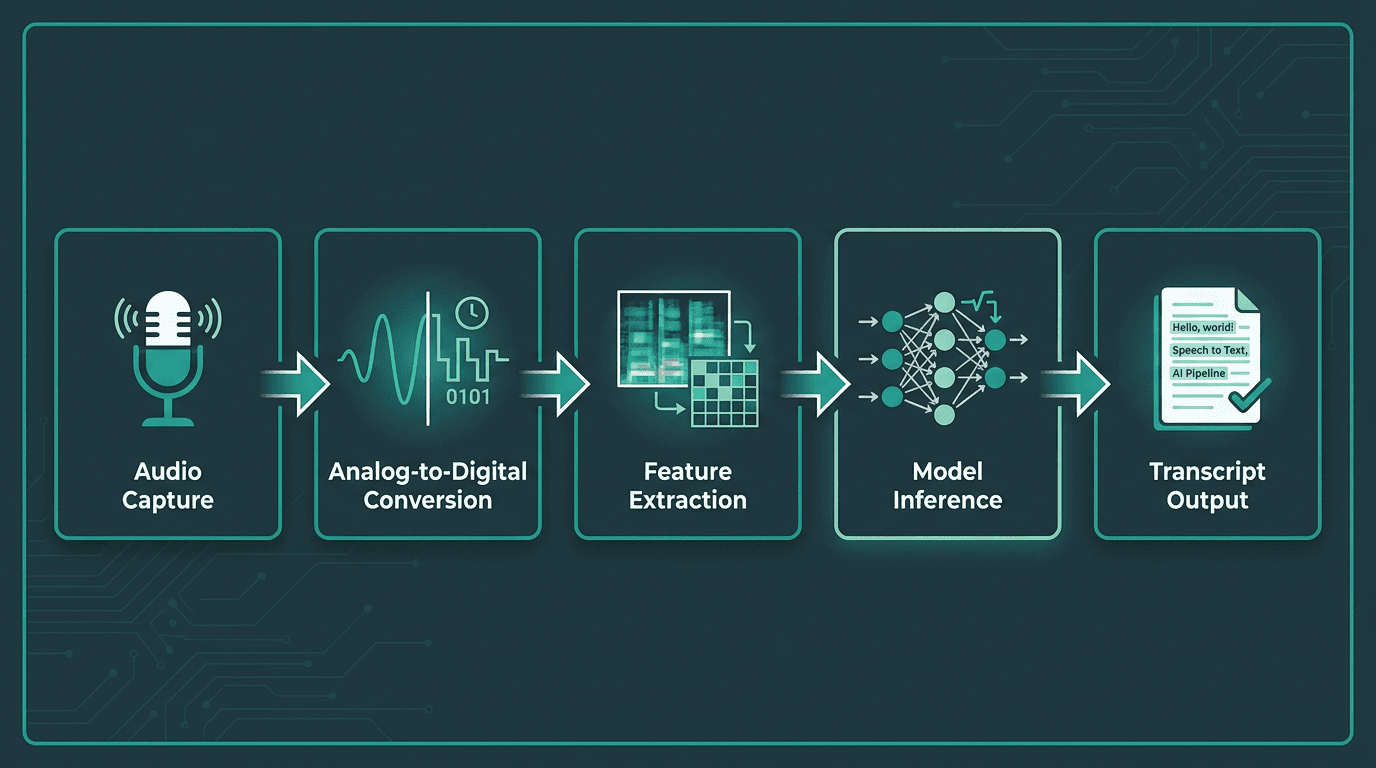
The five-stage pipeline that converts spoken audio into a text transcript.
A Brief History Worth Knowing
The terms evolved from different communities. "Speech to text" became common in research and enterprise software, while "voice to text" became popular through consumer products such as smartphone dictation. That history is a big part of why both phrases still circulate, even when they point to the same underlying engine.
Real-World Applications: Where Each Label Shows Up

Speech-to-text technology powers a wide range of industries and use cases.
You will see the same capability described differently depending on where it shows up in the product. These are the places each label usually appears:
Where 'speech to text' appears in practice:
Contact center analytics: Platforms transcribe thousands of customer calls per day to pull out sentiment, compliance flags, and agent performance signals.
Voice agents: Conversational AI systems use speech-to-text as the front door to a pipeline that also includes language understanding and response generation. Real-time speech-to-text with low latency is critical here.
Medical transcription: Clinicians dictate notes that are transcribed into structured EHR entries, cutting documentation time significantly.
Developer APIs: Services expose speech-to-text as an endpoint that accepts audio files or streams and returns JSON transcripts.
Where 'voice to text' appears in practice:
Mobile keyboard dictation: iOS and Android both ship a microphone button that drops transcribed speech straight into any text field.
Accessibility tools: Screen readers and assistive input systems use voice-to-text to let users with motor impairments write without a keyboard.
Smart home devices: Voice commands that trigger actions often run through a voice-to-text step before intent classification.
Productivity apps: Note-taking and document tools often market dictation as voice-to-text because it is the phrasing most non-technical users recognize.
Three Common Misconceptions
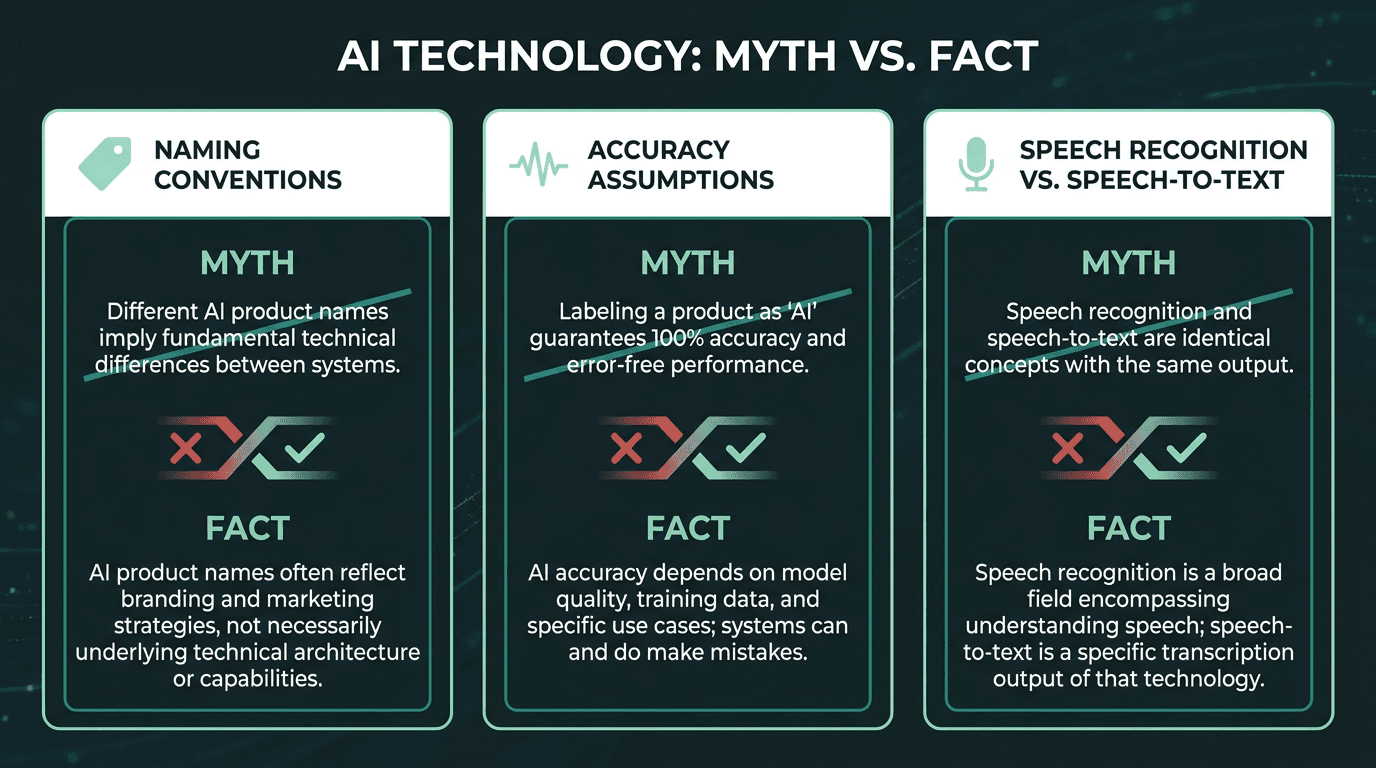
Three persistent myths about speech-to-text and voice-to-text technology.
Misconception 1: Different names mean different technologies. The name usually tells you who the product is talking to, not how it is built. A consumer dictation feature and an enterprise transcription API can run on the same model family. In most cases, the wording is a marketing and UX choice, not an architectural one.
Misconception 2: Voice to text is less accurate. People sometimes assume consumer "voice-to-text" is automatically lower quality than enterprise "speech-to-text." Accuracy comes down to the model, the training data, and the audio you feed it, not the label on the button. A well-tuned mobile dictation system can beat a poorly configured enterprise deployment.
Misconception 3: Speech recognition and speech to text are the same thing. Speech recognition is the umbrella field: detecting and interpreting spoken language. Speech to text is one specific output, where the goal is a transcript. Capabilities like speaker diarization (who said what), language identification, and intent classification are part of speech recognition too, but they are not the same as transcription.
Choosing the Right Tool for Your Use Case
If you are comparing vendors, the terminology matters less than whether the system fits your workload. Focus on latency, accuracy on your actual audio, language support, and how the API slots into your stack. The best speech-to-text AI options in 2026 are easier to evaluate when you treat accuracy and latency as a trade space, not a branding contest.
If you are building voice-first software, architecture beats vocabulary every time. A typical voice agent chain runs speech-to-text into a language model and then back out through text-to-speech. Each hop burns time, and speech-to-text often sets the lower bound for how fast the whole system can respond. When you're ready to build, you will want to look for the best speech-to-text APIs for voice agents to ensure performance.
Key Takeaways
What you need to know about speech to text vs voice to text:
Speech to text and voice to text point to the same core capability: converting spoken audio into a written transcript.
The split is mostly about context. 'Speech to text' dominates developer and enterprise environments; 'voice to text' shows up more in consumer products.
Under the hood, the flow is consistent: audio capture, analog-to-digital conversion, and ML models trained on large audio datasets.
Accuracy is driven by model quality, training data, and audio conditions, not by which phrase a product uses.
Speech recognition is the broader field; speech to text is specifically the transcription output.
If you are building or buying, prioritize latency, accuracy, language support, and API design over naming.
The top speech-to-text transcription software options in 2026 cover both consumer and enterprise needs, across both labels.
The Problem This Confusion Actually Creates
This is not just a pedantic terminology debate. It creates real drag when teams are scoping features, writing specs, or comparing vendors across product and engineering. A product manager asking for "voice to text" and an engineer searching for "speech to text APIs" can end up in different aisles of the same store, even though they want the same thing. Using "speech to text" for technical work, while treating "voice to text" as the consumer-friendly label, usually clears the air fast.
If you are building voice products, evaluate systems on performance rather than phrasing. Smallest.ai's Pulse Speech-to-Text API is a product aimed at low-latency transcription for production voice applications. It is built to act as the listening layer in voice agent pipelines, where every millisecond of transcription delay shows up in the response time users feel. Call it speech to text or voice to text; once you are shipping, the only thing that matters is whether transcription is fast, stable, and accurate.
Is there a technical difference between speech to text and voice to text?
Which term should I use when searching for an API or developer tool?
How accurate is modern speech-to-text technology?
What is the difference between speech to text and automatic speech recognition (ASR)?
Can I use a speech-to-text tool for real-time transcription in a voice agent?

