

Unlock real-time TTS with AI models and voice cloning. Optimize for low-latency deployment. Setup resources now. Enhance your speech services!
The way we interact with technology is changing, and real-time text-to-speech (TTS) AI services are at the center of this transformation. AI-powered TTS has advanced significantly, making speech generation more natural, expressive, and instantaneous than ever before.
From virtual assistants to AI-powered customer support, accessibility tools, and content creation, real-time TTS enables businesses and individuals to convert text into speech within milliseconds. This technology ensures smoother, human-like interactions while reducing operational costs and enhancing user experiences.
Unlike traditional text-to-speech systems, which often produce robotic voices with noticeable lag, AI-driven real-time TTS provides:
Low-latency voice generation (sub-100ms response times)
More natural and expressive speech (deep learning & NLP advancements)
Multilingual & customizable voices (voice cloning and training capabilities)
Scalable and efficient integration (API-based deployments for businesses)
This blog explores how AI enables real-time TTS, its applications, challenges, and how platforms like Smallest AI’s Waves provide an efficient, high-quality solution for real-time speech synthesis.
What is Real-Time Text-to-Speech?
Text-to-speech (TTS) is an AI-driven technology that converts written text into spoken audio. While traditional TTS systems focus on pre-recorded or batch-processing speech, real-time TTS is optimized for immediate response, making it ideal for conversational AI, customer interactions, and live applications.
How is Real-Time TTS Different from Standard TTS?
Feature | Standard TTS | Real-Time TTS |
|---|---|---|
Processing Speed | Can take seconds or minutes | Generates speech in milliseconds |
Voice Quality | Can sound robotic and static | More expressive and natural |
Use Cases | Audiobooks, pre-recorded messages | Live interactions, AI assistants, IVR systems |
Adaptability | Fixed pronunciation, limited emotion | Can adjust tone, pitch, and intonation dynamically |
Integration | Often standalone software | Works seamlessly with APIs and applications |
Key Components of Real-Time TTS
Neural Speech Synthesis: Uses deep learning models to mimic natural speech patterns, making voices more human-like.
Low-Latency Processing: Ensures instant voice generation, critical for live interactions like AI customer support.
Adaptive NLP (Natural Language Processing): Understands context, punctuation, and emotions to produce more expressive speech.
Voice Cloning & Customization: Allows businesses to create a consistent brand voice or replicate a specific speaker’s style.
Real-time TTS is not just about converting text into speech—it’s about enabling fluid, conversational interactions between AI and humans.
How AI Enhances Real-Time TTS
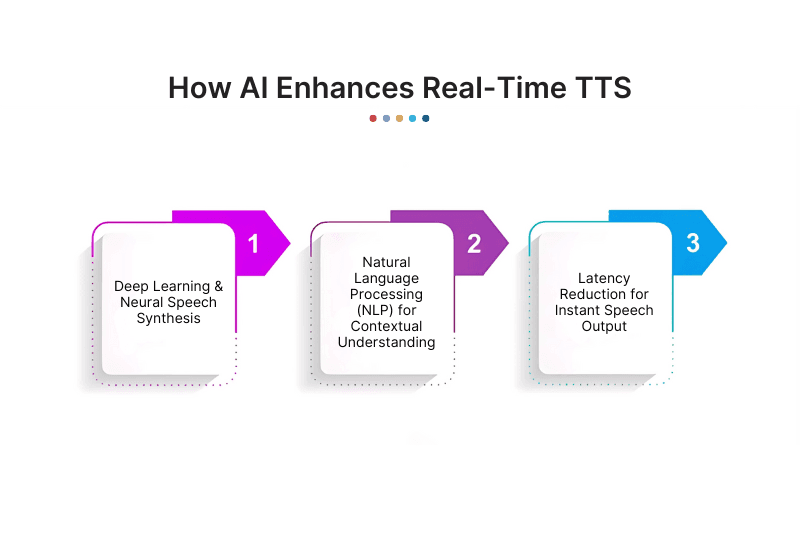
Artificial intelligence is the driving force behind modern real-time TTS, making it significantly better than past speech synthesis methods. Here’s how AI-powered models improve TTS:
1. Deep Learning & Neural Speech Synthesis
Early TTS engines relied on concatenative synthesis, where pre-recorded human voices were stitched together to create speech. However, this method lacked flexibility and often sounded unnatural.
AI-based TTS now uses neural speech synthesis, particularly transformer-based architectures like:
Tacotron 2 – Mimics natural speech patterns, improving pronunciation and fluidity.
WaveNet – Uses deep learning to generate realistic audio waveforms with greater expressiveness.
VITS (Variational Inference Text-to-Speech) – Enhances voice modulation and pronunciation accuracy in real time.
Result: Speech that sounds more human, with accurate stress, tone, and rhythm.
2. Natural Language Processing (NLP) for Contextual Understanding
AI doesn’t just read words—it understands them. Advanced NLP models improve:
Pronunciation accuracy – AI learns correct stress, emphasis, and phonetics for different words.
Sentence flow – Recognizes commas, pauses, and punctuation to create natural speech rhythm.
Contextual adaptation – Adjusts tone based on meaning, e.g., raising pitch in a question.
This ensures real-time TTS doesn’t just speak—it communicates effectively.
3. Latency Reduction for Instant Speech Output
One of the biggest challenges in real-time TTS is reducing response time while maintaining high quality. AI solves this with:
Parallel processing – AI splits text into smaller segments for faster synthesis.
Optimized deep learning models – AI reduces computational complexity, achieving sub-100ms latency.
Cloud-based speech synthesis – Eliminates local hardware limitations by running AI models on high-performance cloud servers.
Result: AI-powered TTS generates speech almost instantly, making it perfect for real-time applications like AI assistants, IVR systems, and interactive media.
Key Features of AI-Powered Real-Time TTS Services
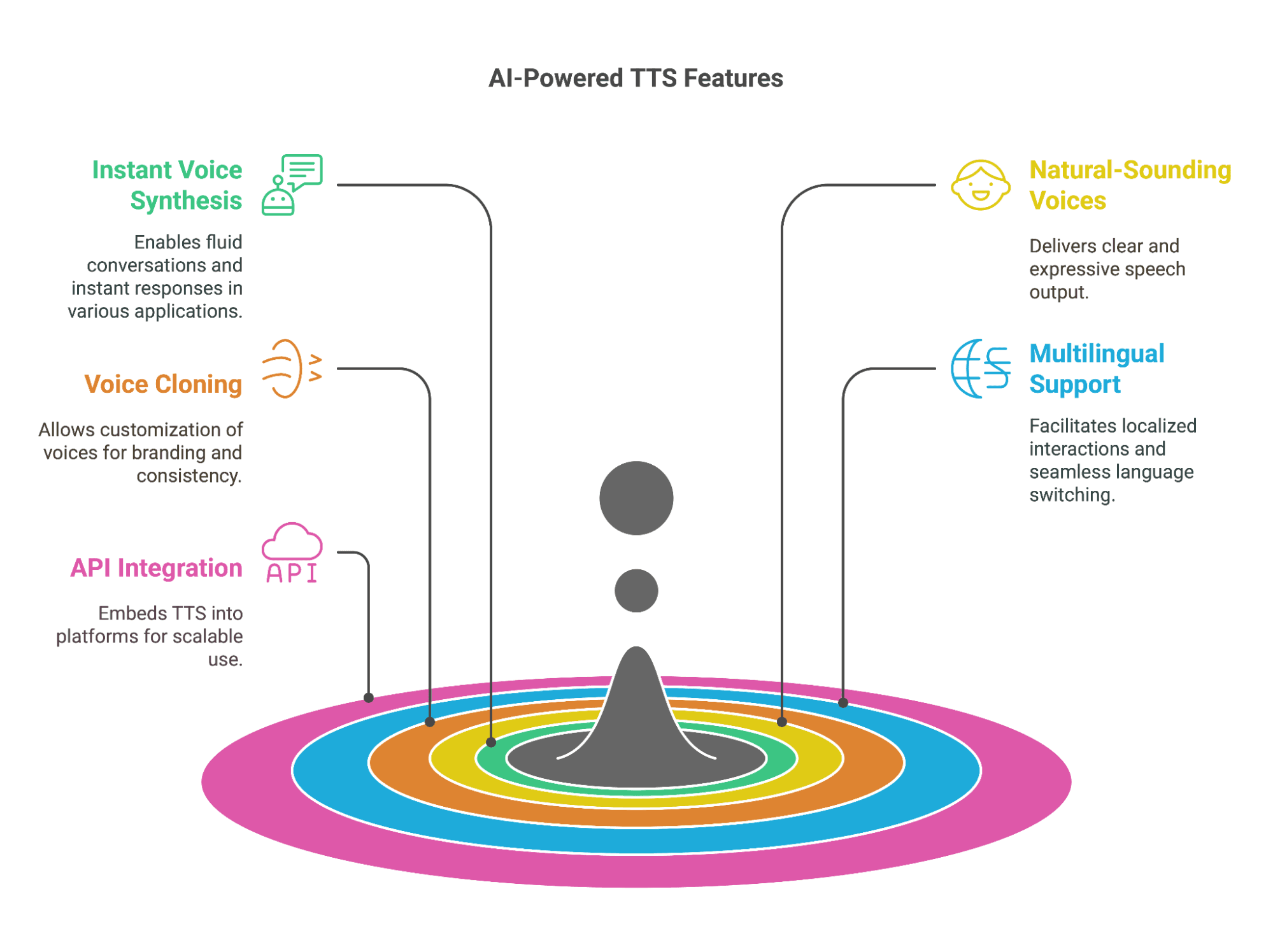
As AI continues to enhance real-time text-to-speech, modern TTS services come with several advanced features that make them faster, more natural, and more adaptive.
1. Instant Voice Synthesis with Low Latency
Real-time AI TTS systems are optimized to process and generate speech within milliseconds. This enables:
Fluid, uninterrupted conversations for AI chatbots and virtual assistants.
Instant voice responses for customer service and IVR systems.
Real-time voiceovers for live content creation, gaming, and interactive applications.
2. High-Quality, Natural-Sounding Voices
AI-powered TTS services use deep learning models to mimic human speech patterns, resulting in:
Clear, expressive, and natural speech output.
Adaptive tone and intonation that adjusts dynamically.
Emotionally responsive speech, improving human-like interactions.
3. Voice Cloning and Customization
Many real-time TTS services allow businesses to:
Create custom brand voices for virtual assistants and customer service agents.
Train AI to replicate a specific speaker’s voice for consistent narration.
Modify speech speed, pitch, and style to fit different use cases.
4. Multilingual and Accent Support
Advanced AI models support:
Multiple languages and dialects, enabling localized voice interactions.
Accent variations, ensuring speech synthesis sounds native to different regions.
Seamless switching between languages for real-time translation applications.
5. API Integration for Seamless Deployment
Real-time AI TTS services provide:
API-based integration, allowing businesses to embed AI-powered speech into apps, websites, and customer service platforms.
Scalability, ensuring TTS solutions work efficiently across small and large deployments.
Cloud-based solutions, reducing the need for on-premise computing power.
Applications of Real-Time AI TTS Services
AI-powered real-time text-to-speech (TTS) is transforming industries by enabling instant, natural-sounding voice generation. Businesses, educators, and content creators rely on low-latency, high-quality speech synthesis to enhance customer engagement, accessibility, and content production.
1. Customer Support & Virtual Assistants
Businesses are increasingly integrating AI-driven TTS into customer service systems to improve response efficiency and reduce operational costs.
AI Chatbots & IVR Systems: AI-powered voice bots handle customer inquiries, process requests, and provide information without human intervention.
Call Centers & Automated Support: Real-time TTS enables automated voice assistants to respond to customers naturally, reducing wait times.
E-commerce & Order Tracking: Many companies use AI voice support to assist customers with tracking orders, modifying bookings, or answering FAQs.
2. Accessibility Tools for the Visually Impaired
Text-to-speech technology is critical in making digital content accessible to individuals with visual impairments or reading disabilities.
Screen Readers & Assistive Technology: AI TTS converts on-screen text into spoken audio, allowing visually impaired users to navigate apps, websites, and documents.
Live Voice Descriptions: AI-powered TTS provides real-time descriptions of images, graphs, or charts, making multimedia content more inclusive.
Dyslexia Support: TTS tools help users with learning difficulties by reading out textbooks, articles, and web pages.
3. Live Content Creation – Streaming, Audiobooks, and Podcasts
Real-time AI TTS has streamlined content production across various media industries by enabling:
Audiobooks & Podcast Narration: AI-generated voices now deliver lifelike narrations for books, articles, and news summaries.
Video Voiceovers: Content creators use AI TTS for quick, professional-sounding narration in explainer videos, social media content, and educational tutorials.
Live Streaming & Interactive Media: AI TTS enables dynamic speech synthesis in gaming streams, virtual events, and live presentations.
4. Gaming & Interactive Media
AI-powered real-time voice synthesis is playing a significant role in the gaming industry by enhancing:
AI-Generated NPC Dialogues: Games now use AI to create realistic, context-aware NPC speech instead of relying on pre-recorded lines.
Voice-Controlled Gameplay: Players interact with AI-driven voice assistants in RPGs, VR simulations, and multiplayer environments.
Storytelling & Adaptive Narration: AI-generated voices adjust tone, pitch, and delivery to match the game’s atmosphere dynamically.
5. Multilingual Voice Translation & Global Communication
AI TTS is bridging language barriers by enabling instant voice translation for businesses, travelers, and educators.
Real-Time Translation Services: AI-powered tools convert text from one language into spoken speech in another, making communication seamless.
Multilingual AI Assistants: Businesses deploy TTS chatbots that can speak and understand multiple languages for customer support.
E-learning & Global Training: AI TTS helps international learners by translating educational content into different languages.
Challenges in Real-Time TTS and How AI Overcomes Them
Despite its advancements, real-time text-to-speech faces challenges that AI technology continuously works to resolve.
1. Latency Issues
Early TTS systems struggled with slow response times, causing delays in AI interactions. AI now optimizes speech synthesis with:
Faster deep learning models (e.g., Tacotron 2, WaveNet).
Cloud-based processing to offload computing demands.
Parallel speech generation to handle multiple requests simultaneously.
2. Voice Quality & Expression Limitations
Traditional TTS often sounded robotic and unnatural. AI now improves voice quality by:
Training on massive voice datasets to mimic human-like speech.
Integrating contextual NLP for adaptive pronunciation and tone changes.
Enhancing speech modulation to express emotions naturally.
3. Customization & Personalization Constraints
Businesses need distinct voices for branding. AI-driven solutions now offer:
Voice cloning capabilities, replicating a person’s voice from small samples.
Dynamic speech adjustments for tone, pitch, and pacing.
Fine-tuning features to match specific use cases.
4. Scalability Challenges
Handling millions of voice requests can slow down performance. AI resolves this by:
Optimizing cloud-based deployment for high-performance TTS.
Distributed computing models to process multiple requests simultaneously.
Edge computing solutions for localized, real-time speech synthesis.
Smallest AI – The Best Real-Time TTS Solution
While many open-source and commercial TTS solutions offer real-time speech generation, they often face challenges with voice quality, latency, and ease of integration. Smallest AI’s Waves stands out by delivering:
✔ Studio-quality, ultra-realistic voices that sound human-like and expressive.
✔ Lightning-fast, real-time processing with sub-100ms latency.
✔ Seamless API integration for developers, making it easy to deploy at scale.
Why Choose Smallest AI’s Waves for Real-Time TTS?
Smallest AI’s Waves platform provides the most accurate, responsive, and natural-sounding speech synthesis for businesses, content creators, and developers. Here’s why it’s the best real-time TTS solution:
1. Instant Speech Generation with Near-Zero Latency
Unlike traditional TTS models that experience delays, Waves is built for instant responses, making it ideal for:
Customer service bots that need to sound natural and human-like.
Live streaming and gaming voiceovers without lag.
Voice assistants that respond in real-time to user queries.
2. Hyper-Realistic, Natural-Sounding Voices
Waves uses advanced deep learning models trained on massive voice datasets to produce speech that:
Sounds indistinguishable from human speech.
Adapts tone and emotion naturally.
Maintains clarity, pronunciation, and rhythm even for long-form content.
3. Multi-Language & Multi-Accent Support
For businesses catering to global audiences, Waves provides:
Support for over 30 languages and 100+ accents, ensuring seamless multilingual conversations.
Accurate pronunciation and contextual adaptation for regional dialects.
Voice-switching capabilities, allowing instant translation of spoken content.
4. Advanced Voice Cloning & Customization
Smallest AI allows businesses to create and personalize AI voices that match their brand’s identity:
Voice cloning with as little as 5 seconds of audio input.
Emotion-based speech synthesis for engaging, expressive interactions.
Custom pitch, speed, and pronunciation tuning to fit specific brand requirements.
5. Enterprise-Grade Scalability & API Integration
For businesses, developers, and large-scale applications, Waves is:
Easily deployable via API, integrating with customer service platforms, e-learning systems, and live applications.
Cloud-based and scalable, handling thousands of real-time speech requests without performance drops.
Highly customizable, allowing developers to fine-tune voices for their unique needs.
6. Cost-Effective Pricing for All Users
Unlike premium TTS providers that charge high licensing fees, Waves by Smallest AI offers:
A free plan for small-scale use.
Affordable premium plans with full-featured customization.
Flexible pricing based on usage, making it cost-effective for businesses of all sizes.
Conclusion
AI-powered real-time text-to-speech (TTS) technology is no longer a luxury—it’s a game-changer for businesses, content creators, and developers. From instant customer support to seamless multilingual conversations, AI TTS enhances engagement, boosts efficiency, and drives automation like never before.
However, not all TTS solutions provide low-latency, natural-sounding, scalable voice synthesis—which is where Smallest AI’s Waves excels.
✔ Hyper-realistic speech output.
✔ Sub-100ms real-time response.
✔ Voice cloning and advanced customization.
✔ API-first design for seamless integration.
✔ Affordable pricing for all users.
If you’re looking for a high-performance AI voice solution that adapts to your needs, try Smallest AI’s Waves today and experience the future of real-time TTS.
🚀 Ready to transform your workflow?
👉 Get started with Smallest AI Waves now!

