English Text to Speech: Best AI Voice Generators for Developers in 2026


Compare the best AI English text to speech generators in 2026. Covers voice quality, latency, API integration, pricing, and advanced use cases for developers
English text to speech technology has travelled a long way from the robotic monotone of early screen readers. Today's AI voice generators produce speech that is nuanced, emotionally aware, and nearly indistinguishable from a human recording. This is no longer a niche developer utility. It is infrastructure, sitting at the center of voice agents, accessibility tools, content pipelines, and customer-facing products.
This article is written for developers, content creators, and product teams who need to evaluate English voice generators seriously. You will come away understanding how the underlying technology works, what separates a genuinely good voice engine from a mediocre one, and which platforms are worth your time in 2026, covering TTS fundamentals, key quality signals, a platform comparison, API integration considerations, and advanced use cases.
What English Text to Speech Actually Does (and How)
Speech synthesis is the artificial production of human speech from text input. Early systems used concatenative synthesis, stitching together pre-recorded phoneme segments. The results were functional but immediately recognizable as machine-generated. The shift to neural TTS, driven by sequence-to-sequence models and later diffusion-based architectures, changed the quality ceiling entirely.
Modern English TTS pipelines run through three stages: text normalization (handling abbreviations, numbers, and punctuation), linguistic analysis (phoneme prediction, stress patterns, prosody modeling), and acoustic synthesis (converting linguistic features into an audio waveform). Acoustic synthesis is where the most dramatic improvements have landed. Neural vocoders like WaveNet and its successors capture the micro-variations in pitch, breath, and timing that make speech feel alive rather than assembled. IBM's overview of TTS technology covers these applications well, from accessibility tools to enterprise automation.
One standard every serious practitioner should know: SSML, the Speech Synthesis Markup Language specified by the W3C. SSML gives developers fine-grained control over pronunciation, pitch, rate, and volume using XML tags. If a production-grade TTS API does not support it, that is a red flag worth taking seriously before you commit.
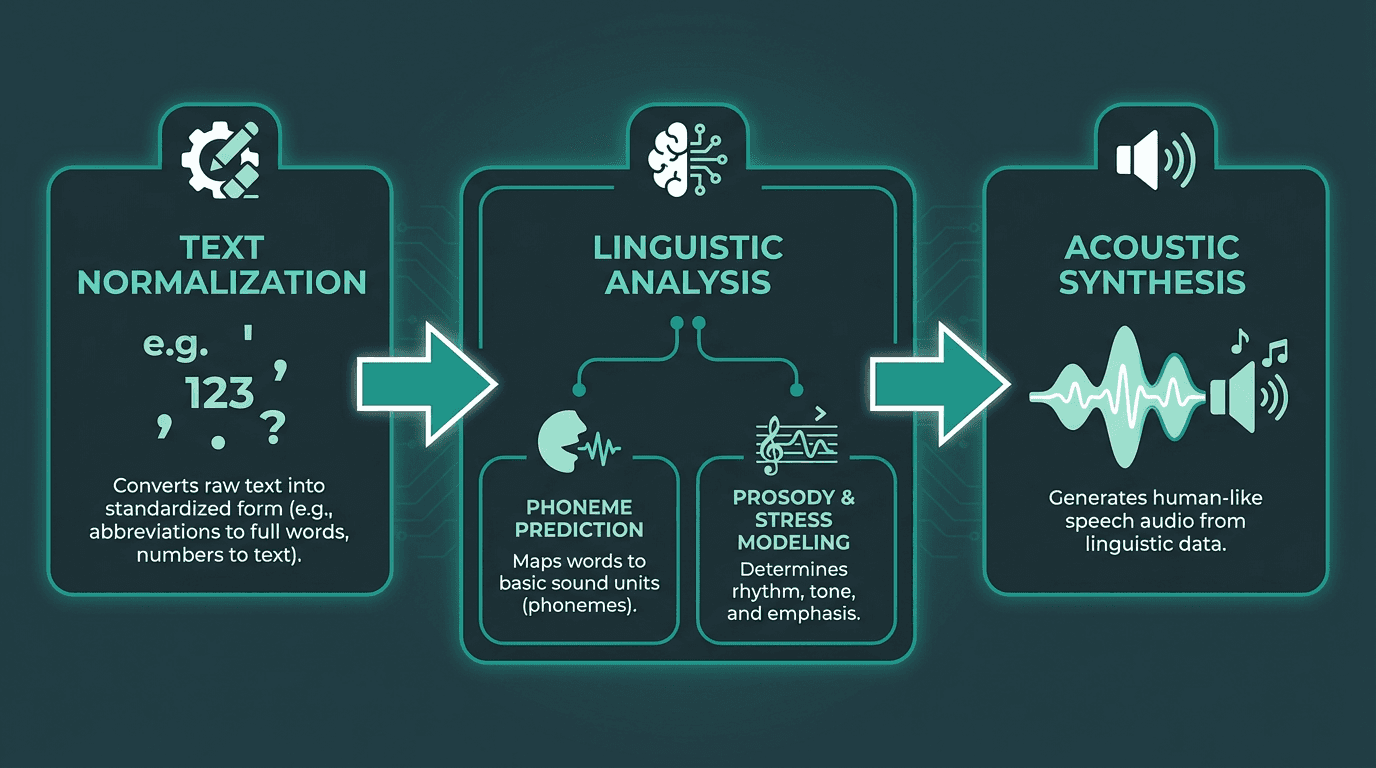
The three-stage neural TTS pipeline: from raw text to synthesized audio waveform
What Separates a Good English Voice Generator from a Great One
Most people evaluate TTS tools by listening to a demo clip. That is the wrong approach. Demo clips are cherry-picked. What you actually need to stress-test is how a voice engine handles edge cases: long sentences with complex clause structures, proper nouns it has never seen, emotional shifts mid-paragraph, and low-latency streaming for real-time applications.
Five signals actually matter when evaluating an English TTS engine. Prosody accuracy comes first: does the voice place stress on the right syllables and modulate pitch naturally across a full paragraph, not just a single sentence? Latency follows closely. For conversational AI and voice agents, sub-200ms streaming latency is what we consider the threshold for dialogue that feels natural rather than transactional. Emotional range matters too: can the voice shift from neutral narration to warm, conversational, or urgent tones without sounding forced? See human-like AI voices with emotion for a detailed breakdown. Voice consistency is the fourth signal: does the same voice character hold across a 10-minute audio file, or does it drift in style and energy? Finally, API reliability and SSML support determine whether a platform can actually survive production: stable uptime, predictable pricing, and the ability to fine-tune output programmatically.
One thing most comparison articles skip entirely is the difference between a voice that sounds good in isolation versus one that sounds good in context. A voice designed for audiobook narration will feel oddly formal inside a customer service chatbot. Matching the voice character to the deployment context is as important as the raw quality of the synthesis.
Best AI English Voice Generators in 2026: A Practical Comparison
The table below compares the leading English TTS platforms across the dimensions that matter most for real deployments. Pricing reflects publicly listed tiers as of April 2026. Editorial ratings for quality and latency are based on our internal evaluation for common use cases.
Platform | Voice Quality (Editorial) | Latency (Editorial) | SSML Support | Best For | Starting Price |
Smallest.ai | High | Low-latency | Yes | Voice agents, real-time apps | Free tier available; see full pricing |
High | Low | Yes | Audiobooks, content creation | Paid plans available | |
Good | Medium | Limited | General purpose, GPT integrations | Usage-based | |
Good | Low | Limited | Transcription-first workflows | Usage-based | |
Good | Low | Partial | Edge/embedded deployments | Usage-based |
Smallest.ai: Built for Real-Time English Voice
Smallest.ai's realistic text-to-speech engine is designed from the ground up for latency-sensitive applications. The Lightning TTS model delivers streaming audio with time-to-first-byte as low as 100ms, which is the threshold that makes voice agents feel like actual conversations rather than call-and-response systems. The voice library covers a wide range of English accents and character types, and the platform supports AI voice cloning for teams that need a consistent branded voice across products. The Text-to-Speech API is well-documented with straightforward authentication and streaming endpoints, and the free tier makes it accessible for prototyping without upfront commitment.
Practical Integration: Getting English TTS Into Your Product
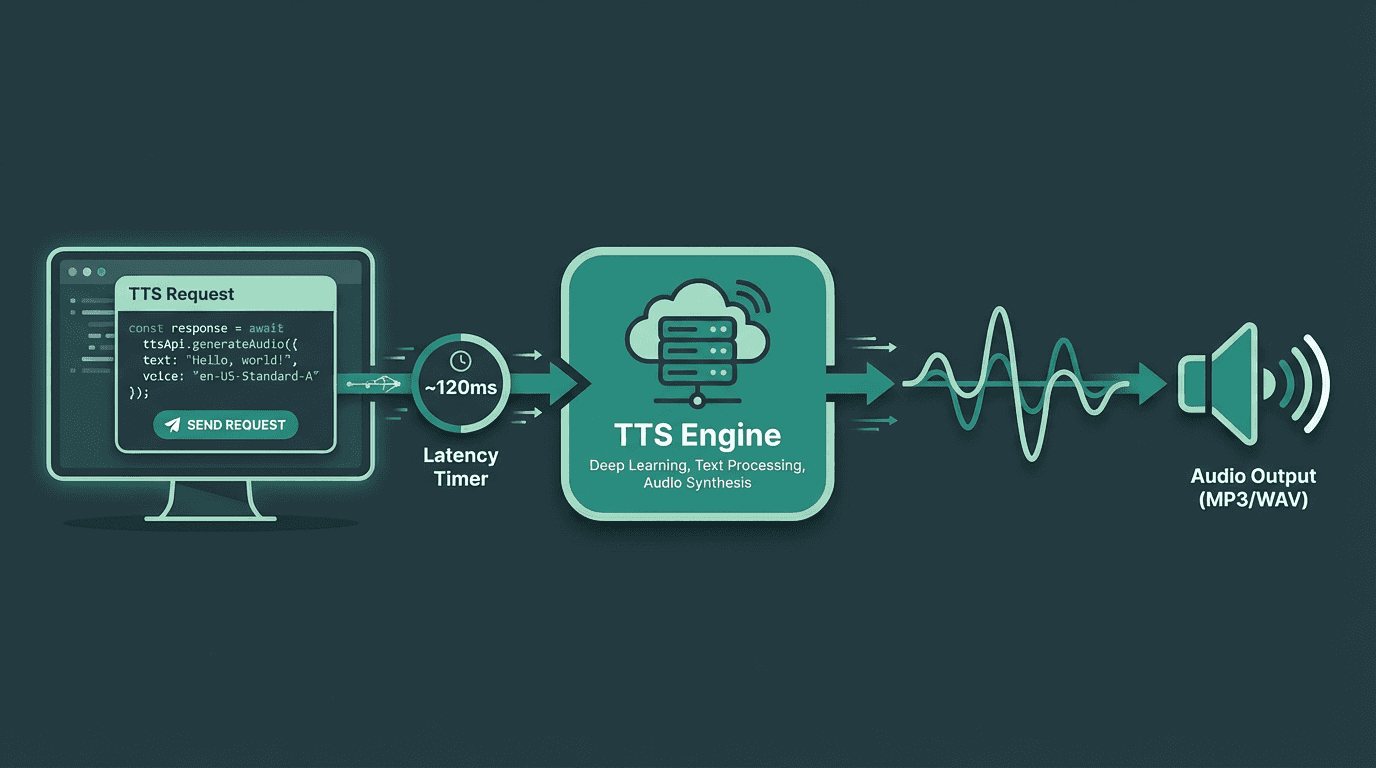
A typical TTS API integration: text input travels to the synthesis engine and streams back as audio in real time
The gap between 'it works in a demo' and 'it works in production' is wider for TTS than most developers expect. Three integration decisions tend to determine whether a deployment holds up.
Streaming vs. Batch Generation
Batch generation (send text, receive a complete audio file) suits pre-produced content: podcast intros, e-learning modules, IVR prompts that do not change. Streaming is essential for anything interactive. When a user asks a question and expects a spoken answer, waiting two or three seconds for a full audio file to render before playback starts breaks the conversational feel entirely. If you are building AI voice agents, streaming TTS is not optional.
Voice Selection and Consistency
Pick a voice early and commit to it across your product. Switching voices between features or screens creates a disjointed experience that users notice even if they cannot articulate why. If your brand requires a specific accent or character type, confirm that the platform supports custom voice cloning before locking in a provider. Rebuilding a voice integration mid-product is painful and disruptive.
Cost Modeling at Scale
TTS pricing is typically per character or per thousand characters. A customer service bot handling 10,000 conversations per day, each averaging 500 characters of synthesized speech, generates 5 million characters daily. For a hypothetical pricing model of $0.015 per thousand characters (a rate in the range of some providers in 2026), that usage would translate to $75 per day or roughly $2,250 per month just for voice synthesis. Run the numbers against your actual usage before assuming a provider's pricing is workable. The best free text-to-speech generators guide covers options for teams with tighter budgets.
Advanced Considerations: When Standard TTS Is Not Enough
Most English TTS guides stop at 'here are the tools, here is how to call the API.' Three edge cases tend to catch experienced teams off guard.
Prosody control for technical content. Standard TTS handles conversational English well. It struggles with technical jargon, acronyms, and domain-specific terminology. A voice that pronounces 'SQL' as 'sequel' inside a developer tool will erode user trust fast. SSML's phoneme tags let you override pronunciation explicitly. Not every platform exposes this in its consumer-facing interface, but it is available at the API level for most serious providers.
Multilingual English contexts. English is spoken with dramatically different phonological patterns across regions: American, British, Australian, Indian, and Nigerian English all have distinct stress patterns and vowel sounds. A single 'English voice' that sounds natural to one audience can feel subtly off to another. If your product serves a global English-speaking audience, test your chosen voice with users from your primary markets before launch, not after.
Accessibility as a design requirement, not an afterthought. TTS is a critical accessibility tool for people with visual impairments or reading disabilities like dyslexia. If accessibility is a stated product requirement, your TTS implementation needs to meet WCAG standards, which means more than just 'the audio plays.' It means correct semantic reading order, appropriate handling of tables and lists, and reliable performance on assistive technology stacks. The free AI voice generator options can serve as a starting point for accessibility-focused prototypes.
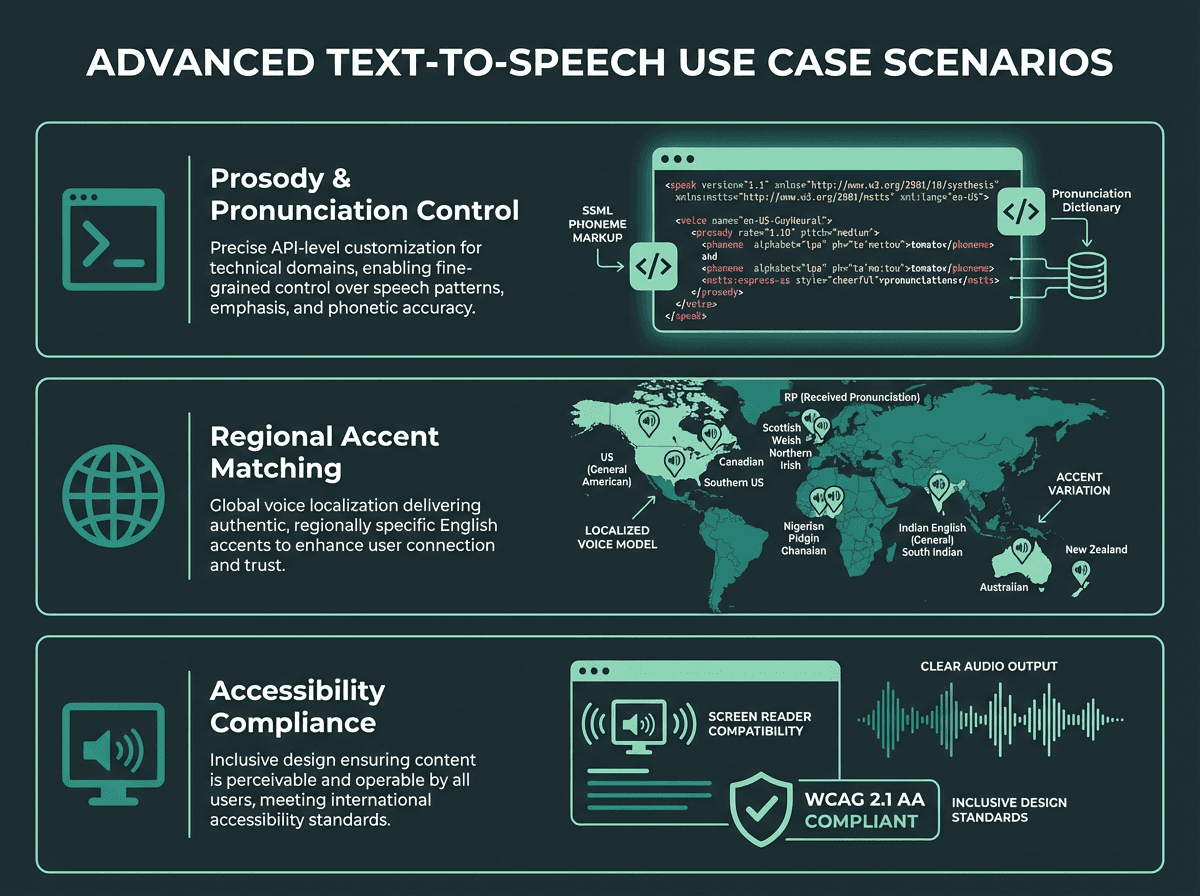
Advanced TTS scenarios: technical pronunciation, regional accent matching, and accessibility compliance
Key Takeaways
English TTS in 2026 is a mature, competitive market with meaningful quality differences between providers. The right choice depends entirely on your use case. For real-time voice agents and conversational applications, latency is the primary constraint and purpose-built streaming engines have a clear advantage. For long-form content production, emotional expressiveness and voice variety matter more. For teams exploring celebrity voice text-to-speech tools or custom branded voices, cloning capabilities become the deciding factor.
Before committing to any platform, validate these five things:
Test with your actual content, not the provider's curated demo sentences
Measure real streaming latency under your expected load, not quoted benchmarks
Confirm SSML support depth for pronunciation edge cases specific to your domain
Model the cost at your projected usage volume, not just the entry-level tier
Check voice consistency across long-form output, not just short clips
The Right Tool for the Problem
The core challenge with English text to speech is not finding a tool that sounds good in a demo. It is finding one that holds up under the specific demands of your product: the latency budget of your voice agent, the pronunciation quirks of your domain, the accent expectations of your users, and the cost structure of your scale. Generic TTS platforms optimize for the average use case, which works fine until your use case is not average.
Smallest.ai's Lightning TTS model is built specifically for the demanding end of that spectrum: real-time voice applications where latency, naturalness, and reliability are non-negotiable. If you are building a voice agent, an interactive IVR, or any product where the voice is the interface, the realistic text-to-speech engine is worth a serious look. The architecture is designed for streaming from the ground up, the voice library covers the range of English characters most products need, and the API is built for developers who require predictable, production-grade performance. Start with the free tier, test against your actual content, and find out exactly where the quality ceiling sits for your requirements.
What is the most natural-sounding English text to speech available in 2026?
How do I choose the right English voice for my product?
Can I use text to speech for accessibility compliance?
What is the difference between streaming and batch text to speech?
Is there a free English text to speech option for developers?

