
Audio to text converter comparison for 2026 across latency, accuracy, languages, and pricing. See which of six tools fits voice agents, media, or offline use.
As audio content grows across meetings, support calls, podcasts, sales conversations, and voice AI products, transcription has moved from a simple utility to core infrastructure. Teams now need audio-to-text converters that are fast, accurate, multilingual, and easy to integrate. The decision point has moved on, too: it’s not “should we add transcription,” it’s “which audio to text converter will hold up under our actual audio and latency constraints?”
Below is a head-to-head look at six leading tools, scored on accuracy, latency, language support, pricing, and developer experience. These six tools were chosen because they represent the main buying paths in today’s speech-to-text market: real-time voice AI infrastructure, developer-first STT APIs, content intelligence platforms, open-source transcription, bundled voice AI suites, and ultra-low-latency streaming systems. Together, they give teams a practical view of the trade-offs between accuracy, speed, cost, language coverage, and production readiness.
How We Evaluated Each Audio to Text Converter
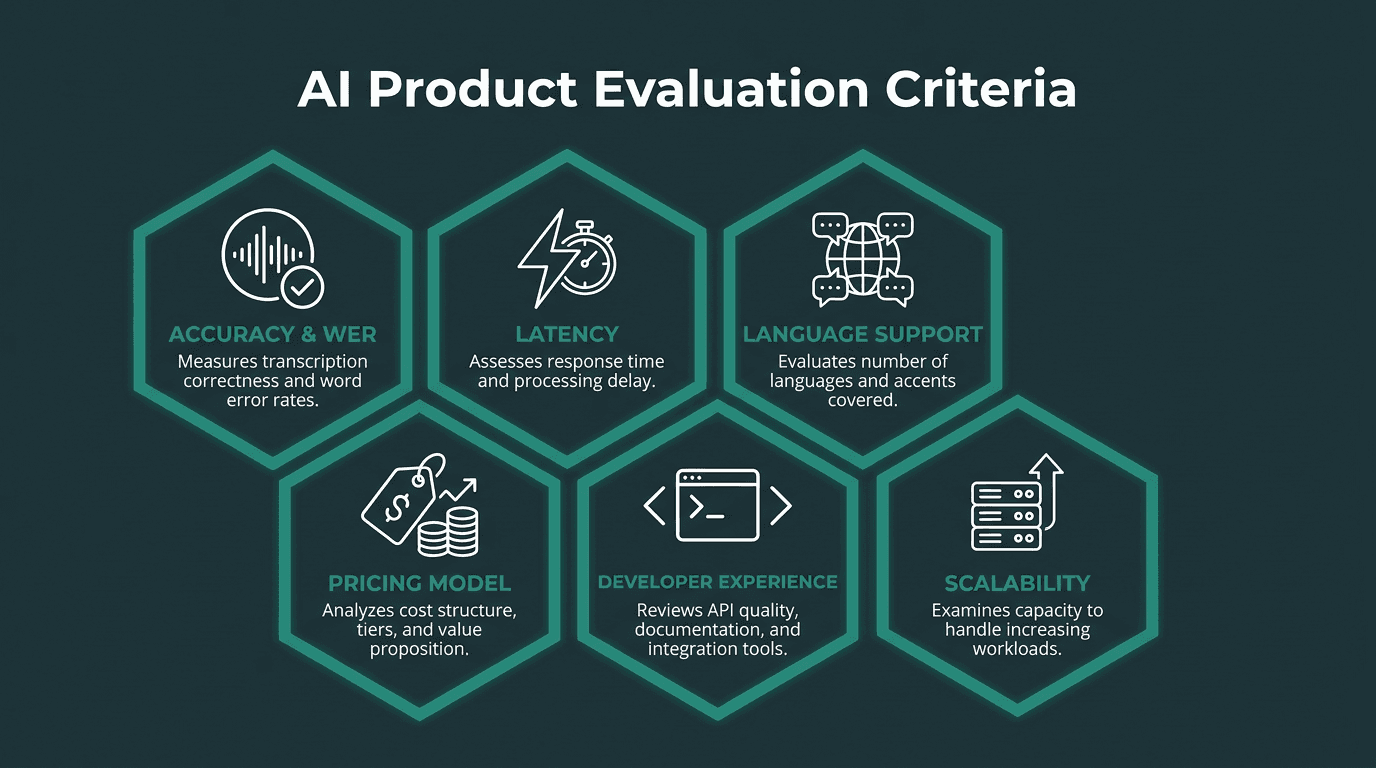
Six criteria used to evaluate every audio to text converter in this comparison.
Each tool is judged on the same six criteria, starting with accuracy. The standard metric is Word Error Rate (WER), which counts substitutions, insertions, and deletions against a reference transcript; lower WER means fewer mistakes. On clean audio, top-tier models often achieve WER below 5%, but that number can slide quickly. Academic ASR benchmarks and vendor research show that real-world conditions like background noise, accents, and telephony audio can significantly increase error rates compared to clean, lab-style datasets. Accuracy is only half the story, so the rest of the rubric covers streaming latency (time-to-first-token for live use), language and accent coverage, pricing clarity and cost at volume, API/SDK ergonomics, and how reliably the system scales for production traffic.
Smallest.ai Pulse: Best for Real-Time Voice Applications
Smallest.ai's Pulse STT is engineered for real-time voice pipelines rather than general-purpose transcription. That design choice shows up where it matters: streaming performance. Pulse is built for low-latency streaming transcription, a practical line between a voice agent that feels conversational and one that feels like it’s constantly catching up. It also plugs directly into Smallest.ai’s Atoms agent platform and Hydra speech-to-speech product, which makes it a clean fit when you’re building an end-to-end voice AI system instead of bolting transcription onto an otherwise unrelated stack.
Pulse’s other differentiator is how it behaves on messy, real-world audio. Accented speech and noisy telephony are explicitly in-scope, which is where many “great on studio audio” systems start to wobble. If your environment includes speech-to-text for multilingual contact centers, Pulse is built to handle those conditions at the model level, rather than asking you to paper over errors downstream.
Pulse STT strengths and limitations:
Strengths: Low-latency streaming transcription, positioned for accented and noisy audio environments, native integration with Smallest.ai's full voice AI stack
Strengths: usage-based pricing for high-volume real-time workloads
Limitation: Smaller ecosystem compared to Deepgram or AssemblyAI for third-party integrations
Limitation: Not the best fit for pure batch transcription of very large media archives
If you want the numbers, the real-time speech-to-text comparison breaks down latency, WER, and cost side by side.
Deepgram: Best for Developer Flexibility and Ecosystem Breadth
Deepgram’s pitch is straightforward: a developer-first speech-to-text platform with a lot of surface area. Nova-3 supports real-time and batch transcription, covers 50+ languages, and ships with practical features like speaker diarization, smart formatting, custom vocabulary, and topic detection. The SDK lineup (Python, Node, Go, and .NET) is solid, with documentation that’s actually built for integration work. If you’re threading transcription through a larger architecture, Deepgram’s connectors and webhook support can shave meaningful time off implementation.
For Nova-3, pricing varies by model and usage tier (see this Deepgram pricing breakdown). The compromise is scope: Deepgram is, deliberately, transcription-first. If you’re building a full voice stack (TTS, agents, speech-to-speech) you’ll still be assembling those pieces elsewhere. As a dedicated transcription layer, though, it’s a strong choice when you want flexibility and a mature ecosystem more than vertical integration.
AssemblyAI: Best for Content Intelligence and Post-Processing
Deepgram is strongest when you mostly care about transcription. AssemblyAI is optimized for what comes next. Its Audio Intelligence suite exposes sentiment analysis, auto-chapters, topic detection, content moderation, and PII redaction as first-class API parameters, so you’re not stitching together separate services just to get usable outputs. LeMUR extends that idea by letting developers run large language model queries directly against transcripts without standing up an extra pipeline. For media workflows, podcast platforms, legal tech, and compliance-heavy environments, those “after transcription” features can save real engineering effort.
Universal-3 Pro accuracy is competitive, and the async transcription API is comfortable with large files. AssemblyAI supports both streaming and async transcription workflows, with strong emphasis on post-processing and audio intelligence features. Pricing is usage-based and spelled out at AssemblyAI pricing. The catch is simple: if you only need fast, low-cost transcription and you won’t use the intelligence layer, AssemblyAI usually won’t be the lowest-cost option at scale.
OpenAI Whisper: Best for Offline and Open-Source Deployments
OpenAI’s Whisper remains the most broadly deployed open-source speech recognition model. It’s MIT-licensed, runs fully on-prem, and avoids the two things that often slow adoption inside regulated organizations: per-minute billing and data leaving your environment. For healthcare, legal, and government teams where data residency is non-negotiable, that’s not a nice-to-have; it’s the requirement. On clean audio, the large-v3 model delivers competitive WER across dozens of languages.
Whisper is more commonly used for batch and near-real-time transcription than ultra-low-latency conversational streaming. It processes audio in chunks, and that latency rules it out for live voice agents and other interactive experiences. At scale, you’re signing up for real GPU spend, and because it’s open-source, maintenance is on you. If you need managed infrastructure, SLAs, or support contracts, a hosted API tends to be the practical route. OpenAI does offer a hosted Whisper endpoint, but in production voice systems it’s more commonly treated as a baseline benchmark than the primary engine.
ElevenLabs: Best for Voice AI Platforms That Need Transcription as One Component
ElevenLabs is best known for text-to-speech and voice cloning, but its Scribe STT model holds up as a transcription engine, with broad multilingual support. The bigger appeal is consolidation. If you’re already using ElevenLabs for TTS or conversational AI, pulling STT from the same vendor reduces integration work and keeps billing simpler. Current plans and usage details are listed at ElevenLabs pricing.
Judged purely as an audio to text converter on transcription metrics, Scribe is competitive without clearly owning the category. If your main requirement is high-volume, low-cost transcription (and you don’t need TTS) Deepgram or Pulse will usually pencil out better. ElevenLabs is most useful for product teams shipping a cohesive voice experience where TTS, STT, and voice cloning need to behave like one system, not three loosely connected APIs.
Cartesia: Best for Ultra-Low Latency Streaming in Edge Environments
Cartesia is a specialist, and it doesn’t pretend otherwise. The main focus is ultra-low latency streaming inference for real-time and edge deployments. Sonic uses a state-space model architecture, which shows up in time-to-first-token for streaming audio. If you’re building something where tens of milliseconds matter (real-time translation, live captioning, interactive voice response) Cartesia’s design can produce a tangible latency advantage.
That specialization comes with narrower coverage. Language support and ecosystem integrations don’t match the breadth you get from Deepgram or AssemblyAI, and Cartesia isn’t aiming to be a general-purpose platform. For latency-critical applications on constrained infrastructure, it’s a serious candidate. If your workload is more conventional, starting with a broader, more established option is usually the faster path. Pricing is published at Cartesia pricing.
Tool | Real-Time Latency | Standout Feature | Pricing Model |
|---|---|---|---|
Smallest.ai Pulse | Low-latency streaming | Tight integration with a native voice AI stack | Usage-based |
Deepgram Nova-3 | Low-latency streaming | Mature SDKs plus custom vocabulary controls | Usage-based |
AssemblyAI Universal-3 Pro | Optimized for async | LeMUR queries, sentiment, and PII redaction | Usage-based |
OpenAI Whisper | Not for real-time | MIT-licensed, on-prem deployment | API |
ElevenLabs Scribe | Moderate | STT bundled with TTS and voice cloning | Subscription + usage |
Cartesia Ink-Whisper | Optimized for ultra-low-latency streaming | State-space model streaming architecture | Usage-based |
Which Audio to Text Converter Should You Choose?
Pick the converter that matches the failure mode you can’t afford. If you’re shipping real-time voice agents or running contact center audio where latency and accent robustness decide whether the system feels usable, Pulse STT is well suited for the job, especially if you already use, or plan to use, the rest of Smallest.ai’s stack. If you want a transcription layer with broad language coverage, strong tooling, and an ecosystem built for integration work, Deepgram is the common choice for teams prioritizing developer tooling. If you need transcripts plus downstream intelligence (summaries, compliance features, and content signals) AssemblyAI saves you from building that pipeline yourself. Whisper is the clear pick when data privacy and zero marginal cost matter and you have the infrastructure to self-host. ElevenLabs makes sense when STT is one component in a platform decision that already includes TTS and voice cloning. Cartesia is the outlier worth considering when ultra-low latency at the edge is the product requirement, not a nice bonus.
If you want a wider set of options, top speech-to-text transcription software picks for 2026 adds more tools and scenarios beyond this shortlist. For teams building interactive systems, the best transcription software for real-time voice systems in 2026 focuses specifically on the constraints that show up in production voice workloads.
Which audio to text converter is most accurate in 2026?
What is Word Error Rate (WER), and why should I care?
Can an audio to text converter run in real time for voice agents?
Which audio to text converter handles multiple languages and accents best?
Should I use open-source Whisper or a managed speech-to-text API?

