PDF to Podcast Generator: A No-Code n8n Workflow for Multilingual AI Audio


Smallest AI's n8n template converts PDFs into polished podcasts in 60 seconds, with native Indian language TTS, two-host dialogue, and voice cloning built in.
NotebookLM made document-to-podcast a mainstream pattern, drop in a paper, get back a polished two-host briefing. But try generating one in Hindi, Tamil, or Bengali and the experience falls apart. Voices don't sound native, prosody is off, and code-mixed text breaks the model.
We built for that gap. Today we're shipping the first official Smallest AI template on the n8n marketplace: a complete PDF-to-podcast workflow with native support for nine Indian languages — Hindi, Tamil, Telugu, Kannada, Malayalam, Bengali, Marathi, Gujarati, and Punjabi — alongside English and 10+ others.
Upload a PDF, get a polished podcast in your inbox. No code, no FFmpeg, no audio infrastructure to manage.
1. Try the template on n8n
2. Copy Podcast Generator Workflow JSON
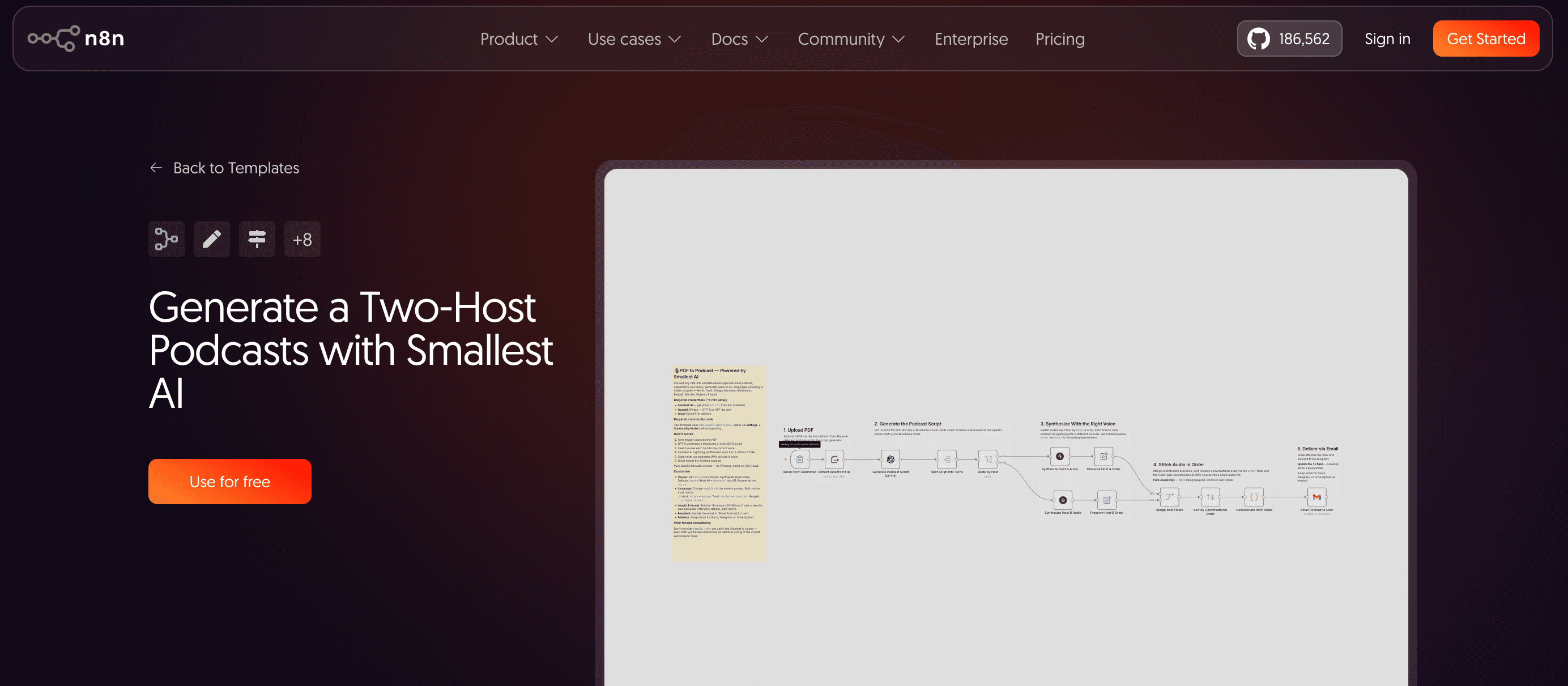
What the workflow produces
Upload a PDF through a form. A few seconds later, a finished WAV file lands in your inbox. That is the full user experience from the outside.
Inside the workflow, seven steps happen in sequence — broken into five logical sections you can see in the n8n editor.
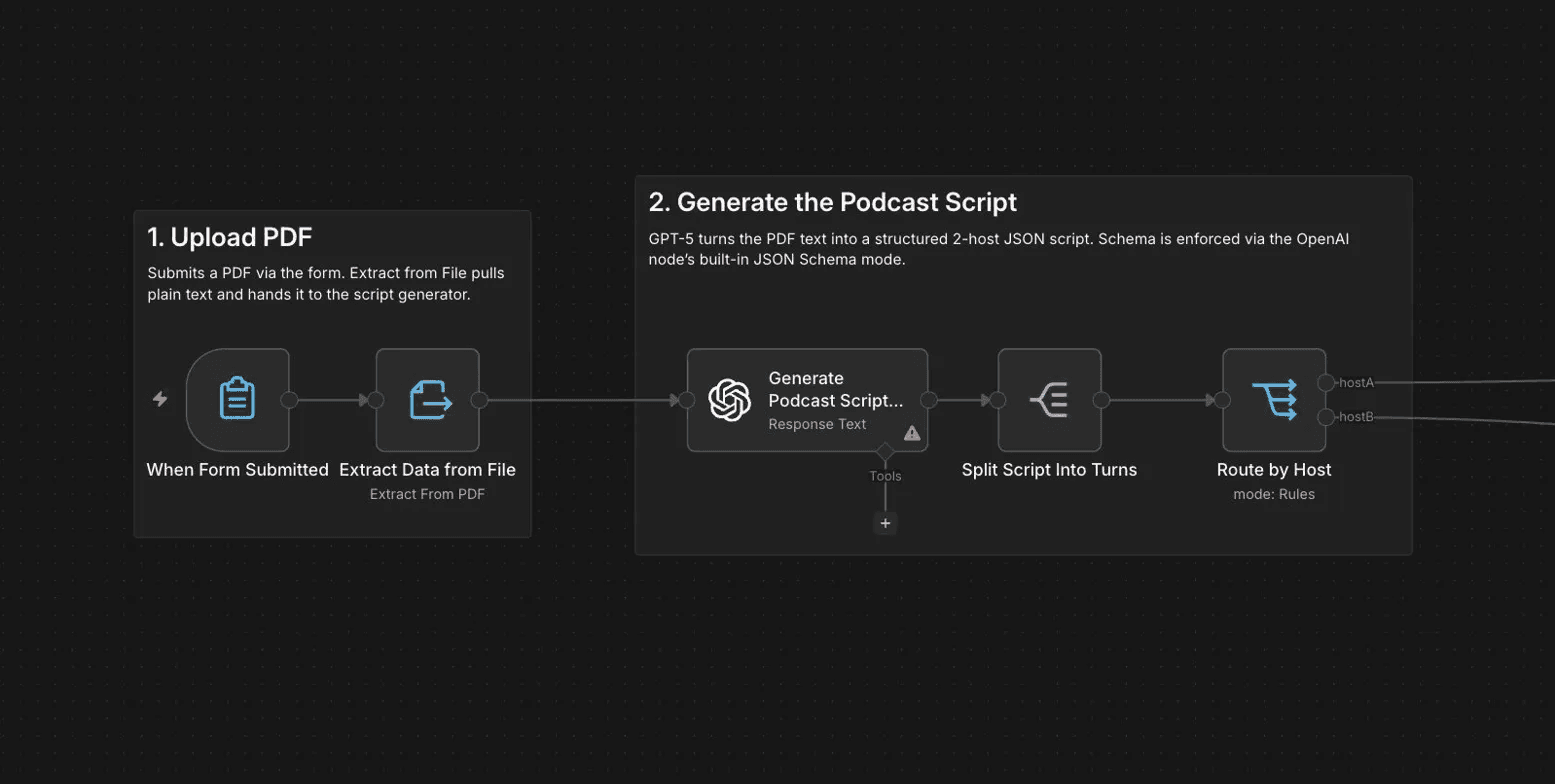
A form trigger accepts the PDF upload, and text extraction pulls the document content into plain text. GPT-5 then generates a structured two-host script in JSON, with each turn tagged by speaker and order. The schema is enforced via the OpenAI node's built-in JSON Schema mode, which guarantees downstream nodes always receive parseable, well-formed output. A Split Out node breaks the script into individual turns, and a Switch node routes each one to the correct voice synthesizer based on the host tag.
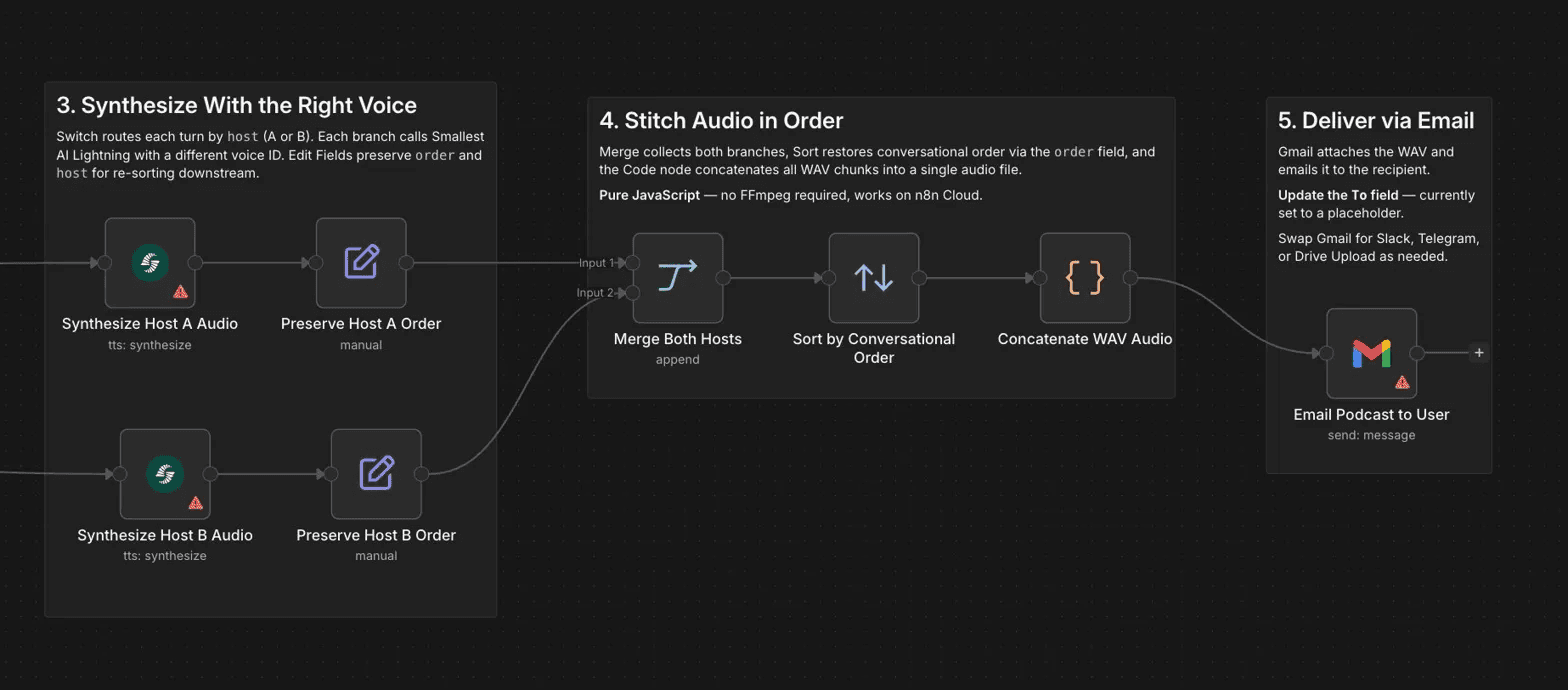
Smallest AI's Lightning V3.1 model generates audio for each turn, with sub-100ms time to first byte on realistic turn lengths. A Code node stitches all audio chunks into a single WAV file in conversational order using pure JavaScript, with no FFmpeg dependency — which means it runs on n8n Cloud without any additional infrastructure. Gmail delivers the finished file as an email attachment.
A five-page PDF produces a four-minute podcast in roughly 60 seconds end to end.
Every component is swappable. Replace Gmail with Slack or Telegram for delivery. Replace the form trigger with a webhook to automate ingestion from a CMS. Replace GPT-5 with GPT-4o-mini to reduce cost. Replace the default voices with a cloned voice to produce branded audio content. The n8n template is the scaffold, not the constraint.
What you can build with this pattern
The template is intentionally minimal. The underlying pattern handles significantly more.
Research and knowledge work. Academic papers, technical reports, and long-form analysis are exactly the kind of content that benefits from audio summarisation. Generate a podcast summary of a paper before deciding whether to read it in full.
Marketing and content distribution. Whitepapers and thought leadership content converted to audio blog or podcast newsletter format reach audiences who prefer listening. The multilingual voiceover capability means the same content can be distributed across language communities without re-recording.
Internal communications. Long strategy memos and update documents converted to audio for executive consumption. A founder-voiced podcast newsletter using voice cloning, delivered weekly without any recording session.
Education. Lecture notes and reading materials converted to audio in students' native languages. For ed-tech platforms serving Indian markets, the ability to generate Tamil tts, Telugu tts, and Kannada tts audio at the same quality as English output is a meaningful capability gap to close.
Accessibility. Document to podcast conversion for users who cannot easily read on screen, in the language they are most comfortable listening in.
Customer education. Product documentation converted to walkthrough audio, automatically updated when the source document changes. A webhook trigger can make this fully automatic.
Why two hosts change how people listen
A single narrator reading a document aloud is an audiobook. Two hosts discussing its contents is a podcast. The difference is not cosmetic.
The two-host format creates conversational rhythm through questions, reactions, and moments of push and pull between speakers. The listener's cognitive load drops because the format itself does some of the interpretive work, signalling which parts are contested, which are established fact, and which the hosts think matter most.
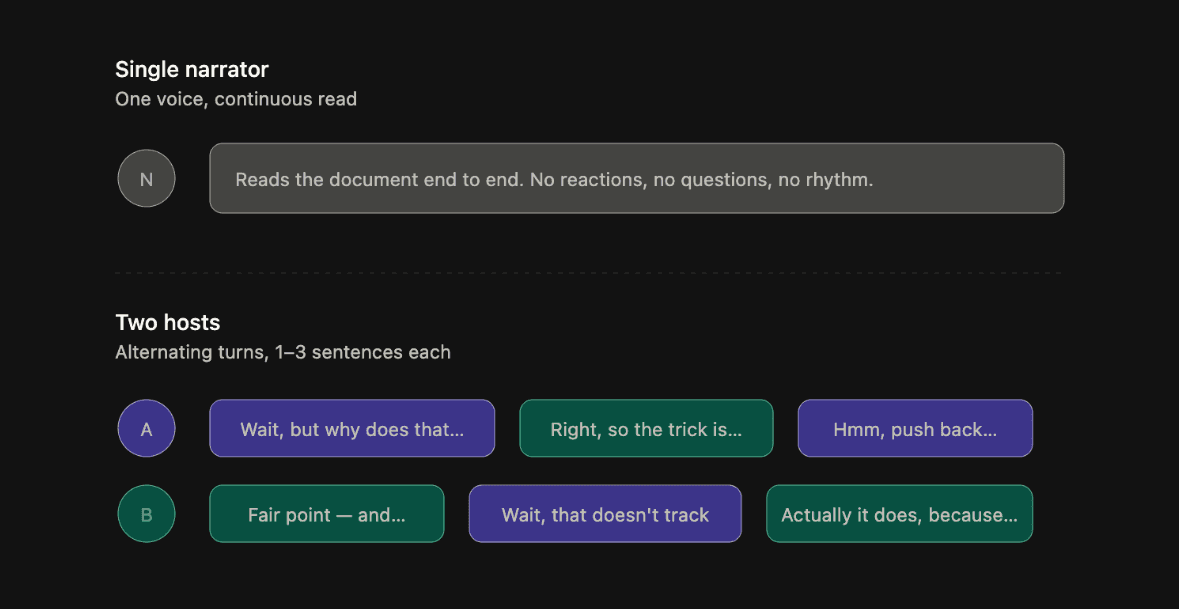
The system prompt that drives the script generation enforces this deliberately. GPT-5 is instructed to keep average turn length to one to three sentences, use connective phrases like "right, so," "wait, but," and "hmm, push back on that," include moments of interruption and qualification, and avoid anything that reads like alternating monologues. The goal is dialogue that sounds like two well-prepared people working through a document together, not a text to speech model taking turns with itself.
The two default hosts are Avery, a female American English voice, and Devansh, a male Indian English voice. The combination was chosen for cross-cultural balance, but both are fully customisable.
The Indian language gap this solves
The document to podcast pattern has become genuinely useful. Researchers use it to absorb papers during commutes. Marketers convert whitepapers into shareable audio. Educators produce accessible formats for students with different learning needs. Founders generate audio briefings from dense internal memos.
But the tools that power these workflows treat Indian languages as a translation problem rather than a synthesis problem. They take a model trained on English speech, run text through a transliteration or translation layer, and generate audio that sounds technically correct but perceptually foreign to native speakers. The intonation patterns are off. The stress falls in the wrong places. A Hindi listener notices immediately.
Smallest AI's Lightning V3.1 model was trained with native support for Indian languages rather than on top of an English model. The phonetic structure, prosody, and natural cadence of each language are handled directly. When the model synthesises a Tamil sentence, it sounds like a Tamil speaker, not a transliteration of one.
The workflow supports nine Indian languages natively: Hindi, Tamil, Telugu, Kannada, Malayalam, Bengali, Marathi, Gujarati, and Punjabi, alongside English and more than ten other global languages.
Switching the podcast to a different language is two changes. Edit the system prompt to specify the target language. Update both voice IDs to a matching pair from Smallest AI's voice library.
Suggested pairs for common use cases:
Hindi:
arjunandaanyaTamil:
arvindandniharikaBengali:
arnabandishitaTelugu, Kannada, Malayalam, Marathi, Gujarati, Punjabi: see the full voice catalog
Both voices in any pair must support the same language. The catalog lists language coverage per voice.
Voice cloning and branded audio
Beyond the built-in voice library, the workflow supports instant voice cloning. Upload a ten-second audio sample of any speaker through the Smallest AI dashboard, and the platform generates a voice ID you can use as either host in the podcast.
This unlocks a category of use cases that generic text to podcast tools cannot reach. A founder who ships a weekly audio update in their own voice. A brand that produces customer education content with a recognisable spokesperson. An educator who converts their own lecture notes into audio using their actual voice.
Voice cloning through the API requires no training pipeline or fine-tuning. The voice cloning api accepts a short reference clip and returns a voice ID ready to use in synthesis requests. For teams building at scale, real time voice cloning means audio content can be generated on demand without pre-registering speakers in advance.
Why this runs on n8n
n8n sits at an interesting point in the workflow automation landscape. It offers more control than Zapier, a visual interface that makes the architecture of a workflow immediately readable, and an active template marketplace where useful patterns get discovered, forked, and adapted by a technical audience.
For a workflow like pdf to podcast ai, n8n is the right platform for several reasons. The visual editor makes it trivially easy to inspect what each step does and swap out components. The template marketplace creates distribution for the pattern itself, not just the tool. And n8n Cloud handles execution, so users do not need to deploy or maintain anything.
The workflow uses the official n8n-nodes-smallestai community node, which exposes Smallest AI's full API as native n8n building blocks: text to speech, speech to text, and voice cloning. Once installed from the Community Nodes settings panel, it behaves identically to any built-in n8n integration.
How it compares to NotebookLM
NotebookLM's audio overview feature is the obvious point of comparison. It is polished, easy to use, and produces genuinely good English-language podcasts. The experience of uploading a document and getting back a well-structured two-host conversation is real and useful.
The limitations are also real. No native Indian language support. No voice cloning. No ability to customise the script structure or delivery style. No control over which voices are used. No option to integrate the output into a broader automation workflow, such as triggering podcast generation from a CMS update or a Slack message.
This n8n template is not a replacement for NotebookLM. It is a notebooklm alternative for the use cases NotebookLM does not cover: multilingual audio content, branded voices, automated pipelines, and workflows that need to fit inside a larger production system.
Setup
Getting the template running takes about five minutes.
Install the n8n-nodes-smallestai community node from Settings > Community Nodes in your n8n instance. Get a Smallest AI API key from the dashboard. The free tier is sufficient for testing. Connect your OpenAI account, either GPT-5 or GPT-4o-mini both work. Connect Gmail OAuth2 for delivery, or swap in your preferred output channel. Open the template, add your credentials, and run.
Sticky notes inside the workflow walk through each section, including how to swap voice IDs, change the language, adjust podcast length, and change the delivery channel.
What is coming next
This is the first Smallest AI template on the n8n marketplace. The roadmap includes a multilingual customer support voicebot with emotion-aware routing, a compliance call transcription workflow with PII redaction, a diarised meeting notes pipeline, voice-cloned newsletter generation, and a nine-language IVR system via Twilio.
Each one targets a workflow gap that current marketplace templates either do not address or do not address well for non-English use cases.
If you are building something in this space, or if you have a workflow you would like to see templated, the team would like to hear about it. The more we understand what is actually being built for Indian-language voice products, the better the next templates will be.
In the meantime, the pdf to podcast template is live. Upload something and see what it makes.

