Detect Voices with Diarization: A Guide to Speaker Diarization in Voice AI


Learn to detect voices with diarization in calls and meetings. A guide to the pipeline, DER scoring, overlap pitfalls, and where attribution boosts analytics.
Every sales call, support interaction, and team meeting produces messy audio where people trade turns, interrupt, and talk over one another. If you can’t reliably detect voices with diarization and assign each slice of speech to the right person, that recording is hard to search, summarize, or analyze. Speaker diarization is what turns a single mixed stream into something structured: speaker-labeled segments you can line up with a transcript. The job boils down to one deceptively simple question: “who spoke when?” Diarization is the process of partitioning an audio stream into homogeneous segments according to speaker identity.
This piece breaks down how diarization works, where it sits in a voice AI pipeline, why it fails, and what teams ship when accuracy matters. If you’re building a call analytics product, meeting intelligence, or a voice detection application, diarization is table stakes for anything involving more than one speaker. Smallest.ai’s Pulse STT API supports speaker diarization, word timestamps, and real-time transcription features, helping teams build speaker-attributed transcripts for multi-speaker voice workflows.
What Speaker Diarization Actually Does
Diarization isn’t transcription. It won’t turn speech into words. What it does is label time ranges with speaker identities (usually anonymous tags like “Speaker 1” or “Speaker A”) unless you’ve pre-enrolled a known speaker profile. Transcription answers what was said. Diarization answers who said it. Put them together and you get an attributed transcript that people can actually read, and systems can reliably analyze.
A diarization output usually looks like a timeline: [00:00:04 - 00:00:18] Speaker 1: “Let’s review the Q3 numbers.” [00:00:19 - 00:00:35] Speaker 2: “Sure, I have the report pulled up.” That simple structure is what makes downstream work possible, meeting summaries, compliance review, and even real-time fraud detection on financial services calls where attribution matters as much as the words.

Diarization adds speaker attribution to raw transcription, making multi-speaker audio structured and usable.
The Technical Pipeline: How Systems Detect Voices with Diarization
Modern diarization isn’t a monolithic model you drop in and forget. It’s a pipeline: several specialized components chained together, each responsible for a different failure mode. The arXiv review of diarization methods tracks how deep learning upgraded the individual parts, while the overall shape of the pipeline stayed largely the same.
The standard detect-voices diarization pipeline involves four stages:
Voice Activity Detection (VAD): Removes silence, background noise, and non-speech audio. Only speech is forwarded, which saves compute and cuts down false alarms.
Segmentation: Splits speech into short, acoustically consistent chunks, often 1–3 seconds. The aim is to create segments where a single speaker dominates, so the next stage has clean input.
Speaker Embedding Extraction: Runs each segment through a neural network (often producing x-vectors or d-vectors) to generate a fixed-length representation of the speaker’s vocal characteristics, an acoustic fingerprint encoded as numbers.
Clustering: Groups embeddings using methods like agglomerative hierarchical clustering or spectral clustering. Segments that land close together in vector space get the same speaker label. The number of clusters maps to the number of detected speakers.
The MDPI peer-reviewed study on speaker diarization methods calls out a detail that matters in production: clustering isn’t just “pick an algorithm and go.” The merge threshold you choose can swing results dramatically, especially when the number of speakers isn’t known ahead of time. Most real deployments need to estimate speaker count on the fly, and that’s one of the places diarization tends to wobble.
How Diarization Is Measured: Understanding DER
When you compare diarization systems (internal experiments or vendor claims) you’ll keep running into Diarization Error Rate (DER). It’s the default benchmark in research and common in product spec sheets. The number is only useful if you know what it’s counting.
DER is the sum of three error types, divided by the total reference speech duration. Those components are: false alarm (non-speech labeled as speech), missed speech (speech that the system fails to detect), and speaker confusion (speech assigned to the wrong speaker). In real recordings, speaker confusion is usually the one that dominates. A system that posts 5% DER on clean, two-speaker audio can easily jump to 20%+ DER on a noisy six-person conference call. Benchmarks don’t travel well; the audio conditions matter as much as the model. (MDPI Applied Sciences review on speaker diarization methods)

DER is the sum of three error types. Speaker confusion is typically the largest contributor in real-world audio.
Where Diarization Gets Hard: Overlapping Speech and Edge Cases
Most introductory explanations quietly assume polite turn-taking. Real conversations ignore that assumption. People cut in, backchannel, laugh, and overlap, sometimes for several seconds. Acoustically, that can be genuinely ambiguous, and the arXiv review flags overlapping speech as one of the most stubborn problems in diarization.
Classic clustering-based diarization assigns each time slice to exactly one speaker. When two people speak at once, the system has to choose, which means it will misattribute at least one voice. End-to-end neural diarization (EEND) models approach overlap differently: they can emit multi-label outputs per frame instead of forcing a single-speaker decision. The trade-off is practical, not theoretical. EEND-style models tend to demand more compute and more training data to get there.
Overlap isn’t the only thing that breaks a tidy pipeline. Production audio comes with low-quality microphones, channel noise, and speakers who sound similar enough to confuse embeddings. Short interjections under a second (“yeah,” “right,” “mm-hmm”) are easy to miss or mis-assign. And speaker count can swing wildly from file to file. If you’re building for call centers or meeting platforms, the only benchmark that really matters is the one you run on your own audio distribution.
Practical Applications: Where Diarization Delivers Real Value
Meeting intelligence is the obvious win. Popular meeting tools helped make speaker-attributed notes feel normal, producing transcripts that don’t read like an unbroken monologue. Without speaker labels, a one-hour meeting with five participants turns into a wall of text. With diarization, you can track who raised a concern, who agreed to an action item, and who dominated the airtime.
Call center analytics is where diarization starts paying rent. Once you can separate agent speech from customer speech, you can measure talk time, spot interruption patterns, run sentiment per speaker, and flag compliance issues with far fewer false positives. This is also where diarization connects directly to emotion detection in voice AI: you can’t interpret how someone is speaking until you’re confident about which person produced the signal.
Other production use cases where accurate speaker detection creates measurable value:
Legal and compliance recording: Court proceedings, depositions, and regulated financial calls need speaker-attributed records that hold up in audits.
Podcast and media production: Automated show notes, chapter markers, and searchable archives all rely on knowing which host or guest said what.
Healthcare documentation: Clinician-patient conversations often need speaker-role structure before they can be summarized or coded.
Education and e-learning: Lecture recordings become easier to navigate and search when instructor and student contributions are separated.
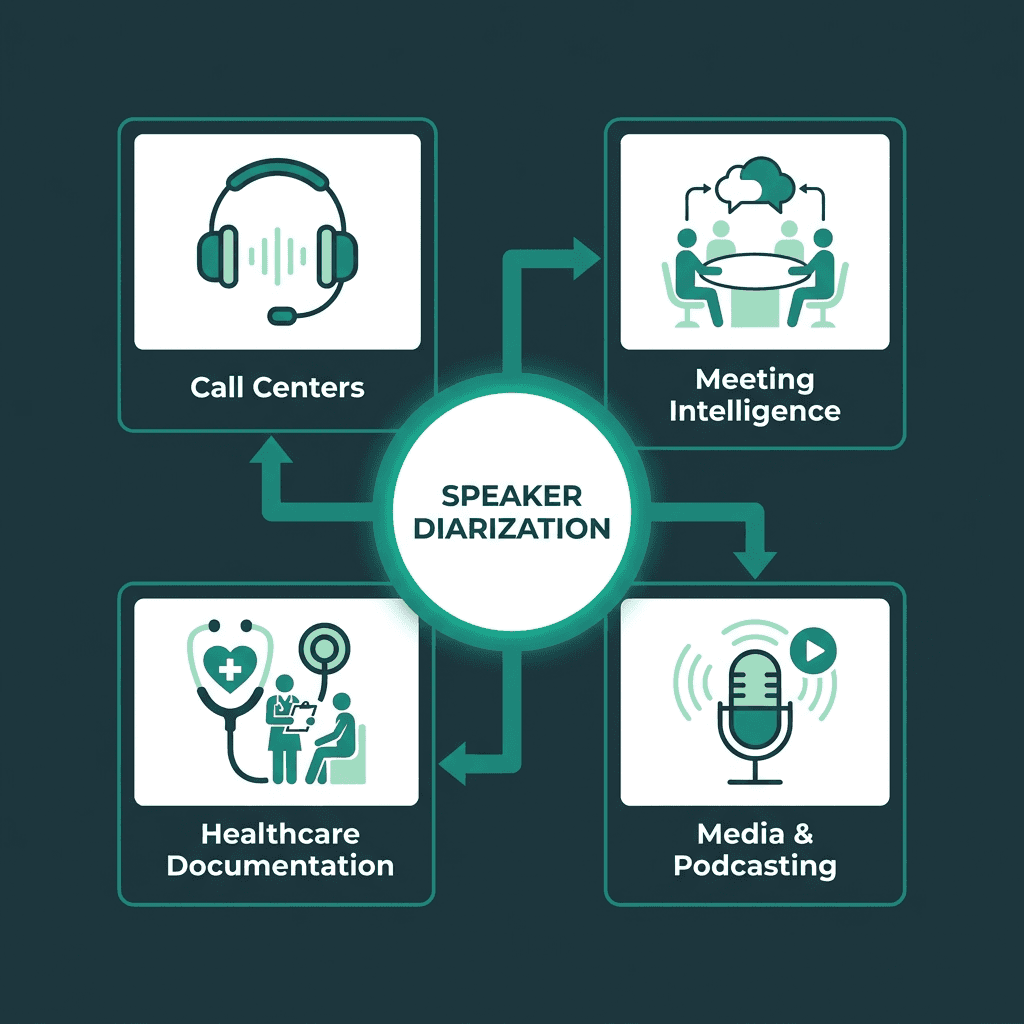
Speaker diarization powers speaker attribution across call centers, meetings, healthcare, and media.
Integrating Diarization Into a Voice AI Stack
In production, diarization almost never runs alone. It typically sits between audio ingestion and whatever analysis or automation comes next. A common pattern looks like this: capture audio; run VAD and diarization alongside automatic speech recognition (ASR); then merge the diarization speaker labels with ASR’s word-level timestamps to produce a final attributed transcript.
That merge step is where the sharp edges show up. ASR and diarization outputs don’t share the same time resolution, and they don’t always agree on boundaries. If a word straddles a speaker boundary, most systems assign it based on where most of the word’s duration lands, which can create small but annoying misattributions even when both components are “good” in isolation. If you’re building a pipeline for production, plan time for alignment logic and for the edge cases you only see after you ship.
Real-time use adds another constraint: latency. Batch diarization can look at the entire recording, which helps clustering and usually improves accuracy. Streaming diarization has to decide with partial context, which is harder. Many systems buffer a few seconds before committing to labels; that lag is fine for live transcription in many products, but it still needs to be designed into any latency-sensitive workflow.
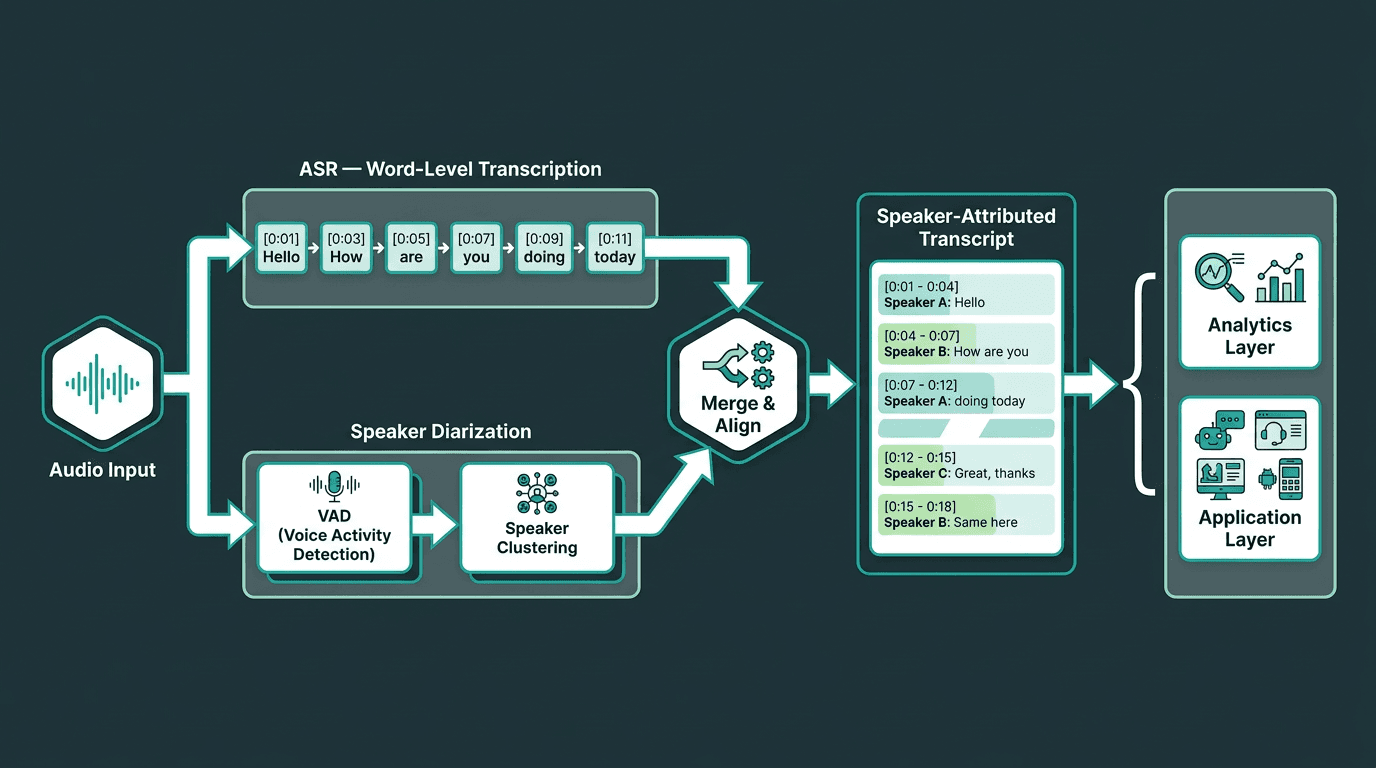
In production, diarization runs in parallel with ASR and merges at a final alignment step.
Speaker Diarization and Smallest AI: Closing the Loop on Voice Intelligence
Knowing “who spoke when” is the first layer of voice intelligence, not the end of the story. The value shows up when speaker attribution feeds decisions: summaries that preserve accountability, analytics that separate agent behavior from customer behavior, or workflows that trigger the right next step. Diarization fixes attribution. On its own, attribution is still just structured data waiting for a system to use it.
Speaker diarization solves one of the biggest problems in multi-speaker voice AI: knowing who said what, and when. Without speaker attribution, transcripts are harder to search, summarize, analyze, or use in downstream workflows.
Smallest.ai’s Pulse STT API supports real-time and pre-recorded transcription with diarization, word timestamps, and speaker-aware outputs, helping teams turn messy conversations into structured transcripts. For teams building voice agents or automated workflows, Pulse can work alongside Atoms for orchestration and Lightning for low-latency speech generation.
Key Takeaways
What to carry forward from this guide:
Speaker diarization answers “who spoke when?” by splitting audio into speaker-labeled segments. It’s separate from transcription, but most useful when paired with it.
The standard pipeline runs VAD, segmentation, speaker embedding extraction, and clustering. Errors introduced early tend to cascade downstream.
DER is the default evaluation metric. It combines false alarms, missed speech, and speaker confusion, and confusion is usually the biggest problem in real multi-speaker audio.
Overlapping speech is still the hardest challenge. End-to-end neural diarization handles overlap better than clustering-based systems, but it costs more compute.
Shipping diarization means aligning ASR word timestamps with diarization segment boundaries. Treat that alignment as a first-class part of the architecture.
High-value deployments show up in meeting intelligence, call center analytics, compliance recording, and healthcare documentation.
What is the difference between speaker diarization and speaker identification?
How many speakers can a diarization system handle accurately?
Can diarization work in real time, or is it only for recorded audio?
What audio quality is needed for reliable speaker detection?
How does speaker diarization fit into a broader voice AI workflow?