Deepgram vs Smallest AI: Real-World STT Latency Benchmarks and API Speed Test for Voice Applications

Compare Deepgram and Smallest AI for STT latency, pricing, accuracy, and voice agent API fit. See which stack works better for real-time voice apps.
When building a voice agent, speech-to-text (STT) latency is a critical factor. The "Deepgram vs Smallest AI API speed test" question arises because both vendors offer real-time transcription but approach it with different architectures.
To feel natural, a conversational voice agent (STT + LLM + TTS) should stay under an 800ms round-trip, a threshold supported by analysis from voice AI specialists. This leaves approximately 150-300ms for the STT layer. If this budget is exceeded, users perceive a noticeable lag. The following sections compare latency, accuracy, pricing, and developer experience to determine what fits best for production voice applications.
What We Are Comparing and Why It Matters
This evaluation focuses on six key areas: streaming latency (median and tail), word error rate (WER), pricing model, developer API experience, scalability under concurrent load, and ecosystem fit within a voice agent pipeline. Latency and WER are the most important metrics, as they directly impact whether a voice product feels responsive or stutters. Pricing becomes the next major consideration when moving from a prototype to a production environment. The other criteria distinguish a clean demo from a system that can handle real-world traffic.
For a broader perspective on how these metrics interact across the full stack, the article on designing voice assistants explains how to allocate latency budgets across STT, LLM, and TTS to maintain conversational flow.
Smallest AI Pulse: Designed for the Voice Agent Pipeline
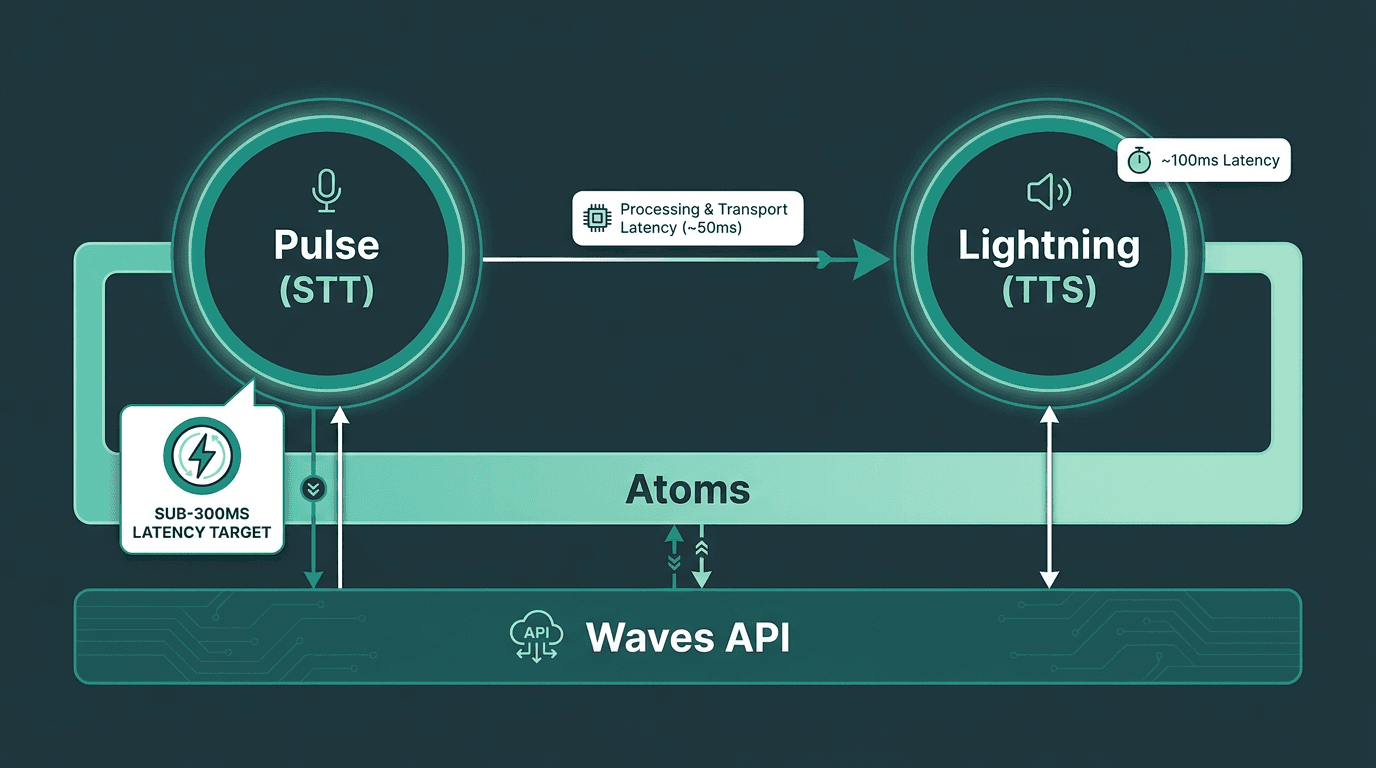
Smallest AI's Pulse STT sits inside a fully integrated voice pipeline alongside Lightning TTS and the Atoms agent platform.
Smallest AI’s Pulse is positioned as part of a full voice agent stack, not just a standalone transcription endpoint. It integrates with Lightning (text-to-speech) and Atoms (an agent platform). This stack is accessible to developers through the Waves API. This integrated approach is designed to optimize latency in practice.
When Pulse and Lightning operate in the same infrastructure, the data handoff from STT to TTS avoids traversing the public internet. In a multi-vendor setup, each of these network hops can add a variable amount of latency, influenced by factors like geographic distance and network congestion. By removing these hops, Smallest AI's architecture aims to stay within the 500-800ms round-trip window suggested for natural conversation. For real-time applications, these saved milliseconds are valuable.
Pulse is specifically tuned for conversational audio, which includes interruptions, filler words, and overlapping speech, common in voice agent interactions. The focus is on providing steady tail latency, as this is often where production systems encounter issues first. For more on this, see the guide on The Latency Problem.
Pulse pricing is usage-based through the Waves API, with current details available on the smallest.ai pricing page. Teams that adopt the full Smallest AI stack (Pulse and Lightning via Atoms) may find the bundled pricing more cost-efficient than assembling a comparable STT and TTS solution from separate vendors.
Deepgram Nova-3: Speed and Accuracy
Deepgram has a long history in real-time transcription infrastructure, and its models reflect this experience. The company's documentation indicates its streaming models are optimized to return results in under 300ms under standard conditions. This performance is crucial for applications requiring immediate feedback.
However, performance under load is a more complex issue. While median latency can be low, tail latency (such as the 95th percentile, or P95) can increase significantly during periods of high concurrency. For applications with hundreds of simultaneous sessions, a single long delay can disrupt the user's conversational flow.
Deepgram’s pricing is usage-based, billed per second. The Pay-As-You-Go plan for Nova-3 streaming is a common starting point, with volume discounts available for enterprise-level commitments. For the latest details, it is best to consult Deepgram's current pricing information on their website. The developer platform is mature, offering features like WebSocket streaming, speaker diarization, custom vocabulary, and language detection. For teams already integrated with Deepgram, this established ecosystem is a significant benefit.
Deepgram Nova-3 at a glance:
Median streaming latency: Optimized for sub-300ms
WER: Varies by dataset and conditions
P95 latency under load: Can increase with high concurrency
Streaming price: Pay-as-you-go, per-second billing
Strong ecosystem: Diarization, custom vocab, 30+ languages
No native TTS or voice agent layer bundled
Where Deepgram Excels and Its Limitations
While Deepgram is a mature, dedicated transcription service for use cases like transcribing recorded calls and media indexing, its focus is limited to standalone STT. It offers low sub-300ms latency, robust developer documentation, and maintained SDKs, but these are standard features for a dedicated transcription API and are not optimized for the complex requirements of an end-to-end voice agent pipeline.
The main limitation appears when the objective is an end-to-end voice agent. Deepgram does not offer a native LLM, TTS, or agent orchestration platform, which means integrating at least two additional vendors. Each service boundary introduces network hops and potential variance. This can lead to audible pauses for users, particularly under high concurrent load.
Where Smallest AI Fits and What to Consider
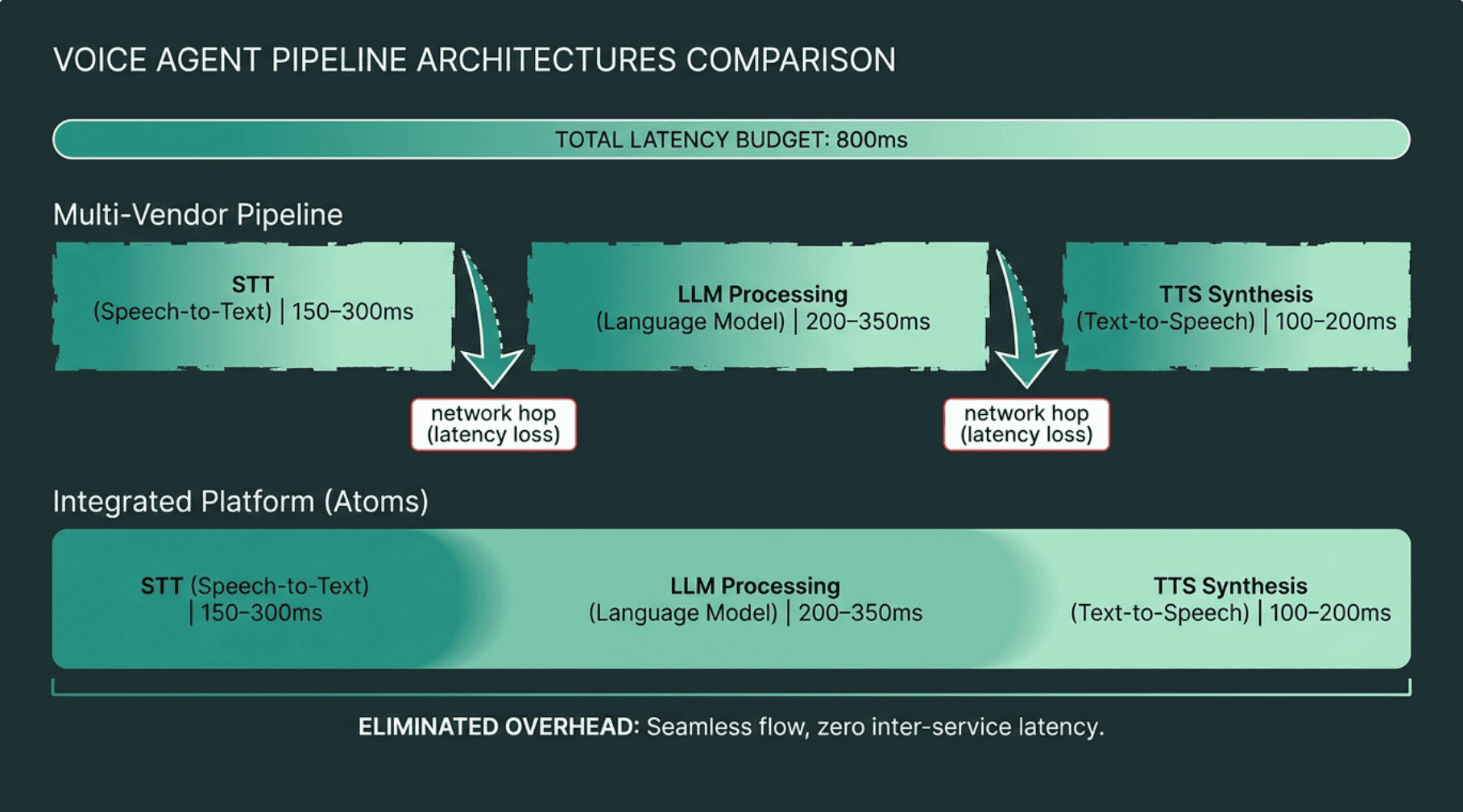
Integrated pipelines eliminate inter-service network hops that silently consume the 800ms conversational latency budget.
Smallest AI is designed for pipeline coherence. For voice agents, fast STT is only part of the equation. The ultimate goal is how quickly a transcript can become a model decision and then audible speech. A co-located Pulse-Lightning stack, delivered via Atoms, is designed to keep these handoffs tight and manage the latency budget within a single system, rather than across separate service level agreements.
The tradeoff is one of scope. Teams that require a standalone transcription API and do not plan to adopt a broader voice agent stack may find Deepgram’s ecosystem and third-party integrations to be a more direct fit. The value of Smallest AI's approach increases as more of its components are adopted. A team that needs STT now but anticipates adding TTS and agent orchestration later is well-aligned with this model. In contrast, a team that only needs transcription for a media archive might find a dedicated transcription provider more suitable.
Verdict: Which Should You Choose?
Choose Deepgram Nova-3 if you need a mature, standalone STT API with broad language support, enterprise-grade features, and the flexibility to pair it with your own LLM and TTS. Its architecture is optimized for low latency. Choose Smallest AI Pulse if you are building a real-time conversational voice agent and want STT and TTS to function as a unified system. The integrated architecture is designed to reduce the inter-service latency that can accumulate in multi-vendor pipelines and provide more predictable performance under load.
Deepgram is a good fit if: you need standalone transcription, you are already committed to specific LLM/TTS vendors, or your primary workload is media, analytics, or call recording rather than live conversation.
Smallest AI is better suited for teams that: are building a voice agent product, prefer a single vendor for the STT-TTS pipeline, or prioritize consistent tail latency in production over median latency in isolation. Understanding the nuances of speech-to-text API pricing models is also recommended before committing at scale. For a hands-on look at the integrated stack, you can explore the Smallest AI platform.
The Problem This Comparison Solves
The challenge for voice engineers is not just finding an STT model that appears fast on paper. Both Deepgram and Smallest AI aim for latency under 300ms in standard conditions. The more difficult problem is consistently keeping a voice agent under an 800ms round-trip budget, across concurrent users, in a production environment where network conditions and load can vary. Multi-vendor pipelines don't just add latency; they add variance that is difficult to predict and debug. Smallest AI's approach is to treat STT as the first stage of a single, integrated voice pipeline. When Pulse hands off directly to Lightning within the AI Voice Agents platform, the latency budget is managed end-to-end. This can be the difference between a voice product that feels immediate and one that sounds like it is pausing to think.
What’s the practical latency difference between Deepgram and Smallest AI for real-time voice agents?
Does Smallest AI offer a speech-to-text API developers can call directly?
How does word error rate compare between the two providers?
Which provider makes more sense for a full conversational voice agent?
What happens to STT latency when concurrency spikes?

